【深度学习基础】预备知识 | 线性代数

【深度学习基础】预备知识 | 线性代数

Francek Chen
发布于 2025-01-22 22:59:22
发布于 2025-01-22 22:59:22
深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特征是具有自动提取特征的能力。神经网络算法、算力和数据是开展深度学习的三要素。深度学习在计算机视觉、自然语言处理、多模态数据分析、科学探索等领域都取得了很多成果。本专栏介绍基于PyTorch的深度学习算法实现。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
在介绍完如何存储和操作数据后,接下来将简要地回顾一下部分基本线性代数内容。这些内容有助于了解和实现大多数模型。本节将介绍线性代数中的基本数学对象、算术和运算,并用数学符号和相应的代码实现来表示它们。
一、标量
如果你曾经在餐厅支付餐费,那么应该已经知道一些基本的线性代数,比如在数字间相加或相乘。例如,北京的温度为
(华氏度,除摄氏度外的另一种温度计量单位)。严格来说,仅包含一个数值被称为标量(scalar)。如果要将此华氏度值转换为更常用的摄氏度,则可以计算表达式
,并将
赋为
。在此等式中,每一项(
、
和
)都是标量值。符号
和
称为变量(variable),它们表示未知的标量值。
采用了数学表示法,其中标量变量由普通小写字母表示(例如,
、
和
)。用
表示所有(连续)实数标量的空间,之后将严格定义空间(space)是什么,但现在只要记住表达式
是表示
是一个实值标量的正式形式。符号
称为“属于”,它表示“是集合中的成员”。例如
可以用来表明
和
是值只能为
或
的数字。
标量由只有一个元素的张量表示。下面的代码将实例化两个标量,并执行一些熟悉的算术运算,即加法、乘法、除法和指数。
import torch
x = torch.tensor(3.0)
y = torch.tensor(2.0)
x + y, x * y, x / y, x**y
二、向量
向量可以被视为标量值组成的列表。这些标量值被称为向量的元素(element)或分量(component)。当向量表示数据集中的样本时,它们的值具有一定的现实意义。例如,如果我们正在训练一个模型来预测贷款违约风险,可能会将每个申请人与一个向量相关联,其分量与其收入、工作年限、过往违约次数和其他因素相对应。如果我们正在研究医院患者可能面临的心脏病发作风险,可能会用一个向量来表示每个患者,其分量为最近的生命体征、胆固醇水平、每天运动时间等。在数学表示法中,向量通常记为粗体、小写的符号(例如,
、
和
)。
在数学上,通过一维张量表示向量。一般来说,张量可以具有任意长度,取决于机器的内存限制。
x = torch.arange(4)
x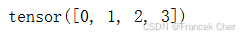
我们可以使用下标来引用向量的任一元素,例如可以通过
来引用第
个元素。注意,元素
是一个标量,所以我们在引用它时不会加粗。大量文献认为列向量是向量的默认方向。在数学中,向量
可以写为:
其中,
是向量的元素。在代码中,我们通过张量的索引来访问任一元素。
x[3]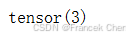
在这里插入图片描述
长度、维度和形状
向量只是一个数字数组,就像每个数组都有一个长度一样,每个向量也是如此。在数学表示法中,如果我们想说一个向量
由
个实值标量组成,可以将其表示为
。向量的长度通常称为向量的维度(dimension)。
与普通的Python数组一样,我们可以通过调用Python的内置len()函数来访问张量的长度。
len(x)4 当用张量表示一个向量(只有一个轴)时,我们也可以通过.shape属性访问向量的长度。形状(shape)是一个元素组,列出了张量沿每个轴的长度(维数)。对于只有一个轴的张量,形状只有一个元素。
x.shape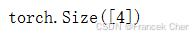
请注意,维度(dimension)这个词在不同上下文时往往会有不同的含义,这经常会使人感到困惑。为了清楚起见,我们在此明确一下:向量或轴的维度被用来表示向量或轴的长度,即向量或轴的元素数量。然而,张量的维度用来表示张量具有的轴数。在这个意义上,张量的某个轴的维数就是这个轴的长度。
三、矩阵
正如向量将标量从零阶推广到一阶,矩阵将向量从一阶推广到二阶。矩阵,我们通常用粗体、大写字母来表示(例如,
、
和
),在代码中表示为具有两个轴的张量。
数学表示法使用
来表示矩阵
,其由
行和
列的实值标量组成。我们可以将任意矩阵
视为一个表格,其中每个元素
属于第
行第
列:
对于任意
,
的形状是(
,
)或
。当矩阵具有相同数量的行和列时,其形状将变为正方形;因此,它被称为方阵(square matrix)。
当调用函数来实例化张量时,我们可以通过指定两个分量
和
来创建一个形状为
的矩阵。
A = torch.arange(20).reshape(5, 4)
A
我们可以通过行索引(
)和列索引(
)来访问矩阵中的标量元素
,例如
。如果没有给出矩阵
的标量元素,如式(2)那样,我们可以简单地使用矩阵
的小写字母索引下标
来引用
。为了表示起来简单,只有在必要时才会将逗号插入到单独的索引中,例如
和
。
当我们交换矩阵的行和列时,结果称为矩阵的转置(transpose)。通常用
来表示矩阵的转置,如果
,则对于任意
和
,都有
。因此,式(2)中的转置是一个形状为
的矩阵:
现在在代码中访问矩阵的转置:
A.T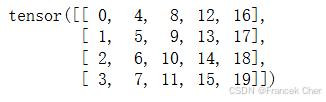
作为方阵的一种特殊类型,对称矩阵(symmetric matrix)
等于其转置:
。这里定义一个对称矩阵
:
B = torch.tensor([[1, 2, 3], [2, 0, 4], [3, 4, 5]])
B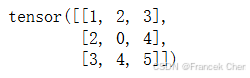
现在我们将B与它的转置进行比较:
B == B.T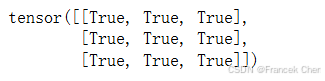
矩阵是有用的数据结构:它们允许我们组织具有不同模式的数据。例如,我们矩阵中的行可能对应于不同的房屋(数据样本),而列可能对应于不同的属性。曾经使用过电子表格软件或已阅读过【深度学习基础】预备知识 | 数据预处理 的人,应该对此很熟悉。因此,尽管单个向量的默认方向是列向量,但在表示表格数据集的矩阵中,将每个数据样本作为矩阵中的行向量更为常见。后面的章节将讲到这点,这种约定将支持常见的深度学习实践。例如,沿着张量的最外轴,我们可以访问或遍历小批量的数据样本。
四、张量
就像向量是标量的推广,矩阵是向量的推广一样,我们可以构建具有更多轴的数据结构。张量(本小节中的“张量”指代数对象)是描述具有任意数量轴的
维数组的通用方法。例如,向量是一阶张量,矩阵是二阶张量。张量用特殊字体的大写字母表示(例如,
、
和
),它们的索引机制(例如
和
)与矩阵类似。
当我们开始处理图像时,张量将变得更加重要,图像以
维数组形式出现,其中3个轴对应于高度、宽度,以及一个通道(channel)轴,用于表示颜色通道(红色、绿色和蓝色)。现在先将高阶张量暂放一边,而是专注学习其基础知识。
X = torch.arange(24).reshape(2, 3, 4)
X
在这里插入图片描述
五、张量算法的基本性质
标量、向量、矩阵和任意数量轴的张量(本小节中的“张量”指代数对象)有一些实用的属性。例如,从按元素操作的定义中可以注意到,任何按元素的一元运算都不会改变其操作数的形状。同样,给定具有相同形状的任意两个张量,任何按元素二元运算的结果都将是相同形状的张量。例如,将两个相同形状的矩阵相加,会在这两个矩阵上执行元素加法。
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
B = A.clone() # 通过分配新内存,将A的一个副本分配给B
A, A + B
具体而言,两个矩阵的按元素乘法称为哈达玛积(Hadamard product)(数学符号
)。对于矩阵
,其中第
行和第
列的元素是
。矩阵
(在式(2)中定义)和
的哈达玛积积为:
A * B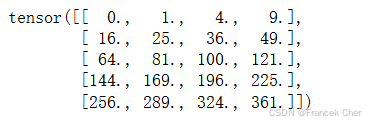
将张量乘以或加上一个标量不会改变张量的形状,其中张量的每个元素都将与标量相加或相乘。
a = 2
X = torch.arange(24).reshape(2, 3, 4)
a + X, (a * X).shape
六、降维
我们可以对任意张量进行的一个有用的操作是计算其元素的和。数学表示法使用
符号表示求和。为了表示长度为
的向量中元素的总和,可以记为
。在代码中可以调用计算求和的函数:
x = torch.arange(4, dtype=torch.float32)
x, x.sum()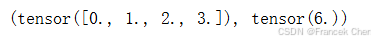
我们可以表示任意形状张量的元素和。例如,矩阵
中元素的和可以记为
。
A.shape, A.sum()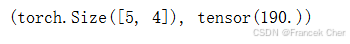
默认情况下,调用求和函数会沿所有的轴降低张量的维度,使它变为一个标量。我们还可以指定张量沿哪一个轴来通过求和降低维度。以矩阵为例,为了通过求和所有行的元素来降维(轴0),可以在调用函数时指定axis=0。由于输入矩阵沿0轴降维以生成输出向量,因此输入轴0的维数在输出形状中消失。
A_sum_axis0 = A.sum(axis=0)
A_sum_axis0, A_sum_axis0.shape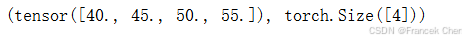
指定axis=1将通过汇总所有列的元素降维(轴1)。因此,输入轴1的维数在输出形状中消失。
A_sum_axis1 = A.sum(axis=1)
A_sum_axis1, A_sum_axis1.shape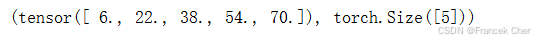
沿着行和列对矩阵求和,等价于对矩阵的所有元素进行求和。
A.sum(axis=[0, 1]) # 结果和A.sum()相同
一个与求和相关的量是平均值(mean或average)。我们通过将总和除以元素总数来计算平均值。在代码中,我们可以调用函数来计算任意形状张量的平均值。
A.mean(), A.sum() / A.numel()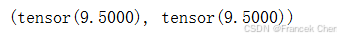
同样,计算平均值的函数也可以沿指定轴降低张量的维度。
A.mean(axis=0), A.sum(axis=0) / A.shape[0]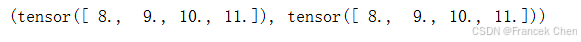
非降维求和
但是,有时在调用函数来计算总和或均值时保持轴数不变会很有用。
sum_A = A.sum(axis=1, keepdims=True)
sum_A
例如,由于sum_A在对每行进行求和后仍保持两个轴,我们可以通过广播将A除以sum_A。
A / sum_A
如果我们想沿某个轴计算A元素的累积总和,比如axis=0(按行计算),可以调用cumsum函数。此函数不会沿任何轴降低输入张量的维度。
A.cumsum(axis=0)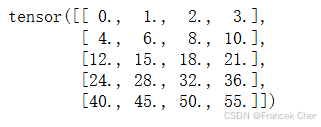
七、点积
我们已经学习了按元素操作、求和及平均值。另一个最基本的操作之一是点积。给定两个向量
,它们的点积(dot product)
(或
)是相同位置的按元素乘积的和:
。
y = torch.ones(4, dtype = torch.float32)
x, y, torch.dot(x, y)
注意,我们可以通过执行按元素乘法,然后进行求和来表示两个向量的点积:
torch.sum(x * y)
点积在很多场合都很有用。例如,给定一组由向量
表示的值,和一组由
表示的权重。
中的值根据权重
的加权和,可以表示为点积
。当权重为非负数且和为1,即
时,点积表示加权平均(weighted average)。将两个向量规范化得到单位长度后,点积表示它们夹角的余弦。本节后面的内容将正式介绍长度(length)的概念。
八、矩阵-向量积
现在我们知道如何计算点积,可以开始理解矩阵-向量积(matrix-vector product)。回顾分别在式(2)和式(1)中定义的矩阵
和向量
。让我们将矩阵
用它的行向量表示:
其中每个
都是行向量,表示矩阵的第
行。矩阵向量积
是一个长度为
的列向量,其第
个元素是点积
:
我们可以把一个矩阵
乘法看作一个从
到
向量的转换。这些转换是非常有用的,例如可以用方阵的乘法来表示旋转。后续章节将讲到,我们也可以使用矩阵-向量积来描述在给定前一层的值时,求解神经网络每一层所需的复杂计算。
在代码中使用张量表示矩阵-向量积,我们使用mv函数。当我们为矩阵A和向量x调用torch.mv(A, x)时,会执行矩阵-向量积。注意,A的列维数(沿轴1的长度)必须与x的维数(其长度)相同。
A.shape, x.shape, torch.mv(A, x)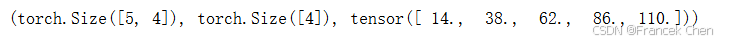
在这里插入图片描述
九、矩阵-矩阵乘法
在掌握点积和矩阵-向量积的知识后,那么矩阵-矩阵乘法(matrix-matrix multiplication)应该很简单。
假设有两个矩阵
和
:
用行向量
表示矩阵
的第
行,并让列向量
作为矩阵
的第
列。要生成矩阵积
,最简单的方法是考虑
的行向量和
的列向量:
当我们简单地将每个元素
计算为点积
:
我们可以将矩阵-矩阵乘法
看作简单地执行
次矩阵-向量积,并将结果拼接在一起,形成一个
矩阵。在下面的代码中,我们在A和B上执行矩阵乘法。这里的A是一个5行4列的矩阵,B是一个4行3列的矩阵。两者相乘后,我们得到了一个5行3列的矩阵。
B = torch.ones(4, 3)
torch.mm(A, B)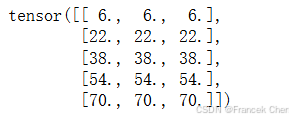
矩阵-矩阵乘法可以简单地称为矩阵乘法,不应与哈达玛积混淆。
十、范数
线性代数中最有用的一些运算符是范数(norm)。非正式地说,向量的范数是表示一个向量有多大。这里考虑的大小(size)概念不涉及维度,而是分量的大小。
在线性代数中,向量范数是将向量映射到标量的函数
。给定任意向量
,向量范数要满足一些属性。第一个性质是:如果我们按常数因子
缩放向量的所有元素,其范数也会按相同常数因子的绝对值缩放:
第二个性质是熟悉的三角不等式:
第三个性质简单地说范数必须是非负的:
这是有道理的。因为在大多数情况下,任何东西的最小的大小是0。最后一个性质要求范数最小为0,当且仅当向量全由0组成。
范数听起来很像距离的度量。欧几里得距离和毕达哥拉斯定理中的非负性概念和三角不等式可能会给出一些启发。事实上,欧几里得距离是一个
范数:假设
维向量
中的元素是
,其
范数是向量元素平方和的平方根:
其中,在
范数中常常省略下标
,也就是说
等同于
。在代码中,我们可以按如下方式计算向量的
范数:
u = torch.tensor([3.0, -4.0])
torch.norm(u)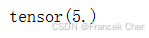
深度学习中更经常地使用
范数的平方,也会经常遇到
范数,它表示为向量元素的绝对值之和:
与
范数相比,
范数受异常值的影响较小。为了计算
范数,我们将绝对值函数和按元素求和组合起来。
torch.abs(u).sum()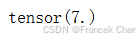
范数和
范数都是更一般的
范数的特例:
类似于向量的
范数,矩阵
的弗罗贝尼乌斯范数(Frobenius norm)是矩阵元素平方和的平方根:
弗罗贝尼乌斯范数满足向量范数的所有性质,它就像是矩阵形向量的
范数。调用以下函数将计算矩阵的弗罗贝尼乌斯范数。
torch.norm(torch.ones((4, 9)))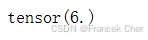
范数和目标
在深度学习中,我们经常试图解决优化问题:最大化分配给观测数据的概率;最小化预测和真实观测之间的距离。用向量表示物品(如单词、产品或新闻文章),以便最小化相似项目之间的距离,最大化不同项目之间的距离。目标,或许是深度学习算法最重要的组成部分(除了数据),通常被表达为范数。
十一、关于线性代数的更多信息
仅用一节,我们就讲完了阅读本专栏所需的、用以理解现代深度学习的线性代数。线性代数还有很多,其中很多数学对于机器学习非常有用。例如,矩阵可以分解为因子,这些分解可以显示真实世界数据集中的低维结构。机器学习的整个子领域都侧重于使用矩阵分解及其向高阶张量的泛化,来发现数据集中的结构并解决预测问题。当开始动手尝试并在真实数据集上应用了有效的机器学习模型,你会更倾向于学习更多数学。因此,这一节到此结束,本专栏将在后面介绍更多数学知识。
小结
- 标量、向量、矩阵和张量是线性代数中的基本数学对象。
- 向量泛化自标量,矩阵泛化自向量。
- 标量、向量、矩阵和张量分别具有零、一、二和任意数量的轴。
- 一个张量可以通过
sum和mean沿指定的轴降低维度。 - 两个矩阵的按元素乘法被称为他们的哈达玛积。它与矩阵乘法不同。
- 在深度学习中,我们经常使用范数,如
范数、
范数和弗罗贝尼乌斯范数。
- 我们可以对标量、向量、矩阵和张量执行各种操作。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-01-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号