OpenAnnotate3D:一个目标取代人类的标注工具

OpenAnnotate3D:一个目标取代人类的标注工具

点云PCL博主
发布于 2023-11-03 15:38:31
发布于 2023-11-03 15:38:31
文章:OpenAnnotate3D: Open-Vocabulary Auto-Labeling System for Multi-modal 3D Data
作者:Yijie Zhou, Likun Cai, Xianhui Cheng, Zhongxue Gan, Xiangyang Xue, and Wenchao Ding
编辑:点云PCL
代码:https://github.com/Fudan-ProjectTitan/OpenAnnotate3D.git
欢迎各位加入知识星球,获取PDF论文,欢迎转发朋友圈。文章仅做学术分享,如有侵权联系删文。
公众号致力于点云处理,SLAM,三维视觉,高精地图等领域相关内容的干货分享,欢迎各位加入,有兴趣的可联系dianyunpcl@163.com。侵权或转载联系
摘要
在大数据和大型模型时代,对于多模态数据的自动标注功能对于实际的人工智能驱动应用非常重要,比如自动驾驶和智能设备,与传统的封闭标注不同,开放词袋标注对于实现人类级认知能力至关重要。然而对于多模态3D数据,几乎没有开放词袋的自动标注系统。本文介绍了OpenAnnotate3D,这是一个开源的开放词汇的自动标注系统,可以自动生成视觉和点云数据的2D掩模、3D掩模和3D边界框标注。我们的系统整合了大型语言模型(LLMs)的思维链能力和视觉语言模型(VLMs)的跨模态能力。据我们所知OpenAnnotate3D是开放词汇多模态3D自动标记的先驱之一。对公共数据集进行了全面评估,结果表明与手动标注相比,该系统显著提高了标注效率,同时提供了准确的开放词汇自动标注的结果。
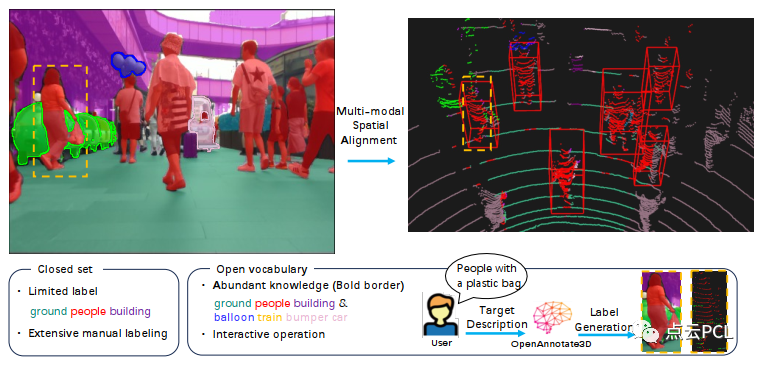
图1:开放词袋多模态3D标注的示意图。与可以为已知类别(如“地面”,“人”和“建筑物”)提供标签的封闭的标注系统相比,OpenAnnotate3D可以为稀有对象(如“气球”和“碰碰车”)提供开放词汇的3D标注。
主要贡献
本文提出了一种名为OpenAnnotate3D的新型数据标注系统,该系统包括基于LLM的解释器模块、可提示的视觉模块以及时空3D自动标注过程。我们的标注系统在接收到多模态3D数据(视觉和点云)和高级标签请求时,例如“标记路边的气球”和“标记右侧携带奇怪货物的骑自行车者”。该系统明确使用LLM解释器推理请求,自动将文本信息与语义3D世界中的特定对象进行匹配,并生成如图1所示的2D掩码、3D掩码和3D边界框注释。该系统有两个亮点。首先基于LLM的解释器模块以闭环迭代方式将LLM和可提示的视觉模型(VLMs)相结合,以更精确地解释高级用户命令。其次还包括了一个时空融合和校正模块,以克服VLMs产生的单帧结果的不完善之处。我们的贡献总结如下:
- 面向多模态3D数据的开源开放词汇自动标注系统的先驱。
- 基于LLM的解释器,以闭环迭代方式与可提示的视觉模块互动,实现高级命令的有效推理。
- 一种时空融合和校正方法,克服了单帧自动标注中的不完善之处。
- 大量实验验证了所提出系统的卓越效率和开放词汇场景理解能力。
内容概述
本文详细介绍OpenAnnotate3D的工作流程以及实现的各个组件,图2展示了我们系统的整个自动标注过程,它接收文本描述T,RGB图像I和3D点云P作为输入,为了进一步减少用户的物理交互频率,该系统还支持语音输入,这些语音信号会通过语音识别模型Whisper自动转录成文本。我们的系统可以根据用户提供的描述性文本生成精确的2D掩码、3D掩码和3D边界框注释。
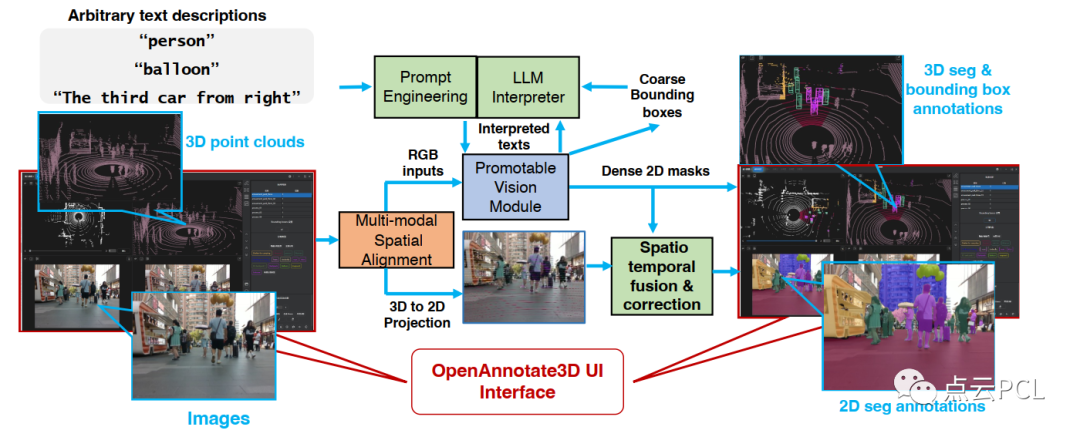
图2: OpenAnnotate3D的工作流程,在接收用户的标注请求后,系统首先通过LLM解释器和适当的提示工程来对请求进行推理。解释器可能会与可提示的视觉模块互动多轮,以使解释的文本适应可提示的视觉模块的推理能力。然后生成密集的2D掩码,通过多模式空间对齐进一步计算3D掩码,为了克服2D掩码的不完美之处,进行了时空融合和校正以精炼3D标签。
基于LLM的解释器模块
系统旨在基于灵活的用户提供的文本描述为一个或多个开放词汇实例进行标注,标注请求可以是高级和抽象的,例如“标记路上的气球”。为此使用LLM作为语义解释器,将用户提供的提示转化为可被VLMs理解的纯文本输出。

图3: 基于预定义提示的解释过程示意图。使用预定义的提示模板,可以为LLM分配一个角色,指定可用的工具。此外,与可提示视觉模块的交互历史被记录并纳入考虑。
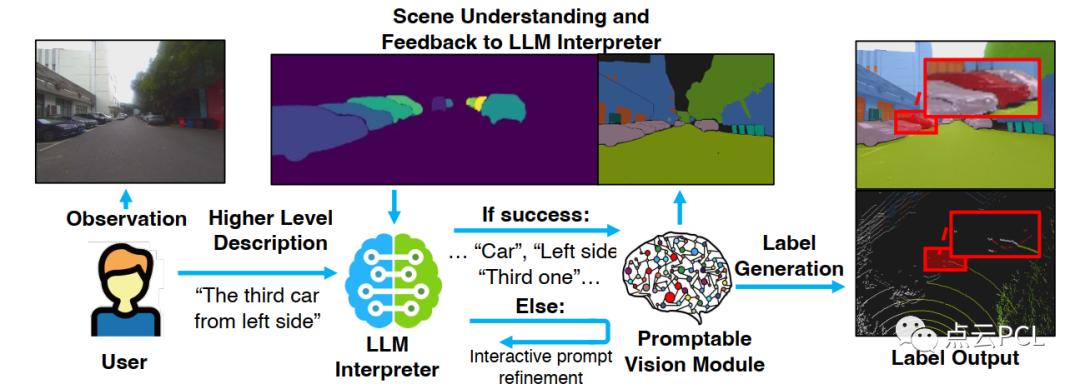
图4:迭代文本解释的流程。LLM首先解释用户的目标提示,提取核心内容,然后通过向可提示的视觉模块进行初始查询来获取场景特征。然后LLM解释器基于可提示的视觉模块的场景理解结果不断完善视觉模块的提示。这显著增强了推理能力和分割准确性。
可提示视觉模块和3D自动标注
在LLM解释器之后构建了一个可以自动注释3D多模态数据的标注过程,当前现成的跨模态视觉-语言模型基于2D图像,例如CLIP和SAM。
多模式空间对齐:如前所述OpenAnnotate3D旨在对RGB和3D点云数据执行对象级别的标注,几乎没有直接处理多模式3D数据的开放词汇模型,因此,我们进行多模式空间对齐,以更好地利用2D VLM的推理能力。
时空融合和校正:在处理多帧视频数据时提供两种可选方案,实现连续帧标注。在第一种方法中,用户可以明确指定视频段内的起始帧和结束帧。一旦系统自动标记了这两帧,就会使用插值算法来标记该视频中的其余帧,这种方法非常高效,但可能不能保证中间帧的注释准确性。
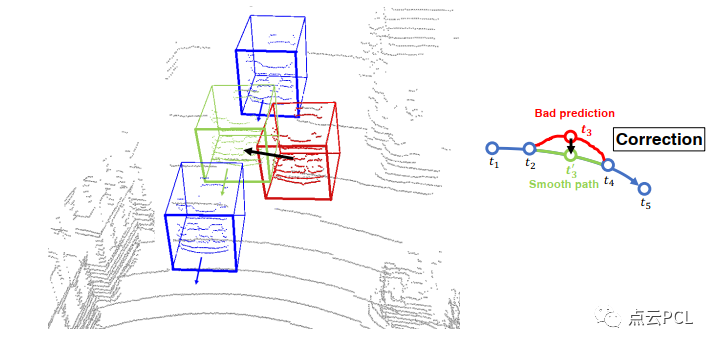
图5,演示了时空融合和校正如何修复不正确注释的结果。
实验
为了评估我们的OpenAnnotate3D系统,在公共基准数据集和内部多模态数据集上进行了实验。如图6所示,展示了OpenAnnotate3D在现实世界场景数据上的标注能力。我们的标注系统不仅可以一致而自动地为一些常见的封闭集对象进行标注,如“自行车”、“人”、“建筑”和“摩托车”,还可以准确识别以前未在封闭集数据中标注的许多开放词汇对象。这些开放词汇对象包括“气球”、“背包”、“行李箱”,以及长描述,如“携带手提箱的人”。这些示例突显了我们标注系统强大的开放词汇标注能力。
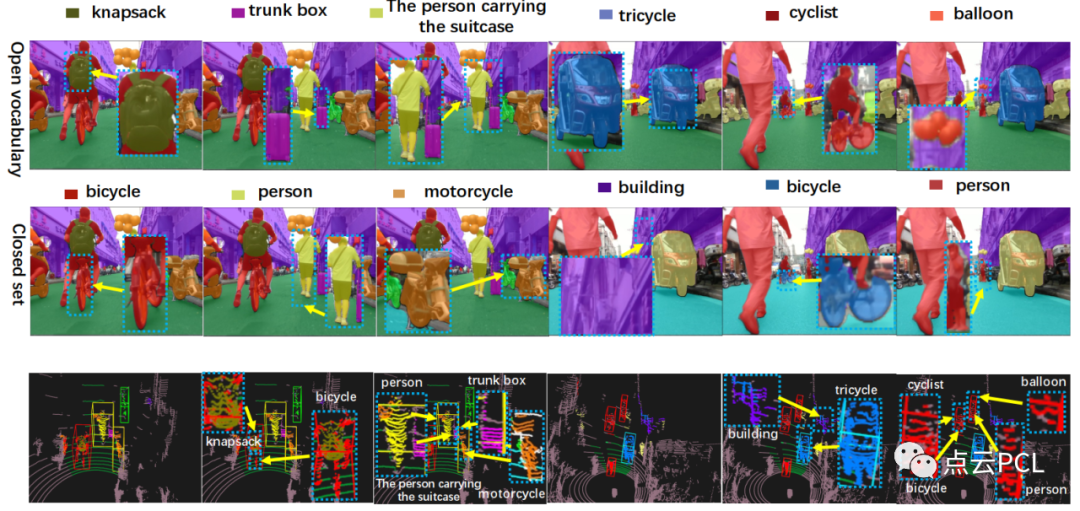
图6: OpenAnnotate3D在in-house数据集上生成的开放词汇标注的可视化。
我们记录了不同标注者完成任务所花费的时间以及与地面实况相比注释的精度,标注结果如表I所示,提供了每个类别的IoU,尤其是对于具有复杂形状的物体,如“人”,“植被”,或相对较小的物体,如“杆”,即使是资深的人类标注者也只能达到67.8%,69.9%和45.3%的IoU。相比之下,我们的OpenAnnotate分别达到了75.3%,81.4%和58.2%的IoU,而无需进行任何手动微调。对于人眼难以精确识别的物体,我们的自动系统表现出更为明显的优势。

时间成本如表II所示,正如我们所看到的,我们的OpenAnnotate3D相对于手动注释而言,耗费的时间明显更少,尤其是对于形状不规则且面积较大的物体,如“植被”和“摩托车”。此外,我们的OpenAnnotate3D,速度稳定(主要取决于GPU性能),可以用时间来量化。相比之下,手动注释不仅效率低,而且在不同用户之间的专业水平上存在差异。

总结
本文提出了OpenAnnotate3D,这是一个开源的、用于多模式3D数据的开放词汇自动标注系统,包括一个基于LLM的解释器模块、一个可提示的视觉模块和一个时空3D自动标注过程,OpenAnnotate3D集成了大型语言模型(LLMs)的思维链能力和视觉语言模型的跨模态能力。据我们所知,OpenAnnotate3D是开放词汇多模式3D自动标注的先驱性工作之一。
资源
自动驾驶及定位相关分享
【点云论文速读】基于激光雷达的里程计及3D点云地图中的定位方法
自动驾驶中基于光流的运动物体检测
基于语义分割的相机外参标定
综述:用于自动驾驶的全景鱼眼相机的理论模型和感知介绍
高速场景下自动驾驶车辆定位方法综述
Patchwork++:基于点云的快速、稳健的地面分割方法
PaGO-LOAM:基于地面优化的激光雷达里程计
多模态路沿检测与滤波方法
多个激光雷达同时校准、定位和建图的框架
动态的城市环境中杆状物的提取建图与长期定位
非重复型扫描激光雷达的运动畸变矫正
快速紧耦合的稀疏直接雷达-惯性-视觉里程计
基于相机和低分辨率激光雷达的三维车辆检测
用于三维点云语义分割的标注工具和城市数据集
ROS2入门之基本介绍
固态激光雷达和相机系统的自动标定
激光雷达+GPS+IMU+轮速计的传感器融合定位方案
基于稀疏语义视觉特征的道路场景的建图与定位
自动驾驶中基于激光雷达的车辆道路和人行道实时检测(代码开源)
用于三维点云语义分割的标注工具和城市数据集
更多文章可查看:点云学习历史文章大汇总
SLAM及AR相关分享
TOF相机原理介绍
TOF飞行时间深度相机介绍
结构化PLP-SLAM:单目、RGB-D和双目相机使用点线面的高效稀疏建图与定位方案
开源又优化的F-LOAM方案:基于优化的SC-F-LOAM
【论文速读】AVP-SLAM:自动泊车系统中的语义SLAM
【点云论文速读】StructSLAM:结构化线特征SLAM
SLAM和AR综述
常用的3D深度相机
AR设备单目视觉惯导SLAM算法综述与评价
SLAM综述(4)激光与视觉融合SLAM
Kimera实时重建的语义SLAM系统
易扩展的SLAM框架-OpenVSLAM
基于鱼眼相机的SLAM方法介绍
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-10-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号