入门自然语言处理(二):GRU


本文是对GRU的精简介绍,对于初学者可以看详细介绍:https://zh.d2l.ai/chapter_recurrent-modern/gru.html
简介
GRU (Gate Recurrent Unit ) 背后的原理与 LSTM 非常相似,即用门控机制控制输入、记忆等信息而在当前时间步做出预测。
GRU 有两个门,即一个重置门(reset gate)和一个更新门(update gate)。从直观上来说,「重置门决定了如何将新的输入信息与前面的记忆相结合,更新门定义了前面记忆保存到当前时间步的量」。如果我们将重置门设置为 1,更新门设置为 0,那么我们将再次获得标准 RNN 模型。
GRU 原论文:https://arxiv.org/pdf/1406.1078v3.pdf
Why
- 解决长期记忆和反向传播中的梯度等问题
- LSTM能够解决循环神经网络因长期依赖带来的梯度消失和梯度爆炸问题,但是LSTM有三个不同的门,参数较多,训练起来比较困难。GRU只含有两个门控结构,且在超参数全部调优的情况下,二者性能相当,但是GRU结构更为简单,训练样本较少,易实现。R-NET: MACHINE READING COMPREHENSION WITH SELF-MATCHING NETWORKS(2017)
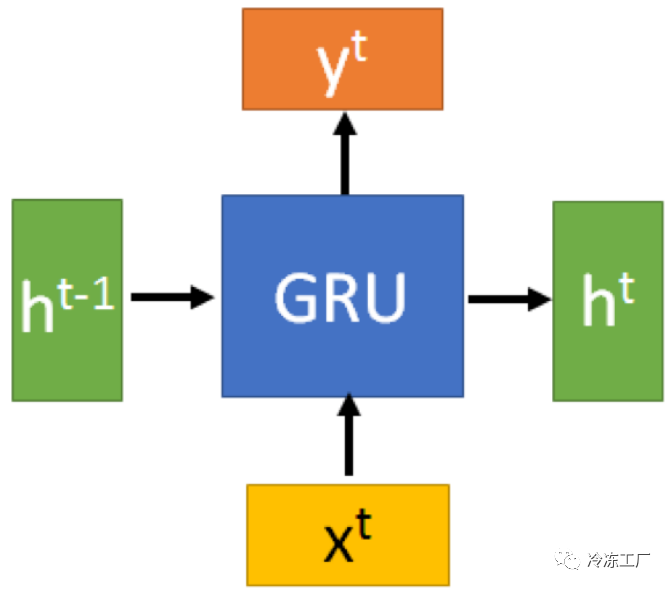
Model
整体结构
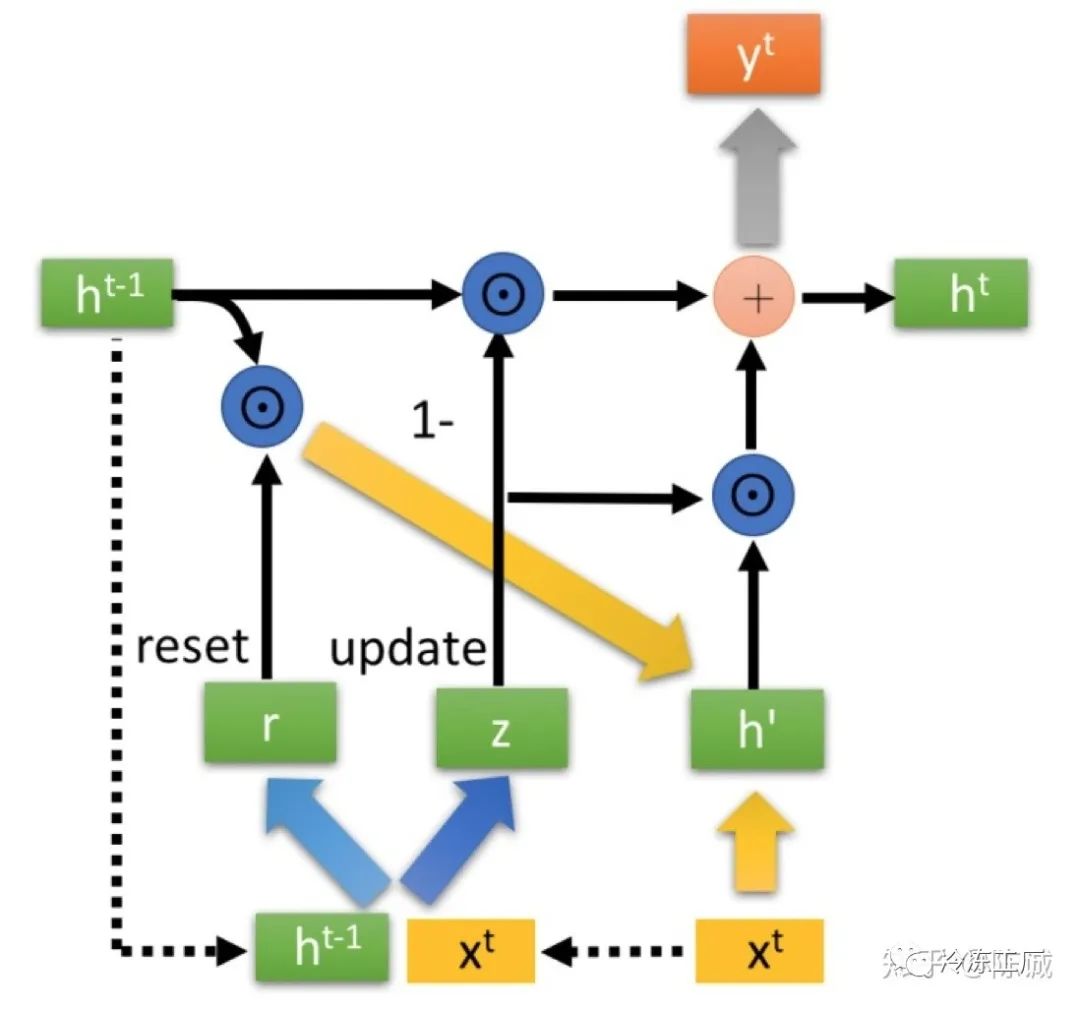
⊙ 是Hadamard Product,也就是操作矩阵中对应的元素相乘,因此要求两个相乘矩阵是同型的。 ⊕ 则代表进行矩阵加法操作。
输入与输出
- 当前输入:
- 上一个节点传递下来的隐状态(hidden state):
这个隐状态包含了之前节点的相关信息。
- 输出:
- 传递给下一个节点的隐状态 :
门控结构
根据输入获取重置的门控(reset gate)和 控制更新的门控(update gate)
为*sigmoid*函数,通过这个函数可以将数据变换为0-1范围内的数值,从而来充当门控信号。
重置数据
如何根据门控重置数据

其中的
根据下面的公式获取:
⊙
Code
class testGRU(nn.Module):
def __init__(self, input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, num_classes=num_classes, sequence_length=sequence_length):
super(SimpleGRU, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.gru = nn.GRU(input_size, hidden_size, num_layers, batch_first=True)
self.fc1 = nn.Linear(hidden_size * sequence_length, num_classes)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
out,_ = self.gru(x, h0)
out = out.reshape(out.shape[0], -1)
out = self.fc1(out)
return out
References
- https://zhuanlan.zhihu.com/p/32481747
- https://www.jiqizhixin.com/articles/2017-12-24
- https://paddlepedia.readthedocs.io/en/latest/tutorials/sequence_model/gru.html
- https://www.kaggle.com/code/fanbyprinciple/learning-pytorch-3-coding-an-rnn-gru-lstm
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-11-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号