Apache Doris 4.0 正式发布!这一次,真的AI了


见字如面,我是一臻
❝过去我们谈数据库,聊的是更快、更稳、更省资源;今天再谈数据库,话题已经变成 AI+数据。 Apache Doris 4.0 的正式发布,把这句
AI+变成了说明书:向量索引(Vector Index)、AI 函数、 Spill Disk、BM25……
Apache Doris 4.0 的功能清单念起来像技术春晚,但真正的看点只有一个——让数据平台长出AI大脑,而且不用搬数据、不用写脚本、不用求爷爷告奶奶地调接口,写 SQL 就行。
先说最抢镜的向量索引。
以前做推荐或搜索,得先让工程师把数据抽到向量引擎,再写一套混合召回,最后把结果导回数据库,链路长得像春运。
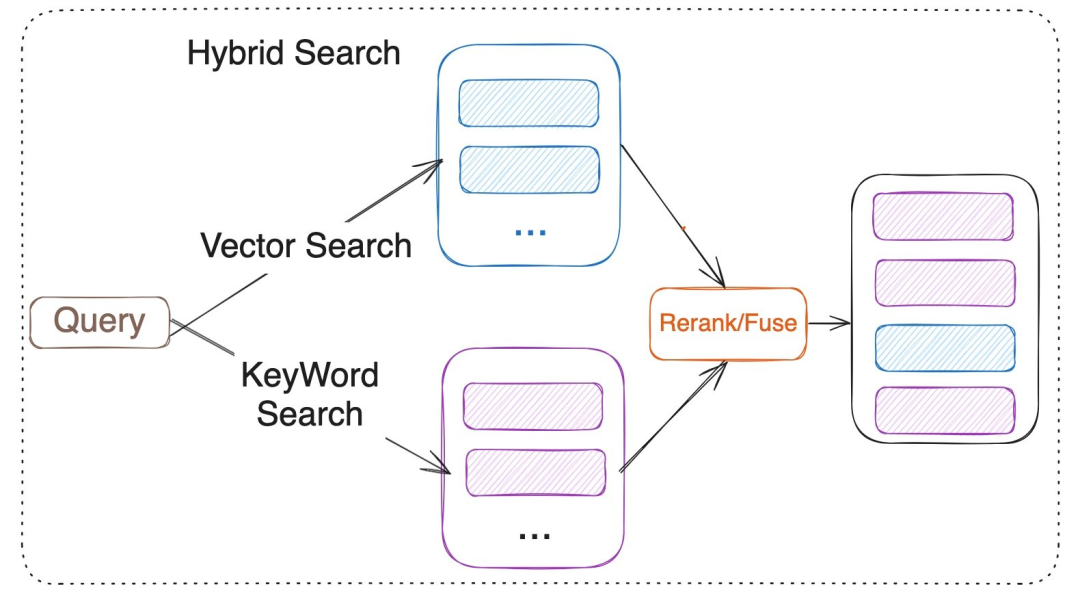
现在把高维向量直接存在 Doris,一条 SQL 就能完成“近似最近邻”,内存里画图、磁盘里兜底,召回速度按毫秒算。
更友好的是量化选项:同样 768 维向量,SQ8 只占FLAT 1/3 空间,省下来的内存可以多存几个月的用户行为,老板看见成本曲线直接点赞:
-- 1) 建表与索引
CREATETABLE doc_store (
idBIGINT,
title STRING,
tags ARRAY<STRING>,
embedding ARRAY<FLOAT> NOTNULL,
INDEX idx_vec (embedding) USING ANN PROPERTIES (
"index_type" = "hnsw",
"metric_type" = "l2_distance",
"dim" = "768",
"quantizer" = "flat"-- 可选:flat / sq8 / sq4
),
INDEX idx_title (title) USING INVERTED PROPERTIES ("parser" = "english")
)
DUPLICATEKEY(id)
DISTRIBUTEDBYHASH(id) BUCKETS 16
PROPERTIES("replication_num"="1");
-- 2) TopN 最近邻(建议使用 PreparedStatement 传入向量), 用真实向量替换下面的 ... 占位符
SELECTid, l2_distance_approximate(embedding, [...]) AS dist
FROM doc_store
ORDERBY dist ASC
LIMIT10;
-- 3) 带过滤条件的 ANN(先过滤后TopN,保障召回), 用真实向量替换下面的 ... 占位符
SELECTid, title,
l2_distance_approximate(embedding, [...]) AS dist
FROM doc_store
WHERE title MATCH_ANY 'music' -- 使用倒排索引快速过滤
AND array_contains(tags, 'recommendation') -- 结构化过滤
ORDERBY dist ASC
LIMIT5;
-- 4) 范围查询,, 用真实向量替换下面的 ... 占位符
SELECTCOUNT(*)
FROM doc_store
WHERE l2_distance_approximate(embedding, [...]) <= 0.35;
有向量还不够,Doris 干脆把大模型也塞进函数仓库。
情感分类、摘要、翻译、实体抽取、语法纠错,甚至让模型帮你判断“这段简历到底匹不匹配岗位”,全都封装成 AI_ 前缀的 SQL 函数。

AI函数执行流程图
分析师不用会 Python,也不用背提示词模板:
select AI_SENTIMENT(comment)
反手就能在千万行评论里秒抓负面情绪。
业务方第一次发现,原来提需求可以这么短:一句 SQL,模型算完,结果落地,全程不用出数据库,合规同学睡得比任何时候都香。
检索场景同样换了引擎。
老版本靠 TF-IDF 打分,长文档总是被“稀释”,关键词飘在三千字末尾却拿不到高分。
4.0 直接换上 BM25,把文档长度、词频、逆文档频率一起拉进公式,长文不再吃亏,短句也难灌水。再加一个 search() 函数,把布尔、短语、多值匹配装进统一语法,写惯了 Elasticsearch 查询字符串的人几乎可以零成本搬家。
更贴心的是自定义分词器:中文用 ik,国际化用 ICU,日志里那些带下划线和点的鬼畜标识符也能按需切开,检索命中率肉眼可见地上涨:
# 中文
SELECT TOKENIZE('中华人民共和国国歌', '"parser"="ik","parser_mode"="ik_smart"');
-- 结果: ["中华人民共和国", "国歌"]
SELECT TOKENIZE('中华人民共和国国歌', '"parser"="ik","parser_mode"="ik_max_word"');
-- 结果: ["中华人民共和国", "中华人民", "中华", "华人", "人民共和国", "人民", "共和国", "共和", "国歌"]
# 国际化
SELECT TOKENIZE('مرحبا بالعالم Hello 世界', '"parser"="icu"');
-- 结果: ["مرحبا", "بالعالم", "Hello", "世界"]
SELECT TOKENIZE('มนไมเปนไปตามความตองการ', '"parser"="icu"');
-- 结果: ["มน", "ไมเปน", "ไป", "ตาม", "ความ", "ตองการ"]
离线跑批的苦,Doris 也顺手治了。
数据量一大,内存就像双十一的快递柜,眨眼就满。过去除了加机器就是改 SQL,现在打开 spilled disk 开关,聚合、排序、Hash Join、CTE 中间结果自动写盘,内存峰值瞬间削平:
# BE 配置项
spill_storage_root_path=/mnt/disk1/spilltest/doris/be/storage;/mnt/disk2/doris-spill;/mnt/disk3/doris-spill
spill_storage_limit=100%
# FE Session Variable
set enable_spill=true;
set exec_mem_limit = 10g;
set query_timeout = 3600;
# Profile check
PARTITIONED_HASH_JOIN_SINK_OPERATOR (id=4 , nereids_id=179):(ExecTime: 6sec351ms)
- Spilled: true
- CloseTime: 528ns
- ExecTime: 6sec351ms
- InitTime: 5.751us
- InputRows: 6.001215M (6001215)
- MemoryUsage: 0.00
- MemoryUsagePeak: 554.42 MB
- MemoryUsageReserved: 1024.00 KB
- OpenTime: 2.267ms
- PendingFinishDependency: 0ns
- SpillBuildTime: 2sec437ms
- SpillInMemRow: 0
- SpillMaxRowsOfPartition: 68.569K (68569)
- SpillMinRowsOfPartition: 67.455K (67455)
- SpillPartitionShuffleTime: 836.302ms
- SpillPartitionTime: 131.839ms
- SpillTotalTime: 5sec563ms
- SpillWriteBlockBytes: 714.13 MB
- SpillWriteBlockCount: 1.344K (1344)
- SpillWriteFileBytes: 244.40 MB
- SpillWriteFileTime: 350.754ms
- SpillWriteFileTotalCount: 32
- SpillWriteRows: 6.001215M (6001215)
- SpillWriteSerializeBlockTime: 4sec378ms
- SpillWriteTaskCount: 417
- SpillWriteTaskWaitInQueueCount: 0
- SpillWriteTaskWaitInQueueTime: 8.731ms
- SpillWriteTime: 5sec549ms
TPC-DS 10 TB 测试里,3 台 64 GB 的小机器跑完 99 条查询,磁盘 I/O 只占用临时盘,业务存储不受干扰,运行时长为 28102.386 秒。
换句话说,以前“内存不够任务就崩”,现在“内存不够就慢点”,慢比跪强,值班电话安静多了。
数据质量也被拉上擂台。
Cast、日期、数字、JSON 一大波函数重新校对准绳,上游格式再奇葩,入库就能被当场纠偏,错误不再流到下游报表。对很多企业来说,这比加十个新功能更值钱:决策错误往往不是因为模型不好,而是因为基础数据被默许脏到底。
Doris 4.0 把校验覆盖到采-存-用全链路,让所有分析都站在同一块干净的地板,而不是在垃圾堆里找金子。
再把镜头拉远,你会发现这次升级不只是“功能更多”,而是角色彻底变了:它不再只是仓库,而是同时兼任向量引擎、大模型网关、全文检索平台和离线计算集群。
对 CIO 来说,少买几套系统就是硬省钱;对架构师来说,数据不用搬来搬去就是软省钱;对分析师来说,把想法变成 SQL 就能上线,省的是最贵的人力成本。
当技术栈被压成一层,沟通摩擦消失,创新周期从周变成天,数据才真正成为生产力,而不是报表里的装饰品。
当只需要写条 SQL 就能调用大模型、就能做向量召回、就能跑 10 TB 离线任务,数据库已不再是后台的黑箱子,而是前线创新的发动机了...
各位看官,意下如何?

完
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号