SPTS v2:华科华工联合发布,端到端文本检测识别提速19倍

SPTS v2:华科华工联合发布,端到端文本检测识别提速19倍

公众号机器学习与AI生成创作
发布于 2023-11-03 16:58:24
发布于 2023-11-03 16:58:24
文源 新智元 编辑:LRS 好困
【新智元导读】单点文本框标注,成本显著降低;将检测和识别解耦,并行解码提升自回归速度。
近年来,场景文本阅读(Text Spotting)有了显著进步,能同时定位和识别文本,广泛应用于智慧办公、金融、交通等领域。
然而,与目标检测相比,文字除了定位还需要精确识别内容;同时,由于字体和排版的不同,文本实例可能以任意形状呈现,这就需要使用包含更多坐标的边界框来标注,例如SCUT-CTW1500最多使用了28个坐标进行标注,标注成本十分高昂。

近几年,以多边形及贝塞尔曲线表征为基准的任意形状文字表征成为了主流研究方向。然而多边形的标注成本十分昂贵。
在此背景下,SPTS系列论文首次证明了不需要任何标注框,仅用单点标注即可取得最好的识别结果,极大地降低了标注成本,同时单点显著地降低了表示文本的序列长度。
然而,由于文本内容(transcript)通常很长(如默认最少25),将所有文本放在一个自回归序列中串行解码依然会导致推理时间非常长。

论文链接:https://arxiv.org/abs/2301.01635
代码地址:https://github.com/Yuliang-Liu/SPTSv2
今年9月,华中科技大学白翔团队刘禹良研究员联合华南理工大学、浙江大学、香港中文大学、字节跳动等机构的研究人员于TPAMI在线发表了SPTS v2的相关工作,针对端到端场景文本检测识别任务,提出基于单点标注的SPTS v2方法。
该方法采用了单点来指示文本位置,采用语言序列统一表征图片、坐标及文本等不同模态,使得检测及识别任务的融合更加紧密,也免除了先验知识的介入和复杂的后处理操作。针对其自回归推理速度较慢的问题,通过将检测识别解耦为自回归的单点序列预测及基于每个单点的并行文本识别进行推理加速。
此外,该方法同样采用了单点来指示文本位置,极大地降低了标注成本,并且使用序列预测的方式完成端到端场景文本检测识别任务,使得两个任务的融合更加紧密,也免除了先验知识的介入和复杂的后处理操作。
实验证明该方法在多个场景文本端到端检测识别数据集上优于现有方法,同时相对于SPTS v1达到了19倍的推理加速。
大白话SPTSv2
1. 怎么用点实现Text Spotting?
以前的Text Spotting方法通常依赖于先检测后采样再识别的端到端模式,强依赖于核心对齐模块,如Mask TextSpotter[2]的Hard ROIMasking、TextDragon[3]的ROISlide及ABCNet[4]的BezierAlign等。

SPTSv2通过序列来统一表征文本实例位置和内容,将Text Spotting简化为离散空间的连续描述。这种检测识别同时预测的方式解耦了识别对检测结果的强依赖,鉴于此,该方法进一步将边界框简化为位于一个点标注。
2. 为什么SPTSv2能显著降低推理时间?
自回归方法的推理时间,在很大程度由串行循环次数决定。
假设一张图片最多包含N个文本实例,每个实例最多包含K个字符,每个实例的位置表征个数为T(单点为2,包括横纵坐标,14点的多边形就是28)。
对于原始的自回归来说,将所有坐标和文本都放在一个序列里面实现,那么预测这张图片需要(T + K) * N + 1个串行循环次数;最后的+1代表终止符号。
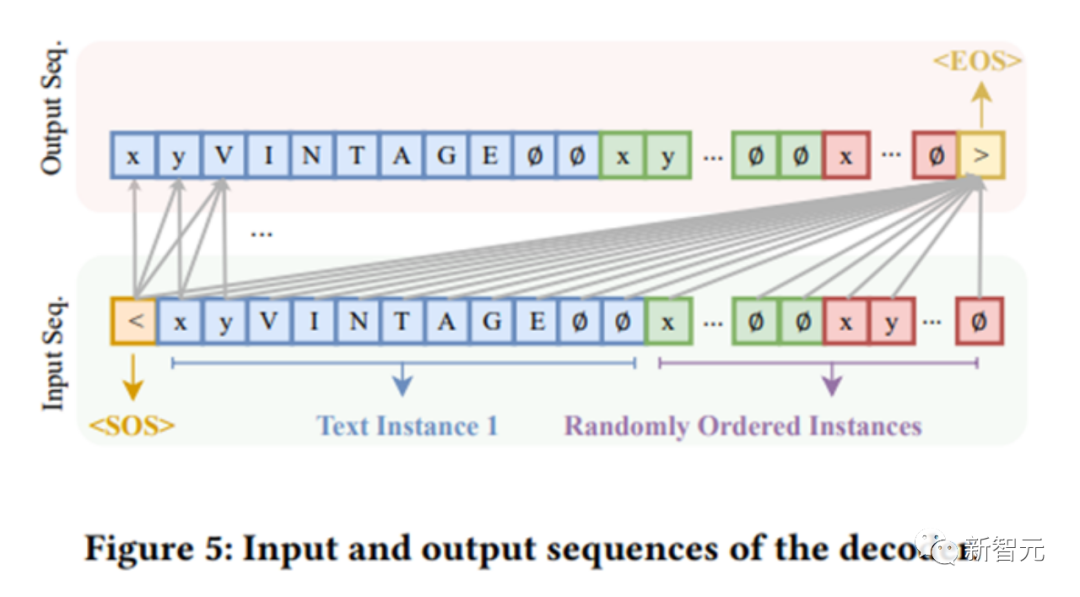
举个例子,假设设置最长有100个文本实例,最大长度取最小默认值25。
那么,对于单点来说,串行循环次数是2701次。对于多边形来说就是5301次。
而SPTS v2提出了实例分配解码器(IAD)和并行识别解码器(PRD),串行自回归只需要单点坐标参与,识别解码是由每个单点并行自回归得到的,总共只需T * N + K + 1个串循环次数,减少了K * (N - 1)。
那么在上述例子中,SPTSv2只需要226次,循环数量减少了91.6%(226/2701),对于文本行来说,K通常取100,此时循环数量甚至减少了97.0%!
同时,在实际上可能串行循环次数还能进一步减少,因为在SPTSv2的识别预测上,如果所有实例都遇到序列结束符,SPTS v2也可以提前结束。
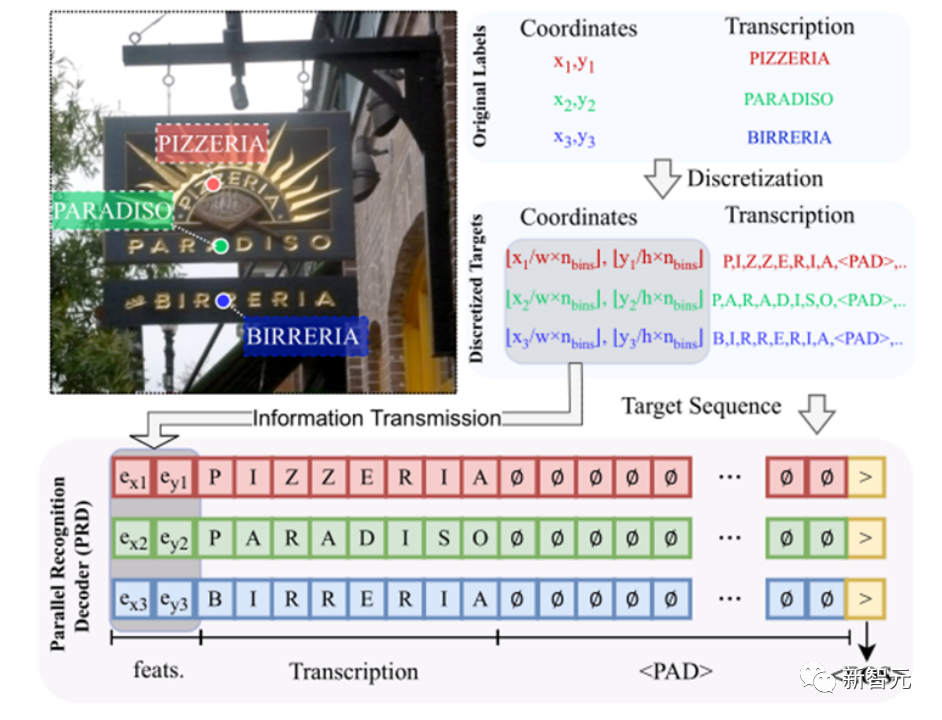
因此,通过这种并行预测,推理速度可以显著提高。
3. 点的表征有什么性质及优点?
① 点的标注可以很随意。
实验表明,点即使是随机的一个点,效果依然是和全部选取中心点相差不大的,甚至比全部取左上角点还要高。这意味着标注人员仅需对着文本随意点一个点即可标注文本。

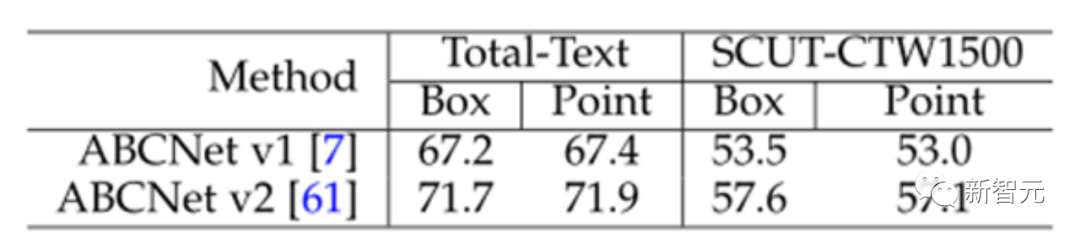
② 点的性能很高。
文中点的性能取得了最好的Text Spotting结果。同时为了消除是否是因为点和框不同评估标准的影响,实验验证了点的评估和框的评估性能差异不大。
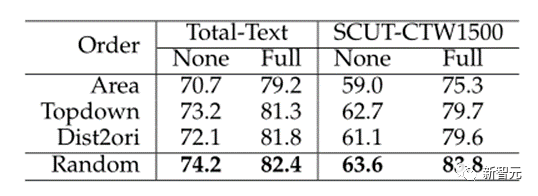
③ 随机文本排序最好。
由于自回归的有序性,第一阶段预测哪个文本点的顺序可能会对结果产生影响。实验表明随机点排序达到了最佳性能,因为它可能会在以后捕获那些丢失的对象。由于在不同迭代中为同一图像构建的不同序列,这使模型更加鲁棒。这一结论也与Pix2seq[5]一致。
④对噪声更加鲁棒。
在SCUT-CTW1500上对框或者点的坐标加上随机扰动,实验结果表明SPTSV2相比于基于框的方法能够更好地应对标注噪声。
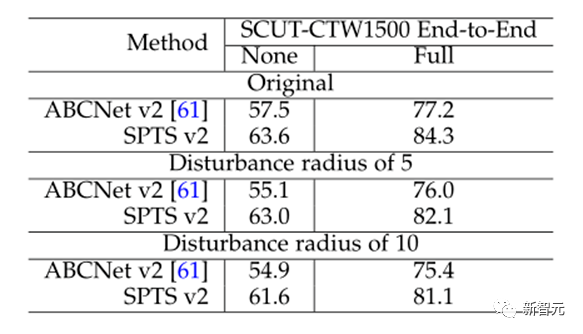
⑤甚至很长的文本行也可以仅用一个点标注。
如SCUT-CTW1500就是文本行数据,SPTSv2效果不仅是最好的,还大幅好于基于框的方法。

4. 既然检测识别解耦,是不是该方法不需要点也能识别结果?
回答是肯定的。文中进一步尝试了No-Point Text Spotting(NPTS),在仅仅使用文本转录训练的情况下,NPTS取得了较好的性能。
但是,相比起有单点标注的结果,性能差距十分明显,平均10%以上的差距,这证明点的标注对最终性能还是至关重要的。

此外,值得一提的是,文中还有一个有趣的发现。仅仅只是在SPTS的框架内验证,如果不预测点,而是预测水平矩形框和多边形,效果不如点。
针对这一现象,文中做了一些分析:
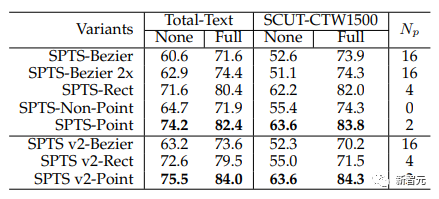
① SPTS-Rect和SPTS-Bezier的结果是根据与SPTS-Point相同的训练时长获得的,三者除了点的数量以外其他严格一致。
实验显示,训练了2倍周期的SPTS-Bezier与1倍周期的比没有显著超越。此外,采用较长的时间甚至会导致其在SCUT-CTW1500的None指标上的表现降低,这表明训练时长可能不是主要问题。
② 过去Text Spotting方法经常可以观察到,有时即使检测结果不准确,识别结果仍然可以准确。
这是因为文本识别的对齐是基于特征空间的,其中裁剪的特征对于文本内容有足够的接受字段,这表明方法对于框的位置标注要求并不是非常敏感。
由于SPTSv2的方法中图像是利用Transformer进行全局编码的,近似的位置可能足以让模型捕获附近的所需特征。
当然这一结论仅仅只是在SPTSv2的框架内做了验证。

总结
本文的方法能够在任意形状的文本上获得更好的准确性的原因可能是:所提出的方法丢弃了基于先验知识设计的特定任务模块(例如RoI模块)。
因此,识别精度与检测结果解耦,即使检测标注点在文本区域内随机,本文的方法也能获得鲁棒的识别结果。
实验证明SPTS v2在多个场景文本端到端检测识别数据集中均有出色的表现,且推理速度可达到SPTS的19倍。
SPTS v2将多模态数据统一表征的训练方法使其特别适合多模态、多任务场景,且整个方法仅需一个交叉熵损失函数,框架十分简洁。另一方面,它能大大减少所需的自回归序列长度(如减少91%)。
事实上,这也引发了思考,大模型ChatGPT本质上也是一个自回归Transformer。
假如,当其能够在第一阶段串行输出关键点,建模不同点之间的关系,那么第二阶段是否也可以根据不同关键点并行输出所有文本内容,这种「分点作答」的方式,或许也可以大幅度提升大模型输出的速度。
参考资料:
[1] Yuliang Liu, et al. “SPTS v2: Single-Point Scene Text Spotting.” IEEE Transactions on Pattern Analysis and Machine Intelligence. 2023.
[2] Minghui Liao, et al. "Mask textspotter v3: Segmentation proposal network for robust scene text spotting." Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XI 16. Springer International Publishing, 2020.
[3] Feng Wei, et al. "Textdragon: An end-to-end framework for arbitrary shaped text spotting." Proceedings of the IEEE/CVF international conference on computer vision. 2019.
[4] Yuliang Liu, et al. "Abcnet v2: Adaptive bezier-curve network for real-time end-to-end text spotting." IEEE Transactions on Pattern Analysis and Machine Intelligence 44.11 (2021): 8048-8064.
[5] Chen Ting, et al. "Pix2seq: A language modeling framework for object detection." arXiv preprint arXiv:2109.10852 (2021).
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-11-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号