原理&图解vLLM Automatic Prefix Cache(RadixAttention)首Token时延优化

原理&图解vLLM Automatic Prefix Cache(RadixAttention)首Token时延优化

BBuf
发布于 2024-06-04 15:40:38
发布于 2024-06-04 15:40:38
作者丨DefTruth
来源丨https://zhuanlan.zhihu.com/p/693556044
编辑丨GiantPandaCV
0x00 前言
看了一些关于Prefix Caching的文章,感觉没有讲得很清晰。最近正好自己也想整理一下相关的技术,因此有了本篇文章。希望结合vLLM Automatic Prefix Caching的源码和一些自己画的图解,能尽量讲清楚这个问题。
最近,准备整理一下PagedAttention、Prefix Cache(RadixAttention)和Chunk Prefills的技术要点。这三个技术目前在TensorRT-LLM、vLLM这两个常用的LLM推理框架中都已经支持,因此,从应用落地的角度来说,理解这三个优化技术的原理也比较有意义。PagedAttention相关的文章网上已经很多,不再过多赘述,之后有时间再单独补档一篇PagedAttention V1/V2的文章。本文为该系列第一篇,主要记录Prefix Cache的技术要点,并结合图解和源码分析vLLM Automatic Prefix Caching的实现。相关技术的整体时间线和相关论文大致如下。
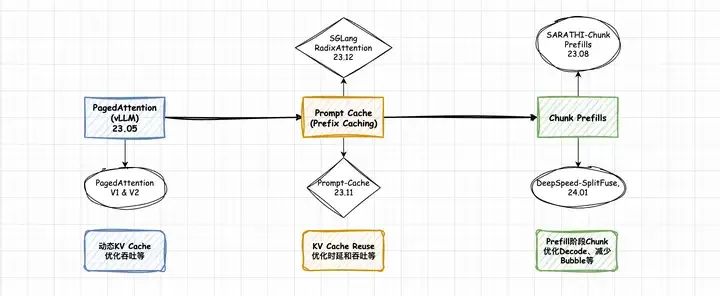
整体时间线
本篇大约1.5w字,内容涵盖如下。本文适合了解PagedAttention原理的同学阅读。
- 0x01 Prefix Caching: RadixAttention原理解析
- 0x02 vLLM Automatic Prefix Caching: Hash RadixAttention
- 0x03 vLLM Automatic Prefix Caching: Hash Prefix Tree
- 0x04 vLLM Automatic Prefix Caching: Prefix/Generate 阶段Hash码处理
- 0x05 vLLM Automatic Prefix Caching: Prefix + Generated KV Caching
- 0x06 vLLM Automatic Prefix Caching: 思考一些边界情况
- 0x07 vLLM Automatic Prefix Caching: 在多轮对话中的应用分析
- 0x08 vLLM Automatic Prefix Caching: Prefix Prefill Kernel与Attention Kernel区别
- 0x09 vLLM Automatic Prefix Caching: 应用实践
- 0x0a Prefix Caching优化相关的其他论文
0x01 Prefix Caching: RadixAttention原理解析
论文: 《Efficiently Programming Large Language Models using SGLang》
https://arxiv.org/pdf/2312.07104
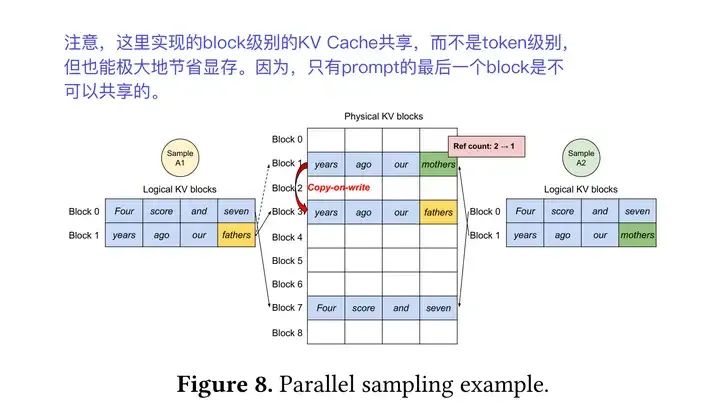
在LLM推理应用中,我们经常会面临具有长system prompt的场景以及多轮对话的场景。长system prompt的场景,system prompt在不同的请求中但是相同的,KV Cache的计算也是相同的;而多轮对话场景中,每一轮对话需要依赖所有历史轮次对话的上下文,历史轮次中的KV Cache在后续每一轮中都要被重新计算。这两种情况下,如果能把system prompt和历史轮次中的KV Cache保存下来,留给后续的请求复用,将会极大地降低首Token的耗时。如果Prefix Cache和Generated KV Cache都可以缓存,在多轮对话的应用中,忽略边界情况,基本上可以认为其消除了历史轮次中生成对话的recompute。如下图所示,这种情况下,每轮对话中,都只有当前轮的prompt需要在prefill阶段进行计算。历史轮次中的Prefix + Generated KV Cache都会被缓存命中。(多轮对话中的应用分析会在后续章节继续展开讲)

Prefix + Generated KV Caching
RadixAttention想要解决的正是这个问题。RadixAttention是在SGLang的论文(《Efficiently Programming Large Language Models using SGLang》)中被提出的,其目的是为了实现Automatic KV Cache Reuse。本文只关注RadixAttention,暂时不关注SGLang的其他内容。RadixAttention使用radix tree(基数树,说实话,这棵树我也不太熟悉)而不是prefix tree。Radix Tree最大的特点就是,它的node,不仅可以是一个单独的元素,也可以是一个变长的序列。具体体现在,在必要的时候,一个已经在Tree中的大node可以动态地分裂成小node,以满足动态shared prefix的需求。避免原理阐述地过于抽象复杂,接下来以论文中带有LRU策略的RadixAttention操作示例来说明RadixAttention原理。
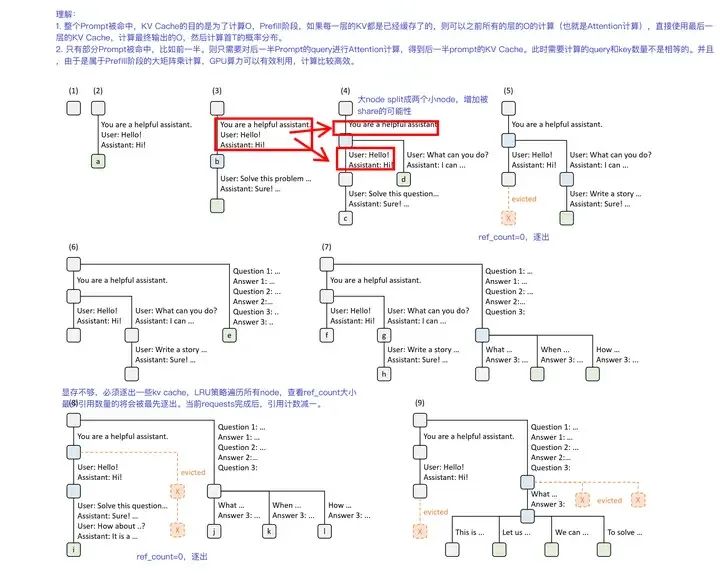
SGLang RadixAttention
图中(1)~(9)表示Radix Tree的动态变化。每条树边都带有一个标签,表示子字符串或token序列。节点用颜色编码以反映不同的状态: 绿色表示新添加的节点,蓝色表示缓存的节点,红色表示已被驱逐的节点。这里讲解一下前面的5个步骤。
步骤(1),Radix Tree最初是空的。步骤(2),服务器处理传入的用户消息: “Hello”,并使用LLM输出: “Hi”,进行响应。system prompt为: "You are a helpful assistant"、用户的prompt为: “Hello!”,LLM回复为: “Hi!”;整个对话被合并为一个大node,保存到Radix Tree的节点a。步骤(3),同一个用户输入了一个新的prompt,服务器从Radix Tree中找到的历史对话前缀(即对话的第一个回合)并复用它的KV Cache。新回合作为新节点追加到树中。步骤(4),开始一个新的聊天会话。Radix Tree将(3)中的大节点“b”,动态地拆分为两个节点,以允许两个聊天会话共享system prompt。步骤(5),第二个聊天继续。然而,由于内存限制,(4)中的节点“c”必须被清除。新的对话被缓存到新的节点"d"。
直观上来说,Radix Tree与Prefix Tree有许多相似之处。值得注意的是,在RadixAttention中,无论是Prefix还是Generate阶段产生的KV Cache,都会被缓存。这可以最大程度增加KV Cache被新请求复用的几率。
0x02 vLLM Automatic Prefix Caching: Hash RadixAttention
Prefix Caching的功能在TensorRT-LLM和vLLM中目前均有支持,我们可以在启动服务时开启。在TensorRT-LLM中,需要通过设置enableBlockReuse为True来开启该功能,在vLLM中则需要指定--enable-prefix-caching。由于TensorRT-LLM目前是半开源状态,blockManager和一些核心的kernel代码是闭源的,因此本文选在vLLM中Prefix Caching实现来进行解读。
[RFC] vLLM Automatic Prefix Cachinghttps://github.com/vllm-project/vllm/issues/2614
vLLM中Prefix Caching使用的是RadixAttention算法,但是使用hash码作为物理KV Block的唯一标识,在工程上感觉更加简单。暂且把这种实现称为: Hash RadixAttention。vLLM中通过BlockSpaceManagerV1类来专门管理block分配。以下是BlockSpaceManagerV1的allocate方法,分析代码之前,先解释一下SequenceGroup数据结构。SequenceGroup在vLLM中用于辅助sampling的实现,group中的所有seq都具有相同的prompt,可以理解成相同的prompt产生的不同采样结果。针对最简单的greedy search,我们可以认为group中只有一个seq。接下来,我们来看下prefix caching,我们可以看到,代码走的是enable_caching分支,调用了gpu_allocator.allocate来分配block;这个gpu_allocator.allocate需要传入当前block的hash码以及已经被hash处理过的tokens数量。
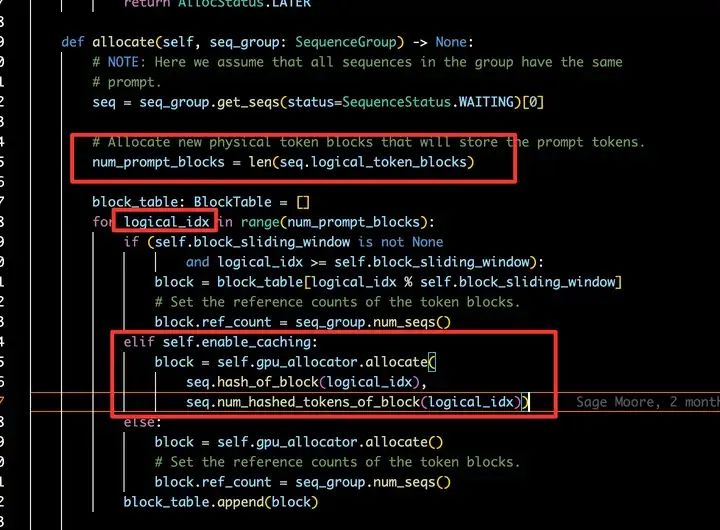
BlockSpaceManagerV1: allocate
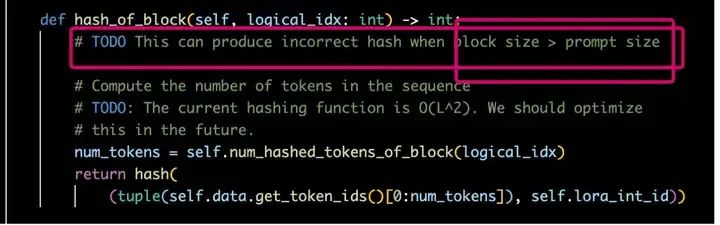
进入hash_of_block这个函数,我们发现vLLM是通过prompt中的token_ids来获取hash值作为cache block的唯一标识。虽然对于不同request的prompt的logical_idx是有重复的,但是逻辑到了hash这步,所利用的token_ids是不一样的。比如有两个请求A和B,prompt长度一样但是内容不一样。这时A和B的num_prompt_blocks和logical_idx是相同的。但是在hash_of_block函数中,实际用来产生hash码的并不是初始的logical_idx,而是通过这个logical_idx和block_size计算得到token_ids作为一个实际的object来获取hash码。因此,可以确保不同prompt的cache block可以获取到唯一的hash码。
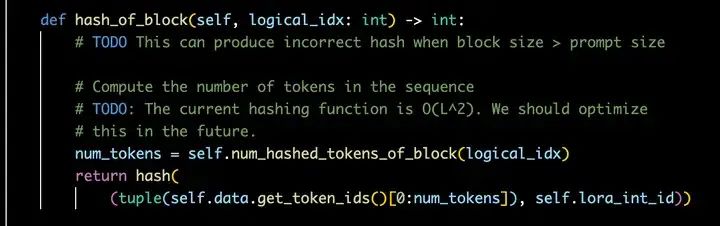
SequenceGroup: hash_of_block
0x03 vLLM Automatic Prefix Caching: Hash Prefix Tree
仔细思考一下这种hash编码的实现,我们还会发现,由于所有当前block的hash码都依赖于此前所有block的token_ids,因此,这个唯一的hash码实际上也代表着一种唯一的前缀关系。这个需要仔细理解,因为只有确保了唯一的前缀关系,才能确保从Prefix Cache KV Blocks中拿到的一系列block是具有相同上下文的。如果把这段代码表达的逻辑画出来,大概长这样:
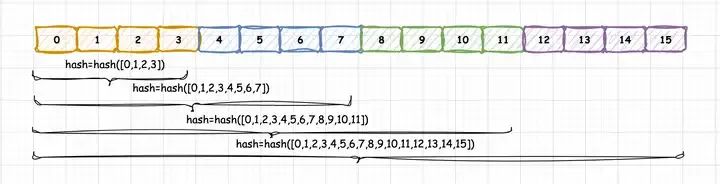
Prefix Caching Hash Code
也就是说这种hash编码的实现,实际上具备前缀树(Prefix Tree)的功能。并且这种前缀树是以PhysicalTokenBlock为单位的,树上的每一个node就是代表一个实际的PhysicalTokenBlock,每一个node的内容就是这个PhysicalTokenBlock的hash码,这个hash码又代表着从树的根节点到当前PhysicalTokenBlock的唯一路径。这里,我画了个图,便于理解Prefix Caching的实现。如果有误,欢迎指正。
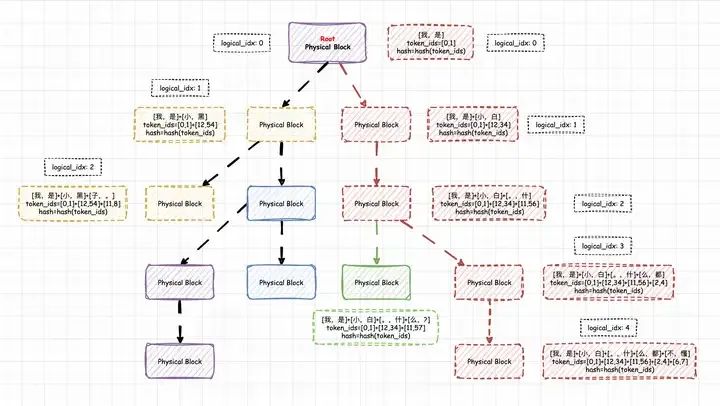
vLLM Prefix Caching: Hash Prefix Tree
0x04 vLLM Automatic Prefix Caching: Prefix/Generate 阶段 Hash 码处理
对于Prefix,所有的token_ids是在inference之前就已知的,因此,可以通过token_ids获取对应的block hash码。那么问题来了,对于Generate阶段呢?我们无法事先知道Generate阶段的token_ids,因为他们还没生成。但是矛盾的是,我们又必须先分配block,才能保存Generate阶段产生的KV Cache。那咋办呢?vLLM中的处理是,对于Generate阶段需要的block,先给它分配一个fake hash,然后进行generation,等到这个block被生成的token填满后,再根据实际生成的token_ids更新hash码。具体的代码调用逻辑如下:
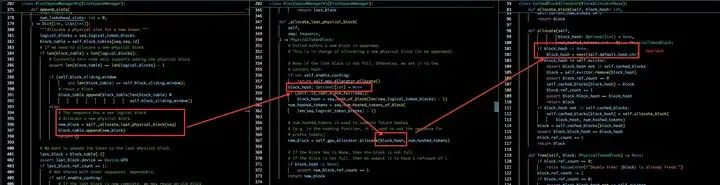
fake hash 调用链路
根据已经生成的token_ids更新hash码代码调用逻辑如下,_promote_last_block这个函数,根据当前的logical_token_blocks(包含了prefix和generated的),调用hash_of_block重新获取到new_hash并使用gpu_allocator.update_hash函数,更新last block的hash码。

hash 编码更新
0x05 vLLM Automatic Prefix Caching: Prefix + Generated KV Caching
由前面的分析我们知道,RadixAttention算法中的Prefix Caching是包括Prefix和Generated KV Cache,并且如果Generated KV Cache如果也能被缓存,那么在多轮对话的场景中,显然具有更大的首Token时延优势。因此,我也比较关注vLLM实际的实现是否和RadixAttention算法描述的一致。我提了issue咨询vLLM团队,他们的回复是: yes! 也就是,相对于只缓存Prefix Cache,vLLM的Prefix Caching功能还缓存了Generated KV Cache,在多轮对话的应用中,基本可以消除历史轮次中生成对话的recompute。附issue链接:
[Doc]: Will both the prompts and generated kv cache reuse if enable_prefix_caching flag is ON?github.com/vllm-project/vllm/issues/4104
vLLM中,对于enable_caching情形,实际使用的gpu_allocator是CachedBlockAllocator。从BlockSpaceManagerV1到CachedBlockAllocator的调用链路大致如下。看着还是有些复杂的,需要细细梳理。但只要抓住2个核心点,就能更容易理解vLLM实现的Prefix+Generated KV Caching功能。
- 核心点1:CachedBlockAllocator实现的是通用的Cache功能,不区分是否为Prefix还是Generate阶段,只要产生了KV Cache,就会被先放到cached_blocks table中缓存,key为block_hash,value为block_id。
- 核心点2:无论是Prefix还是Generate阶段,也只会调用allocate接口,也只有这个接口。
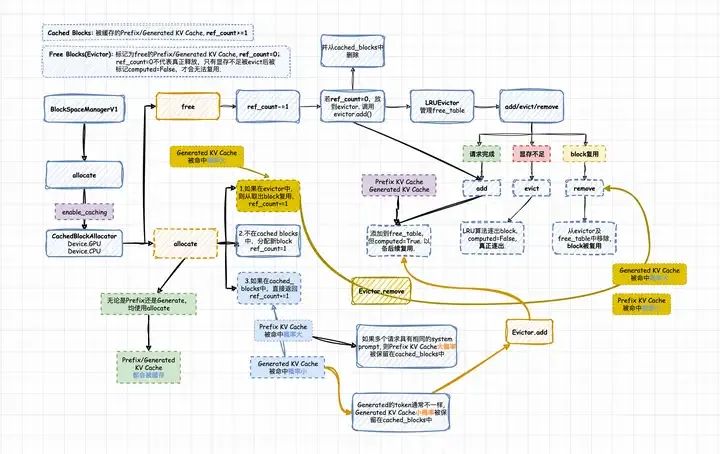
vLLM CachedBlockAllocator: Prefix + Generated KV Caching
CachedBlockAllocator中有个比较重要的概念,ref_count,即block被引用的次数。当block的ref_count次数>=1时,block将会被保存到cached_blocks中;而当ref_count=0时,block就会从cached_blocks中移除,并调用evictor.add()添加到LRUEvictor的free_table中,等待被真正逐出或被复用。这里需要注意的是,ref_count=0不代表真正释放,只有显存不足被evict后被标记computed=False,才会无法复用。我们可以从vLLM的源码中看到对应的处理逻辑,如下:
- CachedBlockAllocator: allocate

CachedBlockAllocator: allocate
另外,我们还可以进一步推测一下上图中这三种allocate的分支,分别对应到实际的情况是什么,也就是什么时候命中了Prefix KV Cache,什么时候命中了Generated KV Cache。
(1)如果在evictor中,则从取出block复用,ref_count+=1。此时,命中Generated KV Cache的概率更大,因为,Generate阶段生成的tokens,对于每个request基本是不一样的,因此,被引用的次数就会较低,一般为1。一旦请求完成生成并返回给用户后,其对应的KV Blocks的实际ref_count为0,此时,就会被CachedBlockAllocator调用free函数,放到LRUEvictor中。也就是说,LRUEvictor的free_table,将会保存大量的Generated KV Cache。这些Generated KV Cache可能会在后续被命中复用,也可能在显存不足时被真正逐出。
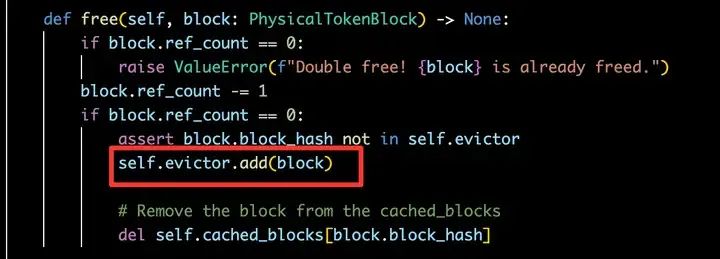
CachedBlockAllocator: free
(2)不在cached_blocks中,也不在evictor中。则直接调用allocate_block分配新block,并将ref_count的值设置为1。此时,既没有命中Prefix KV Cache,也没有命中Generated KV Cache。新分配的block会添加到cache_blocks table中,成为新的cache。
(3)如果在cached_ blocks中。则通过block_hash获取对应的cached block,并且ref_count+=1。此时,命中Prefix KV Cache的概率更大。特别是,如果多个请求具有相同的system prompt,则system prompt对应的Prefix KV Cache由于ref_count一直>=1,因此会长时间驻留在cached_blocks中,会被具有相同system prompt的请求命中。
- CachedBlockAllocator: LRUEvictor
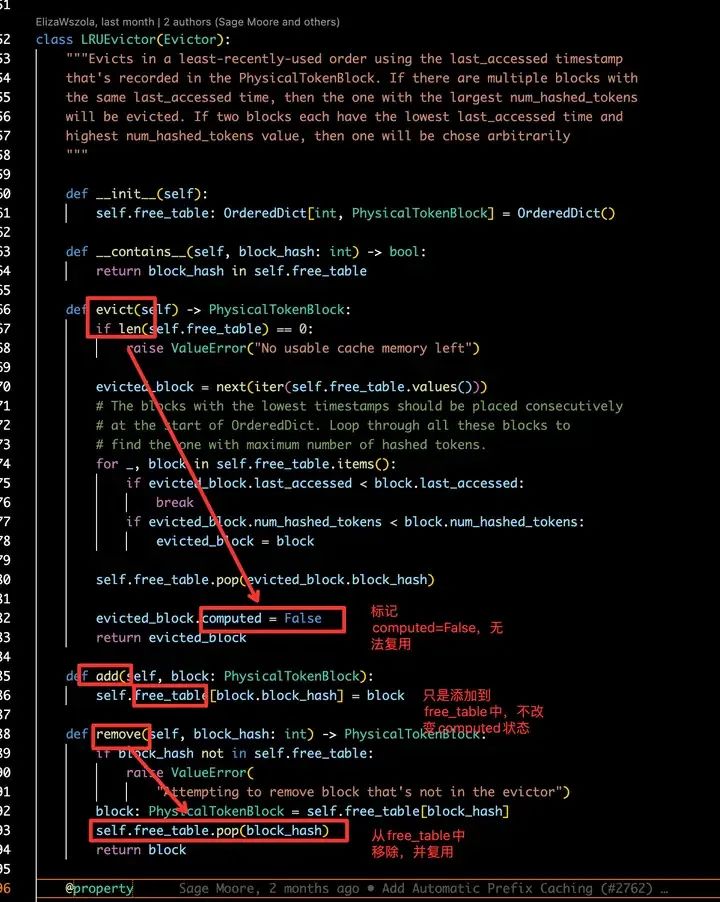
CachedBlockAllocator: LRUEvictor
这部分实现的LRUEvictor。LRUEvictor主要提供3个功能,分别是:add、remove和evict,并且持有free_table成员变量。
(1)Evictor.add:该函数负责将ref_count为0的block添加到free_table中,等待后续的调度。free_table中所有block的computed flag均为True,因此Evictor.add()只是简单地记录ref_count为0的block,并未完全抹除computed状态。这意味着,free_table中记录的block,后续有可能会被新的请求命中,从而得到复用(Evictor.remove),又或者显存不足时,进行真正的逐出(Evictor.evict)。
(2)Evictor.remove:该函数负责根据传入的block_hash,将对应的block从free_table取出复用。
(3)Evictor.evict:该函数执行真正的逐出功能,将free_table中到达时间距离当前最长的block进行逐出。free_table使用了OrderedDict,因此可以认为最先放入free_table的就是距离当前时间最长的block。当遇到确实有其他block的access_time小于选择的evicted_block时,将会选择具有最大num_hashed_tokens数的block进行逐出。这是合理的,因为num_hashed_tokens数越大的block,被reuse的可能性就越小,应该更优先被逐出。

CachedBlockAllocator: allocate_block
从代码中分析,当current_num_blocks==self.num_blocks时,意味着已经没有非computed的block可用了。这时,就会调用evictor.evict(),从free_table中,取出ref_count为0的一个block给到新的请求进行使用。如果依然有足够的未使用的block,则会直接分配新的block,不走evictor.evict()的逻辑。再次提醒,free_table中的block也是使用过的block,computed状态为True,不是真正的空闲block。
0x06 vLLM Automatic Prefix Caching: 思考一些边界情况
vLLM Automatic Prefix Caching的原理和代码基本上讲解完了,现在来让我们思考一个有意思的问题:什么时候永远无法命中Prefix/Generated KV Cache?(后续如果有新的思考,会补充到这小节)答案和block_size的配置以及last block的处理逻辑有关。有两种情况边界情况无法命中cache:
(1)首先,看对于last block中的slots没有被用满的情况,vLLM使用的是Copy on write策略,这种情况下,我个人的理解是,就是last block是不会被不同的seq共享的,也就是不会被不同的request共享。

last block没有被填满

判断last block是否用满
但是由于last block没有被用满,_is_last_block_full的结果为False,因此也不会走到_promote_last_block函数中根据实际生成的token_ids更新hash码,而是保持fake hash。而新请求中hash码是以block为最小单位的,并且hash的值取决于实际的token_ids,不会与fake hash相同。因此无法被后续的请求作为cache命中。(如果理解有误,欢迎大佬指正哈~)
Copy on write
(2)其次,当一个请求的prefix+generated的token数小于block_size时,此时last block也是first block,因此也符合(1)中理解。可以推断,相同的请求在第二次到达vLLM后,不会命中cache。而且,查看vLLM现在的源码,发现有一句注释,似乎正是在说明这个问题。
0x07 vLLM Automatic Prefix Caching: 在多轮对话中的应用分析
可想而知,Prefix Caching在具有长system prompt的场景以及多轮对话的场景中,有非常大的应用价值。特别是多轮对话中,随着历史对话轮次的增加,每次新轮次的对话请求的prefix(prompt),将会越来越长。假设每轮生成512个token,只需要对话8轮,就达到4K长度。因此,如果模型服务具备prefix caching功能,将能极大地降低首Token的时延,提升用户体验。vLLM的prefix caching实现,包含了Prefix和Generated KV Cache。接下来,我们来分析一下只有Prefix、既有Prefix也有Generated KV Cache这两种情况下在多轮对话中的应用。
(1)只有Prefix Caching的优化,多轮对话分析。如下图所示,只有Prefix Caching时,每个新的轮次对话中,总是会有2个片段的prompt需要在prefill阶段进行计算。其中一个frag是上一轮对话的输出,另一个frag是当前轮对话的输入。此时,上一轮对话的输出由于没有被Caching,需要在本轮对话的prefill阶段进行recompute,这个recompute的耗时取决于上一轮生成的token数,根据Chunk Prefills论文(SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills)中的一个观察,"at small batch sizes, the decode cost per token can be as high as ∼ 200 times the prefill cost per token",也就是说,prefill中计算200 tokens的耗时大约等于generate阶段计算一个token的耗时。因此,如果上一轮生成了200个tokens,本轮prefill recompute增加的耗时相当于generate阶段多生成一个token的耗时。

Only Prefix KV Caching
(2)Prefix + Generated KV Caching的优化,多轮对话分析。相对于只缓存Prefix Cache,vLLM的Prefix Caching功能还缓存了Generated KV Cache,在多轮对话的应用中,忽略边界情况,基本上可以认为其消除了历史轮次中生成对话的recompute。如下图所示,这种情况下,每轮对话中,都只有当前轮的prompt需要在prefill阶段进行计算。历史轮次中的Prefix + Generated KV Cache都会被缓存命中。
Prefix + Generated KV Caching
需要注意的是,在实际应用中,当QPS比较大的时候,显存不够用时,vLLM会从Prefix + Generated KV Cache中,按照LRU算法,选择一部分进行逐出,以便新的请求能够有足够的空闲blocks进行推理。因此,想要利用好vLLM Automatic Prefix Caching的特性,我们应该需要考虑几点:
- 尽量保证每个模型服务实例的负载均衡,避免出现pending,分配到的QPS不能太高。
- 同一个对话session的不同轮次的请求,尽量打到同一个模型服务实例,以充分利用历史缓存。实例之间的KV Cache缓存是不共享的,因此,同一个对话session多轮对话的历史缓存只有在相同的实例上才有意义。
- 具有相同或者相似长system prompt的请求,尽可能发送到同一个模型服务实例进行推理。
0x08 vLLM Automatic Prefix Caching: Prefix Prefill Kernel与Attention Kernel区别
需要注意的是,在使用了Prefix Caching后,就无法使用常规的Attention kernel来计算Prefill阶段的注意力结果了。这是由于常规kernel都暗含着一个假设,Q_len等于KV_len,同时两者也等于prompt_len。但是在Prefix Caching的背景下,这个假设就不成立了。因为当前请求的prompt中,会有部分被缓存的KV Cache命中,不需要重复计算,也就是说,Q_len<prompt_len。而由于每个query需要和所有历史的KV做Attention,因此,KV_len依然等于prompt_len。也就是,此时Q_len<KV_len=prompt_len,我们需要一个新的kernel来处理这种情况。vLLM中也正是这样处理的,目前prefix prefill kernel的实现在vllm/attention/ops/prefix_prefill.py(https://github.com/vllm-project/vllm/blob/main/vllm/attention/ops/prefix_prefill.py)。如果使用了prefix caching,则会走到这里实现的triton based prefix prefill kernel。

prefix prefill kernel
prefix prefill kernel相关的也有不少细节,这里先简单说明它解决的问题。后续会单独出一篇kernel讲解的文章,先挖个坑。后续,已填坑,kernel部分解析,请阅读:
DefTruth:[Prefill优化] 图解vLLM Prefix Prefill Triton Kernelhttps://zhuanlan.zhihu.com/p/695799736
0x09 vLLM Automatic Prefix Caching: 应用实践
这里简单提一下Prefix Caching在vLLM中需要怎样开启,使用方法非常简单。
- 离线推理: 指定enable_prefix_caching=True即可,示例来源于: vllm/bechmark_prefix_caching.py (https://github.com/vllm-project/vllm/blob/main/benchmarks/benchmark_prefix_caching.py)
import timefrom vllm import LLM, SamplingParamsPROMPT = "You are a helpful assistant in recognizes the content of tables in markdown format. Here is a table as fellows. You need to answer my question about the table.\n# Table\n|Opening|Opening|Sl. No.|Film|Cast|Director|Music Director|Notes|\n|----|----|----|----|----|----|----|----|\n|J A N|9|1|Agni Pushpam|Jayabharathi, Kamalahasan|Jeassy|M. K. Arjunan||\n|J A N|16|2|Priyamvada|Mohan Sharma, Lakshmi, KPAC Lalitha|K. S. Sethumadhavan|V. Dakshinamoorthy||\n|J A N|23|3|Yakshagaanam|Madhu, Sheela|Sheela|M. S. Viswanathan||\n|J A N|30|4|Paalkkadal|Sheela, Sharada|T. K. Prasad|A. T. Ummer||\n|F E B|5|5|Amma|Madhu, Srividya|M. Krishnan Nair|M. K. Arjunan||\n|F E B|13|6|Appooppan|Thikkurissi Sukumaran Nair, Kamal Haasan|P. Bhaskaran|M. S. Baburaj||\n|F E B|20|7|Srishti|Chowalloor Krishnankutty, Ravi Alummoodu|K. T. Muhammad|M. S. Baburaj||\n|F E B|20|8|Vanadevatha|Prem Nazir, Madhubala|Yusufali Kechery|G. Devarajan||\n|F E B|27|9|Samasya|Madhu, Kamalahaasan|K. Thankappan|Shyam||\n|F E B|27|10|Yudhabhoomi|K. P. Ummer, Vidhubala|Crossbelt Mani|R. K. Shekhar||\n|M A R|5|11|Seemantha Puthran|Prem Nazir, Jayabharathi|A. B. Raj|M. K. Arjunan||\n|M A R|12|12|Swapnadanam|Rani Chandra, Dr. Mohandas|K. G. George|Bhaskar Chandavarkar||\n|M A R|19|13|Thulavarsham|Prem Nazir, sreedevi, Sudheer|N. Sankaran Nair|V. Dakshinamoorthy||\n|M A R|20|14|Aruthu|Kaviyoor Ponnamma, Kamalahasan|Ravi|G. Devarajan||\n|M A R|26|15|Swimming Pool|Kamal Haasan, M. G. Soman|J. Sasikumar|M. K. Arjunan||\n\n# Question\nWhat' s the content in the (1,1) cells\n" # noqa: E501def test_prefix(llm=None, sampling_params=None, prompts=None):
start_time = time.time()
llm.generate(prompts, sampling_params=sampling_params)
end_time = time.time()
print(f"cost time {end_time - start_time}")def main(args):
llm = LLM(model="baichuan-inc/Baichuan2-13B-Chat",
tokenizer_mode='auto',
trust_remote_code=True,
enforce_eager=True,
tensor_parallel_size=2,
enable_prefix_caching=True)
num_prompts = 100
prompts = [PROMPT] * num_prompts
sampling_params = SamplingParams(temperature=0, max_tokens=10)
print("------warm up------")
test_prefix(llm=llm,prompts=prompts,sampling_params=sampling_params)
print("------start generating------")
test_prefix(llm=llm,prompts=prompts,sampling_params=sampling_params,)- 在线服务化:只需要在启动服务时添加 --enable-prefix-caching
python3 -m vllm.entrypoints.openai.api_server \ --model Qwen/Qwen1.5-72B-Chat \ --tensor-parallel-size 8 \ --trust-remote-code \ --enable-prefix-caching \ # 开启vLLM Automatic Prefix Caching
--enforce-eager \ --gpu-memory-utilization 0.90x0a Prefix Caching优化相关的其他论文
Prefix Caching的优化思路,并非只有SGLang RadixAttention以及vLLM中的实现。同期的论文还包括Prompt Cache、Share Prefixes、ChunkAttention等。但是这几篇论文都是只聚焦在Prefix本身,也就是属于“Only Prefix Caching”的情形,虽然依然具备一定的参考价值,但在通用性上,不及SGLang RadixAttention和vLLM的Hash版本RadixAttention实现。我个人更喜欢vLLM Hash RadixAttention实现,巧妙地通过token_ids构造hash码,这样构造的hash码,同时具备前缀树(Prefix Tree)的功能,确保了Prefix/Generated KV Caching中的上下文语义的唯一性和正确性。
- Prompt Cache
Prompt Cache
- Shared Prefixes
Shared Prefixes
- ChunkAttention
ChunkAttention
- [Prompt Cache]: Modular Attention Reuse for Low-Latency Inference(@yale.edu) https://arxiv.org/pdf/2311.04934
- [Cache Similarity]: Efficient Prompt Caching via Embedding Similarity(@UC Berkeley) https://arxiv.org/pdf/2402.01173
- [Shared Prefixes]: Hydragen: High-Throughput LLM Inference with Shared Prefixes(@Stanford University) https://arxiv.org/pdf/2402.05099v1
- [ChunkAttention]: ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition(@microsoft.com) https://arxiv.org/pdf/2402.15220
更多KV Cache优化相关的论文资料,可以参考我整理的Awesome LLM Inference仓库:

Awesome LLM Inference
A curated list of Awesome LLM Inference Paper with codehttps://github.com/DefTruth/Awesome-LLM-Inference
0x0b 总结
本文讲解了SGLang RadixAttention原理,并且结合图解和代码,详细分析了vLLM中的Hash RadixAttention实现。vLLM中的Hash RadixAttention内容包括:Hash RadixAttention、Hash Prefix Tree、Prefix/Generate 阶段Hash码处理、Prefix + Generated KV Caching的调度逻辑、边界情况思考、vLLM Automatic Prefix Caching在多轮对话中的应用分析以及代码应用实践。
本文草图使用http://draw.io绘制,欢迎自取:
https://github.com/DefTruth/CUDA-Learn-Notes/tree/main/draw.iohttps://github.com/DefTruth/CUDA-Learn-Notes/tree/main/draw.io
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-03,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 GiantPandaCV 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号