AsteraLabs:PCIe 长距离跨节点传输方案

AsteraLabs:PCIe 长距离跨节点传输方案

数据存储前沿技术
发布于 2025-02-11 19:23:58
发布于 2025-02-11 19:23:58
要点速览
- 基于PCIe 横向跨节点扩展AI集群的设想(Fig-2)
- 长距离 PCIe 线缆设计原型、信号处理方法、线缆选型(Fig-7/8/10)
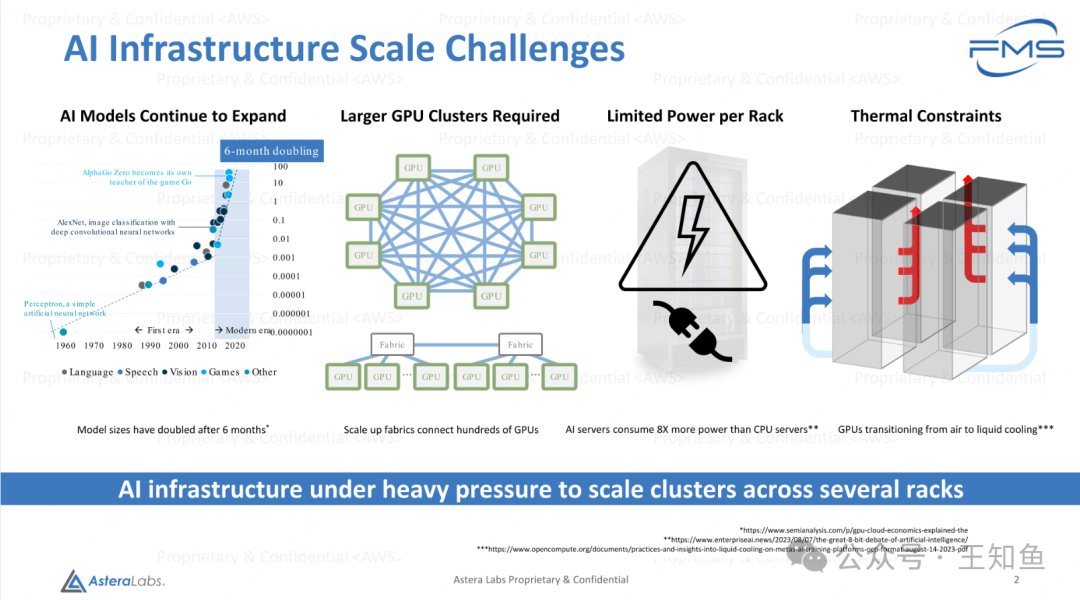
Fig-1
AI基础设施扩展挑战
- AI模型持续扩展:
- 模型规模以6个月为周期翻倍增长。
- 随着多模态数据不断增加,模型规模会加速扩张。
- 需要更大的GPU集群:
- 规模化的Fabric网络连接成百上千的GPU。
- 每个机架的功率受限:
- AI服务器的耗电量是CPU服务器的8倍。
- 功耗限制:
- GPU冷却方式正在从空气冷却转向液体冷却。
总结: AI基础设施面临的主要挑战包括模型规模指数增长、GPU集群需求增加、功耗限制及热量管理。这对扩展多个机架中的计算集群带来了巨大压力。
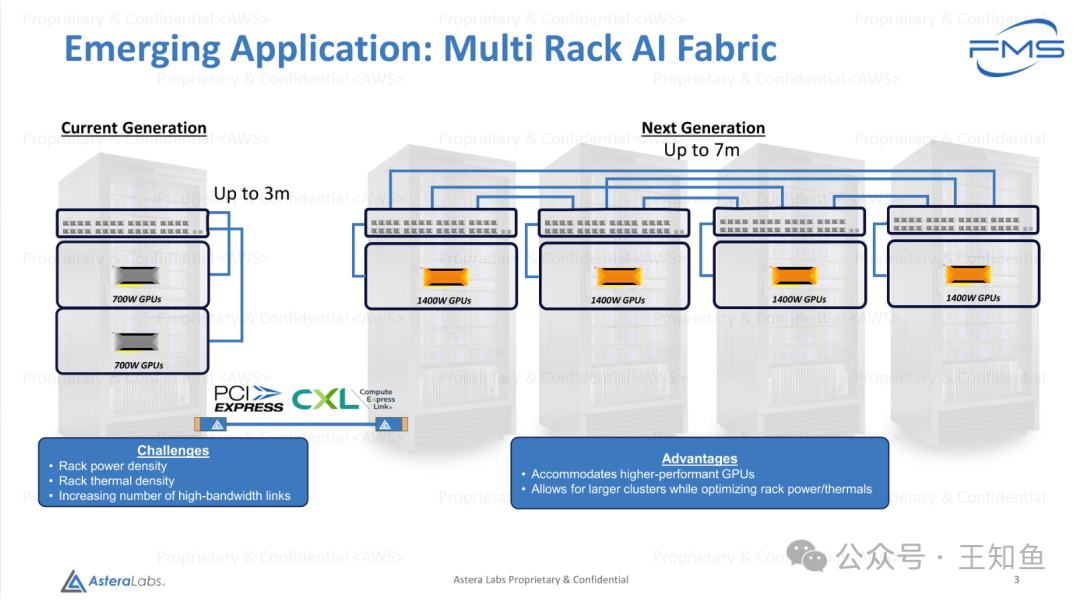
Fig-2
左图是当前数据中心基于PCIe线缆实现的单机架互联通信,线缆长度不超过3m; 下一代PCIe希望延展到7m,已满足更大集群的互联通信。
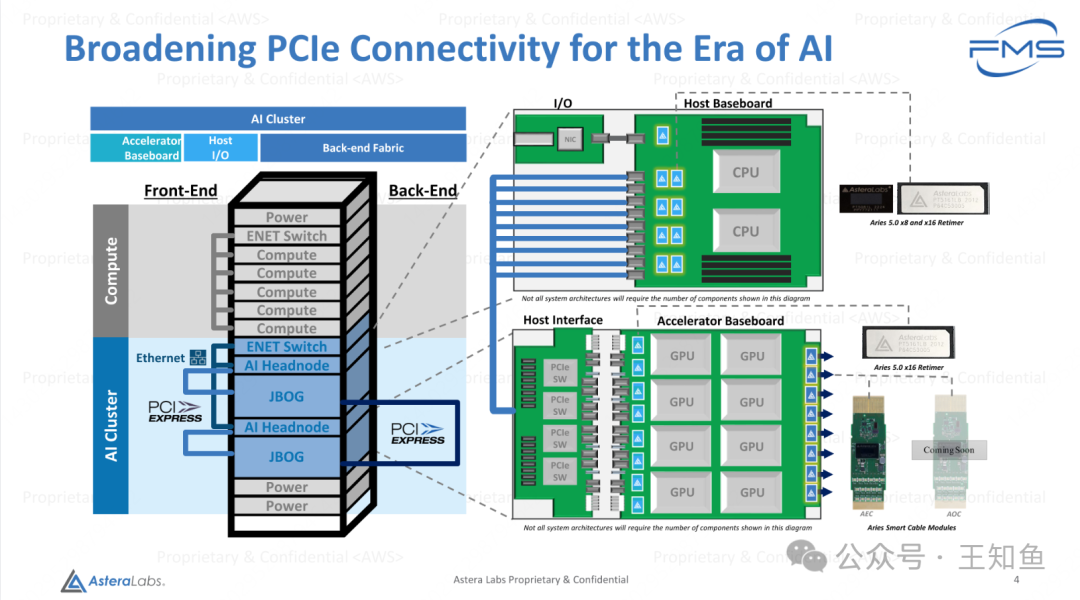
Fig-3
基于PCIe扩展AI基础设施
左侧机架设计有以下几个亮点:
- 单个机架中包含通用计算节点(Compute)和AI加速节点(AI Cluster)
- 加速节点的设计,不是当前业界CPU+GPU的耦合设计,而是借鉴集中式存储架构,将控制节点和计算节点解耦,构建计算头节点(AI Headnode)和 AI加速计算阵列 JBOG(Just Bunch of GPUs),两者之间使用高速PCIe链路互联。
Note
这样设计的优势在于,简化GPU服务器主板设计,优化空间结构同时降低单位密度能耗;但节点间需要更密集的PCIe线路互联。
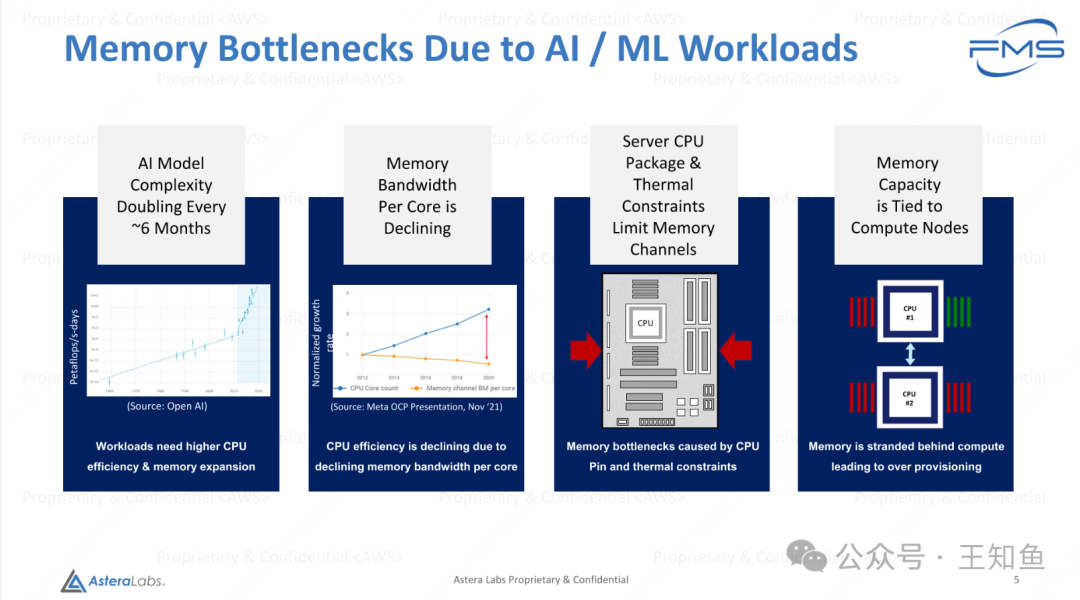
Fig-4
由于AI/ML工作负载导致的内存瓶颈
AI模型复杂度每6个月翻倍:
图表显示,AI工作负载需求持续增加(单位:Petaflops-days)。
需要更高的CPU效率和内存扩展能力。
每核心的内存带宽在下降:
图表展示CPU核心数量的增长,但每核心的内存带宽呈下降趋势。
原因:内存带宽未能跟上CPU扩展的速度。
服务器CPU封装和热量限制内存通道数量:
由于CPU的封装设计和热量管理,内存通道受到限制。
结果:CPU引发内存瓶颈,影响整体性能。
内存容量与计算节点绑定:
当前设计中,内存容量与计算节点(如CPU)紧密耦合。
内存资源因耦合设计被闲置,导致过度配置(over provisioning)。
Note
现代化数据应用系统内存瓶颈(内存墙)的客观原因:AI模型对内存容量的需求(容量和带宽)不断增大、服务器多核设计导致单位核心内存带宽下降(推理可能还是会在CPU上进行)、CPU封装线脚有限、计算和内存节点耦合设计。
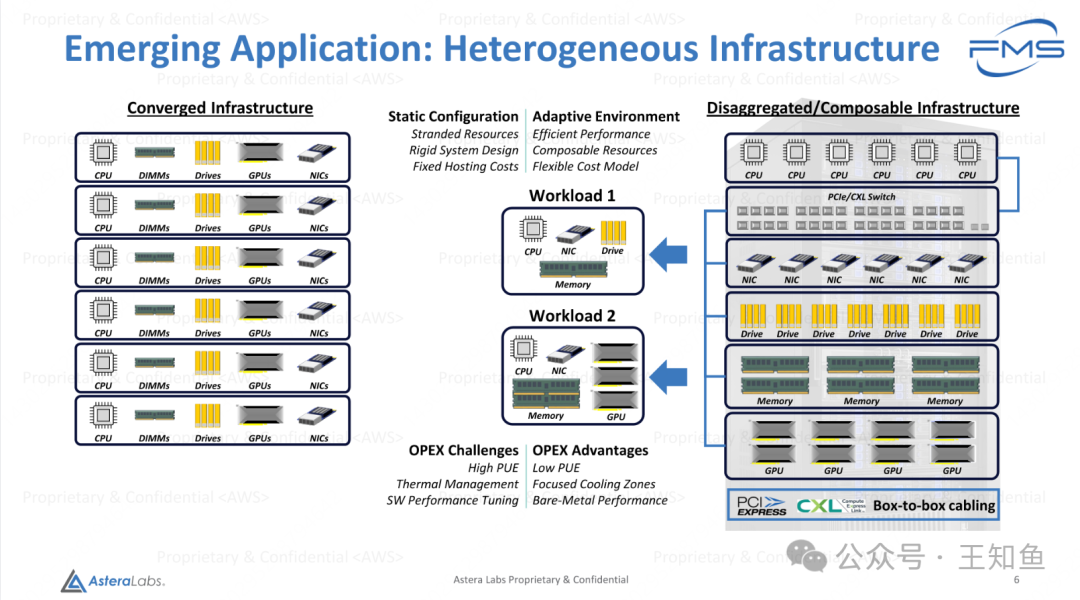
Fig-5
异构基础设施的兴起
Converged Infrastructure(传统融合架构)
- 特点:
- 每个节点均包含固定的CPU、内存(DIMMs)、存储设备(Drives)、GPU和网络接口卡(NICs)。
- 配置静态,资源被捆绑(Stranded Resources)。
- 系统设计刚性(Rigid System Design),存在固定的托管成本(Fixed Hosting Costs)。
- 问题:
- 资源无法动态调配,易造成资源浪费。
- 缺乏灵活性,难以适应不同的工作负载需求。
运维成本挑战(OPEX Challenges)
- 高PUE(电源使用效率低):传统架构散热和电力管理成本高。
- 热管理难题:硬件密集排布导致热量集中难以有效散散。
- 软件性能优化复杂:传统架构因资源耦合需要复杂的性能调优。
---
Disaggregated/Composable Infrastructure(解耦/可组合架构)
- 特点:
- 各种硬件资源模块(CPU、NIC、存储设备、内存、GPU等)独立存在,通过PCIe/CXL交换机动态互联。
- 可根据工作负载需求,灵活组合不同类型的硬件资源。
- 优势:
- 高效性能(Efficient Performance):硬件资源按需组合,最大化资源利用率。
- 灵活成本模型(Flexible Cost Model):资源不再固定,降低托管和扩展成本。
- 低PUE(电源使用效率):集中冷却设计,更高效的散热管理。
- 裸机性能(Bare-Metal Performance):减少虚拟化和资源隔离的性能损耗。
解耦和可组合架构通过将硬件资源模块化设计,利用高速互联(如PCIe/CXL),可以根据工作负载需求动态组合硬件,显著提升资源利用效率、降低成本并简化运维。这种架构尤其适合多样化的AI/ML工作负载和动态云计算环境的需求。相比传统融合架构,其灵活性和性能优化潜力更高。
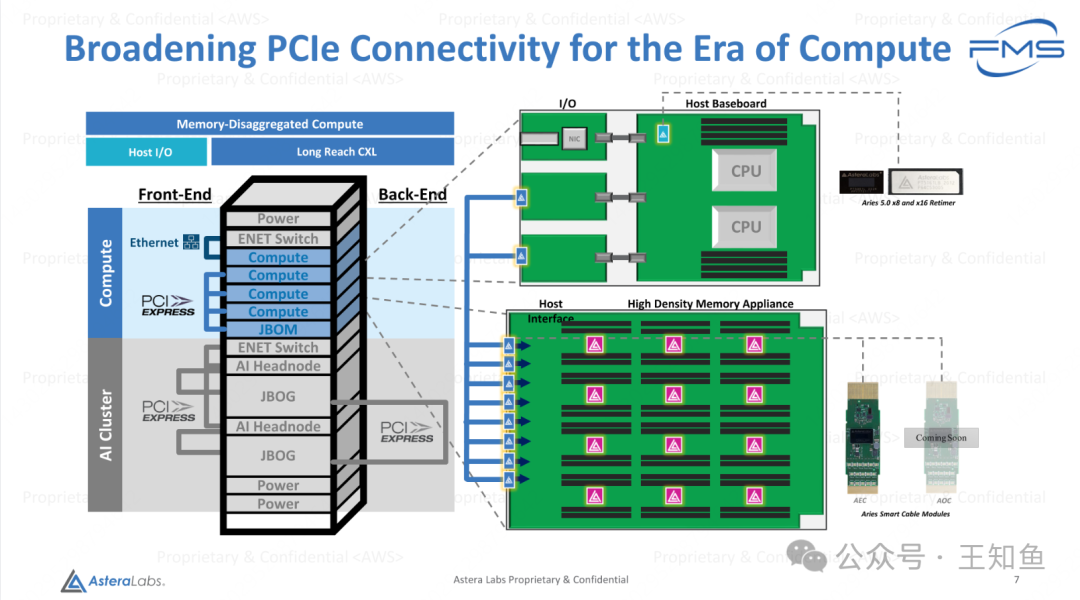
Fig-6
基于PCIe 扩展CPU计算节点的内存(JBOM)
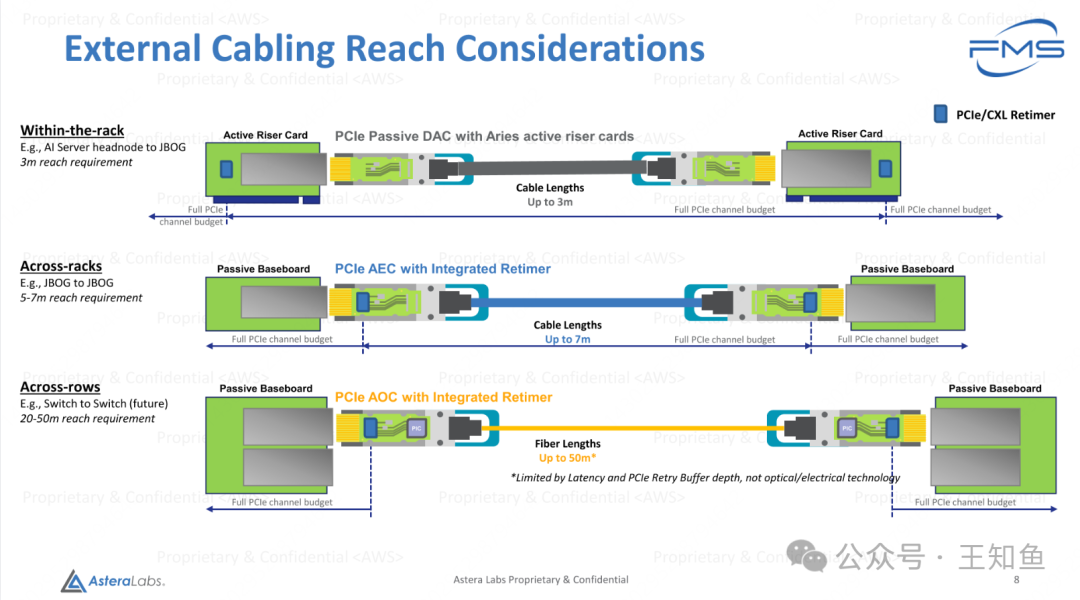
Fig-7
PCIe 布线方案
外部布线覆盖范围的考量(External Cabling Reach Considerations)
1. 机架内布线(Within-the-rack)
- 场景:如AI服务器的头节点(Headnode)连接到GPU阵列(JBOG)。
- 技术:使用PCIe被动DAC(Direct Attach Cable)和Aries主动升降卡(Active Riser Card)。
- 覆盖范围:电缆长度最长3米。
- 特性:
- 支持完整的PCIe信道预算(Full PCIe channel budget)。
2. 机架间布线(Across-racks)
- 场景:如JBOG之间的连接。
- 技术:使用PCIe AEC(Active Electrical Cable,需要Retimer强化信号),带有集成的信号整形(Integrated Retimer)。
- 覆盖范围:电缆长度最长7米。
- 特性:
- 提供信号再生,确保数据传输完整性。
- 支持完整的PCIe信道预算。
3. 行间布线(Across-rows)
- 场景:未来可能的交换机(Switch)到交换机连接。
- 技术:使用PCIe AOC(Active Optical Cable),带有集成的信号整形。
- 覆盖范围:光纤长度最长50米。
- 特性:
- 使用光纤实现超长距离传输。
- 受限于延迟和PCIe重试缓冲深度(Latency and PCIe Retry Buffer Depth),而非光学或电气技术本身。
- 短距离(机架内,3米):使用被动DAC,适合紧凑的物理布局。
- 中距离(机架间,5-7米):使用AEC实现信号增强,满足多机架布线需求。
- 长距离(行间,20-50米):使用AOC,基于光纤技术,可支持数据中心更大范围的设备连接。
这些设计通过优化不同距离的信号传输技术,有效满足从机架内到跨行的大规模AI计算集群需求。
Retimer 在远距离信号传输中的作用
Retimer 是在远距离高速信号传输中提高信号完整性和可靠性的重要组件。它通过重新定时和均衡信号,克服了信号传输过程中因衰减和干扰而导致的质量问题。以下是它在远距离信号传输中的主要作用:
- 信号重生(Signal Regeneration):
- 随着信号在长距离电缆或光纤中传输,其幅度会减弱,且受到噪声和干扰的影响。Retimer 通过重新定时和重新驱动信号,使其恢复到初始的高质量状态,避免数据误码率(BER)的上升。
- 延长传输距离:
- 在 PCIe 或 CXL 等高速传输协议中,信号的物理传输距离受到带宽和衰减的限制。Retimer 的加入可以显著延长传输距离,例如从传统电缆的 3 米扩展到 7 米,甚至通过光缆扩展到 50 米。
- 降低信号抖动(Jitter):
- 信号抖动是高速传输中常见的问题,会影响时序和数据完整性。Retimer 能够重新定时数据流,去除信号的抖动,确保可靠传输。
- 多链路扩展支持:
- 在多链路(例如多个 GPU、JBOG)连接中,Retimer 保证每条链路的信号独立且完整,使复杂的多机架部署成为可能。

Fig-8
PCIe AECs 信号处理技术比较
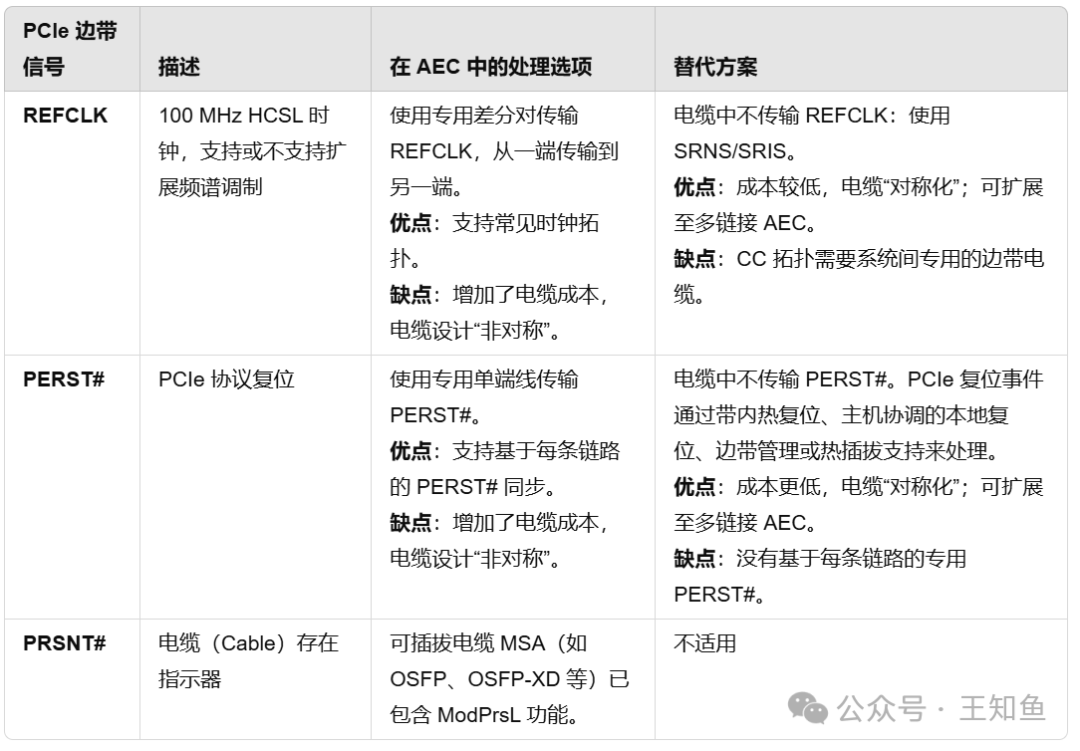
表格说明了三种 PCIe 边带信号(REFCLK、PERST#、PRSNT#)的功能描述、在 AEC 中的处理方式及其替代方案。每种方案均具有优缺点,需根据实际需求选择适合的处理方式。
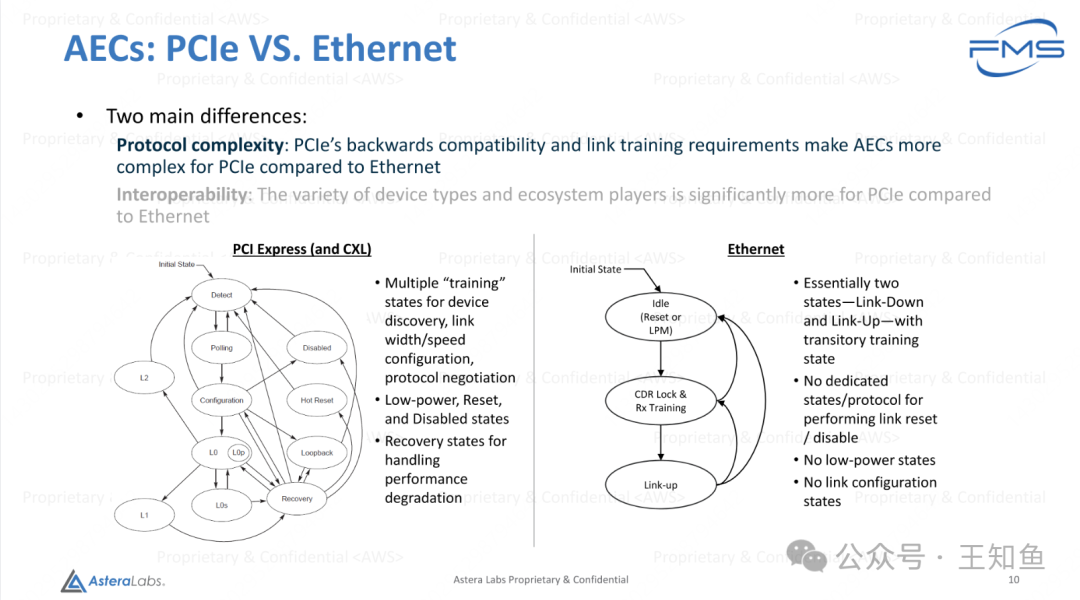
Fig-9
AECs:PCIe 与 Ethernet 的比较
两者的主要区别:
- 协议复杂性(Protocol Complexity):
- PCIe:
- 协议结构更简单,没有 PCIe 的复杂性。
- 支持向后兼容性。
- 需要复杂的链路训练(Link Training)。
- Ethernet:
- 需要复杂的链路训练(Link Training)。
- 互操作性(Interoperability):
- PCIe:
- 通常适用于统一的网络设备环境,互操作性要求相对较少。
- 支持多种设备类型和生态系统参与者(如 GPU、存储、网络设备等)。
- Ethernet:
- 更广泛的互操作性需求。
详细对比:
PCI Express(包括 CXL):
- 状态多样性:
- 包含多个“训练”状态(Training States),用于设备发现、链路宽度/速度配置、协议协商等。
- 低功耗状态(Low-power States):L0、L1、L2、L0s、L0p。
- 恢复状态(Recovery States):用于处理性能退化。
- 特殊状态:如 Reset、Hot Reset、Disabled。
- 复杂性:
- 协议状态图复杂,链路的初始化和训练过程较长。
- 适合需要高性能、复杂设备连接的场景,如 AI 加速、存储扩展等。
Ethernet:
- 状态简单:
- 基本上只有两个主要状态:链路关闭(Link-Down)和链路开启(Link-Up),中间有一个过渡训练状态。
- 功能限制:
- 没有专用的状态/协议来执行链路复位或禁用。
- 不支持低功耗状态。
- 不支持链路配置状态。
- 简化设计:
- 状态图简单,链路初始化快,适用于通用网络场景。
小结:
- PCIe 的特点:
- 协议复杂,支持更高级的设备发现、链路配置和低功耗状态。
- 更适合需要高带宽和复杂拓扑的应用(如 AI、存储和计算加速)。
- Ethernet 的特点:
- 协议简单,状态少,链路建立速度快。
- 更适合网络通信场景,复杂度低但缺乏高级功能。
因此,PCIe 更适合高速互联的计算和存储场景,而 Ethernet 更适合大范围、低复杂度的网络连接应用。
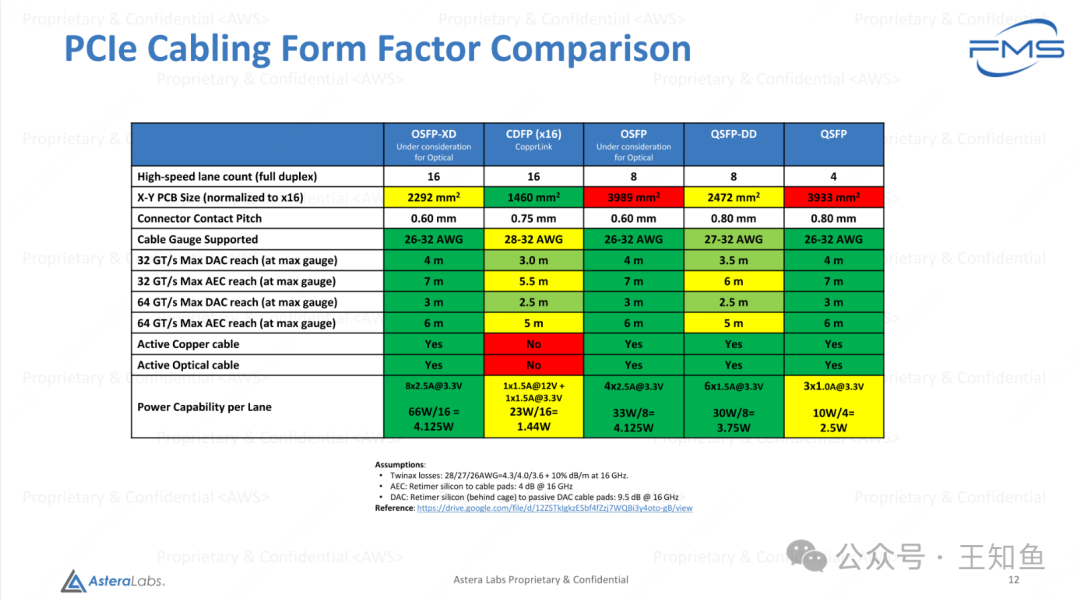
Fig-10
PCIe 线缆选型
对比的关键点
- 通道数量与尺寸:
- OSFP-XD 提供最多的 16 个通道,同时 PCB 尺寸更紧凑(2292 mm²)。
- QSFP 提供最少的 4 个通道,但 PCB 面积更大。
- 线缆支持与长度:
- 所有外形因子都支持被动 DAC 和主动 AEC。
- 在 64 GT/s 速率下,DAC 最大支持 3-4 米,AEC 支持 5-6 米。
- 功率能力:
- OSFP 和 OSFP-XD 的每通道功率能力最高,约 4.125W/通道,适合高性能应用。
- QSFP 的每通道功率最低,2.5W/通道,更适合低功耗场景。
- 光缆支持:
- 除了 CDFP,其他外形因子均支持主动光缆(AOC),便于更长距离的高效传输。
表格展示了 PCIe 布线规格差异,可根据带宽需求、功率要求及距离选择适合的布线解决方案。
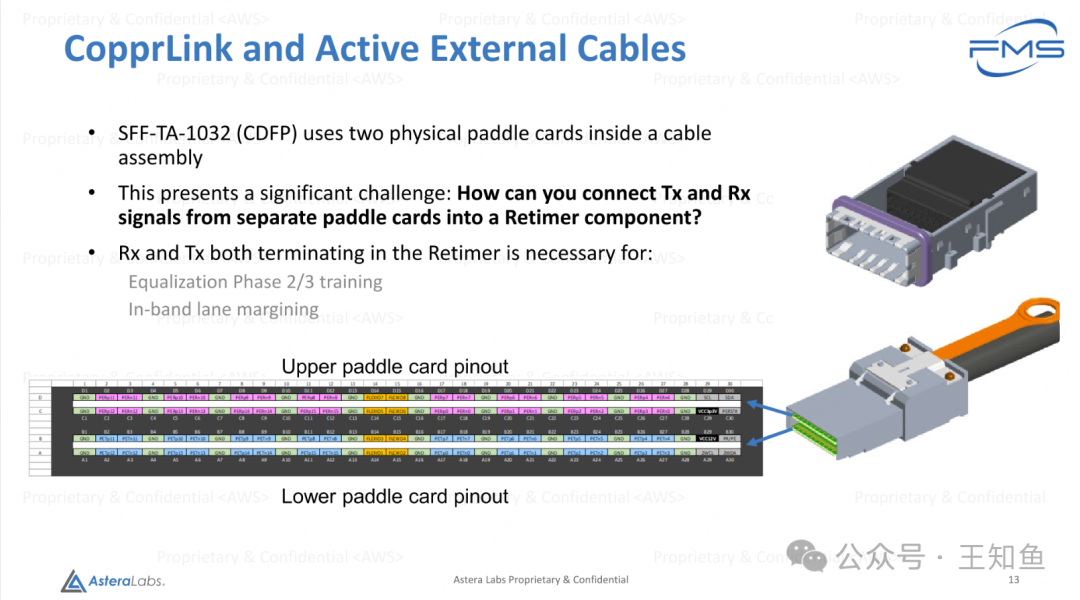
Fig-11
- SFF-TA-1032 (CDFP) 使用电缆组件中的两块物理桨形卡(Paddle Card)。
- 这带来了一个重要挑战:如何将来自不同桨形卡的 Tx 和 Rx 信号连接到 Retimer 组件中?
- Rx 和 Tx 信号同时终止在 Retimer 中的必要性:
- 用于均衡阶段 2/3 的训练(Equalization Phase 2/3 Training)。
- 用于带内通道边界分析(In-band Lane Marginaling)。
技术细节:
- 上方图示为桨形卡的插针布局(Pinout),分为 上桨形卡(Upper Paddle Card Pinout) 和 下桨形卡(Lower Paddle Card Pinout)。
- Retimer 的作用是将不同桨形卡中的传输(Tx)和接收(Rx)信号重新定时和校正,确保信号质量。

Fig-12
Wrap Up
- 演进的 AI 和解耦计算系统拓扑:
- 需要更多的外部布线(External Cabling)以适应复杂的系统架构。
- 覆盖范围需求:
- 2米:适用于机架内布线。
- 7米:适用于机架之间的布线。
- 超过7米:适用于更大规模的集群部署。
- Retimer 支持的 AEC 和光学解决方案:
- 支持信号传输距离的延长,同时为主机/设备提供易于设计的 PCIe 合规接口。
- Retimer 的加入确保了信号的质量和完整性,是长距离传输的关键。
- PCIe AEC 和光学设计的复杂性:
- 相比 Ethernet,PCIe 的协议和互操作性设计更复杂。
- 涉及多个协议层的兼容性,适应不同类型的设备和生态系统。
- OSFP-XD/OSFP 的应用优势:
- 对于 PCIe/CXL x16/x8 应用而言,OSFP-XD/OSFP 是一个有吸引力的选择。
- 支持被动 DAC、主动 AEC 和光学解决方案,满足多种布线需求。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-12-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号