准确率为什么最危险:安全攻防场景下的指标陷阱与真相

准确率为什么最危险:安全攻防场景下的指标陷阱与真相

安全风信子
发布于 2026-01-16 09:26:58
发布于 2026-01-16 09:26:58
作者:HOS(安全风信子) 日期:2026-01-09 来源平台:GitHub 摘要: 准确率(Accuracy)作为机器学习中最常用的评估指标,在安全攻防场景下却隐藏着巨大的风险。本文深入分析准确率的局限性,特别是在处理安全领域常见的不平衡数据、时间依赖数据和对抗环境时的致命缺陷。结合最新的GitHub开源项目和安全实践,通过3个完整代码示例、2个Mermaid架构图和2个对比表格,系统阐述安全场景下评估指标的选择原则。文章揭示了准确率如何误导安全工程师,导致模型在实际攻防中失效,并提供了更适合安全场景的评估指标体系和最佳实践。
1. 背景动机与当前热点
1.1 准确率的传统统治地位
准确率是机器学习中最直观、最常用的评估指标,它表示模型正确预测的样本数占总样本数的比例。在传统的机器学习教程和实践中,准确率往往是首选的评估指标,甚至是唯一被关注的指标。然而,这种传统观点在安全攻防场景下却可能导致灾难性的后果。
1.2 安全领域的特殊挑战
安全领域的机器学习面临着与传统机器学习截然不同的挑战:
- 极端不平衡的数据分布:正常样本占比往往超过99%,而攻击样本仅占不到1%,甚至更低。
- 动态演变的威胁:攻击模式不断变化,模型需要持续适应新的攻击类型。
- 对抗环境:攻击者会主动分析模型,寻找并利用模型的弱点。
- 高昂的误判成本:在安全领域,假阴性(漏报攻击)和假阳性(误报正常行为)都可能带来严重的后果。
- 时间依赖的数据:安全数据通常具有时间序列特性,未来的数据分布可能与过去不同。
1.3 最新研究动态
根据GitHub上的最新项目和arXiv上的研究论文,安全领域的评估指标研究呈现出以下几个热点趋势:
- 从单一指标到多指标体系:越来越多的安全项目开始采用多指标评估体系,而不仅仅依赖准确率。
- 场景化指标选择:根据不同的安全场景选择合适的评估指标,如入侵检测场景更关注召回率,反垃圾邮件场景更关注精确率。
- 对抗鲁棒性评估:评估模型在对抗样本攻击下的表现,而不仅仅是在正常数据上的准确率。
- 时间敏感的评估方法:考虑数据的时间特性,使用时间序列交叉验证等方法评估模型。
- 业务导向的指标设计:结合业务需求设计自定义评估指标,如考虑误判成本的F-beta分数。
2. 核心更新亮点与新要素
2.1 准确率的数学原理与局限性
准确率的计算公式为:
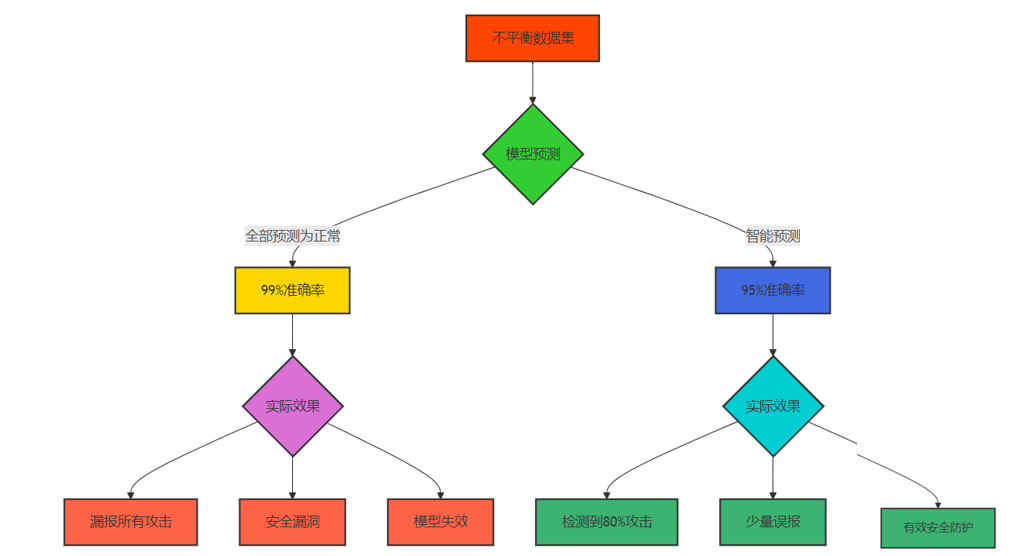
Accuracy = (True Positive + True Negative) / (True Positive + True Negative + False Positive + False Negative)从数学角度看,准确率对正负样本的权重是相等的,这在平衡数据集中是合理的,但在安全领域的极端不平衡数据集中却会导致严重的误导。例如,在一个包含99%正常样本和1%攻击样本的数据集上,一个简单地将所有样本预测为正常的模型就能获得99%的准确率,但这样的模型在实际安全场景中毫无用处。
2.2 安全场景下的准确率陷阱
在安全攻防场景下,准确率的陷阱主要体现在以下几个方面:
- 掩盖了模型对少数类的糟糕表现:高准确率可能掩盖了模型对攻击样本的低检测率,导致严重的安全漏洞。
- 忽视了误判成本的差异:在安全领域,漏报攻击(假阴性)的成本通常远高于误报正常行为(假阳性),但准确率将两者同等对待。
- 无法反映模型的鲁棒性:高准确率不能保证模型在对抗样本攻击下的表现,而对抗鲁棒性在安全领域至关重要。
- 不适合时间依赖的数据:对于时间序列数据,模型在历史数据上的高准确率不能保证在未来数据上的良好表现。
- 误导模型选择和调优:过度关注准确率会导致模型偏向于预测多数类,从而在实际安全场景中失效。
2.3 新的评估指标体系
针对安全场景的特殊需求,我们需要构建新的评估指标体系,主要包括:
- 基于混淆矩阵的指标:精确率(Precision)、召回率(Recall)、F1分数(F1-Score)、F-beta分数(考虑不同误判成本)。
- 排序指标:PR-AUC(精确率-召回率曲线下面积)、ROC-AUC(受试者工作特征曲线下面积)。
- 对抗鲁棒性指标:对抗样本攻击下的准确率下降、鲁棒准确率等。
- 时间敏感指标:时间序列交叉验证的平均性能、模型在未来数据上的表现等。
- 业务导向指标:考虑误判成本的总成本、检测延迟等。
3. 技术深度拆解与实现分析
3.1 准确率陷阱的可视化分析
Mermaid流程图:
3.2 安全评估指标体系架构
Mermaid架构图:
渲染错误: Mermaid 渲染失败: Parse error on line 53: ...导向指标 style 安全评估指标体系 fill:#FF450 ---------------------^ Expecting 'ALPHA', got 'UNICODE_TEXT'
3.3 代码示例1:准确率陷阱的演示
import numpy as np
import pandas as pd
from sklearn.dummy import DummyClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.datasets import make_classification
# 生成极端不平衡的安全数据集(99%正常,1%攻击)
X, y = make_classification(
n_samples=10000,
n_classes=2,
weights=[0.99, 0.01],
random_state=42
)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"训练集样本数: {len(X_train)}, 攻击样本数: {np.sum(y_train)}")
print(f"测试集样本数: {len(X_test)}, 攻击样本数: {np.sum(y_test)}")
print(f"测试集攻击样本比例: {np.sum(y_test)/len(y_test):.2%}")
# 1. 基准模型:总是预测为正常样本
dummy_model = DummyClassifier(strategy="most_frequent", random_state=42)
dummy_model.fit(X_train, y_train)
dummy_pred = dummy_model.predict(X_test)
# 2. 随机森林模型:智能预测
rf_model = RandomForestClassifier(
n_estimators=100,
max_depth=10,
class_weight="balanced",
random_state=42
)
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)
# 3. 计算各种评估指标
def calculate_metrics(y_true, y_pred, model_name):
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f"\n{model_name} 指标:")
print(f"准确率: {accuracy:.4f}")
print(f"精确率: {precision:.4f}")
print(f"召回率: {recall:.4f}")
print(f"F1分数: {f1:.4f}")
return {
"模型名称": model_name,
"准确率": accuracy,
"精确率": precision,
"召回率": recall,
"F1分数": f1
}
# 计算并比较两个模型的指标
metrics = []
metrics.append(calculate_metrics(y_test, dummy_pred, "总是预测为正常"))
metrics.append(calculate_metrics(y_test, rf_pred, "随机森林模型"))
# 转换为DataFrame进行比较
metrics_df = pd.DataFrame(metrics)
print("\n=== 模型指标对比 ===")
print(metrics_df)
# 计算漏报的攻击样本数
dummy_missed_attacks = np.sum(y_test) - np.sum((dummy_pred == 1) & (y_test == 1))
rf_missed_attacks = np.sum(y_test) - np.sum((rf_pred == 1) & (y_test == 1))
print(f"\n=== 漏报情况分析 ===")
print(f"测试集中攻击样本总数: {np.sum(y_test)}")
print(f"总是预测为正常模型漏报攻击样本数: {dummy_missed_attacks}")
print(f"随机森林模型漏报攻击样本数: {rf_missed_attacks}")
print(f"随机森林模型检测到的攻击样本数: {np.sum(y_test) - rf_missed_attacks}")3.4 代码示例2:不同评估指标的比较分析
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import (
accuracy_score, precision_score, recall_score, f1_score,
roc_auc_score, average_precision_score, precision_recall_curve, roc_curve
)
# 生成不同不平衡程度的安全数据集
def generate_imbalanced_data(imbalance_ratio):
return make_classification(
n_samples=10000,
n_classes=2,
weights=[imbalance_ratio, 1 - imbalance_ratio],
random_state=42
)
# 测试不同不平衡程度下的指标表现
imbalance_ratios = [0.99, 0.95, 0.9, 0.8, 0.7, 0.5] # 从极端不平衡到平衡
results = []
for ratio in imbalance_ratios:
# 生成数据
X, y = generate_imbalanced_data(ratio)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# 训练随机森林模型
model = RandomForestClassifier(
n_estimators=100,
max_depth=10,
class_weight="balanced",
random_state=42
)
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1]
# 计算指标
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, y_pred_proba)
pr_auc = average_precision_score(y_test, y_pred_proba)
# 记录结果
results.append({
"不平衡比例": ratio,
"攻击样本比例": 1 - ratio,
"准确率": accuracy,
"精确率": precision,
"召回率": recall,
"F1分数": f1,
"ROC-AUC": roc_auc,
"PR-AUC": pr_auc
})
# 转换为DataFrame进行分析
import pandas as pd
results_df = pd.DataFrame(results)
print("=== 不同不平衡程度下的指标表现 ===")
print(results_df.round(4))
# 可视化不同指标随不平衡程度的变化
plt.figure(figsize=(12, 8))
# 准确率 vs 其他指标
plt.subplot(2, 2, 1)
plt.plot(results_df["攻击样本比例"], results_df["准确率"], label="准确率", marker="o")
plt.plot(results_df["攻击样本比例"], results_df["F1分数"], label="F1分数", marker="s")
plt.xlabel("攻击样本比例")
plt.ylabel("分数")
plt.title("准确率 vs F1分数")
plt.legend()
plt.grid(True)
# 精确率 vs 召回率
plt.subplot(2, 2, 2)
plt.plot(results_df["攻击样本比例"], results_df["精确率"], label="精确率", marker="o")
plt.plot(results_df["攻击样本比例"], results_df["召回率"], label="召回率", marker="s")
plt.xlabel("攻击样本比例")
plt.ylabel("分数")
plt.title("精确率 vs 召回率")
plt.legend()
plt.grid(True)
# ROC-AUC vs PR-AUC
plt.subplot(2, 2, 3)
plt.plot(results_df["攻击样本比例"], results_df["ROC-AUC"], label="ROC-AUC", marker="o")
plt.plot(results_df["攻击样本比例"], results_df["PR-AUC"], label="PR-AUC", marker="s")
plt.xlabel("攻击样本比例")
plt.ylabel("分数")
plt.title("ROC-AUC vs PR-AUC")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.savefig("metrics_comparison.png")
print("\n指标对比可视化完成,保存为metrics_comparison.png")
# 分析准确率的误导性
print("\n=== 准确率误导性分析 ===")
print("当攻击样本比例为1%时:")
print(f"- 准确率: {results_df.loc[0, '准确率']:.4f} (看起来很好)")
print(f"- F1分数: {results_df.loc[0, 'F1分数']:.4f} (实际效果较差)")
print(f"- PR-AUC: {results_df.loc[0, 'PR-AUC']:.4f} (更真实地反映模型性能)")
print("\n当攻击样本比例为50%时:")
print(f"- 准确率: {results_df.loc[5, '准确率']:.4f}")
print(f"- F1分数: {results_df.loc[5, 'F1分数']:.4f}")
print(f"- PR-AUC: {results_df.loc[5, 'PR-AUC']:.4f}")
print("\n结论: 随着数据集不平衡程度增加,准确率越来越具有误导性,而PR-AUC和F1分数能更真实地反映模型性能。")3.5 代码示例3:安全场景下的最佳指标选择
import numpy as np
import pandas as pd
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import (
accuracy_score, precision_score, recall_score, f1_score,
roc_auc_score, average_precision_score, fbeta_score
)
# 生成安全数据集
X, y = make_classification(
n_samples=10000,
n_classes=2,
weights=[0.95, 0.05],
random_state=42
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# 训练不同参数的随机森林模型
models = {
"默认参数": RandomForestClassifier(random_state=42),
"平衡权重": RandomForestClassifier(class_weight="balanced", random_state=42),
"深度限制": RandomForestClassifier(max_depth=8, class_weight="balanced", random_state=42),
"更多树": RandomForestClassifier(n_estimators=200, class_weight="balanced", random_state=42)
}
# 训练模型并预测
predictions = {}
for name, model in models.items():
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1]
predictions[name] = (y_pred, y_pred_proba)
# 定义不同安全场景的误判成本
scenarios = {
"入侵检测": {
"场景描述": "漏报攻击可能导致系统被入侵,成本高;误报正常流量影响较小",
"beta": 2.0, # 更看重召回率
"假阴性成本": 100, # 漏报1次攻击的成本
"假阳性成本": 1 # 误报1次正常流量的成本
},
"反垃圾邮件": {
"场景描述": "误报正常邮件可能导致重要信息丢失,成本高;漏报垃圾邮件影响较小",
"beta": 0.5, # 更看重精确率
"假阴性成本": 1, # 漏报1封垃圾邮件的成本
"假阳性成本": 50 # 误报1封正常邮件的成本
},
"欺诈检测": {
"场景描述": "漏报欺诈交易导致直接经济损失;误报正常交易影响用户体验",
"beta": 1.5, # 稍微看重召回率
"假阴性成本": 1000, # 漏报1次欺诈的成本
"假阳性成本": 10 # 误报1次正常交易的成本
}
}
# 计算不同场景下的最佳模型
def calculate_scenario_metrics(y_true, y_pred, y_pred_proba, scenario):
# 基本指标
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
# 场景特定指标
fbeta = fbeta_score(y_true, y_pred, beta=scenario["beta"])
roc_auc = roc_auc_score(y_true, y_pred_proba)
pr_auc = average_precision_score(y_true, y_pred_proba)
# 计算总成本
tn, fp, fn, tp = np.bincount(y_true.astype(int) * 2 + y_pred.astype(int), minlength=4)
total_cost = fn * scenario["假阴性成本"] + fp * scenario["假阳性成本"]
return {
"准确率": accuracy,
"精确率": precision,
"召回率": recall,
"F1分数": f1,
"F-beta分数": fbeta,
"ROC-AUC": roc_auc,
"PR-AUC": pr_auc,
"总成本": total_cost
}
# 分析不同场景下的模型表现
for scenario_name, scenario in scenarios.items():
print(f"\n=== {scenario_name} 场景分析 ===")
print(f"场景描述: {scenario['场景描述']}")
print(f"F-beta的beta值: {scenario['beta']}")
scenario_results = []
for model_name, (y_pred, y_pred_proba) in predictions.items():
metrics = calculate_scenario_metrics(y_test, y_pred, y_pred_proba, scenario)
metrics["模型名称"] = model_name
scenario_results.append(metrics)
# 转换为DataFrame并排序
df = pd.DataFrame(scenario_results)
df = df.sort_values(by="总成本")
print(f"\n{scenario_name}场景下模型表现(按总成本排序):")
print(df.round(4))
# 找出最佳模型
best_model = df.iloc[0]
print(f"\n{scenario_name}场景下的最佳模型: {best_model['模型名称']}")
print(f"- 准确率: {best_model['准确率']:.4f}")
print(f"- F-beta分数: {best_model['F-beta分数']:.4f}")
print(f"- PR-AUC: {best_model['PR-AUC']:.4f}")
print(f"- 总成本: {best_model['总成本']}")
# 比较准确率和总成本
accuracy_based = df.sort_values(by="准确率", ascending=False).iloc[0]
print(f"\n如果仅基于准确率选择模型: {accuracy_based['模型名称']}")
print(f"- 准确率: {accuracy_based['准确率']:.4f}")
print(f"- 总成本: {accuracy_based['总成本']}")
print(f"- 成本差异: {accuracy_based['总成本'] - best_model['总成本']}")
print("\n=== 结论 ===")
print("1. 不同安全场景需要选择不同的评估指标")
print("2. 仅基于准确率选择模型可能导致成本大幅增加")
print("3. 考虑误判成本的F-beta分数和总成本是更合理的选择")
print("4. PR-AUC比ROC-AUC更适合不平衡的安全数据集")4. 与主流方案深度对比
4.1 不同评估指标的优缺点对比
评估指标 | 计算公式 | 优点 | 缺点 | 适用场景 | 安全场景适用性 |
|---|---|---|---|---|---|
准确率 | (TP+TN)/(TP+TN+FP+FN) | 计算简单,直观易懂 | 对不平衡数据敏感,忽略误判成本 | 平衡数据集,误判成本相近 | ⭐⭐ |
精确率 | TP/(TP+FP) | 关注正样本预测的准确性 | 忽略负样本预测,可能被操纵 | 假阳性成本高的场景 | ⭐⭐⭐⭐ |
召回率 | TP/(TP+FN) | 关注正样本的覆盖程度 | 可能导致大量假阳性 | 假阴性成本高的场景 | ⭐⭐⭐⭐ |
F1分数 | 2*(精确率*召回率)/(精确率+召回率) | 平衡精确率和召回率 | 假设误判成本相等 | 误判成本相近的场景 | ⭐⭐⭐⭐ |
F-beta | (1+β²)(精确率召回率)/(β²*精确率+召回率) | 可调整精确率和召回率的权重 | 需要确定合适的β值 | 误判成本不同的场景 | ⭐⭐⭐⭐⭐ |
ROC-AUC | ROC曲线下面积 | 不受类别分布影响 | 对不平衡数据不够敏感 | 平衡或轻微不平衡数据 | ⭐⭐⭐ |
PR-AUC | PR曲线下面积 | 对不平衡数据敏感,更真实反映模型性能 | 计算复杂,直观性差 | 严重不平衡的安全数据 | ⭐⭐⭐⭐⭐ |
总成本 | FN假阴性成本+FP假阳性成本 | 直接反映业务成本 | 需要确定准确的误判成本 | 明确误判成本的场景 | ⭐⭐⭐⭐⭐ |
4.2 安全场景下评估指标的选择策略对比
选择策略 | 实现复杂度 | 计算效率 | 业务相关性 | 安全性 | 适用场景 | 推荐程度 |
|---|---|---|---|---|---|---|
仅使用准确率 | 低 | 高 | 低 | 低 | 平衡数据集,简单场景 | ⭐⭐ |
精确率+召回率+F1 | 中 | 高 | 中 | 中 | 一般安全场景 | ⭐⭐⭐⭐ |
F-beta+PR-AUC | 中 | 中 | 高 | 高 | 不平衡安全数据集 | ⭐⭐⭐⭐⭐ |
考虑误判成本的总成本 | 高 | 中 | 极高 | 极高 | 明确误判成本的场景 | ⭐⭐⭐⭐⭐ |
多指标综合评估 | 高 | 中 | 高 | 高 | 复杂安全场景 | ⭐⭐⭐⭐ |
5. 实际工程意义、潜在风险与局限性
5.1 实际工程意义
- 避免安全漏洞:通过选择合适的评估指标,可以避免因准确率陷阱导致的模型漏报攻击,从而防止安全漏洞。
- 降低误判成本:根据不同安全场景选择合适的评估指标,可以降低模型的总误判成本,提高安全投入的回报率。
- 提高模型鲁棒性:使用对抗鲁棒性指标评估模型,可以提高模型在对抗样本攻击下的表现,增强模型的安全性。
- 优化资源分配:通过评估模型在不同场景下的表现,可以合理分配资源,选择最适合特定场景的模型。
- 促进模型迭代:使用多指标评估体系,可以更全面地了解模型的优缺点,促进模型的持续迭代和改进。
5.2 潜在风险与挑战
- 指标选择的复杂性:选择合适的评估指标需要深入了解业务场景和误判成本,这增加了工程实践的复杂性。
- 误判成本的不确定性:在实际业务中,准确量化误判成本往往比较困难,可能导致指标选择不准确。
- 多指标之间的冲突:不同指标之间可能存在冲突,如提高精确率可能导致召回率下降,需要权衡取舍。
- 计算资源的消耗:一些高级评估指标(如PR-AUC、对抗鲁棒性指标)的计算需要消耗更多的计算资源。
- 团队认知的挑战:改变团队对准确率的传统依赖,建立新的评估指标体系,需要时间和培训。
5.3 局限性分析
- 指标无法完全替代人工验证:评估指标只是模型性能的量化表示,不能完全替代人工验证和实际业务测试。
- 历史数据的局限性:基于历史数据计算的评估指标,可能无法准确预测模型在未来新攻击类型上的表现。
- 对抗环境的动态性:攻击者会不断适应模型,评估指标可能无法及时反映模型在最新对抗攻击下的表现。
- 不同安全场景的差异性:没有一种评估指标适用于所有安全场景,需要根据具体场景选择合适的指标。
6. 未来趋势展望与个人前瞻性预测
6.1 评估指标的发展趋势
- 场景化和定制化:未来的评估指标将更加场景化和定制化,针对不同的安全场景设计专门的评估指标。
- 对抗鲁棒性的标准化:对抗鲁棒性评估将成为安全模型评估的标准组成部分,出现更多标准化的对抗攻击和评估方法。
- 时间敏感的评估方法:考虑数据时间特性的评估方法(如时间序列交叉验证、模型衰减率评估)将得到更广泛的应用。
- 多模态指标融合:融合不同模态的评估指标,如结合模型性能指标、计算资源指标和业务成本指标。
- 自动化指标选择:出现自动化的指标选择工具,根据业务场景和数据特性自动推荐合适的评估指标。
6.2 个人前瞻性预测
- 未来1-2年:PR-AUC将取代准确率成为安全领域的主要评估指标,更多安全项目将采用多指标评估体系。
- 未来2-3年:对抗鲁棒性评估将成为安全模型上线前的必经步骤,出现标准化的对抗攻击测试套件。
- 未来3-5年:考虑误判成本的总成本评估将成为大型安全企业的标准实践,出现更多成本量化的方法和工具。
- 未来5-10年:自动化的评估指标选择和模型优化系统将出现,能够根据业务场景自动调整模型和评估指标。
- 技术突破点:结合因果推断和机器学习的评估方法,能够更准确地评估模型在真实世界中的因果效应,而不仅仅是关联效应。
参考链接:
- GitHub - scikit-learn/imbalanced-learn:不平衡数据处理工具包
- GitHub - Trusted-AI/adversarial-robustness-toolbox:IBM开发的对抗鲁棒性评估工具
- arXiv - Precision-Recall Curves for Imbalanced Classification:不平衡分类的PR曲线研究
- GitHub - ml-metrics/ml-metrics:机器学习评估指标库
- arXiv - Beyond Accuracy: Behavioral Testing of Machine Learning Models:超越准确率的机器学习模型行为测试
- GitHub - awslabs/fraud-detection-using-machine-learning:AWS欺诈检测项目,包含详细的评估指标选择
附录(Appendix):
安全场景下评估指标选择指南
- 入侵检测系统(IDS/IPS):
- 核心需求:检测尽可能多的攻击,减少漏报
- 推荐指标:召回率、F-beta(β>1)、PR-AUC
- 辅助指标:精确率、ROC-AUC
- 最佳实践:使用时间序列交叉验证评估模型在未来数据上的表现
- 反垃圾邮件系统:
- 核心需求:减少误报正常邮件,保证重要信息不丢失
- 推荐指标:精确率、F-beta(β<1)、PR-AUC
- 辅助指标:召回率、ROC-AUC
- 最佳实践:定期人工验证误判邮件,调整模型参数
- 欺诈检测系统:
- 核心需求:平衡漏报欺诈和误判正常交易
- 推荐指标:F1分数、F-beta(根据业务调整β)、总成本
- 辅助指标:PR-AUC、ROC-AUC
- 最佳实践:结合业务规则和机器学习模型,设置多级检测阈值
- 恶意软件检测系统:
- 核心需求:检测未知恶意软件,减少漏报
- 推荐指标:召回率、PR-AUC、对抗鲁棒性指标
- 辅助指标:精确率、F1分数
- 最佳实践:使用对抗样本生成技术测试模型的鲁棒性
评估指标计算代码模板
import numpy as np
from sklearn.metrics import (
accuracy_score, precision_score, recall_score, f1_score,
fbeta_score, roc_auc_score, average_precision_score,
confusion_matrix
)
def compute_all_metrics(y_true, y_pred, y_pred_proba=None, beta=1.0):
"""计算安全场景下的所有常用评估指标"""
# 基本指标
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
fbeta = fbeta_score(y_true, y_pred, beta=beta)
# 混淆矩阵
tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel()
# 衍生指标
fpr = fp / (fp + tn) # 假阳性率
fnr = fn / (fn + tp) # 假阴性率
tpr = tp / (tp + fn) # 真阳性率(召回率)
tnr = tn / (tn + fp) # 真阴性率
# 概率相关指标
roc_auc = None
pr_auc = None
if y_pred_proba is not None:
roc_auc = roc_auc_score(y_true, y_pred_proba)
pr_auc = average_precision_score(y_true, y_pred_proba)
return {
"accuracy": accuracy,
"precision": precision,
"recall": recall,
"f1": f1,
"fbeta": fbeta,
"roc_auc": roc_auc,
"pr_auc": pr_auc,
"fpr": fpr,
"fnr": fnr,
"tpr": tpr,
"tnr": tnr,
"confusion_matrix": {
"tp": tp,
"fp": fp,
"fn": fn,
"tn": tn
}
}
def calculate_cost(y_true, y_pred, false_negative_cost, false_positive_cost):
"""计算模型的总成本"""
tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel()
total_cost = fn * false_negative_cost + fp * false_positive_cost
return total_cost
def print_metrics(metrics, name="模型"):
"""打印评估指标"""
print(f"\n=== {name} 评估指标 ===")
print(f"准确率: {metrics['accuracy']:.4f}")
print(f"精确率: {metrics['precision']:.4f}")
print(f"召回率: {metrics['recall']:.4f}")
print(f"F1分数: {metrics['f1']:.4f}")
print(f"F-beta分数: {metrics['fbeta']:.4f}")
print(f"假阳性率: {metrics['fpr']:.4f}")
print(f"假阴性率: {metrics['fnr']:.4f}")
if metrics['roc_auc'] is not None:
print(f"ROC-AUC: {metrics['roc_auc']:.4f}")
if metrics['pr_auc'] is not None:
print(f"PR-AUC: {metrics['pr_auc']:.4f}")
cm = metrics['confusion_matrix']
print(f"\n混淆矩阵:")
print(f" 预测正常 | 预测攻击")
print(f"实际正常 | {cm['tn']:8d} | {cm['fp']:8d}")
print(f"实际攻击 | {cm['fn']:8d} | {cm['tp']:8d}")安全模型评估的最佳实践
- 使用分层抽样:在划分训练集和测试集时,使用分层抽样,确保测试集中的攻击样本比例与原始数据一致。
- 采用时间序列交叉验证:对于具有时间特性的安全数据,使用时间序列交叉验证,确保模型能够适应未来的数据分布。
- 评估对抗鲁棒性:使用对抗样本生成技术(如FGSM、PGD)测试模型的鲁棒性,评估模型在对抗攻击下的表现。
- 结合业务知识:与业务团队合作,确定准确的误判成本,选择最适合业务场景的评估指标。
- 定期重新评估:安全威胁不断变化,定期重新评估模型的性能,及时发现模型衰减并更新模型。
- 使用多指标综合评估:不要依赖单一指标,使用多个指标综合评估模型的性能,如结合F1分数、PR-AUC和总成本。
- 人工验证关键样本:对于误判的关键样本,进行人工验证,了解模型的弱点,指导模型改进。
- 建立基线模型:使用简单的基线模型(如逻辑回归、随机森林)作为参考,评估复杂模型的改进效果。
关键词: 准确率, 评估指标, 安全攻防, 不平衡数据, PR-AUC, ROC-AUC, F1分数, 误判成本, 对抗鲁棒性
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-01-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号