RDMA技术解析

RDMA技术解析

霞姐聊IT
发布于 2026-01-15 14:22:42
发布于 2026-01-15 14:22:42
传统TCP/IP网络因多次数据拷贝、内核态切换、CPU协议处理等,逐渐成为性能瓶颈。而 RDMA(远程直接内存访问)凭借零拷贝、内核旁路、协议卸载三大核心优势,从早期专用高性能计算领域走向通用数据中心,成为突破通信瓶颈的关键技术。本文将对RDMA技术的发展历程做一个回顾,并简要解析其技术原理、软硬件基础与核心优势。
一、RDMA技术回顾
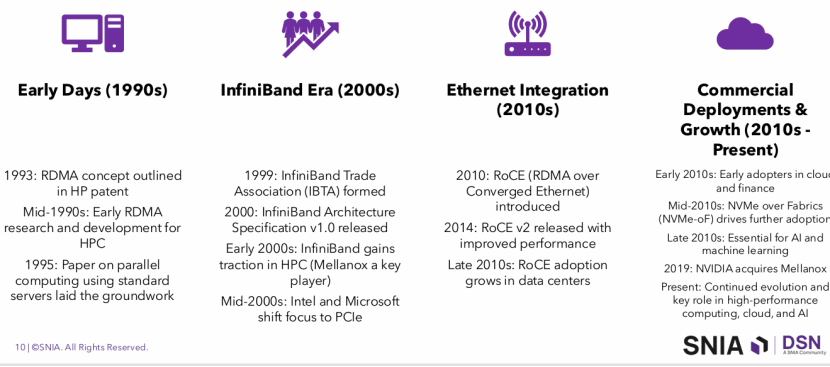
1993年,HP申请了一个专利,这个专利提出了发送方通过硬件直接指定接收方的物理内存地址,将数据绕过接收方的CPU与OS,直接写入目标内存地址的核心架构和实现逻辑,这避免了传统通信中,数据需经发送方内存→发送方CPU→网络→接收方CPU→接收方内存的多环节拷贝,被认为是RDMA(Remote Direct Memory Access)的起源。
RDMA技术不是一被发明出来就大流行的,因为在那时,RDMA需要专用的硬件配套,成本很高,并且生态和软件也不成熟。而当时主流的应用是客户机-服务器架构web、邮件、服务器等,RDMA的巨大投入和它消减的网络延时,并没增加多少好的用户体验,是一个投入产出不成比例的空中楼阁技术。
但在HPC领域,因为它以大规模并行计算为核心,节点间高频消息传递与数据同步对通信有极致要求,传统网络的延时和CPU高占用,对它影响很大。另外HPC领域的软件栈相对统一,改造路径清晰。因此90年代,RDMA首先只在HPC领域得以发展和应用。
1995年,《U-Net: A User-Level Network Interface for Parallel and Distributed Computing》这篇论文横空出世,推动 RDMA的应用从专用 HPC扩展到通用集群。这篇论文提出并实现了一个让应用程序直接、安全访问网络硬件的架构,实现了零拷贝和内核旁路,证明服务器无需专用 HPC 硬件即可通过架构优化突破通信瓶颈,为后续 InfiniBand 的 RDMA 设计、VI 架构等提供了用户态通信的核心参考,。
1999 年,InfiniBand Trade Association(IBTA)成立。IBTA由Intel、IBM、Oracle 等公司发起,是推动 InfiniBand 与 RDMA 技术标准化、产业化的非营利行业联盟。
IBTA在2000 年发布里程碑式的 InfiniBand 1.0 规范,首次标准化原生 RDMA 与 Verbs 语义,为 HPC / 数据中心高性能互联奠定基础;
而InfiniBand虽然性能高,但它成本高,生态不如以太网。所以直到ROCE出来之后,才让RDMA摆脱了InfiniBand专用网络,得以在成本低廉、生态成熟的标准以太网上运行。
IBTA在2010年发布了RoCE v1 (二层),在2014年发布了RoCE v2(三层),RoCE v1 以二层简洁性实现低延迟,适合小规模集中部署;RoCE v2 以 UDP/IP 封装突破路由限制,适配现代数据中心大规模与跨地域需求。
从此RDMA真正从HPC领域走向云计算、AI与存储等领域,成为数据中心广泛采纳的方案。
存储领域,NVMe-oF规范强化RDMA(RoCE(首选)/InfiniBand/iWARP)作为传输层,推动分布式存储与高性能计算融合;
云计算领域,云厂商在云计算大规模商用RDMA,降低云原生场景延迟与 CPU 开销;AI领域,GPUDirect RDMA 允许网卡直接访问GPU显存,避免了数据在GPU显存与主机内存之间的拷贝,将AI训练中节点间的通信延迟降至最低,成为现代AI训练集群的标配……
二、技术解析
1.简介
通过DMA,设备可以直接向内存传输数据,从而将CPU解放出来。CPU只需在数据传输开始前设置相关参数,即可切换到处理其他任务。数据传输完成后,DMA通知CPU,CPU继续处理数据传输任务。所以DMA解决了单机内外设和内存之间数据搬运的问题。
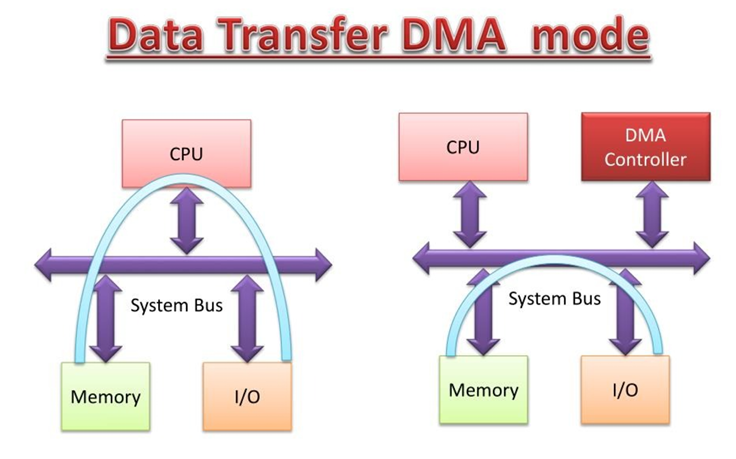
而RDMA将这种绕开 CPU 的直接传输能力扩展到了跨节点的网络场景,它是怎么解决的呢?
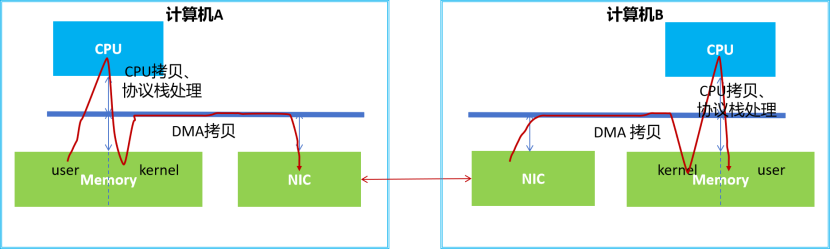
传统的网络通信中,数据传输需要涉及复杂的TCP/IP协议。
计算机A想向计算机B发送消息,首先计算机A的用户空间中的数据需要先复制到内核空间的缓冲区,然后网卡才能读取。在此过程中,数据还会添加各种头部信息和校验和,如TCP/IP头部等。
网卡随后利用DMA技术将内核空间的数据复制到网卡内部缓冲区,并通过网络发送到计算机B。
计算机B接收到数据后执行反向操作,首先将数据从网卡内部缓冲区复制到内核空间中的缓冲区。接着CPU解包数据,将其复制到用户空间。 我们能看到,即使采用了DMA技术,在这过程中仍会涉及到多次数据拷贝(用户态<-> 内核态<->网卡缓冲区),CPU会深度参与协议处理(TCP/IP栈)和中断处理。所以CPU资源被大量消耗,网络延迟也高。
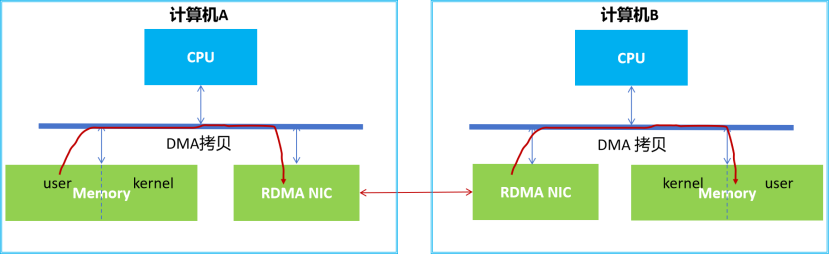
采用了RDMA技术后,CPU在两端的参与就变的非常少了,只会参与控制过程。
计算机A的本地RDMA网卡可以采用DMA技术直接将用户空间的数据拷贝到其内部存储空间,随后自动组装数据,并通过网络发送到远程计算机B的RDMA网卡。
接收数据后,远程RDMA网卡会自动剥离各种头信息和校验和,然后利用DMA技术将数据直接拷贝到用户空间内存中。整个过程高效且对CPU的依赖小。
2.硬件基础:RDMA网卡(RNIC)
RNIC不是传统的网卡,而是承接了协议转换处理、数据拷贝等功能的网卡。除了高速接口、还有IB/RoCE/iWarp等传输层引擎模块、队列管理器、DMA引擎等。
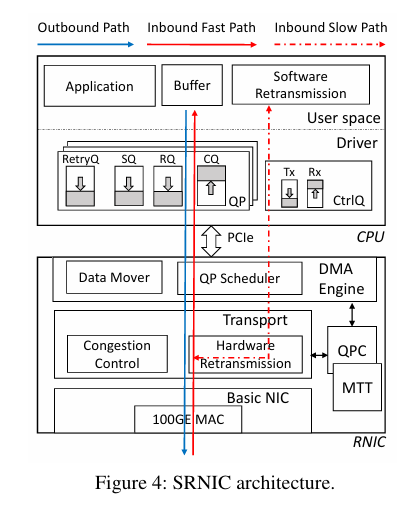
我们以香港科技大学和字节跳动合发的论文中的SRNIC为例,来看下吧:
SRNIC网卡分为三层:
lDMA 引擎层:通过QP Scheduler队列对调度器,对来自主机内存的数万个队列对进行调度,确定下一个待发送数据的队列对,随后通过Data Mover数据搬运器从该SQ发送队列中读取WQE工作队列元素与数据。
lTransport传输层:实现了绝大多数RDMA 传输功能,其中包含一个Congestion Control拥塞控制模块,以及一个Hardware Retransmission硬件重传模块。
lBasic Nic基础网卡层:实现了以太网网卡的核心功能,负责通过100G 以太网 MAC 芯片收发 RoCE v2 数据包。
有两个核心数据结构:
lQPC队列对上下文:用于存储所有与队列对相关的上下文信息。
lMTT内存转换表:用于存储虚拟地址与物理地址的映射关系。
常见的RDMA网卡有:华为SP600,Nvidia的ConnectX、BlueFiled,Intel的Ethernet 800,AMD的Alveo SN1000等等。
3.RDMA网络
有三类RDMA网络,分别是Infiniband、RoCE(V1、V2)、iWARP。
RoCE v2在通用数据中心最流行,InfiniBand主导 HPC/AI 超大规模训练,iWARP 基本边缘化。
(1)Infiniband支持原生RDMA协议,定义了独立的物理层、链路层、传输层,能从硬件级别保证可靠传输。
它的带宽利用率、端到端延迟、CPU占用率等性能也是最好的;但需要支持技术的IB HCA网卡和交换机,独立布线,所以成本也是最高的。
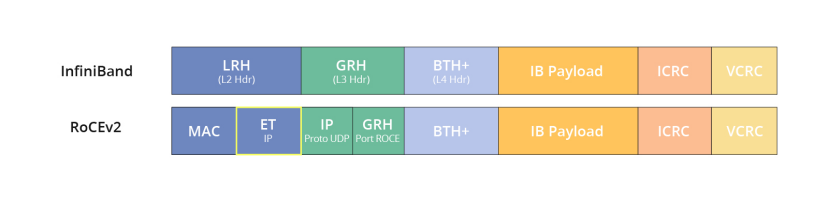
(2) RoCE协议存在RoCEv1和RoCEv2两个版本
RoCEv1是基于以太网链路层实现的RDMA协议,RoCEv2是将 IB 传输层封装到 UDP+IP 中。
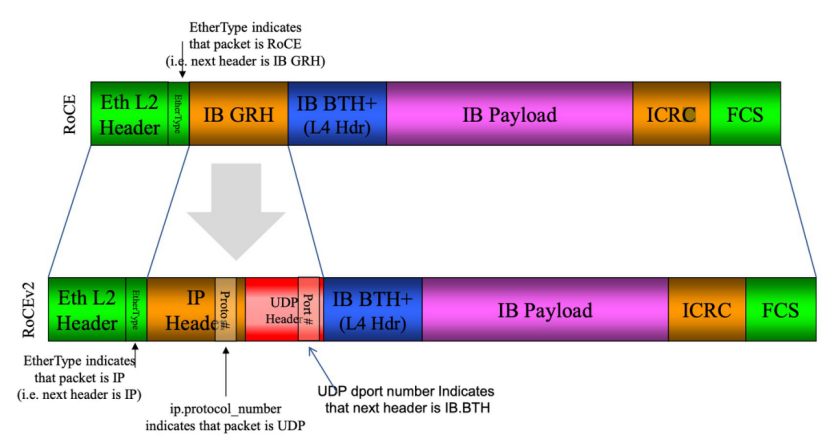
ROCE只需要网卡支持该技术,其它网络基础设施可以复用现有的,无需另外投入,性价比最高。
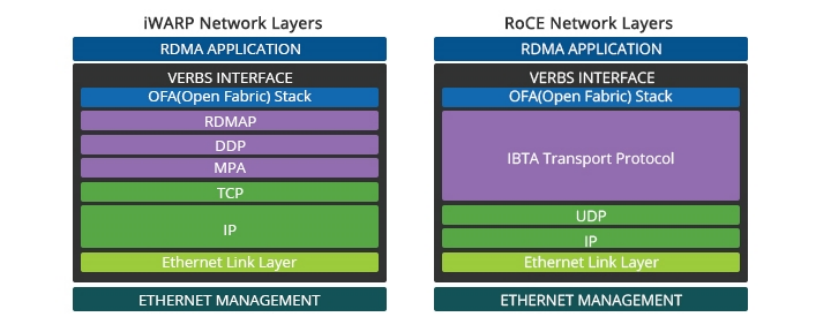
(3)iWARP是在TCP+IP上执行RDMA的网络协议。
iWARP由RDMA Consortium于 2002 年主导提出,成员包括 Broadcom、HP、IBM、Intel、Microsoft 等公司;其标准最终由 IETF 发布,但未成为主流行业标准。
它依赖一套复杂的协议栈(在 TCP/IP 协议之上封装了 DDP、MPA 及 RDMAP 协议),集成难度较高,延迟更高、吞吐量更低、CPU 开销更大,更惨的是没多少硬件厂商支持。

4.RDMA软件
在RDMA硬件之上,就是软件层了。
RDMA应用是直接面向业务的程序,核心是利用 RDMA 零拷贝、低延迟、低 CPU 开销 的特性,解决传统 TCP/IP 网络的性能瓶颈。
ULP(Upper Layer Protocol,上层协议)是基于 Verbs API 实现的场景化协议,目的是让 RDMA 适配不同业务场景,避免应用开发者重复造轮子。
Verbs API是由OFA(OpenFabrics Alliance)定义的标准化用户态编程接口统一编程接口,是连接 RDMA 应用 / ULP 与驱动的核心桥梁。
软件栈是连接软件与硬件的桥梁,负责管理RNIC 硬件资源、实现 Verbs API 与硬件的映射、处理协议适配与中断。
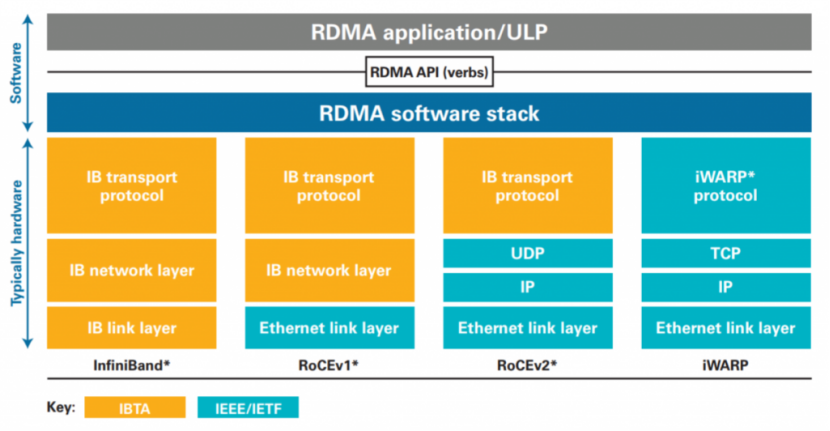
软件层这块,大多以OFED为骨架实现,硬件厂商会基于 OFED 开发标准化驱动与定制优化,让自家RNIC接入生态。软件厂商会通过OFED 提供的标准化接口,调用 RDMA能力。
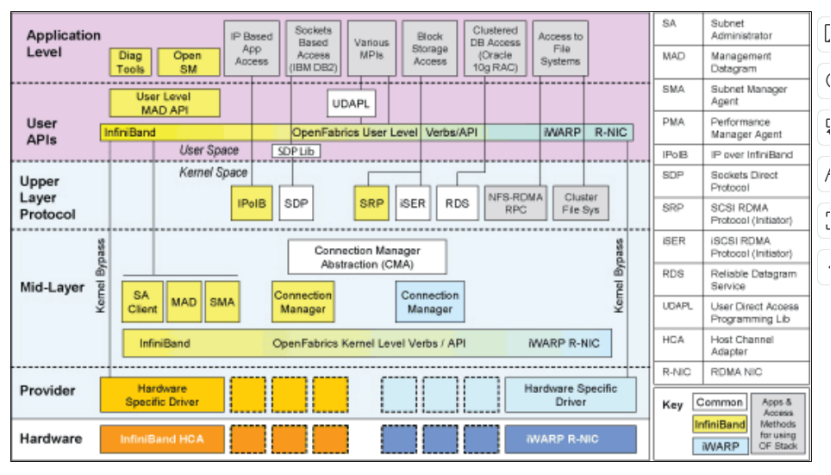
5.软硬件协同流程(RoCE v2 RDMA Write 为例)
应用层:分布式存储应用通过 Verbs API(ibv_post_send)发起 RDMA Write 请求,传入远程内存地址、rkey(远程访问密钥)、传输长度等参数;
软件层:libibverbs接收请求并转化为标准化指令,OFED 驱动ib_core管理 QP/MR(内存区域)资源,完成协议封装(UDP/IP+RDMA 头);
硬件层:RNIC 接收驱动指令,通过DMA引擎读取本地用户态数据,由传输层添加协议头,通过基础网卡层发送至网络;
远程节点:RNIC 接收数据后,硬件剥离协议头,通过 DMA 直接写入用户态内存,触发完成事件(CQE);
应用层:本地应用通过ibv_poll_cq轮询 CQE,确认传输完成。
6.技术优势
RDMA 的低延迟、高吞吐、低 CPU 开销,源于零拷贝、内核旁路、协议卸载三大核心技术的协同:
(1)协议卸载:RDMA的协议栈比传统TCP/IP协议栈更高效,且RNIC 硬件内置协议引擎,完成 RDMA 协议封装 / 解析、拥塞控制、校验和计算等工作,彻底释放 CPU 算力。
(2)零拷贝:应用通过RNIC 直接读取本地用户态内存数据,写入远端用户态内存,跳过传统的多次拷贝流程。
(3)内核旁路:应用通过 Verbs API 直接在用户态操作RNIC 的队列对QP、完成队列CQ,所有传输指令由硬件执行,无内核介入。
今天,RDMA和DMA一起将直接访问的哲学,从芯片内延伸到机房间,深刻影响着计算、通信效率。未来RDMA或许会面临新的协同与演化,但可以确信的是,其内核旁路、零拷贝、协议卸载的核心思想,已成为构建高效计算系统不可动摇的基石。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号