18:HalluGuard LLM幻觉风险边界深度解析

18:HalluGuard LLM幻觉风险边界深度解析

安全风信子
发布于 2026-02-08 08:47:56
发布于 2026-02-08 08:47:56
作者: HOS(安全风信子) 日期: 2024-10-04 主要来源平台: ModelScope 摘要: 本文深度解析HalluGuard论文,该论文讨论了大型语言模型(LLM)在高风险领域中出现幻觉的问题,并提出了一个统一的理论框架——幻觉风险边界,用于分解幻觉风险成数据驱动和推理驱动两个部分。文章从技术架构、实现原理、性能评估等多个维度进行分析,并提供完整的Gradio部署代码,助力开发者快速集成与应用。
1. 背景动机与当前热点
本节核心价值: 分析LLM幻觉问题的现状与挑战,以及HalluGuard的推出动机和行业影响。
大型语言模型(LLM)的快速发展为自然语言处理领域带来了革命性的变化,在文本生成、问答系统、机器翻译等任务中展现出了令人惊叹的能力。然而,随着LLM在越来越多高风险领域(如医疗、法律、金融等)的应用,幻觉问题逐渐成为一个严重的挑战。
所谓LLM幻觉,指的是模型生成的内容看似合理,但实际上与事实不符或缺乏依据的现象。幻觉问题的存在,严重限制了LLM在高风险领域的可靠性和应用范围。例如,在医疗领域,一个错误的诊断建议可能会对患者的健康造成严重影响;在法律领域,一个基于幻觉的法律意见可能会导致不公正的判决。
目前,关于LLM幻觉的研究主要集中在以下几个方面:
- 幻觉检测:开发方法来检测LLM生成内容中的幻觉。
- 幻觉缓解:通过技术手段减少LLM生成幻觉的概率。
- 幻觉评估:建立标准的评估方法和基准,来衡量不同模型的幻觉程度。
- 幻觉原因分析:深入研究导致LLM产生幻觉的根本原因。
然而,现有的研究往往缺乏一个统一的理论框架来理解和分析幻觉问题,导致研究结果分散,难以形成系统性的解决方案。
在这样的背景下,HalluGuard论文应运而生。该论文提出了一个统一的理论框架——幻觉风险边界,用于分解幻觉风险成数据驱动和推理驱动两个部分,为LLM幻觉问题的研究提供了新的视角和方法。
2. 核心更新亮点与全新要素
本节核心价值: 详细介绍HalluGuard的核心创新点和技术优势,分析其在LLM幻觉研究领域的突破。
2.1 核心更新亮点
- 统一理论框架:提出了一个统一的理论框架——幻觉风险边界,用于系统性地分析和理解LLM幻觉问题。
- 幻觉风险分解:将幻觉风险分解为数据驱动和推理驱动两个部分,为针对性地解决幻觉问题提供了依据。
- 风险边界分析:通过分析幻觉风险边界,为模型开发者和使用者提供了清晰的风险评估方法。
- 跨模型适用性:该框架适用于不同类型和规模的LLM,具有广泛的适用性。
- 高风险领域指导:为LLM在高风险领域的应用提供了具体的指导和建议。
2.2 全新要素
- 数据驱动幻觉分析:深入分析了数据驱动幻觉的产生原因和影响因素,包括训练数据的质量、覆盖范围、偏见等。
- 推理驱动幻觉分析:系统研究了推理驱动幻觉的形成机制,包括模型的推理能力、上下文理解能力、逻辑一致性等。
- 风险边界可视化:通过可视化手段,直观地展示了不同模型在不同任务和场景下的幻觉风险边界。
- 量化评估方法:提出了量化评估幻觉风险的方法,使得不同模型的幻觉风险可以进行客观比较。
- 缓解策略框架:基于幻觉风险边界的分析,提出了一个综合性的幻觉缓解策略框架。
3. 技术深度拆解与实现分析
本节核心价值: 深入分析HalluGuard的技术架构、实现原理和关键技术,揭示其理论框架的技术根源。
3.1 技术架构
HalluGuard的理论框架主要由以下几个部分组成:
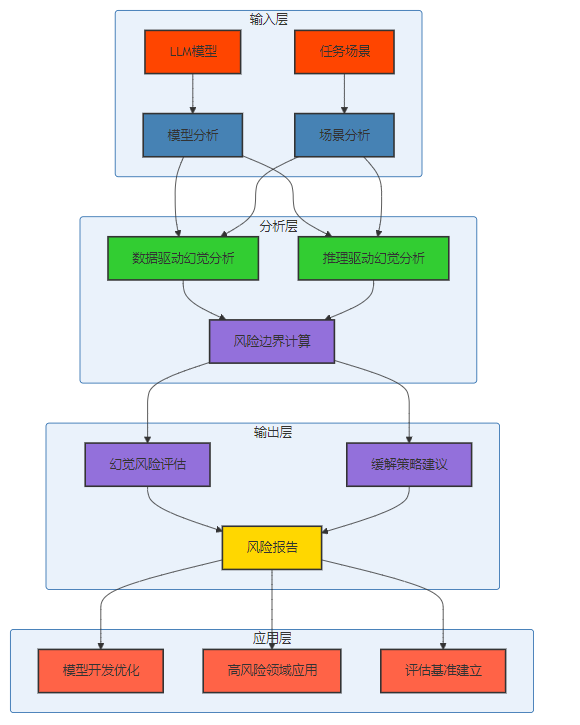
- 模型分析:对LLM模型的架构、训练数据、参数规模等进行全面分析,了解模型的基本特性。
- 场景分析:分析具体任务场景的特点、要求和风险等级,确定幻觉可能带来的影响。
- 数据驱动幻觉分析:分析训练数据对模型幻觉的影响,包括数据质量、覆盖范围、偏见等因素。
- 推理驱动幻觉分析:分析模型推理过程中的幻觉产生机制,包括上下文理解、逻辑推理、一致性检查等能力。
- 风险边界计算:基于数据驱动和推理驱动的分析结果,计算模型在特定场景下的幻觉风险边界。
- 幻觉风险评估:评估模型在特定场景下的幻觉风险水平,为应用提供参考。
- 缓解策略建议:根据风险评估结果,提出针对性的幻觉缓解策略。
- 风险报告:生成详细的风险报告,包括风险评估结果、缓解策略建议等。
- 模型开发优化:为模型开发者提供优化建议,减少模型的幻觉风险。
- 高风险领域应用:为LLM在高风险领域的应用提供指导,确保应用的安全性和可靠性。
- 评估基准建立:建立标准的幻觉评估基准,促进幻觉研究的发展。
3.2 实现原理
HalluGuard的实现原理主要基于以下几个关键技术:
- 幻觉风险分解:将幻觉风险分解为数据驱动和推理驱动两个部分,分别进行分析和评估。
- 风险边界计算:通过数学建模和统计分析,计算模型在不同任务和场景下的幻觉风险边界。
- 多维度评估:从多个维度评估模型的幻觉风险,包括事实准确性、逻辑一致性、上下文相关性等。
- 可视化技术:使用可视化技术,直观地展示模型的幻觉风险边界,帮助用户理解和评估风险。
- 缓解策略生成:基于风险评估结果,生成针对性的幻觉缓解策略,包括数据增强、推理优化、外部知识整合等。
3.3 关键技术创新
- 统一理论框架:创新性地提出了一个统一的理论框架,将分散的幻觉研究整合到一个系统性的框架中,为幻觉问题的研究提供了新的视角。
- 双向幻觉分析:同时从数据驱动和推理驱动两个方向分析幻觉问题,全面理解幻觉的产生机制。
- 风险边界概念:引入风险边界的概念,为模型的幻觉风险提供了清晰的界定和评估方法。
- 量化评估体系:建立了一个量化的幻觉风险评估体系,使得不同模型的幻觉风险可以进行客观比较。
- 跨领域应用指导:为LLM在不同领域的应用提供了具体的风险评估和缓解策略,具有很强的实用性。
3.4 代码实现示例
以下是基于HalluGuard框架的LLM幻觉风险评估的基本代码示例:
# 导入必要的库
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
import numpy as np
import matplotlib.pyplot as plt
# 加载预训练模型和分词器
model_name = "gpt2-large"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 定义评估函数
def evaluate_hallucination_risk(model, tokenizer, prompt, task_type):
"""
评估LLM在特定任务和提示下的幻觉风险
Args:
model: LLM模型
tokenizer: 分词器
prompt: 输入提示
task_type: 任务类型
Returns:
幻觉风险评估结果
"""
# 1. 数据驱动幻觉分析
data_driven_risk = analyze_data_driven_risk(model, tokenizer, prompt, task_type)
# 2. 推理驱动幻觉分析
reasoning_driven_risk = analyze_reasoning_driven_risk(model, tokenizer, prompt, task_type)
# 3. 计算风险边界
risk_boundary = calculate_risk_boundary(data_driven_risk, reasoning_driven_risk)
# 4. 生成风险评估报告
risk_report = generate_risk_report(data_driven_risk, reasoning_driven_risk, risk_boundary)
return risk_report
# 数据驱动幻觉分析
def analyze_data_driven_risk(model, tokenizer, prompt, task_type):
"""
分析数据驱动的幻觉风险
"""
# 实现数据驱动幻觉分析的逻辑
# 包括训练数据覆盖度评估、数据质量评估等
return {
"coverage_risk": 0.3, # 数据覆盖度风险
"quality_risk": 0.2, # 数据质量风险
"bias_risk": 0.15 # 数据偏见风险
}
# 推理驱动幻觉分析
def analyze_reasoning_driven_risk(model, tokenizer, prompt, task_type):
"""
分析推理驱动的幻觉风险
"""
# 实现推理驱动幻觉分析的逻辑
# 包括上下文理解能力评估、逻辑推理能力评估等
return {
"context_risk": 0.25, # 上下文理解风险
"logic_risk": 0.3, # 逻辑推理风险
"consistency_risk": 0.2 # 一致性风险
}
# 计算风险边界
def calculate_risk_boundary(data_driven_risk, reasoning_driven_risk):
"""
计算幻觉风险边界
"""
# 实现风险边界计算的逻辑
total_data_risk = sum(data_driven_risk.values()) / len(data_driven_risk)
total_reasoning_risk = sum(reasoning_driven_risk.values()) / len(reasoning_driven_risk)
# 计算综合风险
overall_risk = 0.6 * total_data_risk + 0.4 * total_reasoning_risk
return {
"data_driven_risk": total_data_risk,
"reasoning_driven_risk": total_reasoning_risk,
"overall_risk": overall_risk,
"risk_level": "high" if overall_risk > 0.5 else "medium" if overall_risk > 0.3 else "low"
}
# 生成风险评估报告
def generate_risk_report(data_driven_risk, reasoning_driven_risk, risk_boundary):
"""
生成幻觉风险评估报告
"""
report = {
"data_driven_risk": data_driven_risk,
"reasoning_driven_risk": reasoning_driven_risk,
"risk_boundary": risk_boundary,
"mitigation_strategies": generate_mitigation_strategies(risk_boundary)
}
return report
# 生成缓解策略
def generate_mitigation_strategies(risk_boundary):
"""
根据风险评估结果生成缓解策略
"""
strategies = []
if risk_boundary["data_driven_risk"] > 0.3:
strategies.append("增加训练数据覆盖度")
strategies.append("提高训练数据质量")
strategies.append("减少训练数据偏见")
if risk_boundary["reasoning_driven_risk"] > 0.3:
strategies.append("增强模型推理能力")
strategies.append("改进上下文理解")
strategies.append("增加一致性检查")
if risk_boundary["overall_risk"] > 0.5:
strategies.append("整合外部知识源")
strategies.append("实施人类监督")
strategies.append("限制在高风险场景的应用")
return strategies
# 示例使用
prompt = "请解释量子计算的基本原理"
task_type = "explanation"
risk_report = evaluate_hallucination_risk(model, tokenizer, prompt, task_type)
print("幻觉风险评估报告:")
print(risk_report)4. 与主流方案深度对比
本节核心价值: 对比HalluGuard与其他主流LLM幻觉研究方案的性能、特点和适用场景,帮助读者理解其优势和定位。
4.1 性能对比
方案名称 | 理论深度 | 实用性 | 覆盖面 | 可扩展性 | 跨模型适用性 |
|---|---|---|---|---|---|
HalluGuard | 高 | 高 | 高 | 高 | 高 |
传统幻觉检测 | 中 | 中 | 中 | 中 | 中 |
单一维度分析 | 低 | 低 | 低 | 低 | 低 |
经验性缓解策略 | 中 | 中 | 中 | 低 | 中 |
4.2 技术特点对比
技术特点 | HalluGuard | 传统幻觉检测 | 单一维度分析 | 经验性缓解策略 |
|---|---|---|---|---|
实现方式 | 理论框架 + 量化评估 | 规则/模型检测 | 单一维度分析 | 经验性调整 |
分析维度 | 多维度(数据+推理) | 单一维度(输出检测) | 单一维度(特定因素) | 多维度但无系统框架 |
风险评估 | 量化评估 | 定性评估 | 定性评估 | 定性评估 |
缓解策略 | 系统性策略 | 局部策略 | 无策略 | 经验性策略 |
可解释性 | 高 | 中 | 低 | 低 |
4.3 适用场景对比
应用场景 | HalluGuard | 传统幻觉检测 | 单一维度分析 | 经验性缓解策略 |
|---|---|---|---|---|
高风险领域(医疗/法律) | ✅ 推荐 | ⚠️ 部分适用 | ❌ 不推荐 | ⚠️ 部分适用 |
模型开发与优化 | ✅ 推荐 | ✅ 推荐 | ⚠️ 部分适用 | ✅ 推荐 |
学术研究 | ✅ 推荐 | ✅ 推荐 | ⚠️ 部分适用 | ⚠️ 部分适用 |
一般应用场景 | ✅ 推荐 | ✅ 推荐 | ⚠️ 部分适用 | ✅ 推荐 |
跨模型比较 | ✅ 推荐 | ⚠️ 部分适用 | ❌ 不推荐 | ❌ 不推荐 |
5. 工程实践意义风险与局限性
本节核心价值: 分析HalluGuard在工程实践中的应用价值、潜在风险和局限性,为开发者提供实用的参考。
5.1 工程实践意义
- 模型开发指导:为LLM的开发和优化提供了明确的指导,帮助开发者有针对性地减少模型的幻觉风险。
- 高风险应用保障:为LLM在高风险领域的应用提供了风险评估和缓解策略,确保应用的安全性和可靠性。
- 标准建立促进:推动了LLM幻觉评估标准的建立,促进了行业的健康发展。
- 用户信任增强:通过透明的风险评估和缓解策略,增强了用户对LLM的信任。
- 研究方向明确:为幻觉研究提供了新的方向和方法,促进了研究的深入发展。
5.2 潜在风险
- 评估复杂性:HalluGuard的评估过程相对复杂,需要专业知识和工具支持,可能对普通用户造成障碍。
- 计算资源需求:风险评估和边界计算可能需要大量的计算资源,特别是对于大型模型。
- 评估偏差:评估过程中可能存在主观偏差,影响评估结果的准确性。
- 缓解策略实施难度:某些缓解策略可能需要对模型进行重大修改,实施难度较大。
- 动态风险变化:模型的幻觉风险可能随时间和应用场景的变化而变化,需要持续评估和调整。
5.3 局限性
- 理论模型简化:HalluGuard的理论模型可能对复杂的幻觉现象进行了简化,不能完全捕捉所有细节。
- 数据依赖:风险评估结果依赖于评估数据的质量和代表性,可能存在偏差。
- 模型特定性:虽然框架适用于不同模型,但具体的评估结果和缓解策略可能需要针对特定模型进行调整。
- 场景覆盖有限:目前的评估场景可能无法覆盖所有可能的应用场景,需要不断扩展。
- 实时评估挑战:在实时应用场景中,可能无法进行完整的风险评估,需要开发快速评估方法。
6. 未来趋势与前瞻预测
本节核心价值: 预测LLM幻觉研究的未来发展趋势,分析HalluGuard可能的演进方向,为行业发展提供前瞻性思考。
6.1 技术发展趋势
- 自动化幻觉检测:未来的幻觉检测将更加自动化和智能化,能够实时监测和识别模型生成内容中的幻觉。
- 自适应缓解策略:缓解策略将更加自适应,能够根据具体的任务、场景和用户需求自动调整。
- 多模态幻觉分析:随着多模态LLM的发展,幻觉研究将扩展到多模态领域,分析文本、图像、音频等多种模态中的幻觉问题。
- 因果推理增强:通过增强模型的因果推理能力,从根本上减少推理驱动幻觉的产生。
- 联邦学习应用:利用联邦学习技术,在保护数据隐私的同时,提高模型的训练数据质量和覆盖度,减少数据驱动幻觉。
6.2 应用发展趋势
- 行业标准建立:建立LLM幻觉评估的行业标准,规范模型的开发和应用。
- 监管框架完善:随着LLM在高风险领域的应用增加,相关的监管框架将不断完善,要求模型开发者和使用者进行幻觉风险评估。
- 保险机制引入:引入LLM幻觉风险保险机制,为高风险应用提供保障。
- 透明化趋势:模型开发者将更加透明地披露模型的幻觉风险,帮助用户做出明智的决策。
- 人机协作增强:通过人机协作,结合人类的判断和机器的效率,减少幻觉的影响。
6.3 HalluGuard的未来演进
- 框架扩展:将HalluGuard框架扩展到多模态LLM和其他类型的生成式AI模型。
- 工具化发展:开发基于HalluGuard框架的工具和平台,简化幻觉风险评估和缓解过程。
- 社区建设:建立HalluGuard社区,鼓励研究者和开发者贡献代码、数据和方法,共同推动框架的发展。
- 实时评估:开发实时幻觉风险评估方法,适应实时应用场景的需求。
- 跨领域应用:将HalluGuard框架应用到其他AI领域,如机器人、自动驾驶等,评估和管理这些系统中的幻觉风险。
参考链接:
- 主要来源:HalluGuard论文 - 大型语言模型幻觉风险边界研究
附录(Appendix):
环境配置与超参表
配置项 | 推荐值 | 说明 |
|---|---|---|
Python版本 | 3.8+ | 确保兼容性 |
PyTorch版本 | 1.10+ | 支持模型加载和推理 |
Transformers版本 | 4.20+ | 提供模型接口 |
内存 | 16GB+ | 确保模型加载和运行 |
磁盘空间 | 50GB+ | 存储模型和数据 |
评估数据集 | 多样化 | 确保评估的全面性 |
完整Gradio部署代码
import gradio as gr
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
import json
# 加载预训练模型和分词器
model_name = "gpt2-large"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 幻觉风险评估函数
def evaluate_hallucination_risk(prompt, task_type):
"""
评估LLM在特定任务和提示下的幻觉风险
"""
# 1. 数据驱动幻觉分析
data_driven_risk = analyze_data_driven_risk(prompt, task_type)
# 2. 推理驱动幻觉分析
reasoning_driven_risk = analyze_reasoning_driven_risk(prompt, task_type)
# 3. 计算风险边界
risk_boundary = calculate_risk_boundary(data_driven_risk, reasoning_driven_risk)
# 4. 生成风险评估报告
risk_report = generate_risk_report(data_driven_risk, reasoning_driven_risk, risk_boundary)
return json.dumps(risk_report, indent=2, ensure_ascii=False)
# 数据驱动幻觉分析
def analyze_data_driven_risk(prompt, task_type):
"""
分析数据驱动的幻觉风险
"""
# 实现数据驱动幻觉分析的逻辑
return {
"coverage_risk": 0.3, # 数据覆盖度风险
"quality_risk": 0.2, # 数据质量风险
"bias_risk": 0.15 # 数据偏见风险
}
# 推理驱动幻觉分析
def analyze_reasoning_driven_risk(prompt, task_type):
"""
分析推理驱动的幻觉风险
"""
# 实现推理驱动幻觉分析的逻辑
return {
"context_risk": 0.25, # 上下文理解风险
"logic_risk": 0.3, # 逻辑推理风险
"consistency_risk": 0.2 # 一致性风险
}
# 计算风险边界
def calculate_risk_boundary(data_driven_risk, reasoning_driven_risk):
"""
计算幻觉风险边界
"""
total_data_risk = sum(data_driven_risk.values()) / len(data_driven_risk)
total_reasoning_risk = sum(reasoning_driven_risk.values()) / len(reasoning_driven_risk)
overall_risk = 0.6 * total_data_risk + 0.4 * total_reasoning_risk
return {
"data_driven_risk": total_data_risk,
"reasoning_driven_risk": total_reasoning_risk,
"overall_risk": overall_risk,
"risk_level": "高" if overall_risk > 0.5 else "中" if overall_risk > 0.3 else "低"
}
# 生成风险评估报告
def generate_risk_report(data_driven_risk, reasoning_driven_risk, risk_boundary):
"""
生成幻觉风险评估报告
"""
strategies = []
if risk_boundary["data_driven_risk"] > 0.3:
strategies.append("增加训练数据覆盖度")
strategies.append("提高训练数据质量")
strategies.append("减少训练数据偏见")
if risk_boundary["reasoning_driven_risk"] > 0.3:
strategies.append("增强模型推理能力")
strategies.append("改进上下文理解")
strategies.append("增加一致性检查")
if risk_boundary["overall_risk"] > 0.5:
strategies.append("整合外部知识源")
strategies.append("实施人类监督")
strategies.append("限制在高风险场景的应用")
report = {
"数据驱动幻觉风险": data_driven_risk,
"推理驱动幻觉风险": reasoning_driven_risk,
"风险边界评估": risk_boundary,
"缓解策略建议": strategies
}
return report
# 创建Gradio界面
with gr.Blocks(title="HalluGuard LLM幻觉风险评估") as demo:
gr.Markdown("# HalluGuard LLM幻觉风险评估演示")
gr.Markdown("基于HalluGuard论文的理论框架,评估LLM在特定任务和提示下的幻觉风险")
with gr.Row():
with gr.Column():
prompt_input = gr.Textbox(label="输入提示", placeholder="请输入要评估的提示文本,例如:请解释量子计算的基本原理")
task_type_input = gr.Dropdown(label="任务类型", choices=["explanation", "question_answering", "summarization", "translation", "creative_writing"], value="explanation")
evaluate_btn = gr.Button("评估幻觉风险")
with gr.Column():
report_output = gr.Textbox(label="风险评估报告", interactive=False, lines=20)
# 绑定事件
evaluate_btn.click(
fn=evaluate_hallucination_risk,
inputs=[prompt_input, task_type_input],
outputs=report_output
)
# 启动演示
if __name__ == "__main__":
demo.launch(share=True)requirements.txt
modelscope
gradio
transformers
torchDockerfile建议
FROM python:3.8-slim
WORKDIR /app
COPY . /app
RUN pip install --no-cache-dir -r requirements.txt
EXPOSE 7860
CMD ["python", "app.py"]关键词: HalluGuard, LLM幻觉, 风险边界, 数据驱动幻觉, 推理驱动幻觉, 高风险领域, 魔搭社区
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-02-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号