2025最新卷积神经网络(CNN)详细介绍及其原理详解


2025最新卷积神经网络(CNN)详细介绍及其原理详解
本文详细介绍了卷积神经网络(CNN)的基础概念和工作原理,包括输入层、卷积层、池化层、全连接层和输出层的作用。通过举例和图解,阐述了CNN如何处理图像,提取特征,以及如何进行手写数字识别。此外,讨论了池化层的平移不变性和防止过拟合的重要性。 本文是关于卷积神经网络(CNN)技术教程,整体内容从基础概念到实际示例,逐层剖析 CNN 的各个组成部分与作用,并通过手写数字识别案例帮助大家更直观地理解其工作原理。
引言
卷积神经网络(Convolutional Neural Network,简称 CNN)自从 2012 年 AlexNet 在 ImageNet 比赛中取得突破性成绩后,迅速成为计算机视觉领域的主流架构。伴随深度学习技术的发展,CNN 不仅在图像分类,还在目标检测、语义分割、风格迁移等任务中表现优异。本文将从最基础的概念开始,逐步带领初学者了解 CNN 的各个组成部分与工作流程,并通过图解与示例让读者对 CNN 原理有更直观的理解。 公众号:猫头虎技术团队 万粉变现经纪人:CSDNWF
CNN 基础概念
1. 什么是神经网络
- 神经元与感知机 神经网络的基本单元是神经元(Neuron),灵感来源于生物神经元。感知机(Perceptron)是最早的人工神经元模型,其计算方式为对输入特征进行加权求和后,再加上一个偏置值(bias),最后通过激活函数输出。其数学表达式可写作:
其中,
为输入特征,
为权重,
为偏置,
为激活函数(如 sigmoid、ReLU 等)。
- 多层神经网络(MLP) 多层神经网络(Multilayer Perceptron,MLP)由多个感知机堆叠组成。典型的 MLP 包括输入层、若干隐藏层和输出层。MLP 在小规模数据集上表现良好,但当图像分辨率增大、数据维度提高时,参数量迅速膨胀,难以应对。
2. 为什么使用卷积神经网络
- 局部连接与权值共享 与全连接层相比,卷积层的神经元只与局部感受野(receptive field)连接,并且在同一个特征图(feature map)内,所有局部感受野共享同一组卷积核(权重)。这大幅减少了参数数量,使得模型更易训练,也能更好地捕捉空间结构信息。
- 平移不变性(Translation Invariance) CNN 可以通过卷积和池化操作,实现特征在空间位置上的平移不变性,即图像中的目标无论位于何处,均能被检测到。
- 层级特征提取(Hierarchical Feature Extraction) 多层卷积堆叠能够从低级特征(如边缘、角点)逐步提取到高级语义特征(如物体整体结构、类别信息)。
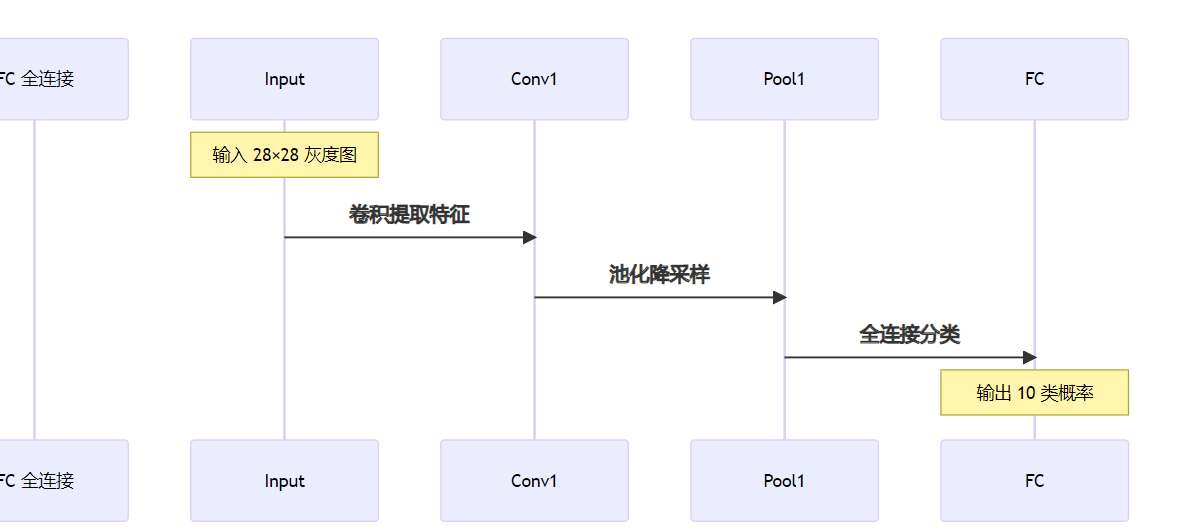
CNN 的整体架构
整体来看,一个典型的 CNN 网络可以分为以下几大部分:
- 输入层(Input Layer):接收图像数据(如彩色三通道图像或灰度图像)。
- 卷积层(Convolutional Layer):通过卷积核滑动提取局部特征,输出特征图(Feature Map)。
- 激活函数(Activation Function):为网络引入非线性,使其具有更强的表达能力。
- 池化层(Pooling Layer):下采样操作,降低特征图尺寸并增强平移不变性。
- 全连接层(Fully Connected Layer, FC):将前面提取到的特征整合,用于最后的分类或回归。
- 输出层(Output Layer):使用 Softmax 或其他激活函数输出最终预测结果。
作者✍️ 猫头虎微信号:Libin9iOak 公众号:猫头虎技术团队 万粉变现经纪人:CSDNWF
以下章节将逐层详细剖析各部分的原理、作用及实现要点。
层级详解与原理
1. 输入层:数据的准备与预处理
- 输入数据格式
对于图像分类任务,常见的输入形式为三维张量(Height × Width × Channels),例如:
- 彩色图像:
H \times W \times 3 (RGB 三通道)
- 灰度图像:
H \times W \times 1 - 数据预处理(Data Preprocessing)
- 归一化(Normalization):将像素值从
[0, 255] 缩放到
[0, 1] 或
[-1, 1] ,有助于加速模型收敛。
- 数据增强(Data Augmentation):随机裁剪(Random Crop)、翻转(Flip)、旋转(Rotate)、色彩抖动(Color Jitter)等操作可增大数据多样性,防止过拟合。
- 批量化处理(Batching):将输入数据划分为若干小批量(Batch),例如 Batch Size = 32 或 64,以利用 GPU 并行加速。
作者✍️ 猫头虎微信号:Libin9iOak 公众号:猫头虎技术团队 万粉变现经纪人:CSDNWF
2. 卷积层:特征提取核心
2.1 卷积核与特征图
- 卷积核(Kernel/Filter) 卷积核是一个
的小矩阵(如
,
),用于对输入图像或前一层特征图进行滤波操作。每个卷积核都会生成一个特征图,网络可学习多组卷积核来提取不同特征。
- 特征图(Feature Map) 通过卷积计算后,得到的二维输出称为特征图(或激活图)。若输入通道数为
,输出通道数为
,则每个输出通道对应一个卷积核组,其尺寸为
。
2.2 卷积操作示意(图解)
输入特征图:
┌─────────┬─────────┬─────────┐
│ 1 │ 2 │ 3 │ 4 │ 5 │
├─────────┼─────────┼─────────┤
│ 6 │ 7 │ 8 │ 9 │ 10│
├─────────┼─────────┼─────────┤
│ 11│ 12│ 13│ 14│ 15│
├─────────┼─────────┼─────────┤
│ 16│ 17│ 18│ 19│ 20│
├─────────┼─────────┼─────────┤
│ 21│ 22│ 23│ 24│ 25│
└─────────┴─────────┴─────────┘
卷积核:
┌───┬───┬───┐
│ 0 │ 1 │ 0 │
├───┼───┼───┤
│ 1 │ -4│ 1 │
├───┼───┼───┤
│ 0 │ 1 │ 0 │
└───┴───┴───┘
将卷积核从左上角 (1,1) 开始滑动,计算加权和即可得到对应的特征值,生成新的特征图。图示说明
- 绿色方框 代表卷积核正在处理的
区域。
- 红色数字 为卷积结果输出到特征图(输出尺寸会比输入小,具体见下文步长与填充)。
2.3 步长(Stride)与填充(Padding)
- 步长(Stride) 步长定义卷积核在输入特征图上滑动的间隔。若步长为 1,卷积核每次移动一个像素;若步长为 2,则每次移动两个像素。步长越大,输出特征图尺寸越小。
- 填充(Padding)
为了使卷积操作输出保持与输入尺寸一致(常称为“same”卷积),可以在输入边缘进行零填充(zero-padding)。常见填充方式有:
- 无填充(Valid):不进行填充,输出尺寸较小。
- 全填充(Same):在输入周围填充
\lfloor k/2 \rfloor 行/列零,使输出尺寸等于输入尺寸。
作者✍️ 猫头虎微信号:Libin9iOak 公众号:猫头虎技术团队 万粉变现经纪人:CSDNWF
3. 激活函数:引入非线性
3.1 常见激活函数介绍
- ReLU(Rectified Linear Unit)
优点:计算简单,能够缓解梯度消失;缺点:存在“神经元死亡”问题(即负值全部变为 0)。
- Leaky ReLU / Parametric ReLU 给负值引入一个较小斜率:
其中
通常为 0.01 或可学习。
- Sigmoid / Tanh
这些函数容易导致梯度消失,已逐渐在深度网络中被 ReLU 系列函数取代。
3.2 为什么要加非线性
- 线性变换堆叠效果有限 如果一层层地叠加线性层(即矩阵乘法 + 偏置,且不加激活函数),最终仍相当于一个线性变换,网络无法拟合复杂、非线性的特征分布。引入非线性激活函数可以使神经网络具备非线性表达能力。
作者✍️ 猫头虎微信号:Libin9iOak 公众号:猫头虎技术团队 万粉变现经纪人:CSDNWF
4. 池化层:降维与平移不变性
池化层(Pooling Layer)常用于卷积层之后,通过对特征图的局部区域进行下采样,减少特征图尺寸与参数量,同时获得一定的平移不变性。
4.1 最大池化与平均池化
最大池化(Max Pooling) 在
的滑动窗口中取最大值输出。能够保留最显著的特征。
输入区域: Max Pooling 2×2 (stride=2)
┌───┬───┐ ┌───┐
│ 1 │ 5 │ │ 5 │
├───┼───┤ → └───┘
│ 3 │ 2 │ (示例)
└───┴───┘平均池化(Average Pooling) 在
的滑动窗口中取像素平均值输出。
输入区域: Average Pooling 2×2 (stride=2)
┌───┬───┐ ┌───┐
│ 1 │ 5 │ │ (1+5+3+2)/4 = 2.75 │
├───┼───┤ → └───────────────────┘
│ 3 │ 2 │
└───┴───┘小提示:
- 在绝大多数图像分类模型中,最大池化 使用更为广泛,因为它能保留更强的边缘、纹理等显著特征。
- 池化层的步长(stride)一般等于池化窗大小,以实现不重叠区块下采样。
4.2 池化层如何防止过拟合
- 降低参数量与计算量 池化层将特征图尺寸减半(如从
变为
),后续层处理的参数量大幅减少,有助于缓解过拟合风险。
- 提高平移不变性(Translation Invariance) 当输入中的物体在微小位置移动时,池化操作能使特征保持相对稳定,不至于因为微小偏移而导致后续分类器输出发生巨大变化。
4.3 平移不变性原理(图解)
原始图像: 卷积层输出(特征图): 池化层处理后:
┌─────────┐ ┌─────────┐ ┌───────┐
│ ■ ■ │ │ 0.8 0.7 │ │ 0.8 │
│ ■ │ │ 0.6 0.9 │ → └───────┘
│ ■ ■ │ │ 0.4 0.5 │
└─────────┘ └─────────┘- 若■ 微移后输入,卷积特征位置略有变化,但经过池化后依然能捕获最强激活 0.9,保持特征不变。
作者✍️ 猫头虎微信号:Libin9iOak 公众号:猫头虎技术团队 万粉变现经纪人:CSDNWF
5. 全连接层:高层表示与分类
5.1 多层感知机(MLP)与全连接的作用
全连接层(Fully Connected, FC) 将池化层(或最后卷积层)输出的多维特征图展平(Flatten)为一维向量,传入若干全连接层,以实现特征组合、映射到类别空间并完成分类。
网络示例
卷积+池化输出: 扁平化后维度:
16 个 5×5×32 特征图 → 16 × 5 × 5 × 32 = 12800 维向量
Flatten 后送入 FC1(4096 单元) → FC2(1024 单元) → 输出层(10 个类别)5.2 Dropout 等正则化技巧
- Dropout 在训练过程中随机将部分神经元置为 0(通常概率为 0.5),迫使网络不依赖单个节点,增强模型鲁棒性。
- L2 正则化(权重衰减) 在损失函数中加入权重平方和惩罚,限制权重增长,不易过拟合。
- Batch Normalization(BN) 对每一层输入进行标准化,加快收敛速度并具有一定的正则化效果。
作者✍️ 猫头虎微信号:Libin9iOak 公众号:猫头虎技术团队 万粉变现经纪人:CSDNWF
6. 输出层:损失函数与预测
6.1 Softmax 分类与交叉熵损失
- Softmax 函数 对于
类目标,设最后一层全连接输出为向量
,则
将原始分数转换为概率分布。
- 交叉熵损失(Cross-Entropy Loss)
其中
为真实标签(one-hot 编码),
为预测概率。最小化交叉熵意味着提高模型对正确类别的置信度。
6.2 回归问题的输出层
- 对于回归任务(如目标检测中的边框回归),最后一层可不使用 Softmax,而是直接输出连续值,配合均方误差(MSE)等损失函数。
作者✍️ 猫头虎微信号:Libin9iOak 公众号:猫头虎技术团队 万粉变现经纪人:CSDNWF
手写数字识别示例(MNIST)
为了更直观地理解 CNN 的工作流程,我们以经典的 MNIST 数据集(手写数字识别)为例,演示如何构建并训练一个简单的卷积神经网络。
1. 数据集简介
- MNIST 数据集
- 包含 60,000 张训练图片和 10,000 张测试图片。
- 每张图片为灰度图,尺寸为
28 \times 28 。
- 标签为 0 到 9 的十个数字类别。
- 加载与预处理
- 归一化:将像素值缩放到
[0,1] 。
- 形状调整:将输入形状重塑为
(N, 1, 28, 28) 。
- 独热编码:将标签转换为 one-hot 格式
(N, 10) 。
2. 模型结构示例
以下以 PyTorch 或 TensorFlow 为例,给出一个经典的 LeNet-5 风格网络结构(注:仅结构示意,非完整代码):
输入:1×28×28
Conv1: 6 个 5×5 卷积核,stride=1, padding=0 → 输出特征图 6×24×24
激活:ReLU
Pool1: 最大池化 2×2,stride=2 → 输出 6×12×12
Conv2: 16 个 5×5 卷积核 → 输出 16×8×8
激活:ReLU
Pool2: 最大池化 2×2,stride=2 → 输出 16×4×4
Flatten: 16×4×4 → 256
FC1: 256 → 120
激活:ReLU
FC2: 120 → 84
激活:ReLU
FC3(输出层):84 → 10
Softmax → 10 类概率LeNet-5 简要说明
- LeNet-5 是最早的成功卷积神经网络之一,由 Yann LeCun 等人在 1998 年提出。
- 结构浅,总参数量小,适用于小规模灰度图像(如 MNIST 手写数字)。
3. 训练过程与超参数设置
- 超参数示例
- 学习率(Learning Rate):0.001(可使用学习率衰减或自适应优化器如 Adam)
- Batch Size:64 或 128
- Epoch 数:10–20(可视训练曲线设置)
- 优化器(Optimizer):SGD(动量 0.9)或 Adam
- 训练流程
- 前向传播:将 batch 数据输入网络,依次计算每层输出,最终得到预测概率。
- 计算损失:使用交叉熵损失函数计算预测与真实标签的差距。
- 反向传播:根据损失对各层参数计算梯度。
- 参数更新:使用优化器更新权重和偏置。
- 评估指标:在验证集或测试集上计算准确率(Accuracy)和损失(Loss),随时监控过拟合趋势。
作者✍️ 猫头虎微信号:Libin9iOak 公众号:猫头虎技术团队 万粉变现经纪人:CSDNWF
4. 结果展示与可视化特征图
- 训练曲线绘制
- 绘制训练集与验证集的损失随 epoch 变化趋势图。
- 绘制训练集与验证集的准确率随 epoch 变化趋势图。
- 特征图可视化 以第一层卷积(Conv1)为例,可在训练前后取一张输入图像,观察输出的多个特征图(6 张 24×24 图)。例如,对于数字 “7” 输入,Conv1 可能提取到边缘、线条等低级特征。
示例说明
- 特征图 1:高亮数字 “7” 的左上边缘。
- 特征图 2:高亮数字 “7” 的右上边缘。
- … 通过可视化能够直观理解卷积核在干什么。
常见问题与进阶技巧
1. 为什么要用多个卷积层
- 逐层提取更复杂特征
- 第一层卷积捕捉低级特征(边缘、角点)。
- 第二层卷积在低级特征的基础上提取中级特征(纹理、简单形状)。
- 第三层及以上的卷积提取更加抽象的高级语义特征(物体零件、整体结构)。
- 深度学习中的“深度” 网络越深,理论上能够学习到更丰富、更抽象的特征表示。但过深会带来梯度消失/梯度爆炸、训练困难等问题,需要借助残差网络(ResNet)、BatchNorm、预训练等技术。
2. 如何选择卷积核大小与数量
- 卷积核大小(Kernel Size)
- 经典用法:
3 \times 3 或
5 \times 5 。
- 多个
3 \times 3 的连续堆叠等效于一个较大感受野:例如,两个连续的
3 \times 3 等效于一个
5 \times 5 (感受野为 5)但参数更少、非线性更强。
- 卷积核数量(Channels)
- 第一层通常较少(如 32 或 64),后续层逐渐加倍(如 128、256、512)。
- 卷积核数量越多,表示能力越强,但计算量与内存消耗也越大。需要结合 GPU 资源与数据集规模进行平衡。
3. 过拟合与欠拟合的对策
- 过拟合(Overfitting)
- 现象:训练集准确率很高,而验证/测试集准确率较低。
- 对策:
- 数据增强:扩充训练集样本多样性(随机剪裁、旋转、平移、翻转)。
- 正则化:使用 Dropout、L2 正则化、BatchNorm。
- 减小模型容量:减少卷积核数量或全连接层神经元数。
- 提前停止(Early Stopping):监控验证集 Loss,当连续多次不下降时停止训练。
- 欠拟合(Underfitting)
- 现象:训练集与验证集准确率都较低。
- 对策:
- 增加模型深度或宽度:加入更多卷积层或扩大卷积核数量。
- 调整学习率:过低学习率可能导致网络无法学到有效特征。
- 训练轮次不足:适当增大 Epoch 数。
4. 迁移学习与预训练模型
- 迁移学习(Transfer Learning) 在大规模数据集(如 ImageNet)上预训练好的模型作为“通用特征提取器”,将其前几层权重固定或微调,再在小规模数据集上训练最后几层。显著缩短训练时间并提升模型性能。
- 常见预训练模型
- VGG、ResNet、Inception、DenseNet、MobileNet 等。
- PyTorch、TensorFlow/ Keras 均提供预训练权重,方便调用。
结语
本文从输入层到输出层,对卷积神经网络(CNN)的基础概念、各层级作用与原理进行了超详细的讲解,并通过手写数字识别示例,帮助您直观理解 CNN 的训练与推理流程。希望大家在阅读后能掌握以下要点:
- CNN 如何通过卷积层提取图像特征;
- 激活函数、池化层、全连接层在网络中的核心作用;
- 通过数据预处理、数据增强、防止过拟合等手段,提高模型性能;
- 迁移学习在实际项目调优中的重要性。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-06-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号