AI Agent + 数据工程

AI Agent + 数据工程

臻成AI大模型
发布于 2026-02-28 15:56:47
发布于 2026-02-28 15:56:47
凌晨两点,某互联网公司的数据工程师小王还在盯着屏幕上的SQL查询报错。这样的场景在过去几年里几乎是常态——
数据工程这个行当,从来都是用时间和体力换成果。但现在,情况正在悄悄发生变化。 这不是什么 magic,也不是靠堆人就能解决的老问题。 AI Agent的出现,正在从根本上改变数据工程师的工作方式,甚至重新定义这个职业的边界。

从堆人到提效
提到AI Agent,很多人的第一反应是又一个大模型概念。
但如果你真正跟一线的数据工程师聊一聊,会发现这次不太一样。
一位在数据领域深耕多年的创业者告诉我,早期AI在数据工程领域的切入点其实很务实——那些原本需要大量人工的数据治理工作,恰恰是大模型最擅长的地方。
比如从海量数据中提炼关键信息、自动生成数据文档、识别重复和冗余的表结构。这些事情以前要靠专人花时间梳理,现在AI可以快速完成。
但这只是第一步。
更深层的变化在于,数据工程的需求本身正在被AI重塑。
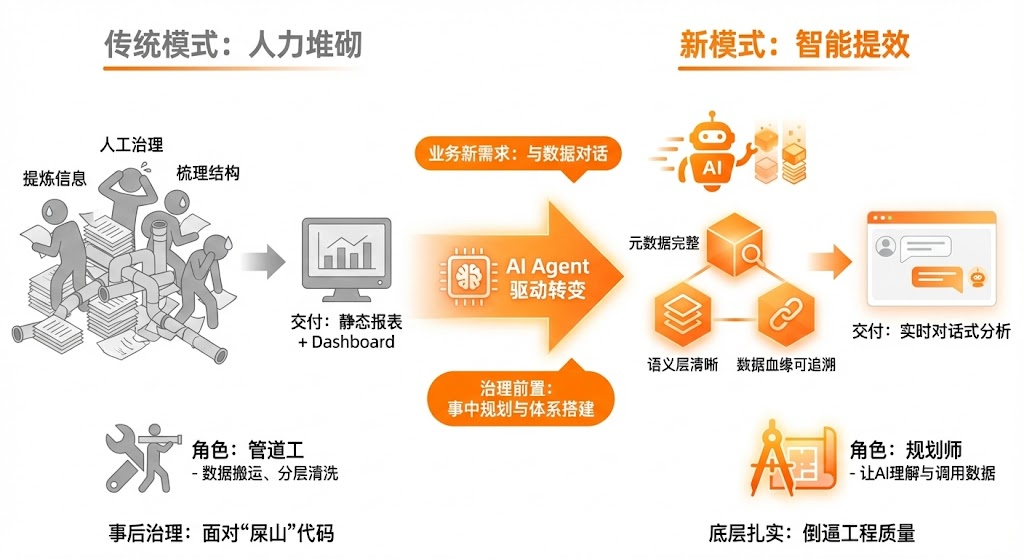
以前的交付物很明确:一张张处理好的数据表,加上一个Dashboard,业务方看数据就够了。
现在呢?业务方不仅看Dashboard,还想直接跟数据对话——问AI一个问题,AI直接给出答案。这就倒逼着数据工程师必须把底层的东西做得更扎实:元数据要完整、语义层要清晰、数据血缘要可追溯。
一位从大厂出来创业的技术专家说得更直接:“数据治理不应该是事后工作。等SQL代码变成屎山再治理,往往已经来不及了。好的数据工程,应该配合AI在事中就做好管理和体系搭建。”
这句话背后是一个残酷的现实:以前数据工程师的工作更像是管道工——把数据从A搬到B,分层、清洗、汇总。
现在的要求变成了规划师——不仅要搬数据,还要让数据能被AI正确理解和调用。
这需要的不仅是技术能力,更是思维方式的转变。
海内外市场的不同路径
有意思的是,AI Agent在数据工程领域的落地,海外和国内走的是完全不同的路。
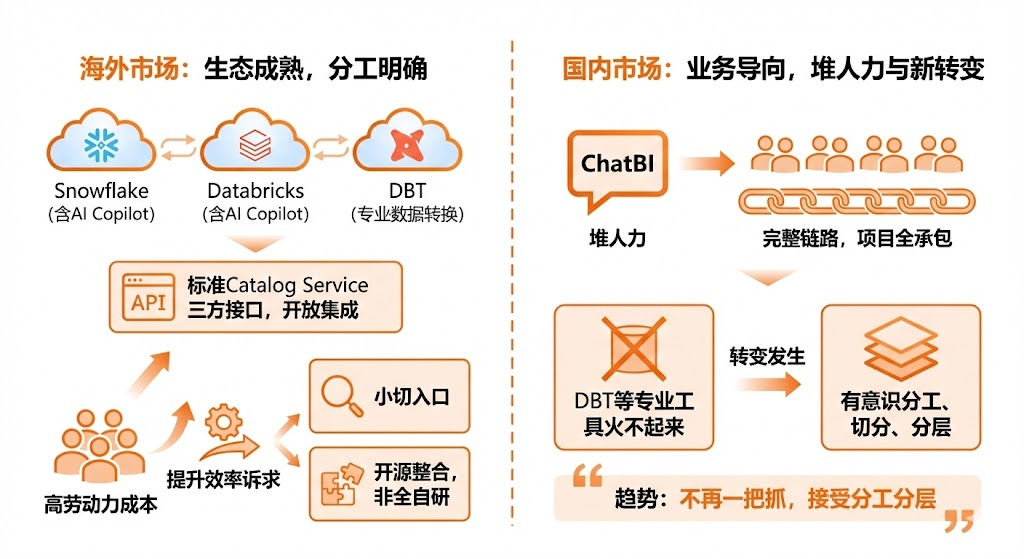
海外市场的特点是生态成熟,分工明确。
Snowflake和Databricks这两大云数据平台都有自己的AI Copilot产品,DBT这样的专业数据转换工具也已经形成了生态。
关键是海外有标准的Catalog Service等三方接口,做开放集成相对容易。
由于劳动力成本高,提升数据工程效率的诉求特别强烈,所以他们更倾向于选择小切入口,用开源生态的方式整合,不需要什么都自己做。
国内完全是另一幅景象。
最火的词是ChatBI,业务导向非常强。
执行力强到什么程度?针对某些场景的AI落地,堆人力也能做上去。往往是从上到下做完整的链路,一个项目从头到尾自己承包。DBT这类工具在国内从来没火过,也火不起来。
但变化也在发生。
国内现在开始有意识地分工、切分、分层,不再什么都自己抓。
一位行业前辈最近坦言,做了这么多年系统,现在越来越多人不想一把抓了,开始接受分工和分层。
这种转变不容易,但趋势已经很明显了。
数据Agent的阿喀琉斯之踵
如果说AI Agent给数据工程带来了什么新问题,准确率绝对是最大的那个。
在数据领域,准确性就是生命线。
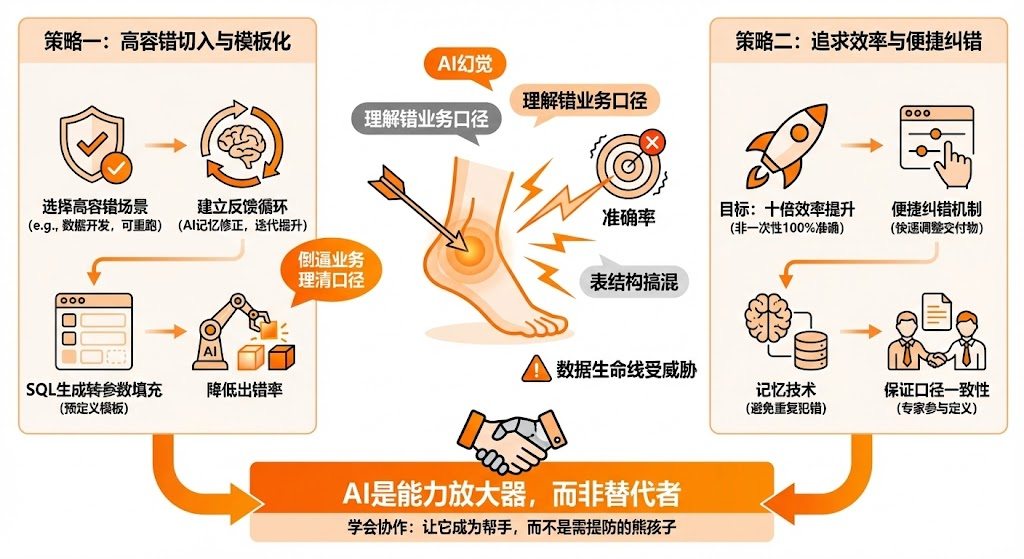
一个数字算错了,决策就可能走偏。但在AI的语境下,准确率恰恰是最难保证的。模型会幻觉,会理解错业务口径,甚至会把表结构搞混。
一家做数据Agent的创业公司分享了他们的应对策略:选择容错度高的场景切入,比如数据开发——改错了可以重跑,而不是直接做生产决策;建立反馈循环,让AI记住用户的修正,通过不断迭代提升准确率;把SQL生成转化为参数填充,预定义模板,只让AI填参数,大幅降低出错率。
最后一点特别重要。
本质上,很多错误源于业务口径本身就不清楚。AI反而能倒逼业务把口径理清楚——当你不得不告诉AI“GMV要这么算”的时候,你自己也得先把规则说清楚。
另一家公司的做法更务实:不追求AI一次性做到百分之百准确,而是追求十倍的效率提升。
具体做法是提供便捷的纠错机制,用户能快速调整AI的交付物;让AI记住修正,通过记忆技术避免重复犯错;保证业务口径的一致性,这个不是技术问题,要让业务专家参与定义。
说白了,AI在数据领域不是来取代人的,而是来放大人的能力的。
关键是你得学会跟AI协作,让它成为你的帮手,而不是一个需要时时提防的熊孩子。
结语
数据工程遇上AI Agent,不是一场突如其来的革命,而是水到渠成的演进。
那些还在用老办法堆人的团队,也许该停下来想一想:未来的数据工程师,需要具备什么样的新能力?
答案也许很简单:不是跟AI比谁写SQL更快,而是比谁能更好地定义问题、设计流程、管理数据资产。
AI可以帮你写代码,但它代替不了你对业务的理解。
这场变革才刚刚开始。真正的问题是,你准备好了吗?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号