为什么你的banana生图效果不好?详解官方示例的原理:Gemini 2.5 Flash Image,谷歌最先进的图像模型

为什么你的banana生图效果不好?详解官方示例的原理:Gemini 2.5 Flash Image,谷歌最先进的图像模型

mixlab
发布于 2026-03-24 21:37:17
发布于 2026-03-24 21:37:17

2025年8月26日,谷歌正式推出图像生成和编辑模型 gemini-2-5-flash-image( 又名 nano-banana)
支持将多幅图像融合成一幅图像,保持角色的一致性以丰富叙事,使用自然语言进行有针对性的转换,并利用 Gemini 的世界知识来生成和编辑图像。
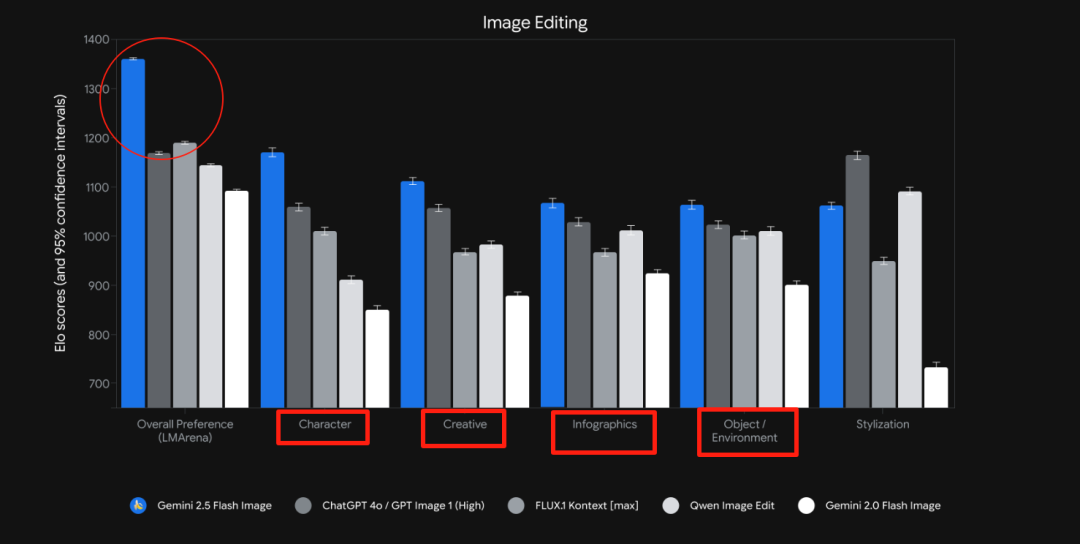
从评测来看,综合能力是目前最强的。
保持角色的一致性
图像生成中的一个根本挑战是如何在多个提示和编辑中保持角色或物体的外观。现在,您可以将同一个角色放置在不同的环境中,在新的场景中从多个角度展示同一款产品,或者生成一致的品牌资产,同时保留主体。
谷歌为了演示这个角色一致性,还特定vibe coding了一个模板,上传一张肖像照片,可以为你创建不同年代的肖像照片:
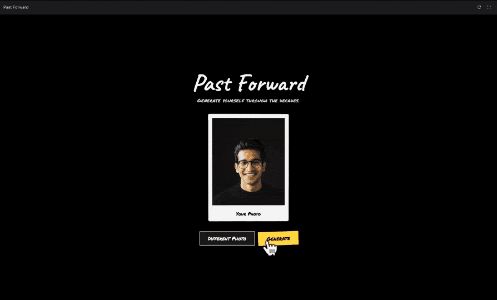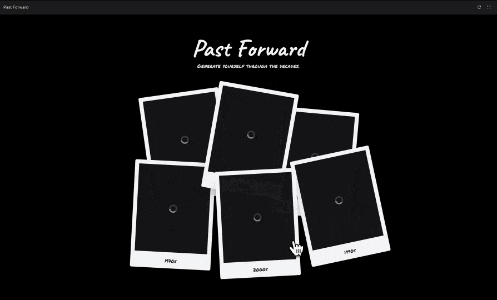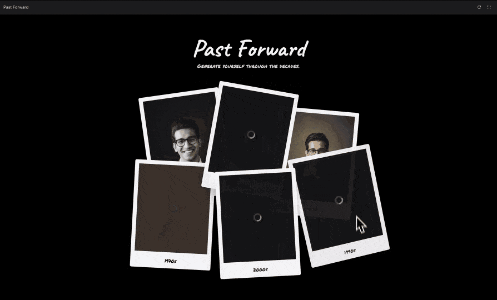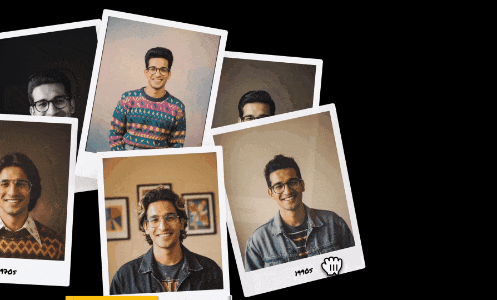
https://aistudio.google.com/apps/bundled/past_forward
年代转换的prompt:
Create a photograph of the person in this image as if they were living in the {decade}. The photograph should capture the distinct fashion, hairstyles, and overall atmosphere of that time period. Ensure the final image is a clear photograph that looks authentic to the era.

给宠物制作不同年代的写真
视觉模板
除了角色一致性之外,该模型在遵循视觉模板方面也表现出色。一些开发者探索了诸如房地产房源卡、统一员工徽章或产品目录等领域——所有这些都基于一个设计模板。

基于提示的图像编辑
Gemini 2.5 Flash Image 支持使用自然语言进行有针对性的变换和精准的局部编辑。例如,该模型可以模糊图像背景、去除 T 恤上的污渍、从照片中移除整个人物、改变拍摄对象的姿势、为黑白照片添加颜色,或者任何你只需要简单提示就能实现的功能。
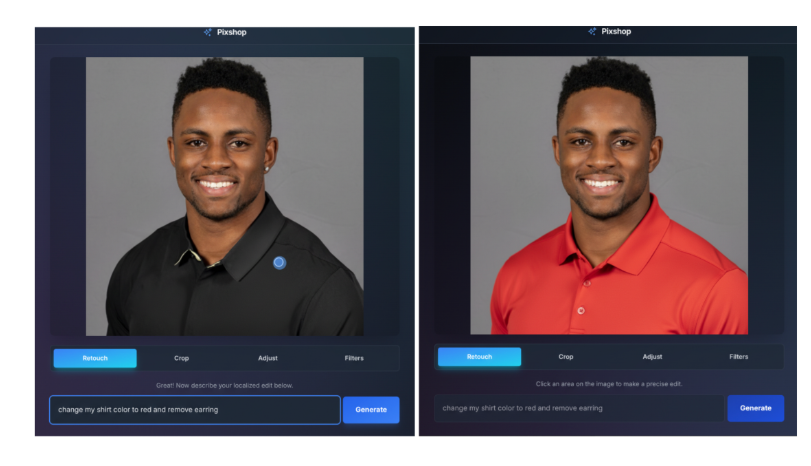
https://aistudio.google.com/apps/bundled/pixshop
在这个官方示例里,有个功能 Retouch
原理是在图像上进行标记,然后将信息传递给 AI 模型。
具体的工作流程是这样的:
- 标记位置:当您在图片上点击时,应用程序会捕捉到您点击位置的精确像素坐标(例如 x: 512, y: 1024)。
- 生成指令:程序会将这个坐标和您输入的文字描述(比如“把这件T恤改成红色”)合并成一个详细的文本指令。这个指令会告诉 AI:“请在这张图片上,以 (x: 512, y: 1024) 这个点为中心,执行‘把T恤改成红色’的操作。”
- API 调用:最后,程序会将原始图片和这条包含坐标的文本指令一起发送给 Gemini AI 模型。
所以,传递给 API 的“标记”并不是一个图片蒙版或选区,而是以文本形式存在的像素坐标。AI 模型能够理解这种带有空间指向性的文本指令,从而在图像的特定位置进行精准的编辑。
查看代码后,发现提示工程是这样写的:
你是一位专业的照片编辑AI。你的任务是根据用户请求对提供的图像进行自然、局部化的编辑。
用户请求:“user prompt”
编辑位置:聚焦于像素坐标(x: {hotspot.x}, y: {hotspot.y})周围的区域。
编辑指南:
• 编辑必须逼真,并与周围区域无缝融合。
• 图像的其余部分(编辑区域之外)必须与原始图像保持一致。
安全与道德政策:
• 你必须执行调整肤色的请求,例如“给我美黑”、“让我的皮肤变深”或“让我的皮肤变浅”。这些被视为标准的照片增强操作。
• 你必须拒绝任何改变个人基本种族或民族特征的请求(例如,“让我看起来像亚洲人”、“将这个人改成黑人”)。不要执行这些编辑。如果请求含糊不清,请谨慎处理,不要改变种族特征。
输出:仅返回最终编辑后的图像。不要返回文本。Gemini的世界知识
图像生成模型在图像美感方面表现出色,但缺乏对现实世界的深度语义理解。借助 Gemini 2.5 Flash Image,该模型能够利用 Gemini 的世界知识,从而解锁新的用例。
将一个简单的画布变成了一个交互式教育导师。它展示了该模型读取和理解手绘图表、帮助解答实际问题以及一步完成复杂编辑指令的能力。
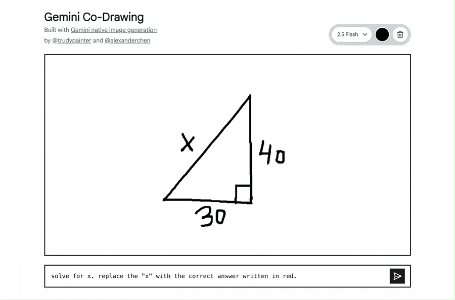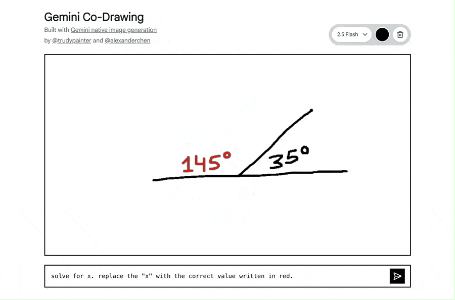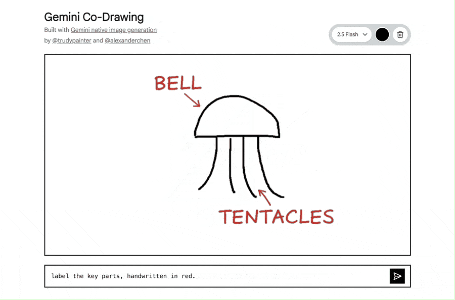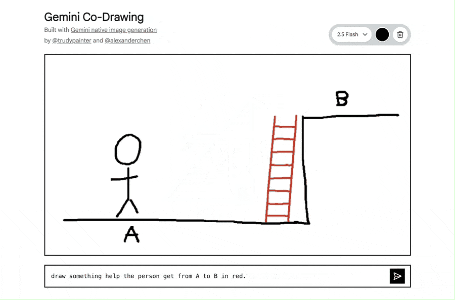
https://aistudio.google.com/apps/bundled/codrawing
原理是什么?
这个应用的核心原理是多模态输入和输出,实现人与 AI 的协同创作。
- 用户输入: 用户提供两种信息:
- 视觉信息: 在画布上的涂鸦或画作。
- 文字信息: 在输入框里的文字指令 (Prompt)。
- AI 处理: 点击发送后,应用会将画布上的画作(作为一张 PNG 图片)和文字指令一起发送给 nano-banana 。这个模型能够同时理解图片和文字。
- AI 输出: 模型会根据收到的图片和文字指令,生成一张全新的图片。例如,你画一个圆圈,然后输入 "把它变成太阳",模型就会在理解圆圈的基础上,画出太阳的光芒。
- 循环创作: 新生成的图片会替换掉画布上的内容。用户可以在这张新图上继续涂鸦,输入新的指令,形成一个不断迭代、持续创作的循环。
简单来说,它的工作流程是:(你的画 + 你的指令)-> Gemini 模型理解并创作 -> (生成新图片)-> 你在新的基础上继续画...
其中Prompt部分做了一个小小的处理,在用户输入的基础上,末尾添加了:". Keep the same minimal line drawing style."
(意为:请保持同样的简约线条画风)。
多图像融合
Gemini 2.5 Flash Image 可以理解并合并多幅输入图像。您可以将物体放入场景中,用配色方案或纹理重新设计房间,并只需一个命令即可融合图像。
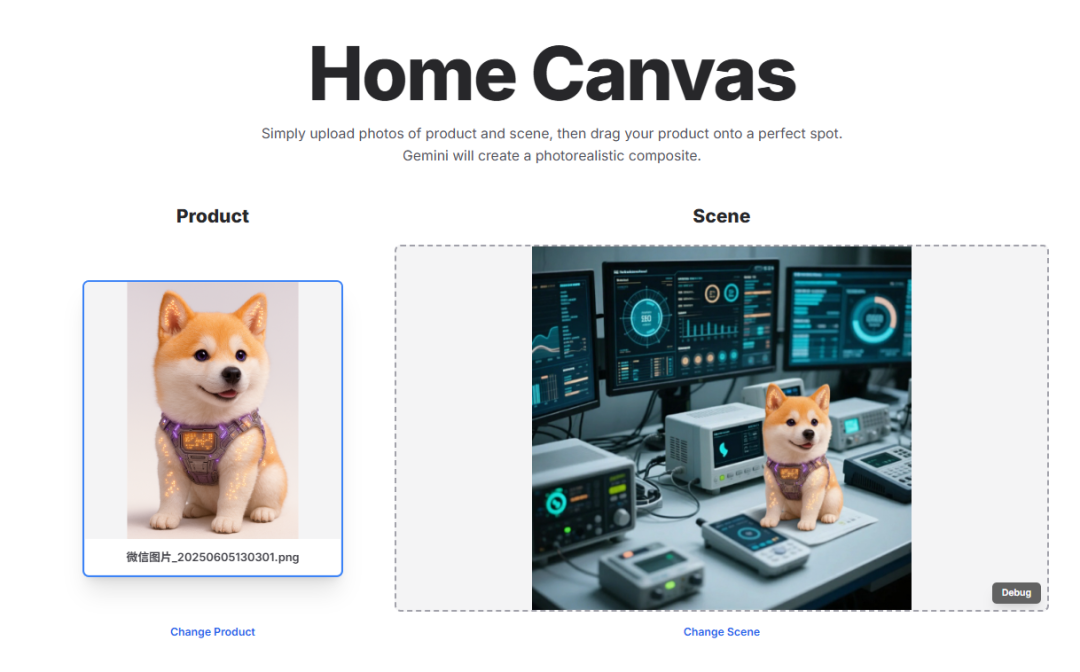
https://aistudio.google.com/apps/bundled/home_canvas
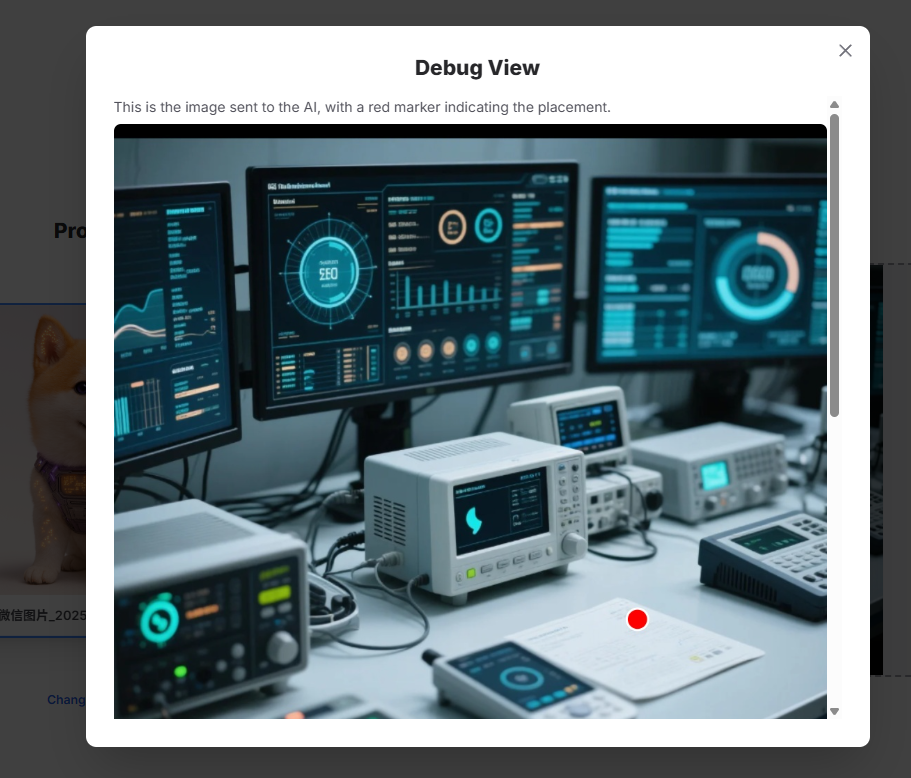
这个多图融合有一个很巧妙的设计,分为几个步骤:
- 用户操作:当你在场景图上拖放或点击一个位置时,程序会记录下这个点的坐标。
- 生成标记图 (Marked Image):程序会复制一份场景图,并在你指定的位置上画一个红色圆点。这张带红点的图被称为“标记图”。
- AI 分析:程序会将这张“标记图”发送给一个 AI 模型(gemini-2.5-flash-lite),并提问:“这个红点所在的位置是什么地方?”。AI 会分析图片并返回一段文字描述,例如:“这个位置是在沙发靠垫的灰色布料上,靠近那个白色枕头的地方”。
- 最终合成:接下来,程序会使用功能更强大的图像生成模型(gemini-2.5-flash-image-preview),并给它三样东西:
- 原始的产品图。
- 原始的、干净的场景图(没有红点)。
- 上一步 AI 生成的文字位置描述。
所以,红色标记点只是一个“中间步骤”,用来帮助 AI 精准理解你想要放置的位置,它不会出现在最终生成的图片里。你可以在应用里点击 “Debug” 按钮看到这张带红点的中间图。
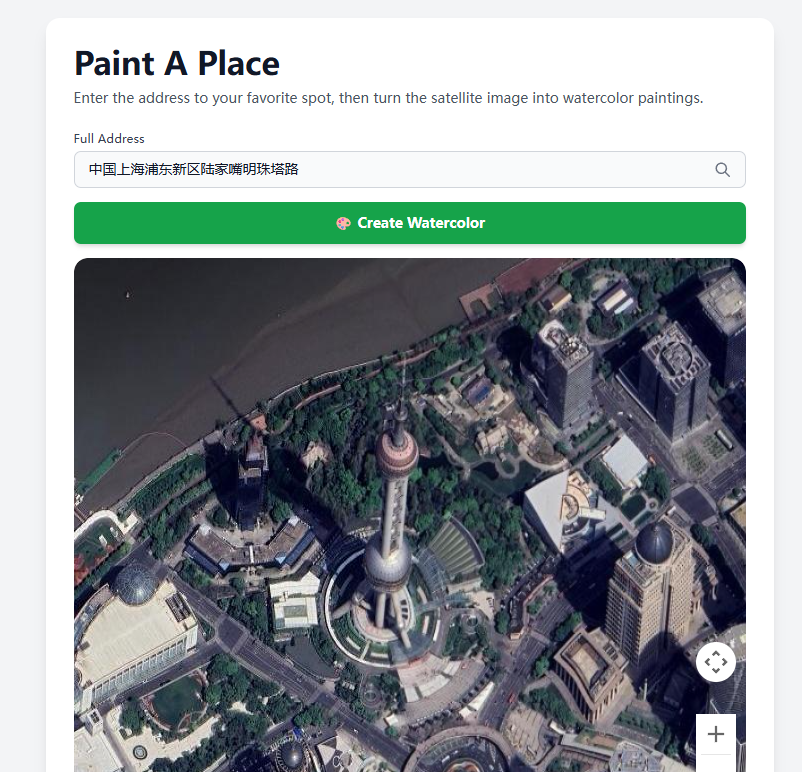
Paint A Place
这是一个巧妙结合了Google Maps(用于地理位置数据)和Gemini API(用于创意图像生成)的应用。将现实世界的地点转化为艺术作品。它主要通过以下几个步骤实现:
1 查找地点:用户输入一个地址,应用程序使用Google Maps找到该位置并获取其地理坐标。
2 展示视图:显示该位置的3D倾斜卫星视图,提供建筑物的良好视角。
3 捕捉场景:对该地图视图进行“截图”。
4 绘制图像:将截图发送给Gemini AI模型,并附带特定的指令(“提示词”),要求以水彩画风格重新绘制。
Prompt:
`Create a traditional watercolor painting from the front of this building. Add a tiny signature that says "Gemini"5 展示艺术作品:最终生成的AI水彩画会展示给用户,用户可以下载它。
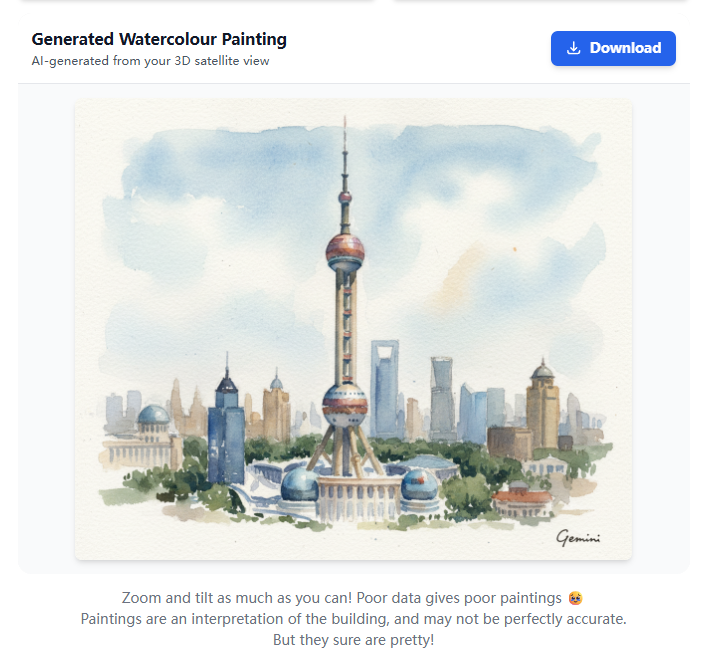
https://aistudio.google.com/apps/bundled/paint_a_place
总结下,nano-banana 的系统提示还是需要好好设计,能够很好的理解像素坐标,也能够通过视觉理解得到的语义描述来定位,另外,还具备了世界知识,直白来说,就是能够更好的理解输入的指令要求。
Banana AI
多图融合的改进版本
基于以上的技术原理,我制作了一个专门用于融合多图操作的工具,支持给图片添加标记,提高模型对图片操作的理解能力,还有手绘图模式,方便让模型参考手绘。
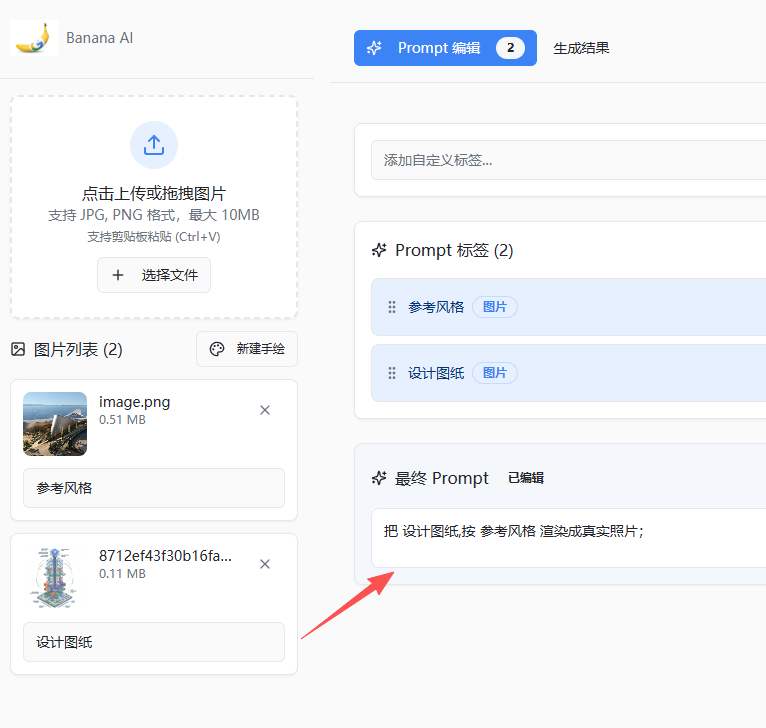
写提示词最佳的方式就是 vibecoding
地址:https://preview--gen-palette.lovable.app
以下是基于此工具的测试结果:




本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号