Nature | 基于检索增强语言模型的科学文献综合分析

Nature | 基于检索增强语言模型的科学文献综合分析

DrugAI
发布于 2026-03-03 10:27:41
发布于 2026-03-03 10:27:41
DRUGONE
科学研究高度依赖对海量文献的系统综合,但随着论文数量激增,研究人员难以高效获取、整合并验证相关知识。大语言模型虽具潜力,但常出现幻觉引用、知识过时及缺乏可靠归因等问题。
研究人员提出了 OpenScholar ——一种专为科学文献综合设计的检索增强语言模型系统。该系统可从 4,500 万篇开放获取论文中检索相关段落,并生成带有精确引用支撑的长篇综合回答。同时,研究人员构建了首个多学科大规模评测基准 ScholarQABench,用于系统评估文献综合能力。实验结果表明,即使是参数规模较小的 OpenScholar-8B,也在复杂多文献综合任务中超越 GPT-4o 与现有系统,并显著减少虚假引用问题。研究人员进一步开源了模型、数据存储库及评测框架。

科学文献综合需要同时满足:
- 高召回与高精度的信息检索;
- 跨多篇论文的知识整合;
- 严格的引用可验证性。
但现有大语言模型存在明显缺陷:
- 频繁生成不存在的文献引用(幻觉率高达 78–98%);
- 覆盖面不足,往往只基于少数论文作答;
- 难以处理长篇、多文献综合任务。
传统检索增强方法(RAG)虽有所改善,但缺乏:
- 专用科学文献数据库;
- 高质量检索与重排序机制;
- 长篇内容自我修正能力。
OpenScholar 系统框架
OpenScholar 由三大核心组件构成:
专用科学文献数据存储库(OSDS)
- 包含 4,500 万篇论文;
- 共 2.36 亿段文本嵌入;
- 覆盖至 2024 年的最新开放获取研究。
是目前规模最大的开源科学文献向量库之一。
多阶段高精度检索管线
综合三类信息源:
- OSDS 密集向量检索;
- 学术搜索 API(关键词驱动);
- 网络学术平台全文抓取。
并通过:双编码器初筛 + 交叉编码器重排序。确保相关性与覆盖性兼顾。
自反馈迭代生成机制
不同于一次性生成,OpenScholar采用:
- 初始回答生成;
- 模型自动反馈指出缺失或不足;
- 追加检索补充证据;
- 多轮修正与完善;
- 最终引用验证。
显著提升:
- 内容完整度;
- 事实准确性;
- 引用可靠性。
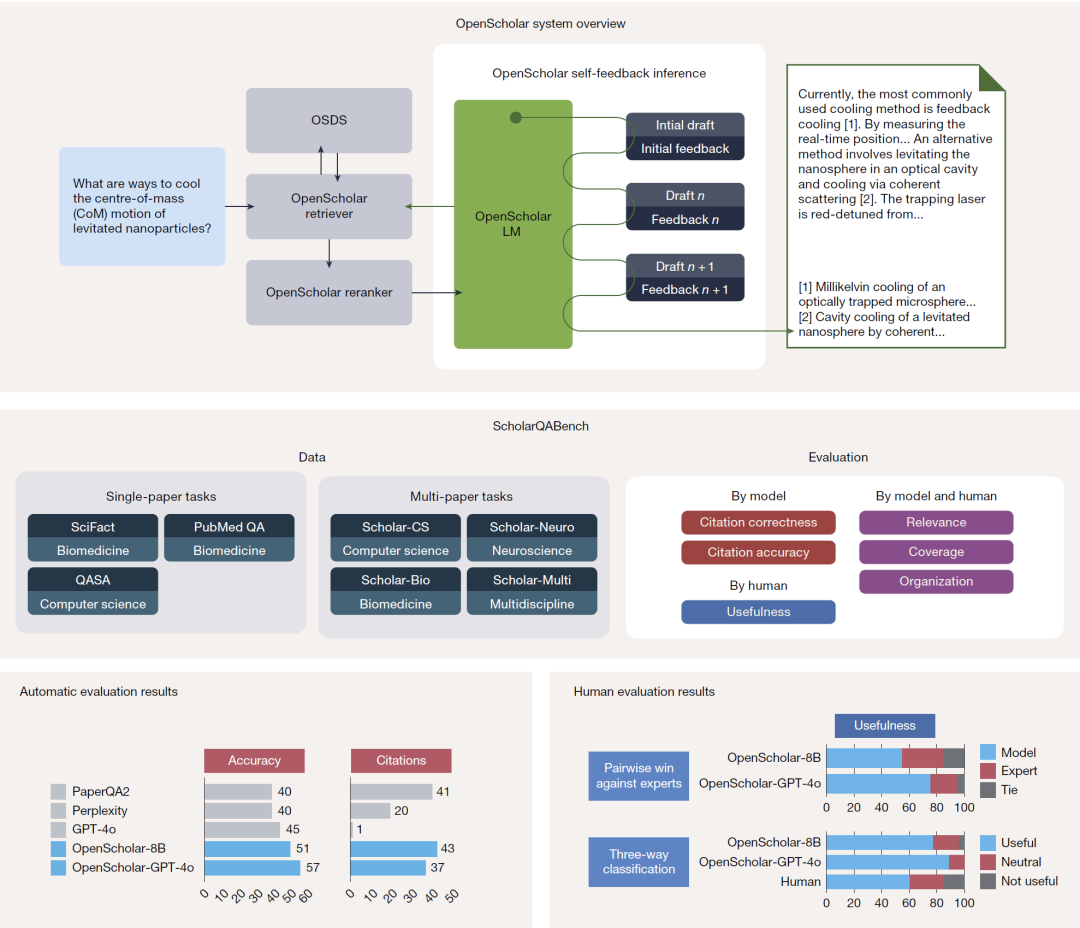
图1:OpenScholar系统架构与ScholarQABench评测框架。
ScholarQABench 多学科评测基准
研究人员提出首个面向文献综合的大规模开放式基准:
覆盖领域:
- 计算机科学
- 物理学
- 生物医学
- 神经科学
数据规模:
- 近 3,000 个专家撰写问题;
- 超过 200 篇长篇标准答案。
评测方式:
- 自动指标(正确性、引用准确率);
- 专家人工评估(覆盖度、结构性、相关性、实用性)。
解决以往短问答或选择题无法评估真实文献综合能力的问题。
主要性能结果
单篇论文任务表现
OpenScholar 在准确率与引用正确性上显著优于:
- 纯语言模型;
- 标准RAG方法。
多论文综合任务表现
- OpenScholar-8B 在正确性评分上超越 GPT-4o 与 PaperQA2;
- OpenScholar-GPT-4o 相比原始 GPT-4o 提升约 12%。
在专家评测中:
- OpenScholar-GPT-4o 有 70% 情况优于人工答案;
- OpenScholar-8B 有 51% 情况优于人工答案。
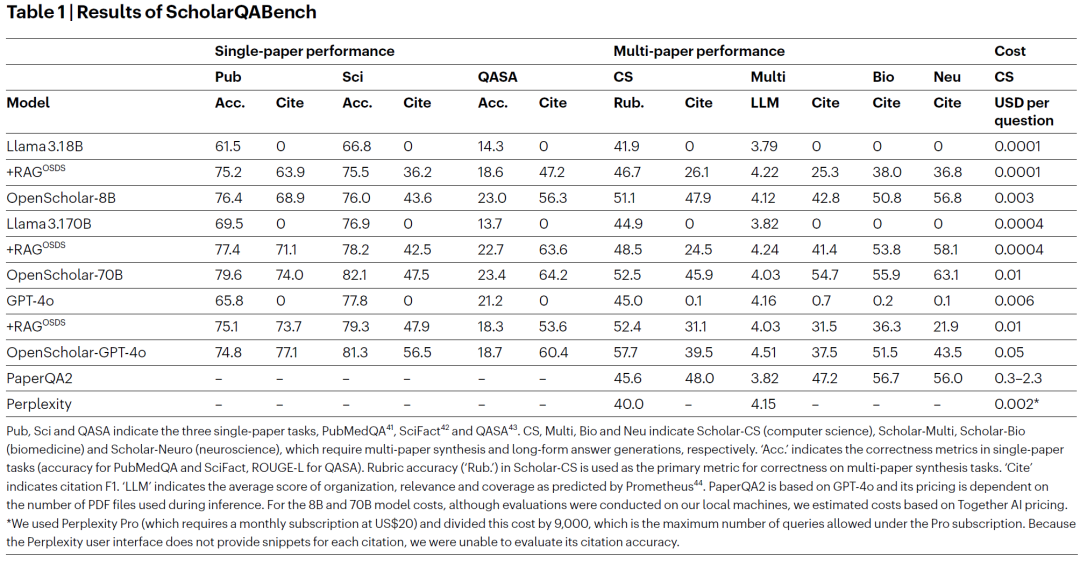
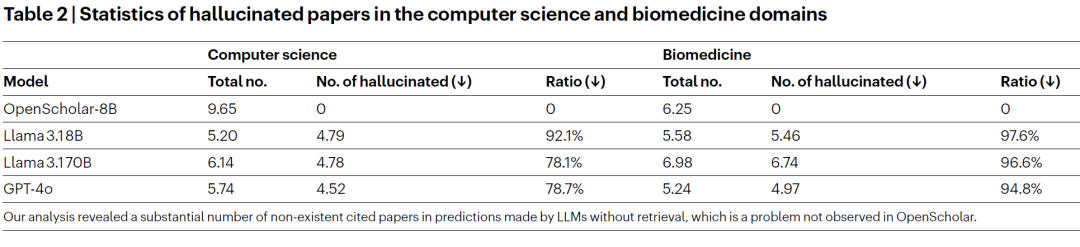
幻觉问题系统分析
研究人员系统统计发现:
不带检索的大语言模型
- 78–98% 的引用论文并不存在;
- 即使存在,往往与内容无关。
OpenScholar
- 幻觉引用几乎为零;
- 引用与内容高度匹配。
同时,检索增强模型在信息覆盖范围上显著优于纯语言模型。
消融实验与系统分析
关键发现:
- 去除重排序模块 → 性能大幅下降;
- 去除自反馈机制 → 综合质量明显变差;
- 单一检索源远不如多源融合。
此外:
- 小模型在长上下文下易性能退化;
- 专项训练模型更善于处理多段证据整合。
专家人工评测结果
专家从多个维度进行细致打分:
- 组织结构
- 覆盖深度
- 内容相关性
- 实际可用性
结果显示:
- OpenScholar 在覆盖度上优势最显著;
- GPT-4o(无检索)在覆盖度表现最差;
- 长回答并非唯一优势,控制长度后 OpenScholar 仍优于人工答案。
讨论
该研究首次系统构建了:
- 全开源科学文献综合系统;
- 超大规模科学检索数据库;
- 面向真实科研需求的评测基准。
核心贡献在于:
- 显著缓解大模型幻觉问题;
- 实现跨多论文高质量知识整合;
- 提供可复现、低成本解决方案。
OpenScholar 展示了检索增强语言模型在科研辅助中的巨大潜力,未来有望成为:
- 文献综述自动化工具;
- 研究方向探索助手;
- 科学知识发现引擎;
- 局限性与未来方向。
主要限制包括:
- 专家标注成本高,评测规模仍有限;
- 自动评价指标仍有改进空间;
- 检索有时未能选中最具代表性的论文。
未来可引入:
- 引文网络信息;
- 时间权重与领域权威性建模;
- 用户交互反馈持续优化系统。
整理 | DrugOne团队
参考资料
Asai, A., He, J., Shao, R. et al. Synthesizing scientific literature with retrieval-augmented language models. Nature (2026).
https://doi.org/10.1038/s41586-025-10072-4

内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号