每日学术速递3.26 (New! 一图速览)


CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Power by Kimi&苏神 编辑丨AiCharm
Subjects: cs.CV
1.OpenVLThinker: An Early Exploration to Complex Vision-Language Reasoning via Iterative Self-Improvement

标题: OpenVLThinker:通过迭代自我改进实现复杂视觉语言推理的早期探索
作者:Yihe Deng, Hritik Bansal, Fan Yin, Nanyun Peng, Wei Wang, Kai-Wei Chang
文章链接:https://arxiv.org/abs/2503.17352
项目代码:https://github.com/yihedeng9/OpenVLThinker
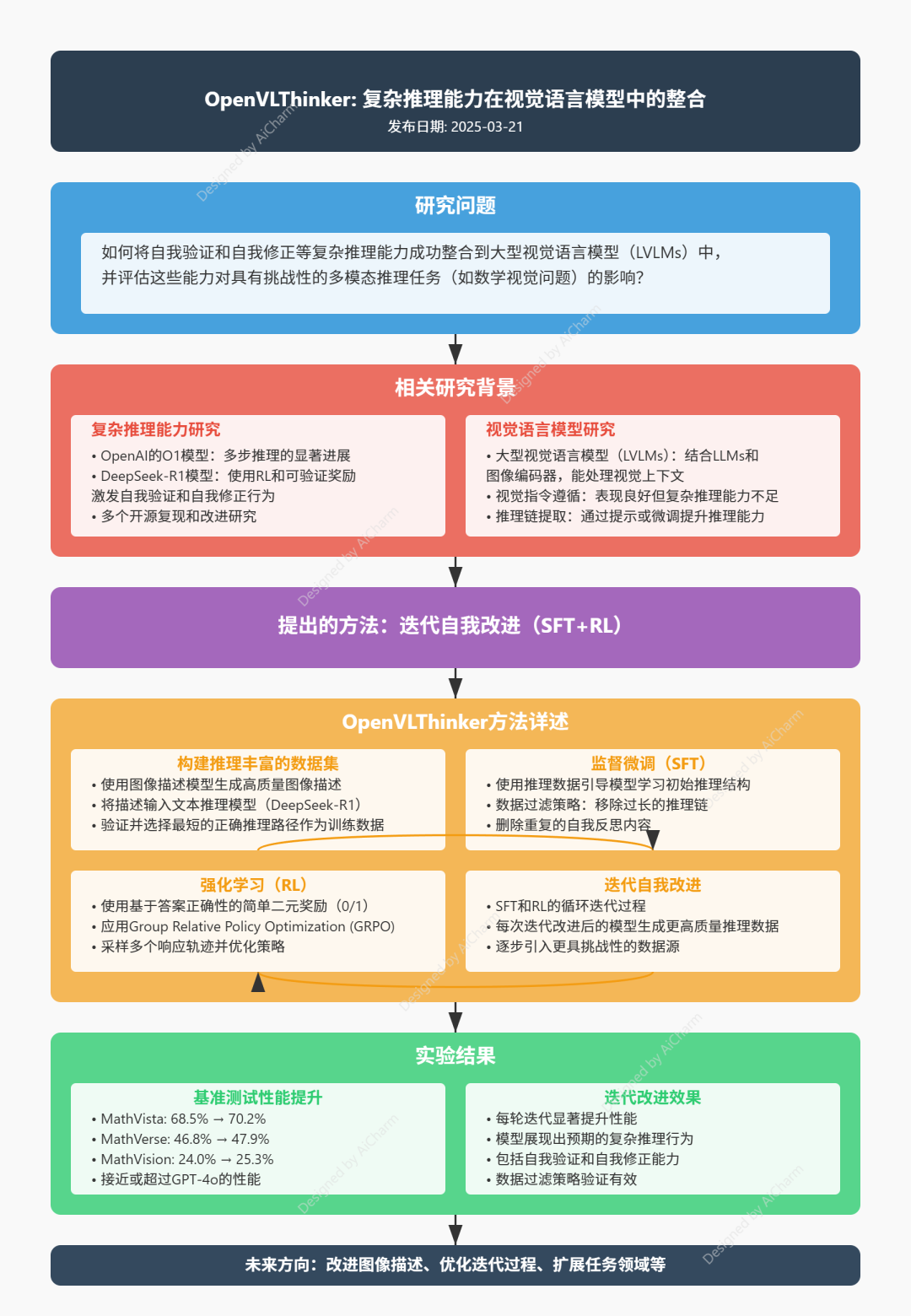

摘要:
DeepSeek-R1 所展示的最新进展表明,大型语言模型 (LLMs) 中的复杂推理能力(包括自我验证和自我纠正等复杂行为)可以通过具有可验证奖励的 RL 实现,并显著提高模型在 AIME 等具有挑战性的任务上的性能。受这些发现的启发,我们的研究调查了是否可以将类似的推理能力成功集成到大型视觉语言模型 (LVLM) 中,并评估了它们对具有挑战性的多模态推理任务的影响。我们考虑了一种迭代利用轻量级训练数据和强化学习 (RL) 的监督微调 (SFT) 来进一步提高模型泛化能力的方法。最初,推理能力是从纯文本 R1 模型中提取出来的,通过使用来自不同视觉数据集的图像的高质量字幕生成推理步骤。随后,迭代 RL 训练进一步增强了推理能力,每次迭代的 RL 改进模型都会为下一轮生成精炼的 SFT 数据集。这一迭代过程产生了 OpenVLThinker,这是一个 LVLM,在 MathVista、MathVerse 和 MathVision 等具有挑战性的基准上表现出持续改进的推理性能,展示了我们策略在强大的视觉语言推理方面的潜力。
这篇论文试图解决什么问题?
这篇论文试图解决的问题是如何将复杂的推理能力(如自我验证和自我修正等高级行为)成功整合到大型视觉语言模型(Large Vision-Language Models, LVLMs)中,并评估这些能力对具有挑战性的多模态推理任务的影响。具体来说,论文探索了如何通过迭代的自我改进方法,结合监督微调(Supervised Fine-Tuning, SFT)和强化学习(Reinforcement Learning, RL),来提升LVLMs在复杂视觉语言推理任务上的表现。
论文的主要目标是:
- 将复杂推理能力从纯文本模型迁移到多模态模型:通过从高质量的图像描述中生成推理步骤,将复杂的推理能力从纯文本模型(如DeepSeek-R1)迁移到LVLMs中。
- 通过迭代自我改进提升模型性能:利用SFT和RL的迭代过程,逐步提升模型的推理能力和泛化能力。
- 验证策略的有效性:通过在多个具有挑战性的多模态推理基准(如MathVista、MathVerse和MathVision)上评估模型性能,验证所提出策略的有效性。
论文如何解决这个问题?
论文通过以下方法解决将复杂推理能力整合到大型视觉语言模型(LVLMs)中的问题:
1. 构建推理丰富的数据集
- 图像描述生成:使用高质量的图像描述来生成推理步骤。具体来说,论文从多个视觉数据集中收集图像和相关问题,并使用一个图像描述模型(如Qwen2.5-VL-3B-Instruct)生成详细的图像描述。
- 文本推理模型蒸馏:将这些图像描述输入到一个文本推理模型(如DeepSeek-R1-Distill-14B),生成推理链。通过验证这些推理链的正确性,选择最短且正确的推理路径作为训练数据。
2. 监督微调(SFT)
- 初始推理结构:使用SFT来引导模型学习初始的推理结构。论文将从文本推理模型中蒸馏出的推理数据用于SFT,使模型能够生成结构化的推理链和最终答案。
- 数据过滤策略:为了防止模型学习到冗长和重复的推理行为,论文采用了数据过滤策略,如移除过长的推理链和删除重复的自我反思内容。
3. 强化学习(RL)
- 奖励函数:使用基于最终答案正确性的简单二元奖励函数(0/1),不依赖于额外的模板或格式奖励。
- GRPO算法:应用Group Relative Policy Optimization(GRPO)算法进行RL训练,以进一步提升模型的推理能力和泛化能力。GRPO通过采样多个响应轨迹并优化策略,使得模型能够生成更准确的推理链。
4. 迭代自我改进
- 迭代过程:结合SFT和RL的迭代过程,逐步提升模型的推理能力。每次迭代中,RL改进后的模型生成更高质量的推理数据,用于下一轮SFT训练。
- 数据源进化:在迭代过程中,逐步引入更具挑战性的数据源,以提升模型在复杂任务上的表现。
5. 模型评估
- 基准测试:在多个具有挑战性的多模态推理基准(如MathVista、MathVerse和MathVision)上评估模型性能,验证所提出方法的有效性。
- 性能提升:通过迭代的SFT和RL训练,模型在这些基准测试中表现出显著的性能提升,证明了所提出方法的有效性。
6. 实验结果
- 性能提升:实验结果显示,经过迭代的SFT和RL训练后,OpenVLThinker-7B在MathVista、MathVerse和MathVision等基准测试中表现优于基线模型Qwen2.5-VL-7B,并接近或超过GPT-4o的性能。
- 推理行为:模型展现出期望的推理行为,包括自我验证和自我修正,如在推理过程中进行自我反思和验证答案的正确性。
通过上述方法,论文成功地将复杂的推理能力整合到LVLMs中,并在多个多模态推理任务上验证了其有效性。
论文做了哪些实验?
论文中进行了多项实验来验证所提出方法的有效性。以下是主要的实验内容和结果:
1. 性能评估实验
- 基准测试:在多个具有挑战性的多模态推理基准上评估模型性能,包括MathVista、MathVerse和MathVision。
- 实验结果:
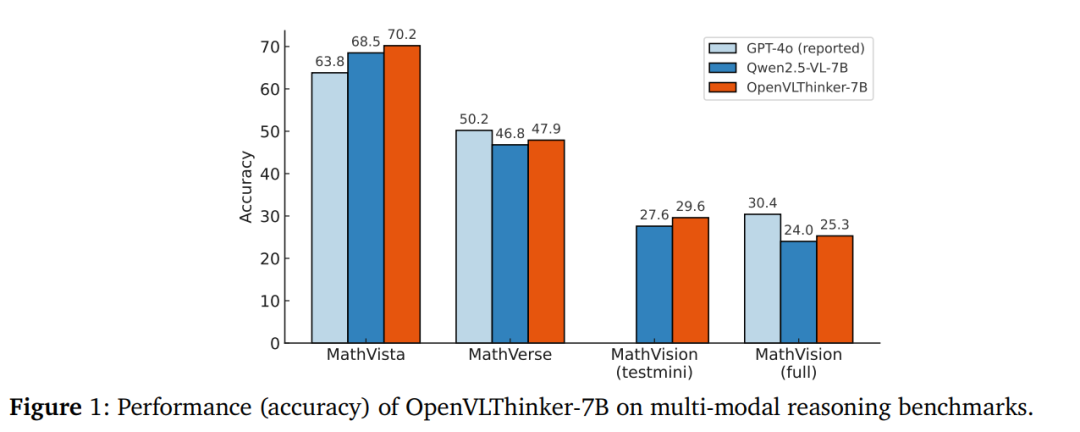
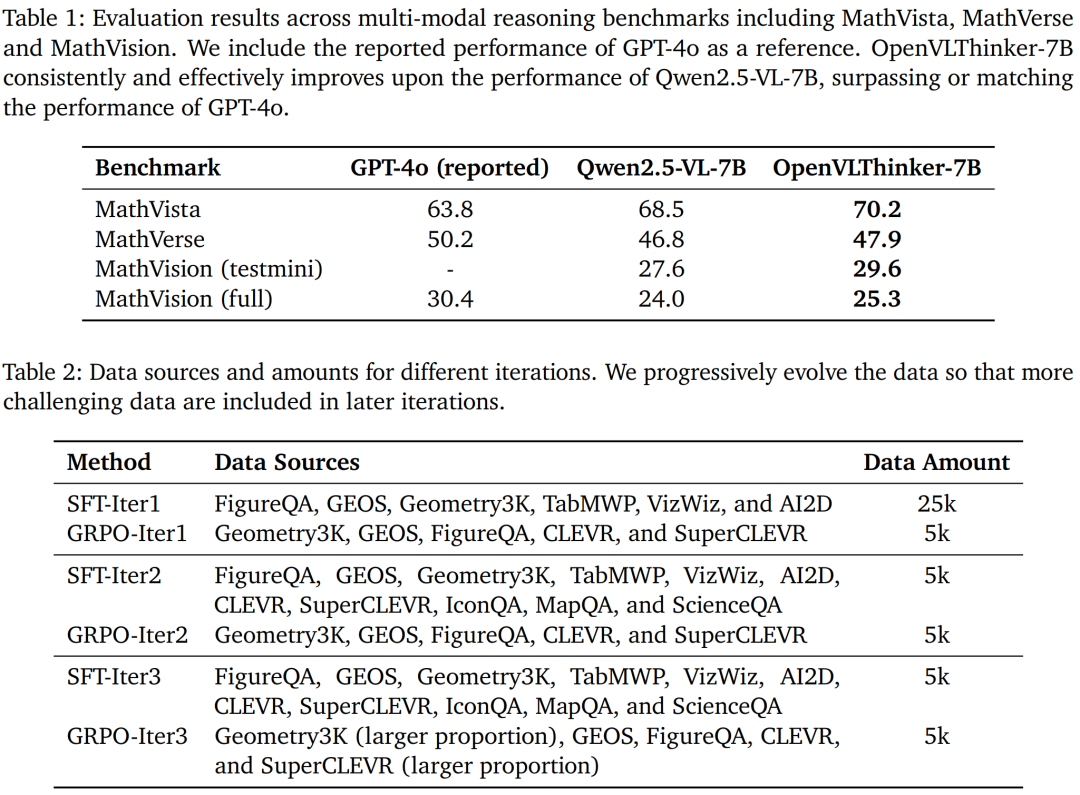
- MathVista:OpenVLThinker-7B的准确率从基线模型Qwen2.5-VL-7B的68.5%提升到70.2%。
- MathVerse:准确率从46.8%提升到47.9%。
- MathVision (testmini):准确率从29.6%提升到30.4%。
- MathVision (full):准确率从24.0%提升到25.3%。
这些结果表明,通过迭代的SFT和RL训练,OpenVLThinker-7B在这些基准测试中表现优于基线模型,并接近或超过GPT-4o的性能。
2. 迭代性能改进实验
- 迭代过程:通过多次迭代的SFT和RL训练,逐步提升模型的推理能力和泛化能力。
- 实验结果:
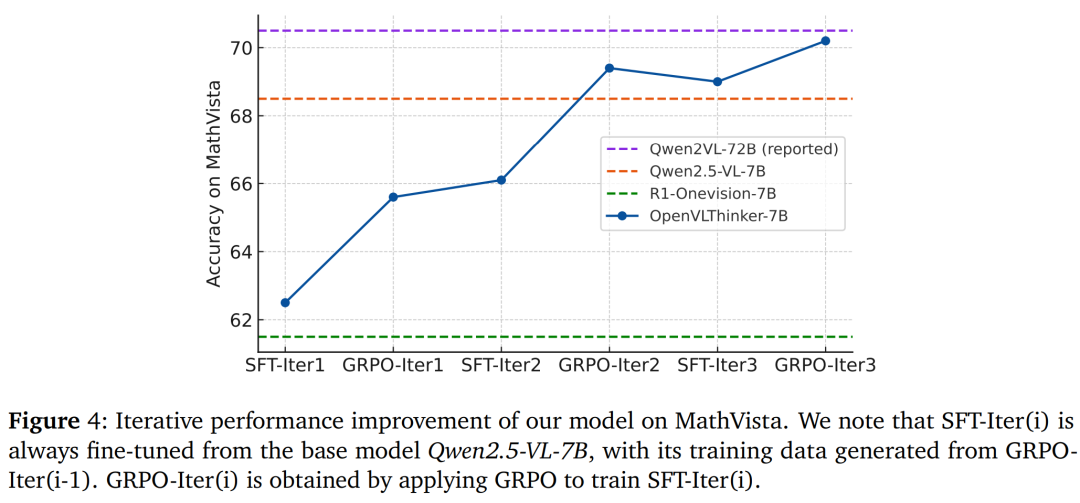
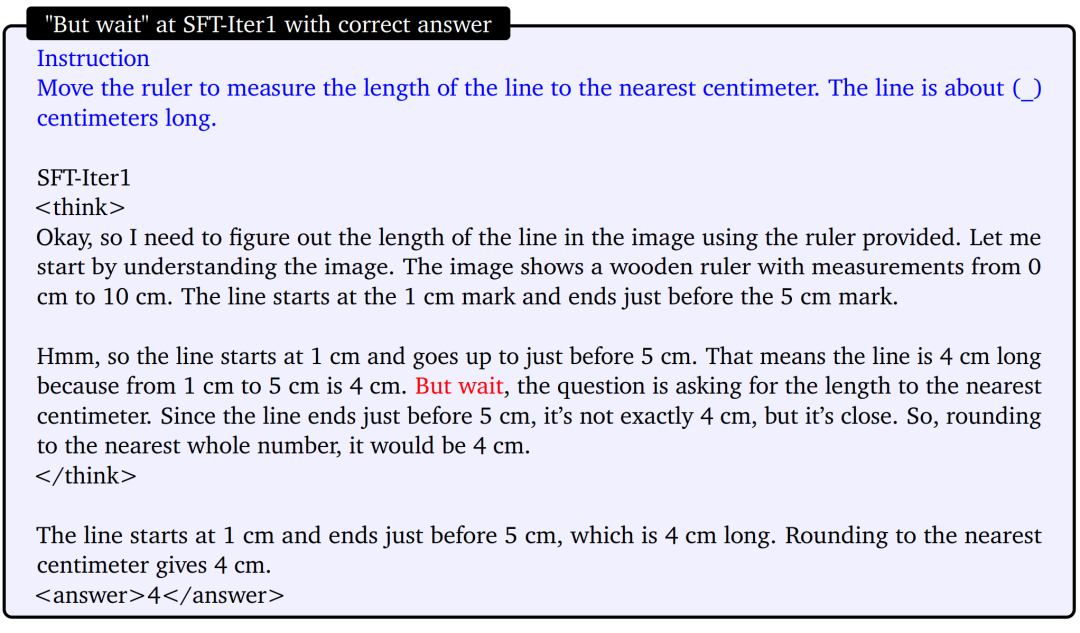
- SFT-Iter1:准确率从68.5%提升到62.5%。
- GRPO-Iter1:准确率从62.5%提升到65.6%。
- SFT-Iter2:准确率从65.6%提升到66.1%。
- GRPO-Iter2:准确率从66.1%提升到69.4%。
- SFT-Iter3:准确率从69.4%提升到70.2%。
这些结果表明,每次迭代都能有效提升模型的性能,证明了迭代自我改进方法的有效性。
3. 复杂推理能力的验证实验
- 推理行为分析:通过具体的推理示例,验证模型是否展现出期望的复杂推理行为,如自我验证和自我修正。
- 实验结果:OpenVLThinker-7B在多个推理示例中展现出良好的推理行为,包括自我反思和验证答案的正确性。例如,在一个几何问题中,模型不仅正确地推导出答案,还进行了自我验证,确保答案的正确性。
4. 数据过滤策略的验证实验
- 数据过滤策略:验证数据过滤策略对模型性能的影响。
- 实验结果:
- 未过滤数据:准确率下降到48.4%。
- 过滤长度小于500词的数据:准确率提升到55.0%。
- 移除重复自我反思的数据:准确率进一步提升到62.5%。
这些结果表明,数据过滤策略能有效提升模型的性能,避免学习到冗长和重复的推理行为。
5. 复杂推理能力的重要性实验
- 对比实验:通过对比实验验证复杂推理能力在视觉问答(VQA)任务中的重要性。
- 实验结果:
- 使用R1风格推理模型(DeepSeek-R1-Distill-14B):在多个VQA任务中表现优于标准指令调优模型(Qwen2.5-14B-Instruct)。
- 增加采样数量(k=2或k=4):R1模型的性能提升更为显著,表明多步推理方法在探索多个假设时更有效。
这些结果表明,复杂推理能力在视觉问答任务中具有显著的优势,能够提升模型的准确性和泛化能力。
6. 单次反馈循环对图像描述的改进实验
- 反馈循环:验证单次反馈循环是否能显著提升图像描述的质量,从而提升最终的VQA性能。
- 实验结果:
- 原始描述:准确率为33%(pass@1),37%(pass@2),44%(pass@4)。
- 经过反馈循环的描述:准确率为29%(pass@1),35%(pass@2),46%(pass@4)。
这些结果表明,单次反馈循环对图像描述的改进效果有限,可能需要更复杂的反馈机制才能显著提升性能。
通过这些实验,论文验证了所提出方法在提升LVLMs复杂推理能力方面的有效性,并展示了迭代自我改进方法在多模态推理任务中的潜力。
论文的主要内容:
本文介绍了一个名为OpenVLThinker-7B的大型视觉语言模型(LVLM),该模型通过迭代的自我改进方法,结合监督微调(SFT)和强化学习(RL),成功整合了复杂的推理能力。研究的主要贡献和发现如下:
研究背景与动机
- 复杂推理能力:近年来,大型语言模型(LLMs)在复杂推理任务上取得了显著进展,尤其是OpenAI的O1模型和DeepSeek-R1模型展示了自我验证和自我修正等高级行为。这些模型通过强化学习(RL)和可验证奖励显著提升了推理能力。
- 视觉语言模型的不足:尽管LVLMs在视觉语言预训练和视觉指令遵循方面表现出色,但在复杂多步推理方面存在不足。如何将复杂的推理能力整合到LVLMs中是一个未充分探索的问题。
研究方法
- 构建推理丰富的数据集:
- 使用高质量的图像描述生成推理步骤,从多个视觉数据集中收集图像和相关问题,并使用图像描述模型生成详细的图像描述。
- 将这些描述输入到文本推理模型中,生成推理链,并通过验证选择最短且正确的推理路径作为训练数据。
- 监督微调(SFT):
- 使用SFT引导模型学习初始的推理结构,通过过滤策略避免模型学习到冗长和重复的推理行为。
- 强化学习(RL):
- 使用基于最终答案正确性的简单二元奖励函数,应用Group Relative Policy Optimization(GRPO)算法进行RL训练,提升模型的推理能力和泛化能力。
- 迭代自我改进:
- 结合SFT和RL的迭代过程,逐步提升模型的推理能力。每次迭代中,RL改进后的模型生成更高质量的推理数据,用于下一轮SFT训练。
- 逐步引入更具挑战性的数据源,提升模型在复杂任务上的表现。
实验结果
- 性能提升:在多个具有挑战性的多模态推理基准(如MathVista、MathVerse和MathVision)上,OpenVLThinker-7B表现优于基线模型Qwen2.5-VL-7B,并接近或超过GPT-4o的性能。
- MathVista:准确率从68.5%提升到70.2%。
- MathVerse:准确率从46.8%提升到47.9%。
- MathVision (testmini):准确率从29.6%提升到30.4%。
- MathVision (full):准确率从24.0%提升到25.3%。
- 迭代性能改进:通过多次迭代的SFT和RL训练,模型性能逐步提升,证明了迭代自我改进方法的有效性。
- SFT-Iter1:准确率从68.5%提升到62.5%。
- GRPO-Iter1:准确率从62.5%提升到65.6%。
- SFT-Iter2:准确率从65.6%提升到66.1%。
- GRPO-Iter2:准确率从66.1%提升到69.4%。
- SFT-Iter3:准确率从69.4%提升到70.2%。
- 推理行为分析:OpenVLThinker-7B在多个推理示例中展现出良好的推理行为,包括自我反思和验证答案的正确性。
结论
本文通过迭代的SFT和RL训练,成功将复杂的推理能力整合到LVLMs中,并在多个多模态推理任务上验证了其有效性。这一初步结果展示了将R1风格的推理能力引入多模态上下文的潜力,为未来的研究提供了新的方向。
2.Beyond Semantics: Rediscovering Spatial Awareness in Vision-Language Models
标题:超越语义:重新发现视觉语言模型中的空间意识
作者:Jianing Qi, Jiawei Liu, Hao Tang, Zhigang Zhu
文章链接:https://arxiv.org/abs/2304.05977
项目代码:https://github.com/THUDM/ImageReward



摘要:
视觉语言模型 (VLM) 擅长识别和描述物体,但难以进行空间推理,例如准确理解物体的相对位置。受人类视觉双通路(腹侧-背侧)模型的启发,我们研究了为什么 VLM 尽管具有强大的物体识别能力,却无法完成空间任务。我们的可解释性驱动分析揭示了一个关键的根本原因:VLM 中的视觉嵌入主要被视为语义“标记袋”,由于其嵌入规范不成比例地大,掩盖了微妙但关键的位置线索。我们通过大量诊断实验验证了这一见解,表明当删除标记顺序或细粒度空间细节时,性能影响最小。在这些发现的指导下,我们提出了简单、可解释的干预措施,包括规范化视觉嵌入规范和提取中间层空间丰富的特征,以恢复空间意识。我们在合成数据和标准基准上的经验结果都表明空间推理能力有所提高,凸显了可解释性设计选择的价值。我们的研究不仅揭示了当前 VLM 架构的基本局限性,而且还为增强对视觉场景的结构化感知提供了可行的见解。
这篇论文试图解决什么问题?
这篇论文试图解决的问题是视觉-语言模型(Vision-Language Models, VLMs)在空间推理任务上的不足。尽管VLMs在识别和描述物体(ventral任务)方面表现出色,但在理解物体之间的相对位置(dorsal任务)方面却存在系统性困难。例如,即使能够准确识别出“苹果”和“杯子”,VLMs却常常无法正确判断“苹果是否在杯子的左边”。论文的核心目标是探索为什么VLMs会在空间推理方面失败,并提出改进方法以增强其空间感知能力。
具体来说,论文的主要贡献包括:
- 提出一个基于可解释性的理论解释,说明VLMs在空间推理任务中失败的原因,即嵌入范数抑制(embedding norm suppression)。
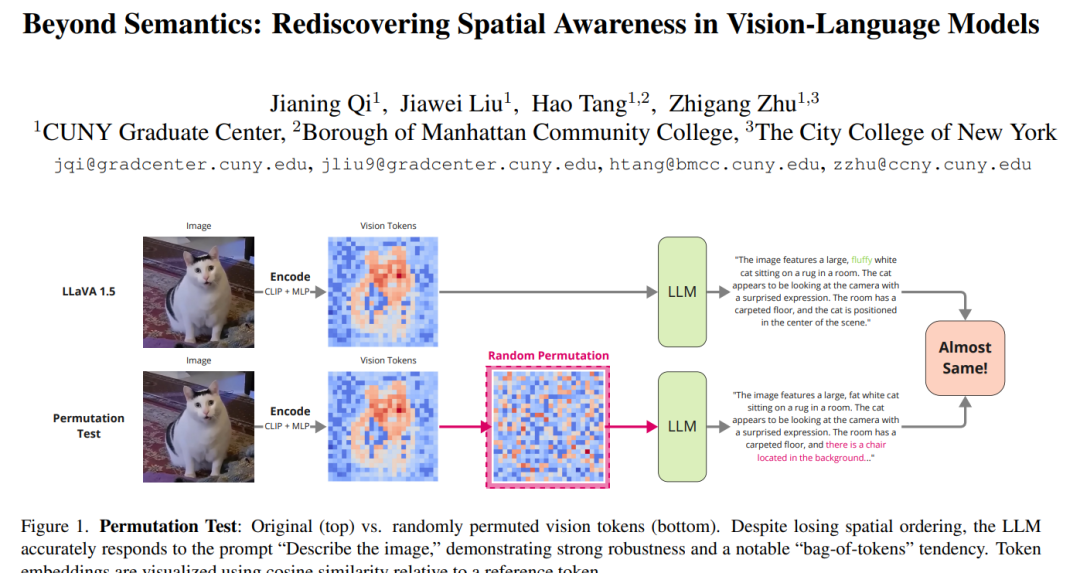
- 通过系统性的实验验证这一理论,包括随机打乱视觉令牌顺序和压缩空间信息,发现VLMs对这些操作表现出显著的鲁棒性,表明其倾向于“词袋模型(bag-of-tokens)”行为。
- 提出一种简单的、可解释的干预措施,通过归一化视觉嵌入范数和提取中间层特征来恢复空间感知能力,并在合成数据和标准基准测试中验证了这些方法的有效性。
论文如何解决这个问题?
论文通过以下几个步骤来解决视觉-语言模型(VLMs)在空间推理任务上的不足问题:
1. 诊断问题:词袋模型(Bag of Tokens)倾向
论文首先通过两个诊断实验来验证VLMs是否忽视了空间信息:
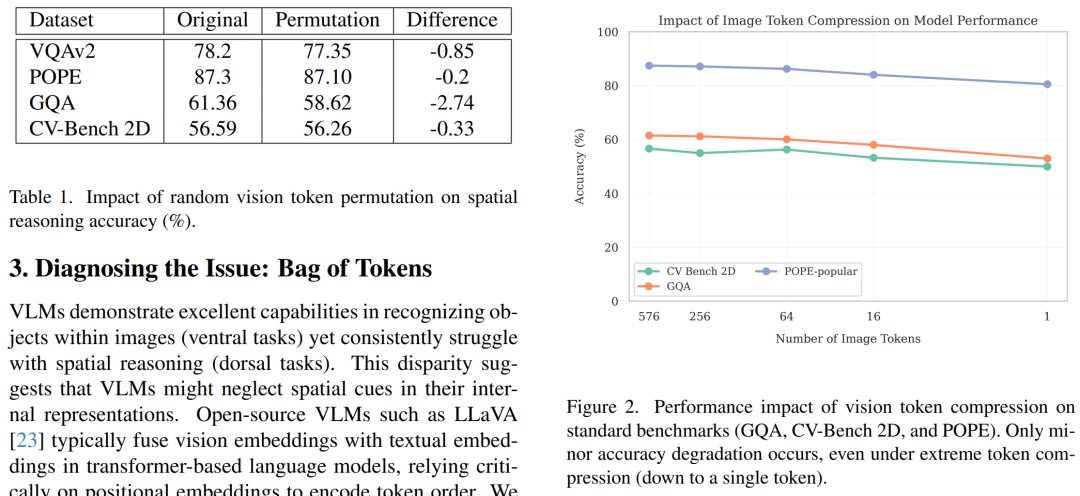
- Token Permutation Test(令牌排列测试):如果位置顺序对空间推理很重要,那么随机打乱视觉令牌的顺序应该会显著降低模型性能。实验结果表明,随机排列视觉令牌对性能的影响非常小,这表明VLMs对令牌顺序不敏感,呈现出“词袋模型”倾向。
- Spatial Compression Study(空间压缩研究):如果局部空间信息很重要,那么大幅减少视觉令牌的数量应该会导致性能显著下降。实验结果表明,即使将视觉令牌数量从576减少到1,性能下降也非常有限,这进一步支持了VLMs主要依赖语义信息而不是空间信息的假设。
2. 分析原因:嵌入范数抑制(Embedding Norm Suppression)
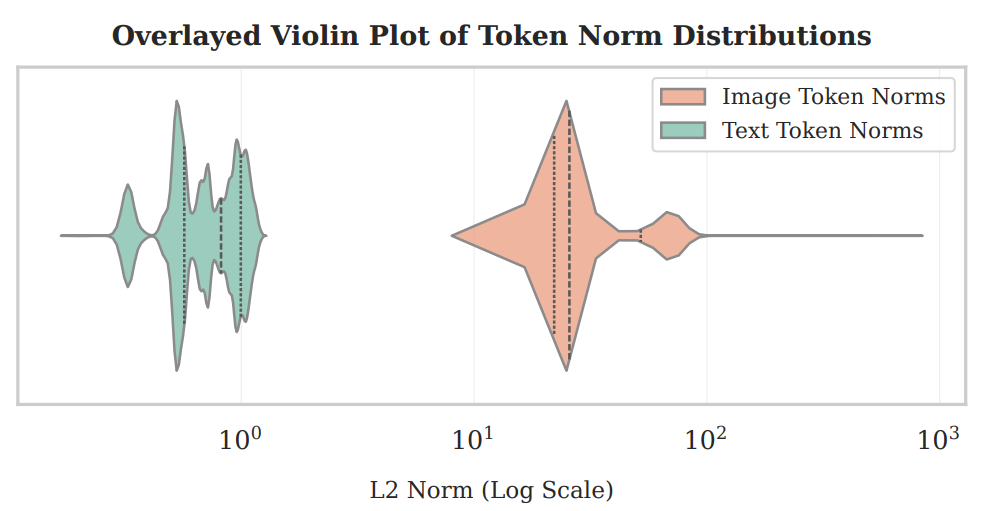
论文进一步分析了为什么VLMs会忽视空间信息。通过分析嵌入范数,发现视觉嵌入的范数通常比文本嵌入的范数大1到2个数量级,有时甚至达到3个数量级。这种巨大的范数差异导致位置编码在注意力机制中被掩盖。论文通过理论推导和实验验证了这一点:
- 理论推导:在Transformer的自注意力机制中,视觉嵌入的高范数导致视觉到文本的注意力分数过高。为了保持文本输出的连贯性,模型会隐式地降低这些视觉相关的注意力分数,从而削弱了位置编码的效果。
- 实验验证:通过计算视觉和文本嵌入的L2范数,发现视觉嵌入的范数远大于文本嵌入的范数,这证实了嵌入范数差异对位置编码的影响。
3. 提出解决方案:恢复空间感知能力
基于上述分析,论文提出了两种简单的、可解释的干预措施来恢复VLMs的空间感知能力:
- Vision Token Normalization(视觉令牌归一化):通过RMS归一化将视觉嵌入的范数调整到与文本嵌入相近的范围,从而减少语义信号的主导作用,使位置编码能够更清晰地显现。
- Intermediate-Layer Features(中间层特征):直接利用视觉编码器的中间层特征,这些特征保留了更丰富的局部空间信息,有助于提高空间推理能力。
4. 实验验证
论文通过在合成数据集和标准基准测试上进行实验,验证了这些干预措施的有效性:
- 合成数据集(2DS):该数据集专门设计用于测试空间推理能力,消除了语义捷径。实验结果表明,归一化和中间层特征的结合显著提高了模型在空间推理任务上的性能。
- 标准基准测试:在VQAv2、POPE、GQA和CV-Bench等标准基准测试上,归一化和中间层特征的结合也显示出一致的性能提升,尤其是在空间关系任务上。
5. 分析注意力机制的影响
论文进一步分析了这些干预措施对VLMs注意力机制的影响:
- 注意力可视化:通过可视化注意力图,发现归一化后的模型能够更集中地关注相关的空间令牌,而中间层特征的加入则使注意力更加稀疏但更具选择性。
- 注意力熵分析:通过计算注意力熵,发现归一化后的模型在空间区域的探索上更加广泛和均匀,而中间层特征的加入则使模型更有信心地关注特定的空间区域。
通过这些步骤,论文不仅揭示了VLMs在空间推理任务中失败的根本原因,还提出了有效的解决方案,并通过实验验证了这些解决方案的有效性。这些发现为未来VLMs的设计和改进提供了重要的指导。
论文做了哪些实验?
论文中进行了以下几类实验来验证其观点和提出的解决方案:
诊断性实验
Token Permutation Test(令牌排列测试)
- 目的:验证视觉令牌的顺序是否对空间推理性能有显著影响。
- 方法:使用LLaVA 1.5 7B模型,随机打乱从视觉编码器和投影层获得的视觉令牌嵌入的顺序,然后将这些打乱顺序的视觉令牌输入到LLM中,并与原始未打乱顺序的基线性能进行比较。
- 数据集:VQAv2、POPE、GQA和CV-Bench。
- 结果:随机令牌排列只导致了较小的性能下降(从0.2%到2.74%),这表明VLMs对视觉令牌的顺序不敏感,呈现出“词袋模型”的倾向。
Spatial Compression Study(空间压缩研究)
- 目的:探究VLMs对局部空间信息的依赖程度。
- 方法:使用LLaVA 1.5 7B模型,系统地减少视觉令牌的数量,从原始的576个减少到1个。通过在MLP投影层后使用平均池化来实现,这种方法严重限制了局部空间细节,但保留了一些语义内容。然后在各种基准测试上评估性能影响。
- 结果:即使将视觉令牌数量从576减少到1,性能下降也非常有限(最坏情况下下降8.5%),这表明VLMs主要依赖语义线索而不是局部空间细节来完成典型基准测试任务。
机制分析实验
Embedding Norm Analysis(嵌入范数分析)
- 目的:分析视觉嵌入和文本嵌入的范数差异,以及这种差异如何影响位置编码在注意力机制中的有效性。
- 方法:使用COCO验证数据集(5000个图像-文本对),提取视觉和文本嵌入的L2范数,并进行比较。
- 结果:视觉嵌入的范数通常比文本嵌入的范数大1到2个数量级,有时甚至达到3个数量级。这种巨大的范数差异导致位置编码在注意力计算中被掩盖。
解决方案验证实验
Controlled Study with Synthetic Dataset(使用合成数据集的对照研究)
- 目的:验证提出的解决方案是否能够有效增强VLMs的空间感知能力。
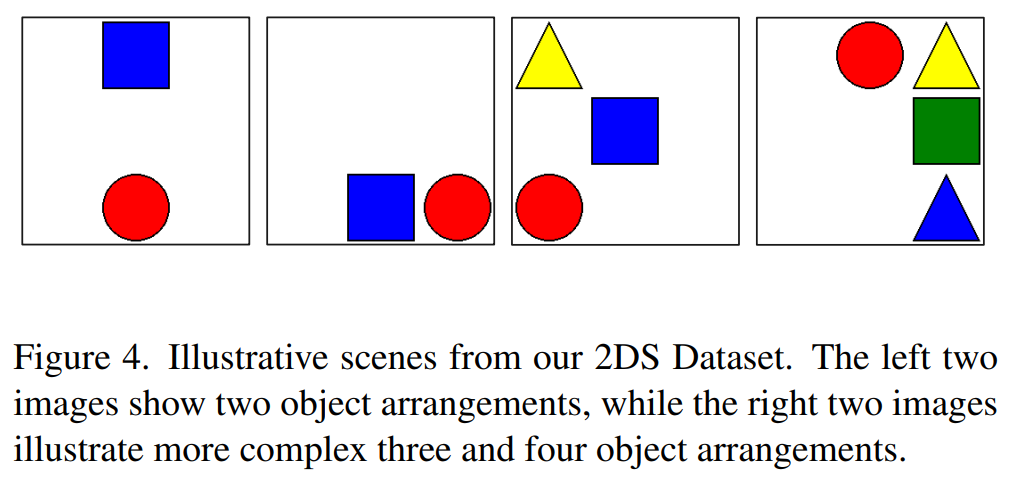
- 方法:设计了一个二维合成空间基准数据集(2DS),该数据集专门用于测试空间推理能力,消除了语义捷径。数据集包含不同数量的对象(2到6个),并针对每张图像系统地提出了结合语义(颜色、形状)和空间(绝对、相对)属性的问题。
- 模型变体:
- + Normalize:对视觉嵌入进行归一化处理。
- + Normalize + Multilayer:在归一化的基础上,加入中间层特征以保留更细致的空间信息。
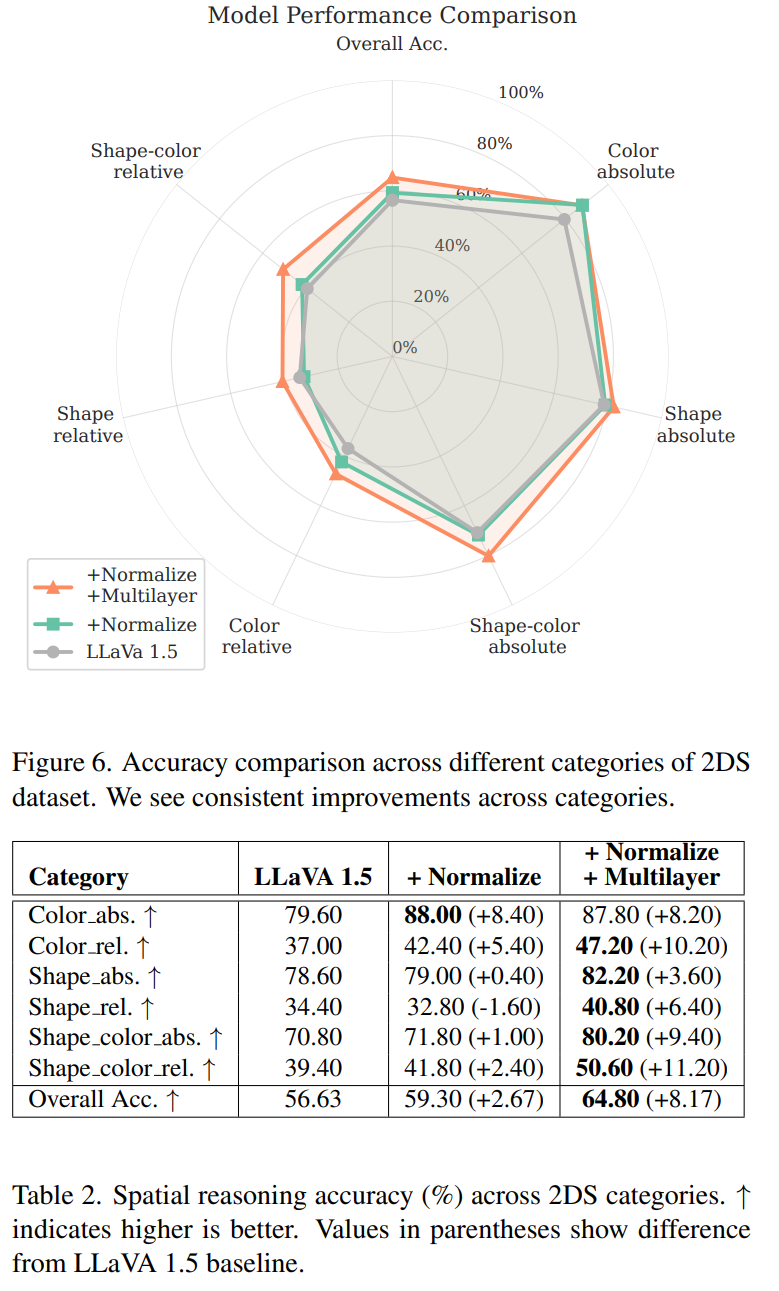
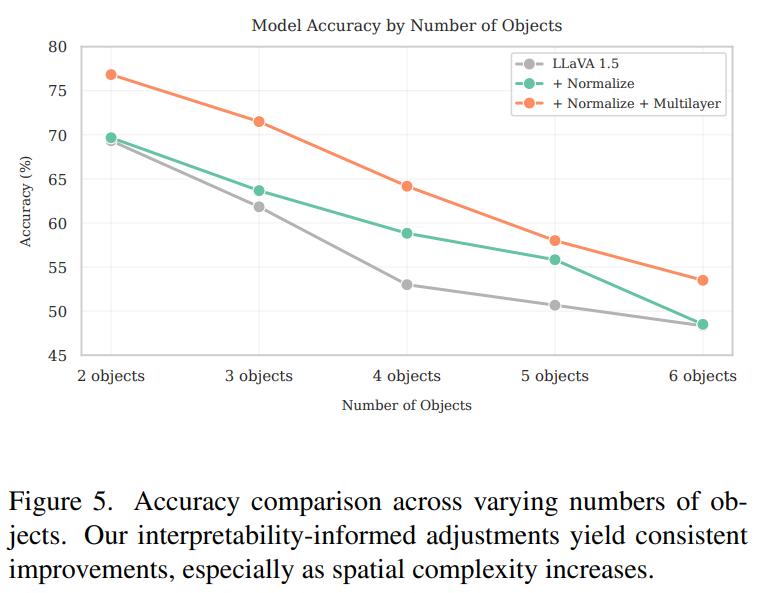
- 结果:在2DS数据集上,归一化和中间层特征的结合显著提高了模型在空间推理任务上的性能,尤其是在形状和颜色结合的相对位置查询上。
Experiments on Standard Benchmarks(标准基准测试实验)
- 目的:验证提出的解决方案在标准基准测试上的泛化能力。
- 方法:在VQAv2、POPE、GQA和CV-Bench等标准基准测试上评估归一化和中间层特征的结合效果。
- 结果:归一化和中间层特征的结合在这些标准基准测试上也显示出一致的性能提升,尤其是在空间关系任务上。
注意力机制分析实验
Attention Visualization(注意力可视化)
- 目的:通过可视化注意力图来解释归一化和中间层特征对空间推理的影响。
- 方法:选择具有代表性的查询,比较原始LLaVA 1.5模型、归一化模型和归一化加中间层特征模型的注意力图。
- 结果:归一化模型的注意力图更加集中,显示出对相关空间令牌的明确关注。而归一化加中间层特征模型的注意力图则更加稀疏,显示出对特定空间区域的高选择性关注。
Attention Entropy Analysis(注意力熵分析)
- 目的:定量分析注意力图的分布特性。
- 方法:计算归一化和中间层特征模型的注意力熵,并与原始模型进行比较。
- 结果:归一化模型的注意力熵高于原始模型,表明其在空间区域的探索上更加广泛和均匀。而归一化加中间层特征模型的注意力熵最低,表明其对特定空间区域的关注更加集中。
这些实验共同验证了论文提出的观点,即VLMs在空间推理任务上的不足主要是由于嵌入范数差异导致的位置编码被掩盖,而通过归一化和中间层特征的结合可以有效增强VLMs的空间感知能力。
论文的主要内容:
论文《Beyond Semantics: Rediscovering Spatial Awareness in Vision-Language Models》主要研究了视觉-语言模型(VLMs)在空间推理任务中的不足,并提出了相应的解决方案。以下是论文的主要内容总结:
研究背景
- 人类视觉的双通路模型:人类通过腹侧通路(ventral stream)识别物体,通过背侧通路(dorsal stream)编码空间关系。VLMs在物体识别(腹侧任务)方面表现出色,但在空间推理(背侧任务)方面存在困难。
- VLMs的空间推理问题:尽管VLMs能够准确识别物体,但在理解物体之间的相对位置时却常常失败。例如,判断“苹果是否在杯子的左边”这类问题时,VLMs的表现不佳。
诊断问题:词袋模型(Bag of Tokens)倾向
- Token Permutation Test(令牌排列测试):通过随机打乱视觉令牌的顺序,发现VLMs对令牌顺序不敏感,表现出“词袋模型”的倾向。
- Spatial Compression Study(空间压缩研究):通过减少视觉令牌的数量,发现VLMs对局部空间信息的依赖程度很低,主要依赖语义信息。
分析原因:嵌入范数抑制(Embedding Norm Suppression)
- 嵌入范数分析:发现视觉嵌入的范数通常比文本嵌入的范数大1到2个数量级,有时甚至达到3个数量级。这种巨大的范数差异导致位置编码在注意力机制中被掩盖。
- 理论推导:通过数学推导,证明了视觉嵌入的高范数会导致注意力分数过高,模型为了保持文本输出的连贯性,会隐式地降低这些视觉相关的注意力分数,从而削弱了位置编码的效果。
提出解决方案:恢复空间感知能力
- Vision Token Normalization(视觉令牌归一化):通过RMS归一化将视觉嵌入的范数调整到与文本嵌入相近的范围,减少语义信号的主导作用,使位置编码能够更清晰地显现。
- Intermediate-Layer Features(中间层特征):直接利用视觉编码器的中间层特征,这些特征保留了更丰富的局部空间信息,有助于提高空间推理能力。
实验验证
- 合成数据集(2DS):设计了一个二维合成空间基准数据集,专门用于测试空间推理能力,消除了语义捷径。实验结果表明,归一化和中间层特征的结合显著提高了模型在空间推理任务上的性能。
- 标准基准测试:在VQAv2、POPE、GQA和CV-Bench等标准基准测试上,归一化和中间层特征的结合也显示出一致的性能提升,尤其是在空间关系任务上。
注意力机制分析
- 注意力可视化:通过可视化注意力图,发现归一化模型的注意力图更加集中,显示出对相关空间令牌的明确关注。而归一化加中间层特征模型的注意力图则更加稀疏,显示出对特定空间区域的高选择性关注。
- 注意力熵分析:通过计算注意力熵,发现归一化模型在空间区域的探索上更加广泛和均匀,而归一化加中间层特征模型对特定空间区域的关注更加集中。
结论
论文通过系统性的诊断和可解释性分析,揭示了VLMs在空间推理任务中失败的根本原因,并提出了简单的干预措施来恢复空间感知能力。这些干预措施在合成数据集和标准基准测试上都取得了显著的效果,为未来VLMs的设计和改进提供了重要的指导。
未来方向
- 更复杂的空间推理任务:扩展到三维空间推理和动态场景理解。
- 改进的归一化方法:探索更复杂的归一化方法和多模态归一化策略。
- 模型架构的改进:设计专门的空间感知模块和端到端训练方法。
- 数据集和任务设计:开发更具挑战性的基准测试和多模态数据集。
- 注意力机制的优化:进一步优化注意力机制,以更好地利用空间信息。
- 模型的泛化能力:研究模型在不同领域和场景中的泛化能力,特别是在零样本和少样本学习场景中。
- 理论分析和模型解释:深化对VLMs空间感知能力的理论分析,开发更先进的模型解释方法。
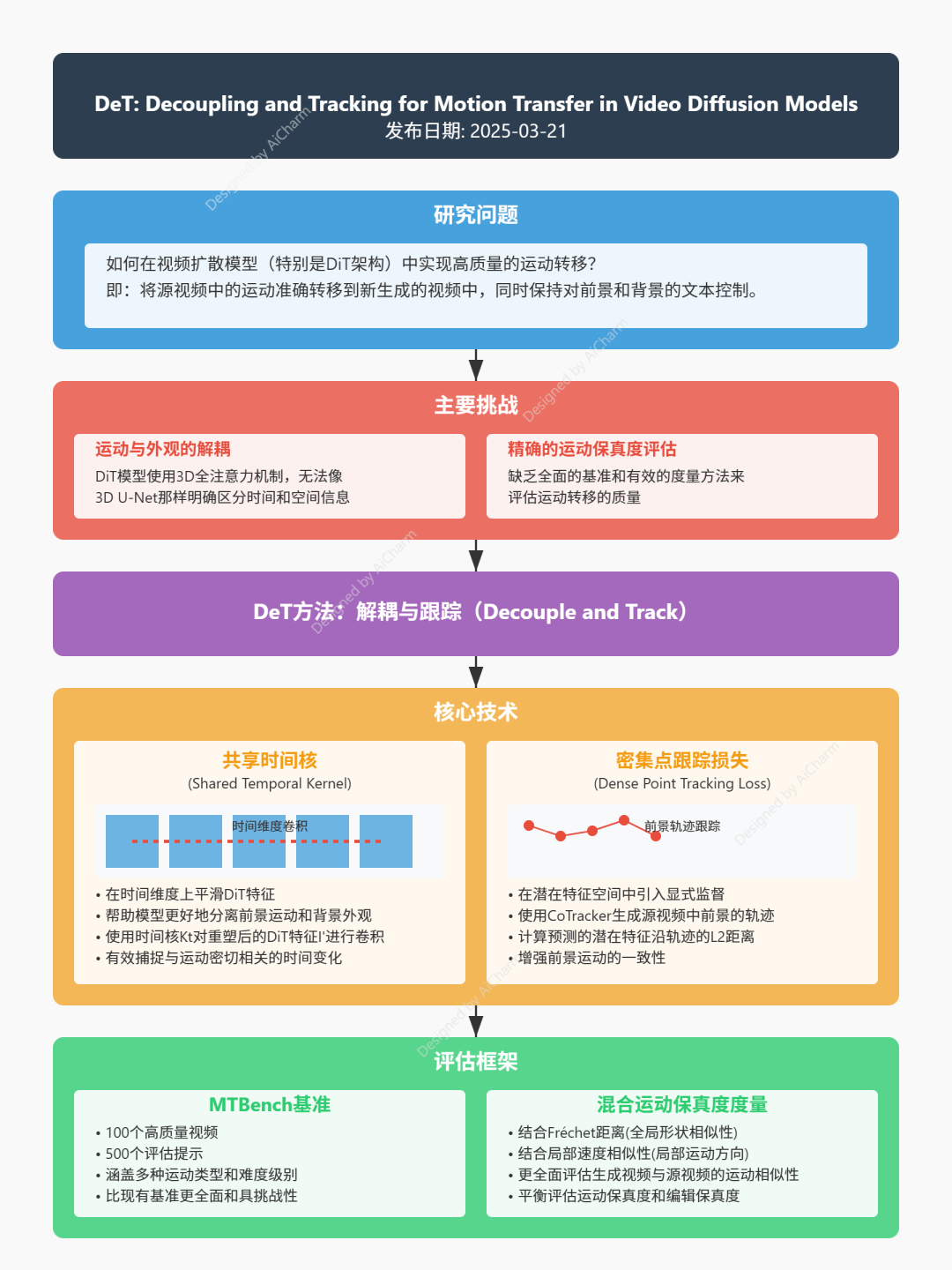
3.Decouple and Track: Benchmarking and Improving Video Diffusion Transformers for Motion Transfer

标题: 解耦和跟踪:对运动传输的视频扩散变换器进行基准测试和改进
作者:Qingyu Shi, Jianzong Wu, Jinbin Bai, Jiangning Zhang, Lu Qi, Xiangtai Li, Yunhai Tong
文章链接:https://arxiv.org/abs/2503.17350
项目代码:https://github.com/microsoft/AdaM









摘要:
运动迁移任务涉及将运动从源视频迁移到新生成的视频,这需要模型将运动与外观分离。以前基于扩散的方法主要依赖于 3D U-Net 中单独的空间和时间注意机制。相比之下,最先进的视频扩散变换器 (DiT) 模型使用 3D 全注意机制,它没有明确分离时间和空间信息。因此,空间和时间维度之间的相互作用使得 DiT 模型的运动和外观分离更具挑战性。在本文中,我们提出了 DeT,一种调整 DiT 模型以提高运动迁移能力的方法。我们的方法引入了一个简单而有效的时间核来平滑时间维度上的 DiT 特征,从而有助于将前景运动与背景外观分离。同时,时间核有效地捕捉了与运动密切相关的 DiT 特征的时间变化。此外,我们在潜在特征空间中沿密集轨迹引入了显式监督,以进一步增强运动一致性。此外,我们提出了 MTBench,这是一个通用且具有挑战性的运动迁移基准。我们还引入了一种混合运动保真度度量,该度量同时考虑了全局和局部运动相似性。因此,我们的工作比以前的工作提供了更全面的评估。在 MTBench 上进行的大量实验表明,DeT 在运动保真度和编辑保真度之间实现了最佳平衡。
这篇论文试图解决什么问题?
这篇论文试图解决视频扩散模型(Video Diffusion Models)在运动转移(Motion Transfer)任务中的挑战,即如何将一个源视频中的运动准确地转移到新生成的视频中,同时保持对前景和背景的灵活文本控制。具体来说,论文主要关注以下几个问题:
- 运动与外观的解耦(Decoupling Motion and Appearance):
- 运动转移任务的核心挑战是从源视频中分离运动信息和外观信息。以往的方法主要依赖于3D U-Net中的分离式时空注意力机制,但这些方法与最新的视频扩散Transformer(DiT)模型不兼容。DiT模型使用3D全注意力机制,没有明确区分时间和空间信息,这使得运动与外观的解耦更加困难。
- 提升运动转移的准确性(Improving Motion Transfer Accuracy):
- 论文提出了一种新的方法DeT(Decouple and Track),通过引入共享时间核(Shared Temporal Kernel)和密集点跟踪损失(Dense Point Tracking Loss),来改善DiT模型在运动转移任务中的表现。共享时间核通过在时间维度上平滑特征,帮助模型更好地分离前景运动和背景外观。密集点跟踪损失则通过在潜在特征空间中引入显式监督,增强前景运动的一致性。
- 建立一个更具挑战性的基准(Creating a Challenging Benchmark):
- 论文提出了一个新的运动转移基准MTBench,它包含100个高质量视频和500个评估提示,涵盖了多种运动类型和难度级别。与以往的基准相比,MTBench更加全面和具有挑战性,能够更好地评估运动转移方法的性能。
- 评估运动保真度(Evaluating Motion Fidelity):
- 论文引入了一种混合运动保真度度量(Hybrid Motion Fidelity Metric),结合了Fréchet距离和局部速度相似性,用于更全面地评估生成视频与源视频之间的运动相似性。
总的来说,论文的目标是通过改进DiT模型,使其能够更有效地进行运动转移,同时提供一个更全面的评估框架来衡量不同方法的性能。
论文如何解决这个问题?
论文通过提出一种名为 DeT(Decouple and Track) 的方法来解决视频扩散模型(DiT)在运动转移任务中的挑战。具体来说,DeT通过以下两个主要技术手段来解决运动与外观解耦的问题,并提升运动转移的准确性:
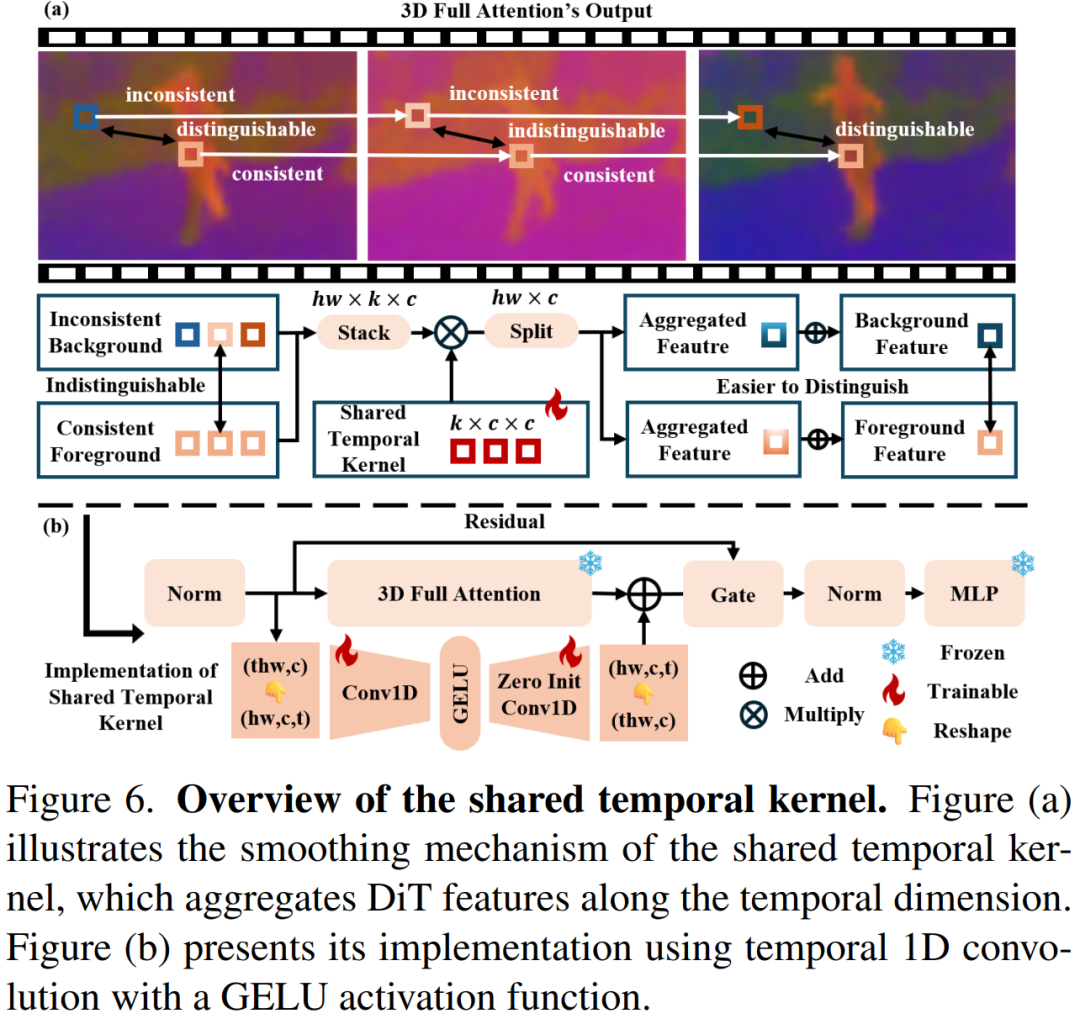
1. 共享时间核(Shared Temporal Kernel)
- 动机:在分析DiT模型的特征时,作者发现前景和背景的特征在某些帧中难以区分,导致背景外观与前景运动无法正确解耦。此外,作者观察到在去噪过程中,背景特征的时间不一致性使得区分前景和背景变得困难。为了改善这一点,作者提出在时间维度上平滑DiT特征,以帮助模型更精确地分离前景和背景。
- 实现:共享时间核通过在时间维度上对DiT特征进行卷积操作来实现平滑。具体来说,作者使用一个时间核 Kt∈Rk×c×cKt∈Rk×c×c 对重塑后的DiT特征 I′∈Rhw×t×cI′∈Rhw×t×c 进行卷积。这一操作不仅有助于解耦前景运动和背景外观,还能够有效地捕捉与运动密切相关的时间变化。
- 效果:通过在所有DiT块中集成共享时间核,模型能够更好地对齐运动,同时确保前景和背景外观的解耦。实验结果表明,这种方法在运动保真度和编辑保真度方面都取得了显著的提升。
2. 密集点跟踪损失(Dense Point Tracking Loss)
- 动机:为了进一步增强前景运动的一致性,作者引入了密集点跟踪损失。这一损失函数基于这样一个观察:前景的DiT特征在时间上保持一致。通过在潜在特征空间中引入显式监督,模型能够更好地对齐前景轨迹上的特征,从而鼓励生成一致的运动动态。
- 实现:作者使用CoTracker [25]来跟踪源视频中的前景,生成一组轨迹 T∈RN×T×2T∈RN×T×2。在训练过程中,计算预测的潜在特征 E^(S)E^(S) 沿轨迹的L2距离,并仅在可见点上应用损失函数。最终的损失是去噪损失(DL)和密集点跟踪损失(TL)的加权和。
- 效果:密集点跟踪损失显著提高了前景运动的一致性,使得生成的视频在运动模式上更加贴近源视频。实验结果表明,这一损失函数在提升运动保真度方面发挥了重要作用。
3. MTBench基准和混合运动保真度度量
- MTBench基准:为了全面评估运动转移方法的性能,作者提出了一个新的基准MTBench。MTBench包含100个高质量视频和500个评估提示,涵盖了多种运动类型和难度级别。与以往的基准相比,MTBench更加全面和具有挑战性。
- 混合运动保真度度量:作者引入了一种混合运动保真度度量,结合了Fréchet距离和局部速度相似性。Fréchet距离用于衡量轨迹的全局形状相似性,而局部速度相似性则用于比较轨迹之间的局部速度方向。这种混合度量能够更全面地评估生成视频与源视频之间的运动相似性。
总结
通过引入共享时间核和密集点跟踪损失,DeT方法有效地解决了DiT模型在运动转移任务中的挑战。共享时间核通过在时间维度上平滑特征,帮助模型更好地解耦前景运动和背景外观;密集点跟踪损失则通过在潜在特征空间中引入显式监督,增强了前景运动的一致性。此外,MTBench基准和混合运动保真度度量为评估运动转移方法提供了一个更全面的框架。实验结果表明,DeT在运动保真度和编辑保真度之间取得了最佳平衡,显著优于现有的方法。
论文做了哪些实验?
论文中进行了以下几类实验来验证所提方法DeT的有效性和性能:
1. 定性结果(Qualitative Results)
- 运动转移效果展示:通过对比源视频和生成视频,展示DeT在不同难度级别(简单、中等、困难)的运动转移任务上的效果。生成视频能够准确地保留源视频的运动模式,同时允许通过文本提示灵活控制前景和背景。
- 跨类别运动转移:展示了从一个类别(如人类)到另一个类别(如熊猫)的运动转移效果,验证了DeT方法的泛化能力。
- 与现有方法的对比:将DeT与其他现有的运动转移方法(如MotionDirector、SMA、MotionClone等)进行对比,展示DeT在运动保真度和编辑保真度方面的优势。
2. 定量结果(Quantitative Results)
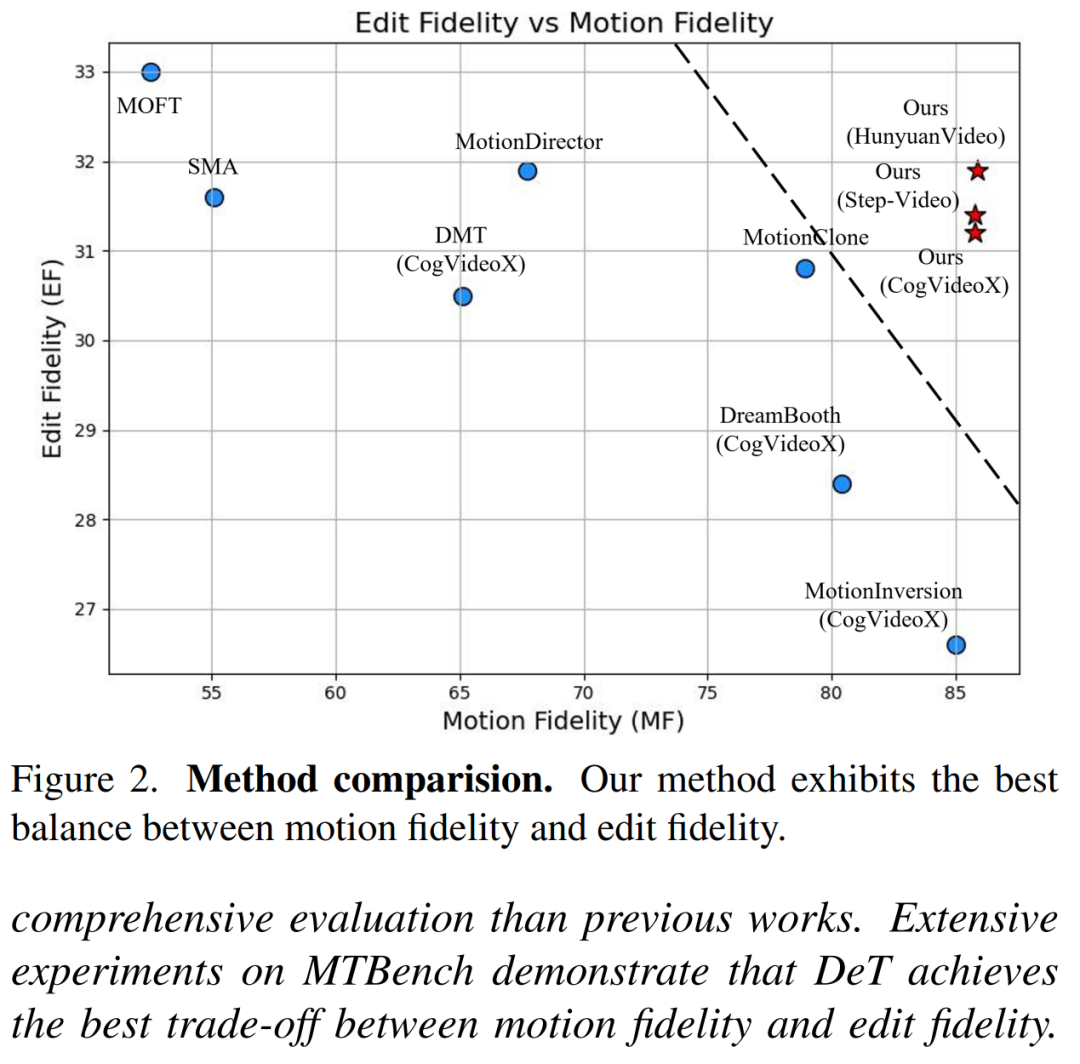
- 在MTBench基准上的评估:使用MTBench基准对DeT进行评估,该基准包含100个高质量视频和500个评估提示,涵盖了多种运动类型和难度级别。评估指标包括:
- 运动保真度(Motion Fidelity):结合Fréchet距离和局部速度相似性的混合度量,用于评估生成视频与源视频之间的运动相似性。
- 编辑保真度(Edit Fidelity):使用CLIP模型计算生成视频的每一帧与目标文本提示之间的相似度,评估文本控制的效果。
- 时间一致性(Temporal Consistency):通过计算连续帧之间的DINO特征的余弦相似度,评估生成视频的时间连贯性。
- 与现有方法的对比:在MTBench基准上,将DeT与其他现有方法(如MotionDirector、SMA、MotionClone等)进行对比,展示DeT在各项指标上的优越性。
3. 消融研究(Ablation Studies)
- 共享时间核的有效性:通过对比使用共享时间核和其他替代方法(如LoRA、Conv3D、局部注意力等),验证共享时间核在运动保真度和编辑保真度方面的有效性。
- 密集点跟踪损失的影响:通过调整密集点跟踪损失的权重 λTLλTL,研究其对运动保真度和编辑保真度的影响。
- 超参数调整:
- 丢弃层的比例:研究在推理阶段丢弃共享时间核的层数对性能的影响。
- 时间核的大小:研究不同时间核大小对性能的影响。
- 中间维度:研究共享时间核的中间维度对性能的影响。
4. 额外分析(Additional Analysis)
- 丢弃层策略的分析:通过分析DiT模型在不同层的特征和注意力图,解释为什么在推理阶段丢弃共享时间核的某些层可以提高文本控制能力。
- 不同DiT模型的性能对比:在不同的DiT模型(如CogVideoX-5B、HunyuanVideo、StepVideo-T2V)上应用DeT,验证其泛化能力。
5. 更多定性结果(More Qualitative Results)
- 额外的定性对比:提供了更多的定性对比结果,展示DeT在不同场景和运动类型下的表现,进一步验证其泛化能力和鲁棒性。
通过这些实验,论文全面地验证了DeT方法在运动转移任务中的有效性,特别是在运动保真度和编辑保真度之间的平衡上。实验结果表明,DeT在MTBench基准上取得了最佳性能,并且在各种定性评估中也表现出色。
论文的主要内容:
本文提出了 DeT(Decouple and Track),这是一种针对视频扩散模型(DiT)的改进方法,专门用于提升运动转移任务的性能。运动转移任务的目标是将源视频中的运动模式转移到新生成的视频中,同时允许用户通过文本提示对前景和背景进行灵活控制。文章的主要贡献和内容可以总结如下:
研究背景与挑战
- 运动转移任务:将源视频中的运动模式转移到新生成的视频中,同时保持对前景和背景的文本控制。
- 现有方法的局限性:以往的方法主要依赖于3D U-Net中的分离式时空注意力机制,这些方法与最新的视频扩散Transformer(DiT)模型不兼容。DiT模型使用3D全注意力机制,没有明确区分时间和空间信息,这使得运动与外观的解耦更加困难。
DeT方法
- 共享时间核(Shared Temporal Kernel):
- 动机:通过在时间维度上平滑DiT特征,帮助模型更好地分离前景运动和背景外观。
- 实现:使用时间核 Kt∈Rk×c×cKt∈Rk×c×c 对重塑后的DiT特征 I′∈Rhw×t×cI′∈Rhw×t×c 进行卷积操作,以实现特征的平滑。
- 效果:显著提升了运动保真度和编辑保真度。
- 密集点跟踪损失(Dense Point Tracking Loss):
- 动机:通过在潜在特征空间中引入显式监督,增强前景运动的一致性。
- 实现:使用CoTracker [25] 生成源视频中前景的轨迹 T∈RN×T×2T∈RN×T×2,并在训练过程中计算预测的潜在特征 E^(S)E^(S) 沿轨迹的L2距离。
- 效果:显著提高了前景运动的一致性,使得生成的视频在运动模式上更加贴近源视频。
MTBench基准和评估指标
- MTBench基准:提出了一个新的基准MTBench,包含100个高质量视频和500个评估提示,涵盖了多种运动类型和难度级别。
- 混合运动保真度度量:引入了一种结合Fréchet距离和局部速度相似性的混合度量,用于更全面地评估生成视频与源视频之间的运动相似性。
实验结果
- 定性结果:展示了DeT在不同难度级别(简单、中等、困难)的运动转移任务上的效果,生成视频能够准确地保留源视频的运动模式,同时允许通过文本提示灵活控制前景和背景。
- 定量结果:在MTBench基准上,DeT在运动保真度、编辑保真度和时间一致性方面均取得了最佳性能,显著优于现有的方法。
- 消融研究:通过消融研究验证了共享时间核和密集点跟踪损失的有效性,以及不同超参数对性能的影响。
结论
DeT通过引入共享时间核和密集点跟踪损失,有效地解决了DiT模型在运动转移任务中的挑战,显著提升了运动保真度和编辑保真度。此外,MTBench基准和混合运动保真度度量为评估运动转移方法提供了一个更全面的框架。实验结果表明,DeT在运动转移任务中取得了最佳性能,展示了其在实际应用中的潜力。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-03-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号