B站开源IndexTTS-2,零样本语音克隆,情感可控、时长可控,本地轻松跑

B站开源IndexTTS-2,零样本语音克隆,情感可控、时长可控,本地轻松跑

Ai学习的老章
发布于 2026-03-02 20:37:50
发布于 2026-03-02 20:37:50
大家好,我是 Ai 学习的老章
几天前我把手机系统语言和 B 站语言设置成了英文
字幕,评论和弹幕也是英文
字幕,评论和弹幕也是英文
最牛逼的是视频声音也被转成了英文,不同人物音色还都保留了!声音克隆这一块,还是 B 站会整活儿
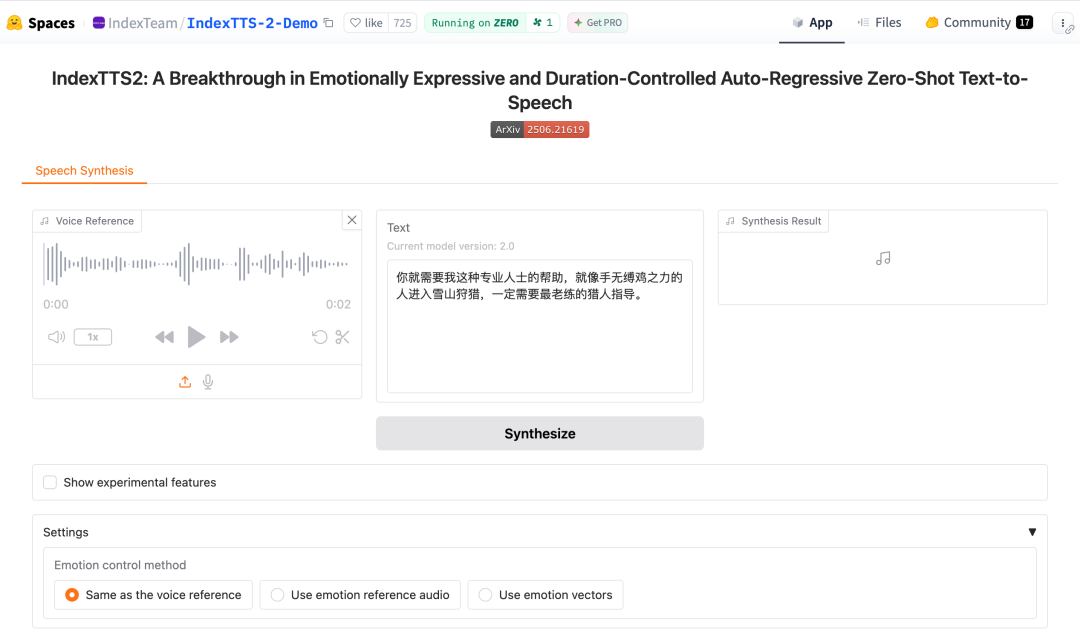
我搜了一下,发现 B 站开源过一个情感可控、时长可控的零样本语音克隆模型——IndexTTS-2,试了一下官方 Demo,效果确实不错。
简介
IndexTTS-2 是 B 站 Index 团队开源的第二代零样本文本转语音系统。说白了就是:给它一段参考音频,它就能用这个声音说任何你想说的话,还能带情绪。
IndexTTS-2 架构图
IndexTTS-2 架构图
这个项目最牛的地方在于解决了一个行业痛点:传统自回归 TTS 模型(比如 XTTS、CosyVoice)虽然语音自然度很高,但由于逐 token 生成的机制,很难精确控制合成语音的时长。但在视频配音这种场景下,你必须让语音精准匹配画面时长——差个 0.5 秒都不行!
IndexTTS-2 首次在自回归模型上实现了精确的时长控制,同时还支持情感和音色的分离控制,这意味着你可以:
- 用张三的声音 + 李四的情绪来合成语音
- 精确指定语音时长,完美匹配视频画面
- 用自然语言描述情绪(比如"害怕"、"惊讶"),模型自动生成对应情感的语音
核心功能与特点:
- 时长精确可控:支持指定 token 数量来精确控制语音时长,误差率低于 0.02%,这数据太炸了
- 情感与音色分离:独立控制音色(谁的声音)和情感(什么情绪),互不干扰
- 多模态情感输入:支持参考音频、情感向量、自然语言描述三种方式控制情感
- 基于 Qwen3 的情感理解:用 DeepSeek-R1 蒸馏 Qwen3-1.7B,实现文本到情感向量的转换
- 中英双语支持:基于 55K 小时数据训练,其中 30K 中文 + 25K 英文
- 开源可商用:Apache 2.0 协议,代码和权重全开源
技术亮点
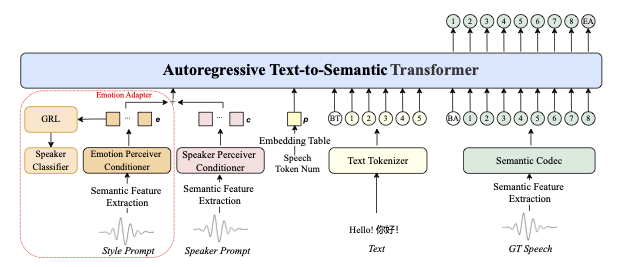
IndexTTS-2 的架构由三个核心模块组成:
1. Text-to-Semantic 模块 (T2S)
这是个自回归 Transformer,负责把文本转成语义 token。创新点在于时长编码机制——通过将目标 token 长度编码为嵌入向量,让模型在生成时"知道"自己需要生成多少个 token。30% 概率随机置零,同时支持自由生成模式。
2. Semantic-to-Mel 模块 (S2M)
基于 Flow Matching 的非自回归模块,负责把语义 token 转成梅尔频谱。引入了 GPT 隐层增强技术,把 T2S 模块最后一层的隐状态融合进来,有效解决了情感语音合成时的发音模糊问题。
3. Text-to-Emotion 模块 (T2E)
用 DeepSeek-R1 作为教师模型生成情感分布,然后用 LoRA 蒸馏到 Qwen3-1.7B,实现了低成本的自然语言情感控制。支持 7 种基础情感:愤怒、快乐、恐惧、厌恶、悲伤、惊讶、平静。
三阶段训练策略也是一大亮点:
- Stage 1:全量数据建立基础能力
- Stage 2:135 小时高质量情感数据 + GRL 解耦
- Stage 3:全量数据二次微调增强鲁棒性
安装
IndexTTS-2 的安装方式比较现代化,必须用 uv 包管理器,官方不支持 conda 和 pip(原因是依赖版本太敏感)。
# 1. 安装 uv
pip install -U uv
# 2. 克隆仓库
git clone https://github.com/index-tts/index-tts.git && cd index-tts
git lfs pull
# 3. 安装依赖
uv sync --all-extras
# 4. 下载模型
uv tool install "huggingface-hub[cli,hf_xet]"
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
国内用户如果 HuggingFace 访问慢,可以用 ModelScope:
uv tool install "modelscope"
modelscope download --model IndexTeam/IndexTTS-2 --local_dir checkpoints
硬件要求:
- GPU:NVIDIA GPU + CUDA 12.8+(推荐)
- 内存:8GB+(推荐 16GB)
- 存储:10GB+
使用
Web Demo 一键启动:
uv run webui.py
访问 http://127.0.0.1:7860 即可体验。支持 FP16 推理(省显存)、DeepSpeed 加速等选项。
Python API 使用:
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(
cfg_path="checkpoints/config.yaml",
model_dir="checkpoints",
use_fp16=True, # 省显存
use_cuda_kernel=False,
use_deepspeed=False
)
# 基础语音克隆
text = "大家好,我是 AI 配音"
tts.infer(
spk_audio_prompt='examples/voice_01.wav',
text=text,
output_path="gen.wav"
)
情感控制的几种方式:
# 方式 1:参考音频控制情感
tts.infer(
spk_audio_prompt='voice.wav', # 音色
emo_audio_prompt='emo_sad.wav', # 情感
text=text,
emo_alpha=0.9, # 情感强度
output_path="gen.wav"
)
# 方式 2:情感向量控制
# [happy, angry, sad, afraid, disgusted, melancholic, surprised, calm]
tts.infer(
spk_audio_prompt='voice.wav',
emo_vector=[0, 0, 0, 0, 0, 0, 0.45, 0], # 惊讶
text=text,
output_path="gen.wav"
)
# 方式 3:自然语言描述情感
tts.infer(
spk_audio_prompt='voice.wav',
text="快躲起来!是他要来了!他要来抓我们了!",
use_emo_text=True, # 自动从文本推断情感
emo_alpha=0.6,
output_path="gen.wav"
)
性能对比
根据论文实验结果,IndexTTS-2 在多个测试集上全面碾压同类模型:
模型 | LibriSpeech WER↓ | SeedTTS-zh WER↓ | 情感相似度↑ |
|---|---|---|---|
MaskGCT | 3.58% | 3.21% | 0.812 |
F5-TTS | 2.41% | 3.35% | 0.795 |
CosyVoice2 | 2.07% | 2.43% | 0.831 |
SparkTTS | 2.43% | 2.87% | 0.847 |
IndexTTS-2 | 1.88% | 2.12% | 0.872 |
时长控制精度更是惊人——在时长缩放实验中,token 数量误差率普遍低于 0.03%,这意味着几乎可以按毫秒级精度控制语音时长。
相关链接:
- 论文地址:https://arxiv.org/abs/2506.21619
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号