Multi-LoRA Composition | 无需训练的任意LoRA组合

Multi-LoRA Composition | 无需训练的任意LoRA组合

iResearch666
发布于 2024-03-14 11:22:45
发布于 2024-03-14 11:22:45
Multi-LoRA Composition | 无需训练的任意LoRA组合
本文主要介绍无需训练的任意数量LORA的切换与组合方法,说人话就是“可以将每个Lora的特色合成到一张图像上,比如人物、服装、物体这3个LORA通过不训练的方法,就可以在一张图像上合成这3种元素,且精度没有损失”。


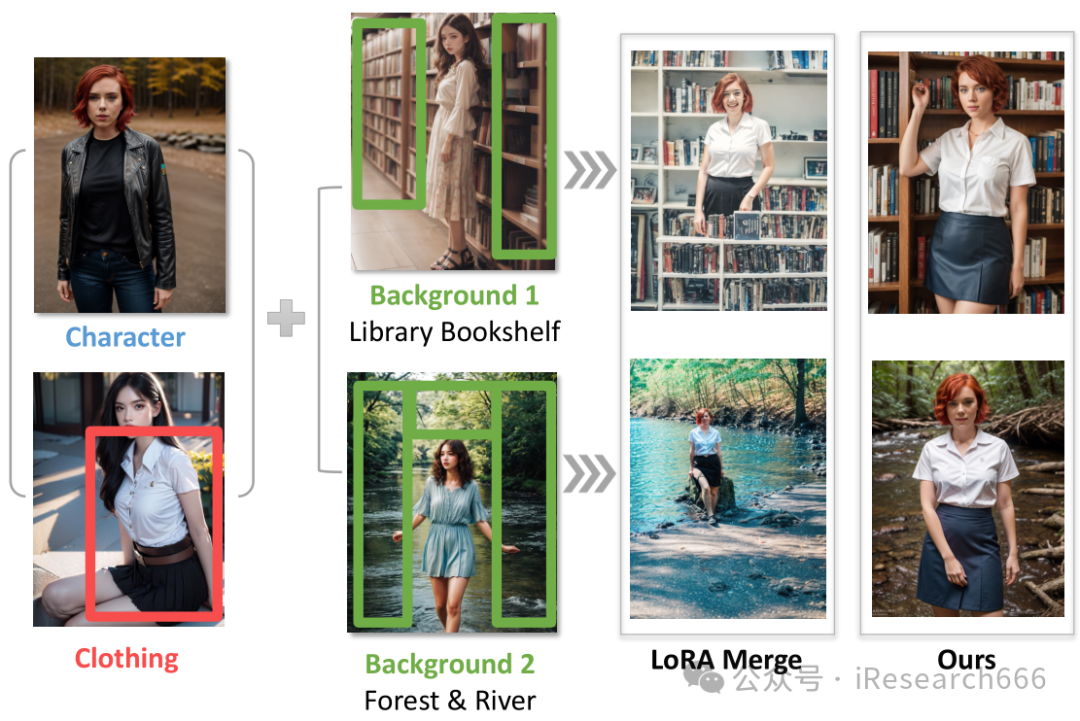
引言
该项目探索文本到图像生成的新方法,重点是集成多个低秩适应 (LoRA) 以创建高度定制和详细的图像。推出 LoRA Switch 和 LoRA Composite,这些方法旨在在准确性和图像质量方面超越传统技术,尤其是在复杂的构图中。
01 亮点介绍
无需训练,即可将任意数量的LoRA模型进行切换或者组合
- LoRA Switch 和 LoRA Composite 无需微调即可动态、精确地集成多个 LoRA。
- 与合并 LoRA 权重的方法不同,该方法专注于解码过程,保持所有 LoRA 权重完整。
02 先睹为快


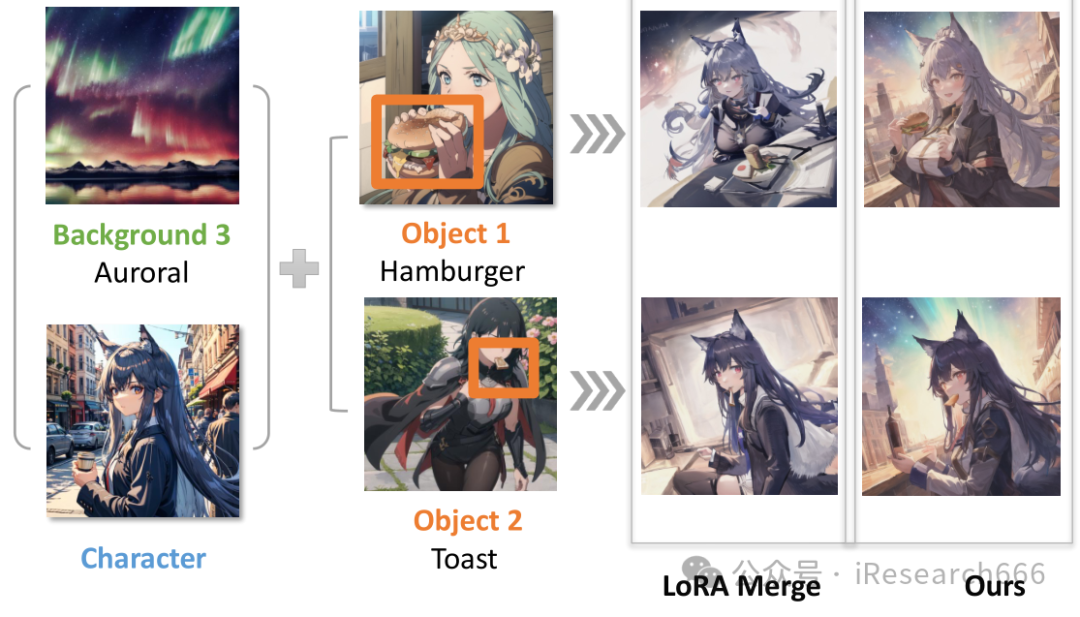
03 测试结果







方法论
01 三种Lora组合方法对比
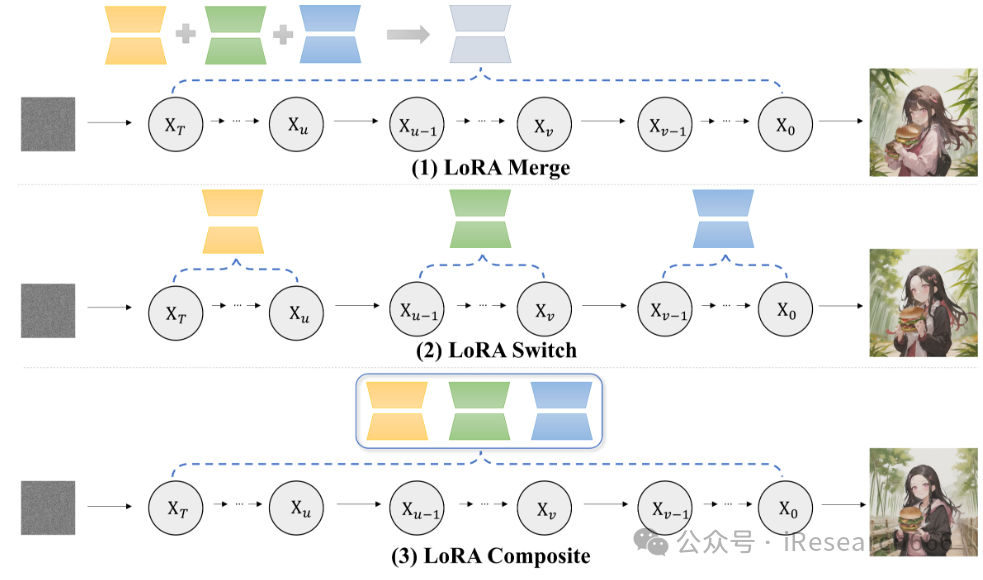
- LoRA Merge 合并,多个合成一个

- 在图像中以统一方式集成多个元素的流行方法。
- 它是通过线性组合多个 LoRA 来合成一个统一的 LoRA,然后插入到文本到图像模型中来实现的。
- LoAR Merge完全忽略了生成过程中与扩散模型的交互,导致图中汉堡包和手指的变形。
- LoRA Switch (LoRA-S) 切换,训练中等间隔切换Lora

- 为了探索在每个去噪步骤中激活单个 LoRA,我们提出了 LoRA Switch。
- 该方法通过在整个解码过程中以指定的时间间隔顺序激活各个 LoRA,在扩散模型中引入了动态适应机制。
- 如图所示,每个 LoRA 都由对应于特定元素的唯一颜色表示,每个去噪步骤仅使用一个 LoRA。
- LoRA Composite (LoRA-C) 组合,多个Lora元素组合为一个图像
- 为了探索在每个时间步合并所有 LoRA,而不合并权重矩阵,提出了 LoRA Composite。
- 它涉及在每个步骤中单独计算每个 LoRA 的无条件和条件分数估计。
- 通过汇总这些分数,该技术可确保在整个图像生成过程中提供平衡的指导,从而促进不同 LoRA 所代表的所有元素的紧密集成。

02 Lora切换与组合原理
这两种方法分别是LORA SWITCH和LORA COMPOSITE,它们都是在解码过程中应用的,不需要对LoRA权重进行训练或调整。以下是这两种方法的详细介绍:
- LORA SWITCH (LORA-S):

- LORA SWITCH方法通过在每个去噪步骤中选择性地激活单个LoRA来实现动态适应。在生成过程中,模型会在不同的LoRA之间进行轮换,确保每个元素都能被精确渲染。
- 例如,在虚拟试穿场景中,LORA SWITCH可能在连续的去噪步骤中交替激活角色LoRA和服装LoRA,以确保每个元素都能清晰地呈现。
- 该方法通过预先安排的排列顺序来激活LoRA,每个LoRA在特定的去噪步骤中被激活,然后按照顺序轮换,使得每个元素在图像生成过程中多次贡献。
- LORA COMPOSITE (LORA-C):
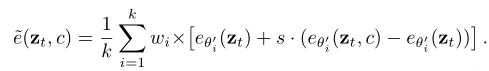
- LORA COMPOSITE方法受到无分类器引导(classifier-free guidance)的启发,它在每个去噪步骤中计算每个LoRA的无条件和条件分数估计,然后将这些分数平均,以提供平衡的图像生成指导。
- 这种方法确保了在图像生成过程中所有LoRA都能有效地贡献,解决了合并LoRA时可能出现的稳定性和细节保留问题。
- 具体来说,LORA COMPOSITE在每个去噪步骤中,根据文本条件c,从每个LoRA中聚合分数,以形成综合的指导分数,从而在生成过程中平衡地整合所有元素。
这两种方法都避免了对LoRA权重矩阵的直接操作,而是通过影响扩散过程来实现多LoRA的组合。这种方法允许在不牺牲图像质量的情况下,灵活地组合任意数量的LoRA,克服了现有研究中通常只能合并两个LoRA的限制。
03 基于GPT-4V的评估器

- 提出的方法在所有配置和两个维度上始终优于 LoRA Merge,并且随着 LoRA 数量的增长,优越性也随之增加。
- LoRA Switch 在合成质量方面表现出卓越的性能,而 LoRA Composite 在图像质量方面表现出色。
- 合成图像生成的任务仍然非常具有挑战性,特别是随着要合成的元素数量的增加。

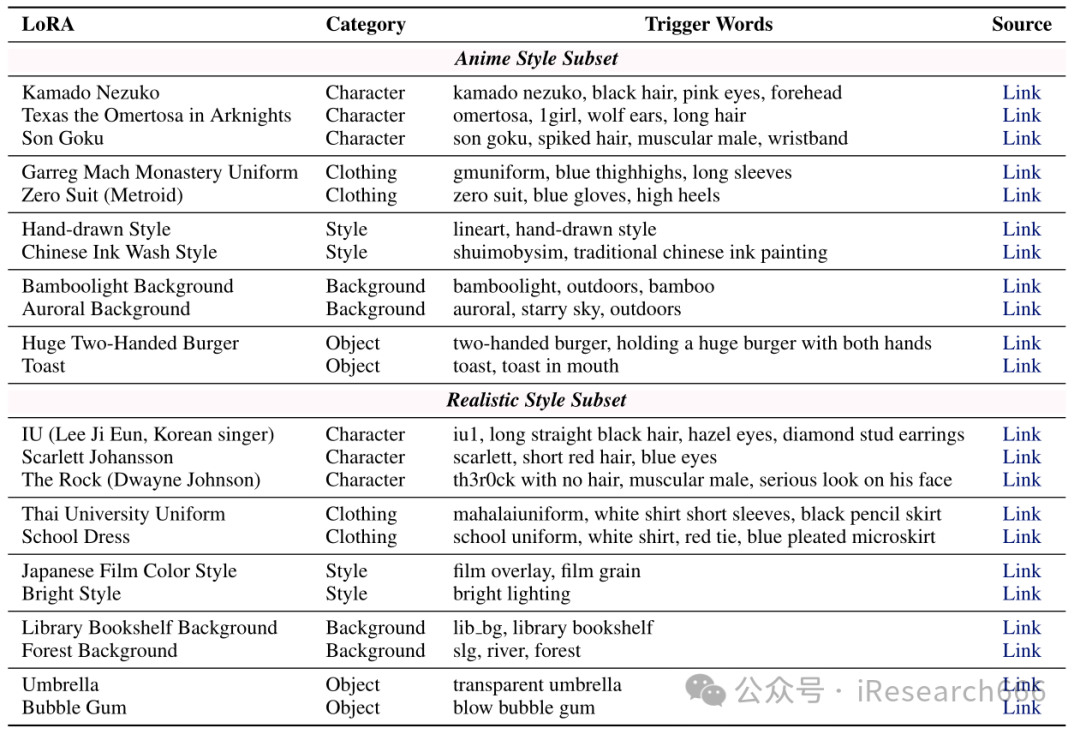
04 LoRA模型类别
- ComposLoRA 具有 22 个 LoRA 和 480 个不同的组合集,允许生成具有 2-5 个 LoRA 的任意组合的图像,包括至少一个字符 LoRA。
内容概述
论文题目《Multi-LoRA Composition for Image Generation》
摘要:
- 论文介绍了在文本到图像模型中广泛使用的低秩适应(Low-Rank Adaptation,LoRA)技术,用于精确渲染生成图像中特定元素,如独特角色或风格。
- 现有方法在有效组合多个LoRA时面临挑战,尤其是在集成LoRA数量增加时,这限制了复杂图像的创建。
- 论文从解码中心的角度研究多LoRA组合,并提出了两种无需训练的方法:LORA SWITCH和LORA COMPOSITE。
- LORA SWITCH在每个去噪步骤中交替激活不同的LoRA,而LORA COMPOSITE同时结合所有LoRA以指导更连贯的图像合成。
- 为了评估这些方法,研究者建立了一个新的综合测试平台ComposLoRA,包含480个组合集。
- 使用基于GPT-4V的评估框架,研究结果表明,这些方法在性能上明显优于现有基线,尤其是在组合中LoRA数量增加时。
引言:
- 论文讨论了LoRA在图像生成中的应用,以及如何通过LoRA实现个性化和真实的图像表示。
- 强调了组合性在可控图像生成中的重要性,并提出了通过组合多个专注于不同元素的LoRA来实现高级定制的策略。
方法:
- 论文详细介绍了LoRA的基本概念,包括扩散模型、无分类器引导(classifier-free guidance)和LoRA合并(LoRA Merge)。
- 提出了两种新的多LoRA组合方法:LORA SWITCH和LORA COMPOSITE,这两种方法都避免了对LoRA权重矩阵的操纵,而是直接影响扩散过程。
实验:
- 介绍了ComposLoRA测试平台,它包含了多种LoRA类别和480个组合集。
- 使用GPT-4V作为评估器,对图像质量和组合效果进行了评估。
- 实验结果表明,提出的LORA SWITCH和LORA COMPOSITE方法在性能上优于LoRA Merge方法。
分析:
- 论文分析了不同图像风格(现实风格和动漫风格)对方法性能的影响。
- 探讨了LoRA激活顺序和步长对LORA SWITCH性能的影响。
- 分析了GPT-4V作为评估器时的潜在偏见。
相关工作:
- 论文回顾了可组合文本到图像生成的相关研究,以及基于LoRA的操作研究。
结论:
- 论文提出了从解码中心视角探索多LoRA组合的首次尝试,并介绍了LORA-S和LORA-C方法,这些方法超越了当前基于权重操作的技术限制。
- 通过建立专门的测试平台ComposLoRA,引入了可扩展的自动化评估指标,使用GPT-4V进行评估。
- 研究不仅突出了这些方法实现的优越质量,而且为评估基于LoRA的可组合图像生成提供了新的标准。
附录:
- 提供了ComposLoRA中每个LoRA的详细描述,以及用于GPT-4V比较评估的完整评估提示和结果。
实战教程
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
'SG161222/Realistic_Vision_V5.1_noVAE',
custom_pipeline="MingZhong/StableDiffusionPipeline-with-LoRA-C",
use_safetensors=True
).to("cuda")
# Load LoRAs
lora_path = 'models/lora/reality'
pipeline.load_lora_weights(lora_path, weight_name="character_2.safetensors", adapter_name="character")
pipeline.load_lora_weights(lora_path, weight_name="clothing_2.safetensors", adapter_name="clothing")
# List of LoRAs to be composed
cur_loras = ["character", "clothing"]
# Set the prompts for image generation
prompt = "RAW photo, subject, 8k uhd, dslr, high quality, Fujifilm XT3, half-length portrait from knees up, scarlett, short red hair, blue eyes, school uniform, white shirt, red tie, blue pleated microskirt"
negative_prompt = "extra heads, nsfw, deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime, text, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck"
# Generate and save the image
generator = torch.manual_seed(11)
image = pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
height=1024,
width=768,
num_inference_steps=100,
guidance_scale=7,
generator=generator,
cross_attention_kwargs={"scale": 0.8},
callback_on_step_end=switch_callback,
lora_composite=True if method == "composite" else False
).images[0]
image.save('example.png')

应用场景
提出的多LoRA组合方法(LORA SWITCH和LORA COMPOSITE)可以应用于多种图像生成场景,尤其是在需要精确控制和组合多个视觉元素的情况下。以下是一些具体的应用场景:
- 个性化图像生成:
- 用户可以根据自己的喜好定制图像,例如生成具有特定角色、服装或风格的个性化图像。
- 虚拟试穿:
- 在电子商务中,用户可以上传自己的照片,并尝试不同的服装或配饰,以查看搭配效果。
- 动漫风格转换:
- 将现实风格的照片转换成动漫风格,或者在动漫创作中实现特定角色的个性化设计。
- 游戏角色设计:
- 在游戏开发中,设计师可以利用这些方法快速生成或修改角色的外观,包括服装、发型和配饰。
- 电影和动画制作:
- 在电影和动画制作中,这些技术可以用来创建复杂的场景和角色,提高制作效率。
- 艺术创作辅助:
- 艺术家可以使用这些工具来辅助创作,例如生成草图或概念艺术,然后在此基础上进行细化。
- 社交媒体内容创作:
- 社交媒体用户可以利用这些工具生成独特的图像内容,用于个人表达或吸引关注。
- 教育和培训:
- 在教育领域,可以创建定制的图像来辅助教学,例如历史场景重现或科学概念可视化。
- 广告和营销:
- 广告商可以利用这些技术快速生成吸引人的广告图像,以适应不同的市场和客户群体。
- 数据增强:
- 在机器学习中,这些方法可以用来生成新的训练数据,特别是在数据集有限的情况下。
这些应用场景展示了多LoRA组合方法在图像生成领域的广泛潜力,尤其是在需要高度定制化和创意表达的场合。通过这些方法,用户可以实现更精细的图像控制,创造出符合特定需求的视觉内容。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-06,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 iResearch666 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号