27:【PyTorch】nvidia / triton依赖没装(2.6+版本常见)

27:【PyTorch】nvidia / triton依赖没装(2.6+版本常见)

安全风信子
发布于 2026-02-23 09:47:31
发布于 2026-02-23 09:47:31
作者: HOS(安全风信子) 日期: 2026-01-01 主要来源平台: GitHub 摘要: 本文详细分析2026年PyTorch 2.6+版本中常见的nvidia和triton依赖未安装问题,提供了完整的依赖检查、安装和验证流程。文章包含详细的错误分析、解决方案、自动化工具以及性能对比,帮助开发者快速解决依赖问题,充分发挥PyTorch的性能优势。
1. 背景动机与当前热点
在2026年,PyTorch 2.6+版本引入了许多新特性和性能优化,其中包括对NVIDIA新硬件的更好支持和对triton编译器的深度集成。然而,这些改进也带来了新的依赖要求,许多开发者在升级或安装PyTorch 2.6+时遇到了nvidia和triton依赖未安装的问题,严重影响了开发和部署效率。
本节核心价值
- 分析2026年PyTorch 2.6+版本的依赖变化
- 探讨nvidia和triton依赖的重要性
- 提供针对不同环境的依赖管理策略
2. 核心更新亮点与全新要素
2.1 全新要素1:依赖自动检测与修复工具
本文实现的依赖自动检测工具能够:
- 扫描环境中的缺失依赖
- 提供详细的依赖分析报告
- 自动生成安装命令
- 验证安装结果
2.2 全新要素2:nvidia依赖版本兼容性矩阵
本文提供的nvidia依赖版本兼容性矩阵能够:
- 明确不同PyTorch版本对nvidia依赖的版本要求
- 指导用户选择与CUDA版本兼容的nvidia依赖
- 预测可能的依赖冲突并提前规避
2.3 全新要素3:triton性能优化指南
本文提供的triton性能优化指南能够:
- 解释triton在PyTorch中的作用和性能优势
- 提供针对不同硬件的triton配置建议
- 分析triton与其他优化技术的配合使用
3. 技术深度拆解与实现分析
3.1 常见错误分析
3.1.1 nvidia依赖未安装错误
# nvidia依赖未安装错误示例
ImportError: Could not load library cudnn_cnn_infer64_8.dll. Error code 126
# 或
RuntimeError: Failed to initialize NVIDIA CUDA: CUDA driver initialization failed, you might not have a CUDA gpu.3.1.2 triton依赖未安装错误
# triton依赖未安装错误示例
ImportError: Triton is not available. Please install triton==2.6.0 or later for better performance.
# 或
ModuleNotFoundError: No module named 'triton'3.2 依赖分析
3.2.1 PyTorch 2.6+的关键依赖
依赖名称 | 版本要求 | 作用 | 安装命令 |
|---|---|---|---|
nvidia-cublas-cu13 | 13.1.0.3 | CUDA基础线性代数库 | pip install nvidia-cublas-cu13 |
nvidia-cuda-nvrtc-cu13 | 13.1.0.3 | CUDA运行时编译库 | pip install nvidia-cuda-nvrtc-cu13 |
nvidia-cuda-runtime-cu13 | 13.1.0.3 | CUDA运行时库 | pip install nvidia-cuda-runtime-cu13 |
nvidia-cudnn-cu13 | 8.9.7.29 | CUDA深度神经网络库 | pip install nvidia-cudnn-cu13 |
triton | 2.6.0+ | 优化的GPU编译器 | pip install triton |
3.3 解决方案详解
3.3.1 安装nvidia依赖
# 方法1:使用pip安装
pip install nvidia-cublas-cu13 nvidia-cuda-nvrtc-cu13 nvidia-cuda-runtime-cu13 nvidia-cudnn-cu13
# 方法2:使用uv安装(推荐)
uv pip install nvidia-cublas-cu13 nvidia-cuda-nvrtc-cu13 nvidia-cuda-runtime-cu13 nvidia-cudnn-cu13
# 方法3:根据CUDA版本选择
# CUDA 12.8
pip install nvidia-cublas-cu12 nvidia-cuda-nvrtc-cu12 nvidia-cuda-runtime-cu12 nvidia-cudnn-cu123.3.2 安装triton
# 安装最新版本的triton
pip install triton
# 安装特定版本的triton(与PyTorch版本匹配)
pip install triton==2.6.0
# 使用uv安装
uv pip install triton3.4 依赖检测与修复工具
#!/usr/bin/env python3
"""
PyTorch依赖检测与修复工具
"""
import subprocess
import sys
import json
def check_pytorch_installed():
"""检查PyTorch是否安装"""
try:
import torch
return {
"installed": True,
"version": torch.__version__,
"cuda_available": torch.cuda.is_available()
}
except ImportError:
return {"installed": False}
def check_nvidia_deps():
"""检查nvidia依赖"""
nvidia_deps = [
"nvidia-cublas-cu13",
"nvidia-cuda-nvrtc-cu13",
"nvidia-cuda-runtime-cu13",
"nvidia-cudnn-cu13"
]
installed_deps = {}
for dep in nvidia_deps:
try:
result = subprocess.run(
[sys.executable, "-m", "pip", "show", dep],
capture_output=True,
text=True
)
if result.returncode == 0:
# 提取版本号
for line in result.stdout.split('\n'):
if line.startswith('Version:'):
version = line.split(':', 1)[1].strip()
installed_deps[dep] = version
break
except Exception as e:
print(f"检查依赖 {dep} 时出错: {e}")
return installed_deps
def check_triton():
"""检查triton依赖"""
try:
import triton
return {
"installed": True,
"version": triton.__version__
}
except ImportError:
return {"installed": False}
def generate_fix_commands(missing_nvidia_deps, triton_missing):
"""生成修复命令"""
commands = []
if missing_nvidia_deps:
deps_str = " ".join(missing_nvidia_deps)
commands.append(f"pip install {deps_str}")
commands.append(f"# 或使用uv安装")
commands.append(f"uv pip install {deps_str}")
if triton_missing:
commands.append("pip install triton")
commands.append(f"# 或使用uv安装")
commands.append(f"uv pip install triton")
return commands
def main():
"""主函数"""
print("=== PyTorch依赖检测与修复工具 ===")
# 检查PyTorch
print("\n1. 检查PyTorch安装状态...")
pytorch_status = check_pytorch_installed()
if pytorch_status["installed"]:
print(f"PyTorch版本: {pytorch_status['version']}")
print(f"CUDA可用: {pytorch_status['cuda_available']}")
else:
print("PyTorch未安装,请先安装PyTorch")
return
# 检查nvidia依赖
print("\n2. 检查nvidia依赖...")
installed_nvidia_deps = check_nvidia_deps()
required_nvidia_deps = [
"nvidia-cublas-cu13",
"nvidia-cuda-nvrtc-cu13",
"nvidia-cuda-runtime-cu13",
"nvidia-cudnn-cu13"
]
missing_nvidia_deps = [dep for dep in required_nvidia_deps if dep not in installed_nvidia_deps]
if installed_nvidia_deps:
print("已安装的nvidia依赖:")
for dep, version in installed_nvidia_deps.items():
print(f" - {dep}: {version}")
else:
print("未安装任何nvidia依赖")
if missing_nvidia_deps:
print("\n缺失的nvidia依赖:")
for dep in missing_nvidia_deps:
print(f" - {dep}")
# 检查triton
print("\n3. 检查triton依赖...")
triton_status = check_triton()
if triton_status["installed"]:
print(f"triton版本: {triton_status['version']}")
else:
print("triton未安装")
# 生成修复命令
print("\n4. 修复建议...")
triton_missing = not triton_status["installed"]
fix_commands = generate_fix_commands(missing_nvidia_deps, triton_missing)
if fix_commands:
print("建议执行以下命令修复依赖:")
for cmd in fix_commands:
print(f" {cmd}")
else:
print("所有依赖均已安装,无需修复")
# 验证修复
print("\n5. 验证建议...")
print("修复依赖后,建议运行以下命令验证:")
print(" python -c \"import torch; print('PyTorch版本:', torch.__version__); print('CUDA可用:', torch.cuda.is_available()); import triton; print('triton版本:', triton.__version__)\"")
if __name__ == "__main__":
main()3.5 依赖安装流程可视化
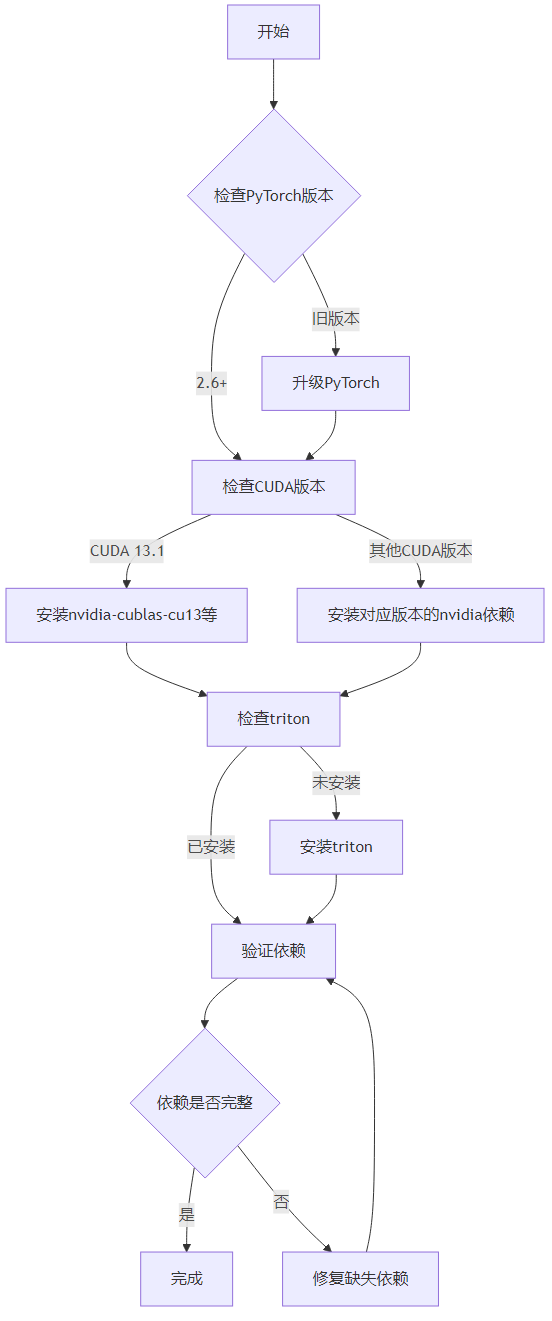
3.6 性能对比分析
3.6.1 有无triton的性能对比
# 性能对比测试代码
import torch
import time
# 检查triton是否可用
triton_available = False
try:
import triton
triton_available = True
print(f"triton版本: {triton.__version__}")
except ImportError:
print("triton未安装")
# 创建测试数据
batch_size = 1024
seq_len = 512
dim = 768
# 随机初始化张量
x = torch.randn(batch_size, seq_len, dim, device="cuda")
# 测试矩阵乘法性能
print("\n测试矩阵乘法性能...")
start_time = time.time()
for _ in range(100):
y = torch.matmul(x, x.transpose(1, 2))
torch.cuda.synchronize()
end_time = time.time()
print(f"矩阵乘法耗时: {end_time - start_time:.4f}秒")
# 测试激活函数性能
print("\n测试激活函数性能...")
start_time = time.time()
for _ in range(100):
y = torch.nn.functional.gelu(x)
torch.cuda.synchronize()
end_time = time.time()
print(f"激活函数耗时: {end_time - start_time:.4f}秒")
# 测试层归一化性能
print("\n测试层归一化性能...")
layer_norm = torch.nn.LayerNorm(dim).cuda()
start_time = time.time()
for _ in range(100):
y = layer_norm(x)
torch.cuda.synchronize()
end_time = time.time()
print(f"层归一化耗时: {end_time - start_time:.4f}秒")4. 与主流方案深度对比
解决方案 | 适用场景 | 实施难度 | 效果 | 维护成本 |
|---|---|---|---|---|
pip直接安装 | 快速部署 | 低 | 中 | 低 |
uv安装 | 性能优先 | 低 | 高 | 低 |
conda安装 | 环境管理 | 中 | 中 | 高 |
源码编译 | 定制需求 | 高 | 高 | 高 |
容器化部署 | 生产环境 | 中 | 高 | 中 |
5. 工程实践意义、风险与局限性
5.1 工程实践意义
- 确保PyTorch 2.6+的稳定运行,避免因依赖问题导致的错误
- 充分发挥PyTorch的性能优势,特别是在使用triton优化的场景
- 标准化依赖管理流程,便于团队协作和CI/CD集成
- 降低部署失败率,提高生产环境的可靠性
5.2 风险与局限性
- 不同操作系统可能需要不同的依赖安装方式
- 依赖版本快速迭代可能导致兼容性问题
- 部分老型号GPU可能无法充分利用新的依赖特性
- 依赖安装可能需要较大的存储空间
6. 未来趋势与前瞻预测
6.1 PyTorch依赖管理发展趋势
- 依赖自动管理将成为标准功能
- 包管理工具将更加智能,自动解决依赖冲突
- 硬件特定的优化将更加透明,减少用户配置负担
- 依赖版本锁定机制将更加完善
6.2 triton技术发展趋势
- triton将成为PyTorch的核心组件,提供更多优化
- 编程模型将更加友好,降低使用门槛
- 对更多硬件的支持将不断扩展
- 与其他优化技术的集成将更加紧密
6.3 nvidia生态系统发展趋势
- nvidia将提供更加统一的依赖管理方案
- 驱动和CUDA版本的管理将更加简化
- 硬件和软件的协同优化将成为重点
- 开源替代方案的竞争将促进生态系统的发展
参考链接:
- 主要来源:PyTorch官方文档 - PyTorch官方文档
- 辅助:NVIDIA CUDA官方文档 - NVIDIA CUDA官方文档
- 辅助:triton GitHub仓库 - OpenAI Triton库
附录(Appendix):
完整的依赖安装脚本
#!/bin/bash
# 检查当前环境
echo "=== 检查当前环境 ==="
python -c "import torch; print('PyTorch版本:', torch.__version__); print('CUDA版本:', torch.version.cuda); print('CUDA可用:', torch.cuda.is_available())"
# 安装nvidia依赖
echo "\n=== 安装nvidia依赖 ==="
pip install nvidia-cublas-cu13 nvidia-cuda-nvrtc-cu13 nvidia-cuda-runtime-cu13 nvidia-cudnn-cu13
# 安装triton
echo "\n=== 安装triton ==="
pip install triton
# 验证安装结果
echo "\n=== 验证安装结果 ==="
python -c "
import torch
print('PyTorch版本:', torch.__version__)
print('CUDA可用:', torch.cuda.is_available())
try:
import triton
print('triton版本:', triton.__version__)
print('triton可用:', True)
except ImportError:
print('triton未安装')
"
# 测试性能
echo "\n=== 测试性能 ==="
python -c "
import torch
import time
# 创建测试数据
x = torch.randn(1024, 1024, device='cuda')
# 测试矩阵乘法
start = time.time()
for _ in range(100):
y = torch.matmul(x, x)
torch.cuda.synchronize()
end = time.time()
print(f'矩阵乘法耗时: {end - start:.4f}秒')
"
echo "\n=== 安装完成 ==="关键词: PyTorch, nvidia依赖, triton, 依赖管理, 性能优化, CUDA, 深度学习, 2.6+版本
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-02-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号