DeepSeek 彻底和 NVIDIA 决裂了!

DeepSeek 彻底和 NVIDIA 决裂了!

民工哥
发布于 2026-03-24 14:31:05
发布于 2026-03-24 14:31:05
— 特色专栏 —
大家好,我是民工哥!

专为下一代国产芯片设计!DeepSeek采用UE8M0 FP8标准:华为积极适配 彻底和NVIDIA决裂了
DeepSeek 彻底和 NVIDIA 决裂了!
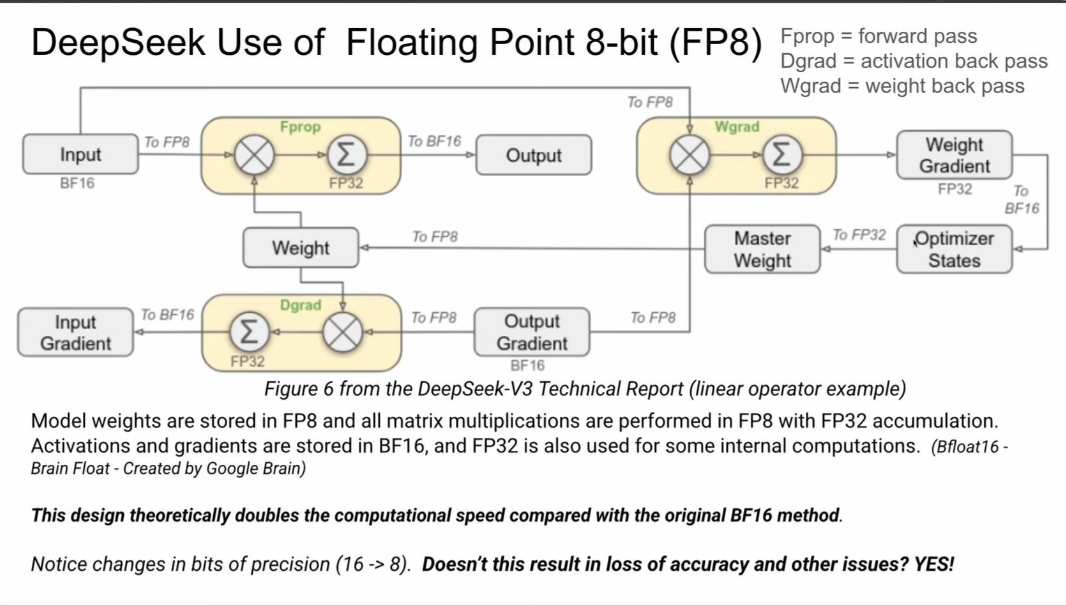
近日,深度求索宣布正式发布DeepSeek-V3.1。其中一个重大的进步和惊喜,就是支持了UE8M0 FP8。

DeepSeek在其官宣发布DeepSeek-V3.1的文章中提到,UE8M0 FP8是针对即将发布的下一代国产芯片设计。

UE8M0 FP8采用“无符号指数(U8)+ 动态缩放(Scale)”策略,通过省略符号位和尾数位,将存储开销压缩至极低水平(仅8位),同时通过Scale因子动态调整数值范围,避免信息丢失。
这种设计使国产芯片(如昇腾、寒武纪)在推理阶段可减少50%-75%的显存占用,矩阵乘法速度较FP16提升2-3倍。
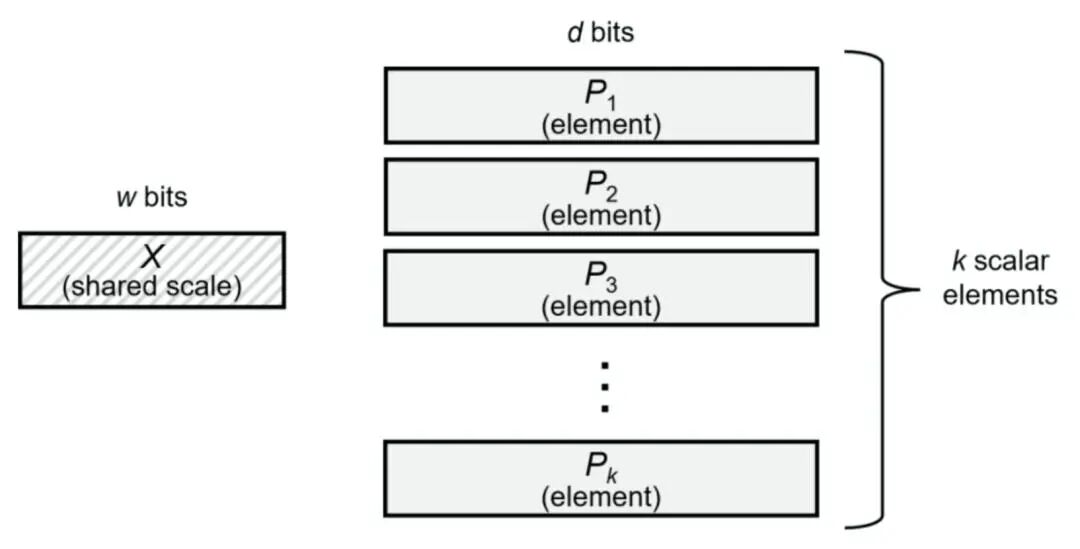
相比NVIDIA的FP8标准(E4M3/E5M2,含3-2位小数精度),UE8M0 FP8牺牲了部分通用性(如不支持负数直接表示),但换取了更低的功耗和更高的运算效率,对芯片制程工艺要求更低,更适合国产芯片当前的技术水平。
NVIDIA的FP8标准与其CUDA软件栈、Tensor Core硬件深度绑定,支持混合精度训练(如FP16/FP8/FP32动态切换),并覆盖从训练到推理的全流程。这种生态闭环使开发者难以轻易迁移至其他标准。
UE8M0 FP8为国产芯片提供了技术路径,使其在推理效率上接近NVIDIA同级产品(如H200)。
生态闭环仍面临巨大的挑战,国产AI生态需从芯片、框架、算力平台到应用层实现闭环适配。
目前,摩尔线程已推出支持原生FP8的GPU,芯原股份的NPU也兼容FP8技术,但软件栈(如编译器、驱动)的成熟度仍落后于NVIDIA,需长期投入。

DeepSeek通过UE8M0 FP8标准,DeepSeek将模型精度与国产芯片绑定,降低对海外GPU的依赖,为国产芯片提供应用场景和优化方向。
DeepSeek-V3.1的推理成本仅为闭源系统的1/60,推动AI应用渗透率从15%向50%跃升。这种成本优势可能吸引更多开发者转向国产生态。
在各项评测指标得分基本持平的情况下,R1-0528
NVIDIA 目前依旧是全球AI芯片主导者,占据数据中心 AI 加速芯片市场约90%份额,其GPU在训练效率、生态兼容性上具有不可替代性。
DeepSeek 此次的发布可以说是对国产AI体系自主化的一次重要推动,Deepseek这次适配国产芯片,是从“硬件替代”升级到“硬件+生态”一起抓,这才是关键中的关键。
但是,国产AI生态自主化闭环仍需长期建设。
👍 既然都看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号