【机器学习】从理论到实践:决策树算法在机器学习中的应用与实现


📕引言
决策树是一种广泛应用于分类和回归任务的监督学习算法。它通过将数据集划分成不同的子集来做出决策,直观且易于理解。在本篇文章中,我们将深入剖析决策树的原理,并通过具体的代码实例展示其在机器学习中的应用。
⛓决策树的基本原理
1. 决策树的结构
决策树由节点和边组成,其中每个节点表示数据集的某个特征,每条边表示特征的某个值所对应的分支。决策树的最顶端称为根节点,叶节点代表决策结果。以下是一个简单的决策树示例图:
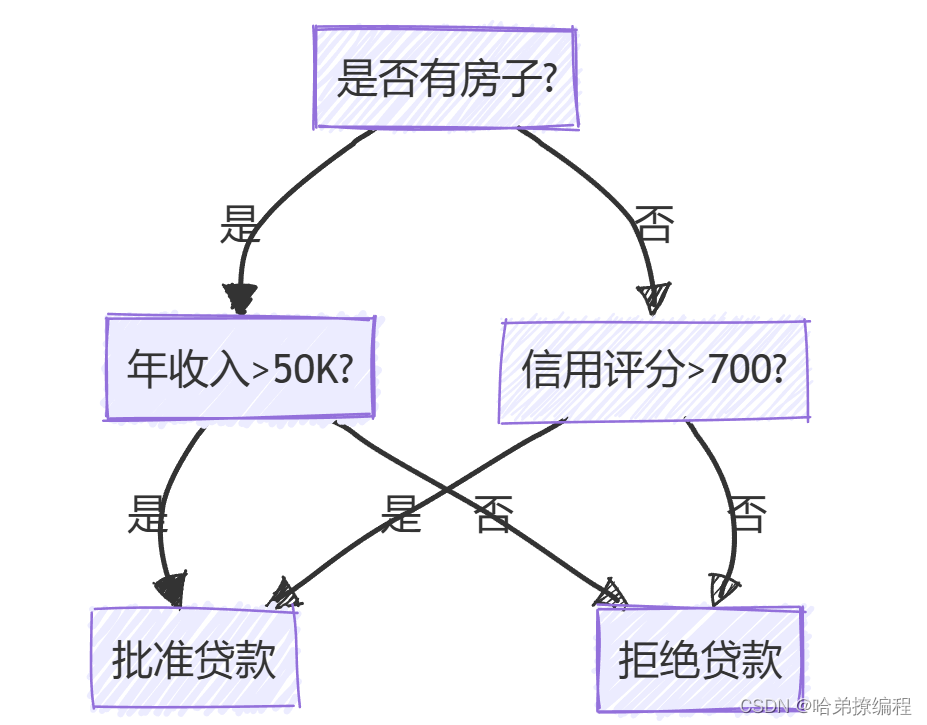
2. 信息增益
决策树的构建过程依赖于一个重要概念:信息增益。信息增益用于衡量某个特征在划分数据集时所带来的纯度提升。常用的纯度度量包括熵、基尼指数等。
熵的计算公式
熵(Entropy)用于衡量数据集的不确定性,其计算公式为:
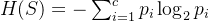
H(S) = -\sum_{i=1}^{c} p_i \log_2 p_i
其中,
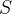
S
是数据集,

c
是类别数,
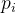
p_i
是第
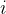
i
类的概率。
信息增益的计算公式
信息增益(Information Gain)用于衡量选择某个特征进行数据划分时,数据集纯度的提升,其计算公式为:
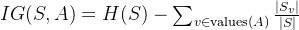
IG(S, A) = H(S) - \sum_{v \in \text{values}(A)} \frac{|S_v|}{|S|}
I
其中,
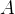
A
是特征,
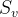
S_v
是根据特征
A
的值
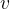
v
划分的数据子集。
3. 基尼指数
基尼指数(Gini Index)是另一种常用的纯度度量方法,用于衡量数据集的不纯度,其计算公式为:
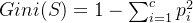
Gini(S) = 1 - \sum_{i=1}^{c} p_i^2
其中,
p_i
是第
i
类的概率。
4. 决策树的构建
决策树的构建过程可以归纳为以下步骤:
- 选择最佳特征进行数据集划分:选择使得信息增益最大化或基尼指数最小化的特征。
- 根据特征值划分数据集:将数据集根据选定特征的不同取值划分为若干子集。
- 递归构建子树:在每个子集上递归构建子树,直到满足停止条件(如所有样本属于同一类别或特征用尽)。
以下是决策树构建过程的伪代码:
函数 BuildTree(data, features):
如果 data 中所有实例属于同一类别:
返回该类别
如果 features 为空或 data 为空:
返回 data 中出现次数最多的类别
选择使信息增益最大的特征 A
创建节点 node,并将其标记为特征 A
对于特征 A 的每个可能取值 v:
子数据集 sub_data = 由 data 中特征 A 的值为 v 的实例构成
如果 sub_data 为空:
在 node 上创建叶节点,标记为 data 中出现次数最多的类别
否则:
在 node 上创建子节点,并将子节点连接到 BuildTree(sub_data, features \ {A})
返回 node🤖决策树的代码实现
接下来,我们通过具体代码展示如何在Python中实现决策树,并应用于分类任务。
1. 数据准备
我们使用一个简单的数据集来演示决策树的构建过程。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# 加载Iris数据集
data = load_iris()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['target'] = data.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(df.drop(columns=['target']), df['target'], test_size=0.3, random_state=42)2. 决策树模型训练
我们使用Scikit-Learn中的DecisionTreeClassifier来训练决策树模型。
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 初始化决策树分类器
clf = DecisionTreeClassifier(criterion='entropy', max_depth=3, random_state=42)
# 训练模型
clf.fit(X_train, y_train)
# 预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'决策树模型的准确率: {accuracy:.2f}')3. 决策树的可视化
我们可以使用Scikit-Learn的export_graphviz函数和graphviz库来可视化决策树。
from sklearn.tree import export_graphviz
import graphviz
# 导出决策树
dot_data = export_graphviz(clf, out_file=None,
feature_names=data.feature_names,
class_names=data.target_names,
filled=True, rounded=True,
special_characters=True)
# 使用graphviz渲染决策树
graph = graphviz.Source(dot_data)
graph.render("decision_tree") # 生成决策树的PDF文件4. 决策树的解释
在实际应用中,决策树的解释能力非常重要。我们可以通过以下方式解读决策树的结果:
特征重要性:决策树可以计算每个特征的重要性,反映其在树中进行决策时的重要程度。
import matplotlib.pyplot as plt
import numpy as np
feature_importances = clf.feature_importances_
features = data.feature_names
indices = np.argsort(feature_importances)
plt.figure(figsize=(10, 6))
plt.title("Feature Importances")
plt.barh(range(len(indices)), feature_importances[indices], align="center")
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel("Relative Importance")
plt.show()决策路径:我们可以追踪决策树在做出某个预测时的决策路径。
sample_id = 0 # 样本索引
node_indicator = clf.decision_path(X_test)
leaf_id = clf.apply(X_test)
sample_path = node_indicator.indices[node_indicator.indptr[sample_id]:node_indicator.indptr[sample_id + 1]]
print(f'样本 {sample_id} 的决策路径:')
for node_id in sample_path:
if leaf_id[sample_id] == node_id:
print(f'--> 叶节点 {node_id}')
else:
print(f'--> 节点 {node_id}, 判断特征:{features[clf.tree_.feature[node_id]]}, 阈值:{clf.tree_.threshold[node_id]:.2f}')🍎决策树在机器学习中的应用
决策树在机器学习中有广泛的应用,主要体现在以下几个方面:
1. 分类任务
决策树在分类任务中应用广泛,如垃圾邮件分类、疾病诊断等。以下是使用决策树进行分类任务的示例代码:
from sklearn.datasets import load_wine
from sklearn.metrics import classification_report
# 加载葡萄酒数据集
wine_data = load_wine()
X_wine = wine_data.data
y_wine = wine_data.target
# 划分训练集和测试集
X_train_wine, X_test_wine, y_train_wine, y_test_wine = train_test_split(X_wine, y_wine, test_size=0.3, random_state=42)
# 训练决策树分类器
wine_clf = DecisionTreeClassifier(criterion='gini', max_depth=5, random_state=42)
wine_clf.fit(X_train_wine, y_train_wine)
# 预测
y_pred_wine = wine_clf.predict(X_test_wine)
# 评估模型
print(classification_report(y_test_wine, y_pred_wine, target_names=wine_data.target_names))2.决策树在回归任务中的应用
决策树同样适用于回归任务,例如房价预测、股票价格预测等。决策树回归模型通过将数据集划分为若干区域,并对每个区域内的样本进行平均来进行预测。以下是一个使用决策树进行回归任务的示例代码:
from sklearn.datasets import load_boston
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error
# 加载波士顿房价数据集
boston = load_boston()
X_boston = boston.data
y_boston = boston.target
# 划分训练集和测试集
X_train_boston, X_test_boston, y_train_boston, y_test_boston = train_test_split(X_boston, y_boston, test_size=0.3, random_state=42)
# 初始化决策树回归器
regressor = DecisionTreeRegressor(criterion='mse', max_depth=5, random_state=42)
# 训练模型
regressor.fit(X_train_boston, y_train_boston)
# 预测
y_pred_boston = regressor.predict(X_test_boston)
# 计算均方误差
mse = mean_squared_error(y_test_boston, y_pred_boston)
print(f'决策树回归模型的均方误差: {mse:.2f}')3. 特征选择
决策树可以用于特征选择,通过计算特征的重要性来筛选出对预测结果影响最大的特征。这在高维数据集的处理上尤其有用。
# 计算特征重要性
feature_importances = regressor.feature_importances_
features = boston.feature_names
# 打印特征重要性
for name, importance in zip(features, feature_importances):
print(f'Feature: {name}, Importance: {importance:.2f}')4. 异常检测
决策树还可以用于异常检测,通过构建深度较大的树来识别数据集中异常点。较深的叶节点通常对应于异常样本。
from sklearn.ensemble import IsolationForest
# 初始化隔离森林模型
iso_forest = IsolationForest(n_estimators=100, contamination=0.1, random_state=42)
# 训练模型
iso_forest.fit(X_train_boston)
# 预测异常
anomalies = iso_forest.predict(X_test_boston)
print(f'异常样本数量: {sum(anomalies == -1)}')🎇决策树的优缺点
优点
- 直观易懂:决策树的结构类似于人类的决策过程,易于理解和解释。
- 无需特征缩放:决策树对数据的缩放不敏感,不需要进行特征归一化或标准化。
- 处理缺失值:决策树能够处理数据集中的缺失值。
- 非线性关系:决策树能够捕捉数据中的非线性关系。
缺点
- 容易过拟合:决策树在训练数据上表现良好,但在测试数据上可能表现不佳,需要通过剪枝等方法进行优化。
- 对噪声敏感:决策树对数据中的噪声较为敏感,容易导致模型不稳定。
- 偏向于多值特征:决策树在选择特征时偏向于取值较多的特征,可能导致偏差。
💡决策树的改进方法
剪枝
剪枝是通过删除决策树中的一些节点来减少模型的复杂度,防止过拟合。剪枝方法主要包括预剪枝和后剪枝。
- 预剪枝:在构建决策树的过程中,通过限制树的最大深度、最小样本数等参数来防止树的过度生长。
- 后剪枝:在决策树构建完成后,通过评估子树的重要性来剪除不重要的子树。
集成方法
集成方法通过结合多个决策树的预测结果来提高模型的稳定性和准确性,常见的集成方法包括随机森林和梯度提升树。
随机森林
随机森林通过构建多棵决策树,并对每棵树的预测结果进行投票来获得最终结果,有效减少了单棵决策树的过拟合问题。
from sklearn.ensemble import RandomForestRegressor
# 初始化随机森林回归器
rf_regressor = RandomForestRegressor(n_estimators=100, max_depth=5, random_state=42)
# 训练模型
rf_regressor.fit(X_train_boston, y_train_boston)
# 预测
rf_y_pred = rf_regressor.predict(X_test_boston)
# 计算均方误差
rf_mse = mean_squared_error(y_test_boston, rf_y_pred)
print(f'随机森林回归模型的均方误差: {rf_mse:.2f}')梯度提升树
梯度提升树通过逐步构建多个决策树,每棵树都在之前所有树的基础上进行改进,从而提高模型的准确性。
from sklearn.ensemble import GradientBoostingRegressor
# 初始化梯度提升回归器
gb_regressor = GradientBoostingRegressor(n_estimators=100, max_depth=3, random_state=42)
# 训练模型
gb_regressor.fit(X_train_boston, y_train_boston)
# 预测
gb_y_pred = gb_regressor.predict(X_test_boston)
# 计算均方误差
gb_mse = mean_squared_error(y_test_boston, gb_y_pred)
print(f'梯度提升回归模型的均方误差: {gb_mse:.2f}')总结
本文详细介绍了决策树的基本原理、构建过程及其在机器学习中的应用。通过详细的代码示例,我们展示了如何使用决策树进行分类和回归任务,并探讨了决策树的优缺点及其改进方法。希望通过本文的介绍,读者能够更深入地理解决策树算法,并能在实际应用中灵活运用这一强大的工具。 无论是在特征选择、分类任务、回归任务还是异常检测中,决策树都展现出了其独特的优势和广泛的应用前景。通过不断优化和改进,决策树将在更多的机器学习任务中发挥重要作用。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-06-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号