IBM首提面向RAG系统大规模配置空间的超参数优化HPO研究:方法、对比与发现

IBM首提面向RAG系统大规模配置空间的超参数优化HPO研究:方法、对比与发现

AgenticAI
发布于 2025-05-08 13:36:00
发布于 2025-05-08 13:36:00
随着大型语言模型(LLMs)在实际应用中的广泛使用,如何确保模型能够访问到解决用户查询所需的知识成为一大挑战。为此,检索增强生成(Retrieval-Augmented Generation,RAG)范式应运而生,通过引入检索系统为生成模型提供上下文信息,从而提高生成质量。
然而,RAG 的模块化设计虽然提供了灵活性,但也带来了配置复杂性。选择合适的生成模型、检索参数(如每个查询检索的文档数量、排序方式等)以及其他超参数,都会显著影响系统性能。由于评估每种配置都需要大量计算资源和时间,全面探索所有可能的配置组合几乎不可能。
为了解决这一问题,自动超参数优化(Hyper-Parameter Optimization,HPO)方法被引入到 RAG 系统中。尽管已有一些 HPO 框架应用于 RAG,但它们的有效性尚未经过严格的基准测试。本文旨在填补这一研究空白,系统地评估不同 HPO 方法在 RAG 系统中的表现。
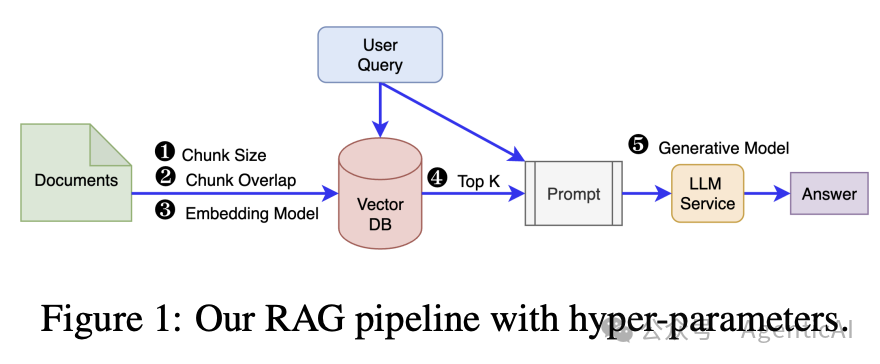
1. 核心贡献与方法
本文的主要贡献在于对 RAG 系统中超参数优化方法的系统性分析。作者评估了五种 HPO 算法:树结构的 Parzen 估计器(TPE)、三种贪婪优化方法和随机搜索。
- 随机搜索(Random Search):最基础的方法,随机采样参数组合。虽然简单,但在高维空间中往往能覆盖更广区域。
- TPE(Tree-structured Parzen Estimator):基于贝叶斯优化的一种方法,使用概率模型(如高斯核密度估计)来建模参数与性能之间的关系,有针对性地探索性能更优的区域。
- 全局贪婪(Greedy Global):按照参数组整体组合逐步搜索最优,易陷入局部最优,但计算效率高。
- 局部贪婪(Greedy Local):从当前最优配置出发,对单个参数逐一微调优化,适合低维搜索空间。
- 顺序管道贪婪(Greedy Pipeline Order):按照 RAG 管道顺序依次优化模块(如先调 retriever,再调 generator),符合模块化思维,但效果受顺序影响大。
实验涵盖了由五个检索和生成参数组成的 162 种可能的 RAG 配置,这是目前为止在 RAG 超参数优化中探索的最大搜索空间。
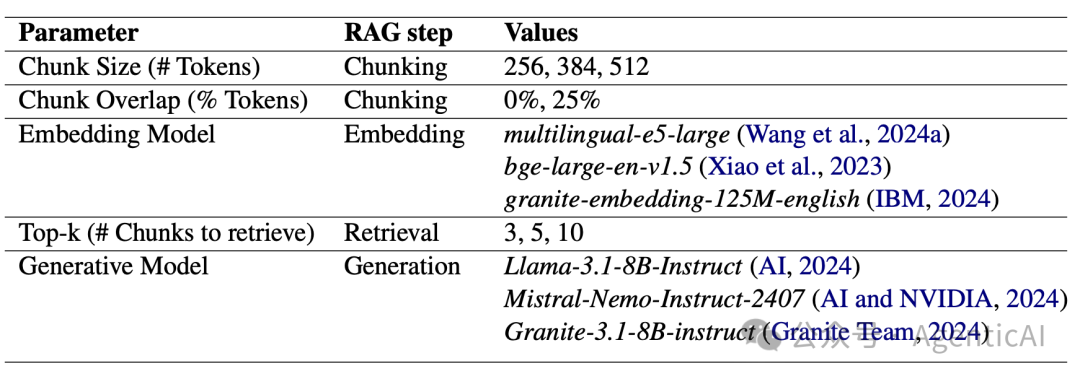
研究发现,RAG 的超参数优化可以高效地完成,贪婪方法或迭代随机搜索都能显著提升系统性能。特别是,对于贪婪的 HPO 方法,先优化生成模型比按照 RAG 管道顺序逐步优化更为有效。
2. 实验设计与结果
实验使用了来自不同领域的五个 RAG 问答数据集,包括机器学习领域的 arXiv 文章、生物医学、维基百科等。评估指标涵盖了传统的词汇匹配指标和基于大型语言模型的评估方法(LLM-as-a-Judge)。
在实验部分,作者系统对比了以下 6 种超参数优化方法在 RAG 系统中的表现:
- Grid Search:穷举搜索空间中所有参数组合,是最传统的方法。虽然全面但计算开销巨大,在参数维度较高时不可扩展,仅作为性能上限的对比参考。
- Random Search:从整个搜索空间中随机采样配置进行评估。相比 Grid Search 更高效,能覆盖较多组合,但可能错过高质量局部区域。
- TPE(Tree-structured Parzen Estimator):贝叶斯优化方法,通过构建参数到性能的概率模型来预测高性能区域。理论上更聪明,但在 RAG 的搜索空间中收敛效果并不总是优于贪婪策略。
- Greedy-M(Greedy Modular):一种模块化贪婪策略。先分别对 RAG 系统的检索器(Retriever)和生成器(Generator)独立优化,然后组合两个局部最优结果。这种方法简单高效,适用于模块解耦明确的系统。
- Greedy-R(Greedy by Retrieval first):顺序贪婪优化策略,先固定生成器,仅优化检索模块中的参数(如检索数量、rerank 方式等),再固定检索器参数优化生成器。这种方式模拟真实部署场景中逐层调优的流程。
- Greedy-R-CC(Greedy Retrieval + Coordinate Correction):在 Greedy-R 的基础上增加一个“参数修正”步骤,即在完成一次顺序贪婪优化后,再次微调所有参数以修正局部最优问题。该方法在实验中取得最优结果。
结果显示,经过超参数优化的 RAG 系统在所有数据集上性能都有显著提升。特别是,贪婪优化方法在大多数情况下优于其他方法,且优化生成模型的顺序对最终性能有重要影响。
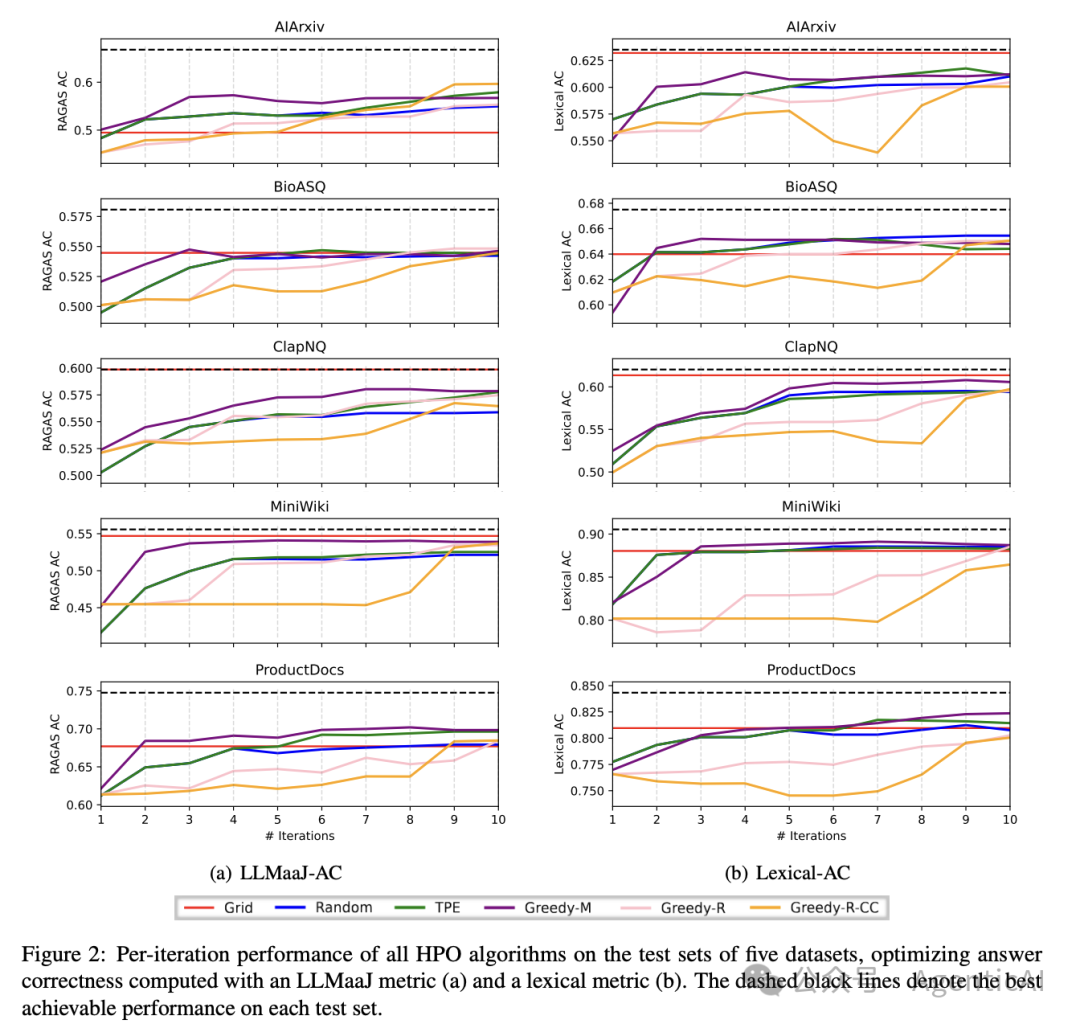
或许一张表格更能清晰的表明各个 HPO 方法的区别。
方法 | 类型 | 是否考虑模块交互 | 是否全局优化 | 收敛稳定性 | 表现总结 |
|---|---|---|---|---|---|
Grid Search | 穷举 | ✔️ | ✔️ | 高 | 最优参考但成本极高 |
Random Search | 随机 | ❌ | ✔️ | 中 | 高效但不稳定 |
TPE | 贝叶斯 | ✔️ | ✔️ | 中 | 理论强但表现波动 |
Greedy-M | 贪婪 | ❌ | ❌ | 高 | 简单快速,适合模块解耦场景 |
Greedy-R | 贪婪 | 部分 ✔️ | ❌ | 高 | 顺序优化有效但局部最优风险 |
Greedy-R-CC | 贪婪+修正 | ✔️ | 近似 ✔️ | 高 | 性能最佳,推荐使用 |
3. 结果分析
除了系统评测六种 HPO 方法的效果,作者在第六节进一步展开了三方面分析,为读者深入理解搜索策略背后的机制提供了实证支持:
3.1 各阶段搜索空间的重要性
作者将整个 RAG 管道拆成两个子空间——Retriever 参数空间与 Generator 参数空间,并进行独立评估。结果发现:
- 在大多数任务中,仅优化 Retriever 参数 就能获得大部分性能提升;
- Generator 参数对性能的边际影响相对较小。
这一发现不仅印证了“先调 Retriever 更有效”的策略合理性,也为工业实践中优先调参提供了依据。
3.2 模块间参数组合的非独立性分析
作者进一步比较了「独立调参后组合」与「联合调参」的结果差异。尽管模块分开调参(如 Greedy-M)能简化搜索空间,但当 Retriever 与 Generator 存在非线性交互(如 Retriever 的返回文档数影响上下文长度)时,模块组合优化往往更优。
这说明贪婪式的 Greedy-R、Greedy-R-CC 比完全独立优化(Greedy-M)更具优势,尤其是在复杂依赖的系统中。
3.3 贪婪算法的收敛性与稳定性
为了评估贪婪算法是否容易陷入局部最优,作者在多个初始点上启动 Greedy-R 和 Greedy-R-CC,并观察其最终性能分布。实验表明:
- Greedy-R-CC 在不同初始点上均能稳定收敛至接近最优解,且结果方差最小;
- 相比之下,TPE 与 Random Search 的表现更易受起点影响,波动性较大。
这进一步强调了 Greedy-R-CC 方法在实际部署中的鲁棒性与高性价比,尤其适合在资源受限场景中快速获得较优配置。
4. 总结
这篇论文通过系统地评估不同的超参数优化方法,为 RAG 系统的配置提供了实用的指导。其最大亮点在于探索了迄今为止最大的 RAG 超参数搜索空间,并发现了高效的优化策略。
- RAG 系统中的调参并不需要复杂的黑盒优化;
- 相对简单的顺序贪婪策略(尤其是带局部修正的 Greedy-R-CC)在精度、稳定性与成本三方面都表现最佳;
- 并首次实证支持“Retriever 优先优化”的设计原则。
然而,目前作者尚未开源代码或配置脚本,后续若开源将大大便利实践者复现与扩展。
附|关注大模型实战应用?
👋 Agentic AI —— 专注 RAG 与 LLM 落地的实战派工程师,graphrag-server[1] 与 markify[2] 作者。
🎯 只分享最实用的技术方案与最佳实践,不谈空话!
📦 加入星球立享:
- ✅ 最新 hipporag2 精简代码
- ✅ GraphRAG 全套配置 + 手把手实体标注
- ✅ 技术私享问答,直击核心难题
🧰 热门开源项目:
- 🔹
graphrag-server:GraphRAG 接口服务 - 🔹
markify:高效文件解析助手
参考资料
[1]
graphrag-server: https://github.com/KylinMountain/graphrag-server
[2]
markify: https://github.com/KylinMountain/markify
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号