GPT4做数据分析时间序列预测之四相当棒2023.5.25

GPT4做数据分析时间序列预测之四相当棒2023.5.25

用户7138673
发布于 2023-08-16 21:07:22
发布于 2023-08-16 21:07:22
1、把6个时间序列预测的方法的python代码合并。
程序设置为数据读取、数据预测、数据保存3个步骤。
不同的数据预测方法保存在同一个excel的不同列。
2、
下面的代码将三种不同的预测方法合并到一个程序中,并将预测结果保存到同一个Excel文件的不同列中。在这个代码中,我们首先读取数据,然后对数据进行预测,最后将预测结果保存到一个Excel文件中。我们在一个循环中进行预测,每次迭代都会对不同的时间窗口进行预测。我们将使用pandas的ExcelWriter对象来将所有的预测结果保存到同一个Excel文件中。
```python
import pandas as pd
from statsmodels.tsa.holtwinters import ExponentialSmoothing
from statsmodels.tsa.api import ExponentialSmoothing as ES
# 读取Excel文件
df = pd.read_excel('销售数据.xlsx')
# 将年月列转换为时间格式,并设为索引
df['年月'] = pd.to_datetime(df['年月'])
df.set_index('年月', inplace=True)
# 创建一个空的DataFrame来保存所有的预测结果
df_all_forecasts = pd.DataFrame()
for i in range(48, 60):
rows_to_read = i
df_subset = df[:rows_to_read]
# ExponentialSmoothing预测
model1 = ExponentialSmoothing(df_subset['销售金额'], trend='add', seasonal='add', seasonal_periods=12)
model1_fit = model1.fit()
forecast1 = model1_fit.predict(start=len(df_subset), end=len(df_subset)+11)
# 移动平均预测
df_subset['移动平均'] = df_subset['销售金额'].rolling(window=36).mean()
forecast2 = [df_subset['移动平均'].iloc[-1]] * 12 # 使用最后一个移动平均值作为所有未来月份的预测值
# ExponentialSmoothing预测(使用另一种方法)
model3 = ES(df_subset['销售金额'], trend='add', seasonal='add', seasonal_periods=12)
model3_fit = model3.fit()
forecast3 = model3_fit.forecast(steps=12)
# 创建一个新的DataFrame来保存预测结果
df_forecast = pd.DataFrame({
'年月': pd.date_range(start=df_subset.index[-1] + pd.DateOffset(months=1), periods=12, freq='MS'),
'ExponentialSmoothing预测销售金额': forecast1.values,
'移动平均预测销售金额': forecast2,
'ExponentialSmoothing(方法2)预测销售金额': forecast3
})
# 将预测结果追加到df_all_forecasts中
df_all_forecasts = df_all_forecasts.append(df_forecast)
# 创建一个ExcelWriter对象
writer = pd.ExcelWriter('预测销售数据.xlsx')
# 将df_all_forecasts写入Excel文件
df_all_forecasts.to_excel(writer, index=False)
# 保存Excel文件
writer.save()
```
在这个代码中,我们首先初始化了三个不同的模型,然后使用每个模型进行预测,最后将预测结果保存到一个新的DataFrame中。每次迭代都会对一个不同的时间窗口进行预测,并将预3、
根据您的需求,以下是将这三种预测方法(SARIMAX、Prophet、ARIMA)合并到一个程序中,并将预测结果保存到Excel文件的不同列中的代码。
请注意,预测方法的参数可能需要根据您的实际数据进行调整。此外,这里的代码仅适用于包含年月和销售金额两列的Excel文件。
```python
import pandas as pd
from statsmodels.tsa.statespace.sarimax import SARIMAX
from prophet import Prophet
from pmdarima import auto_arima
# 读取Excel文件
df = pd.read_excel('销售数据.xlsx')
# 将年月列转换为时间格式
df['年月'] = pd.to_datetime(df['年月'])
# 将年月列设置为索引
df.set_index('年月', inplace=True)
# 初始化SARIMA模型
model_sarima = SARIMAX(df['销售金额'], order=(1, 1, 1), seasonal_order=(1, 1, 1, 12))
# 训练模型
model_sarima_fit = model_sarima.fit(disp=False)
# 预测未来12个月的销售金额
forecast_sarima = model_sarima_fit.predict(start=len(df), end=len(df)+11)
# Prophet
df_prophet = df.reset_index().rename(columns={'年月': 'ds', '销售金额': 'y'})
# 初始化Prophet模型
model_prophet = Prophet()
# 训练模型
model_prophet.fit(df_prophet)
# 创建未来12个月的日期框架
future = model_prophet.make_future_dataframe(periods=12, freq='MS')
# 进行预测
forecast_prophet = model_prophet.predict(future)
df_forecast_prophet = forecast_prophet[['ds', 'yhat']][-12:]
# ARIMA
model_arima = auto_arima(df['销售金额'], seasonal=True, m=12)
# 使用选择的模型进行预测
forecast_arima = model_arima.predict(n_periods=12)
# 创建一个新的DataFrame来保存预测结果
df_forecast = pd.DataFrame({
'年月': pd.date_range(start=df.index[-1] + pd.DateOffset(months=1), periods=12, freq='MS'),
'SARIMA预测销售金额': forecast_sarima.values,
'Prophet预测销售金额': df_forecast_prophet['yhat'].values,
'ARIMA预测销售金额': forecast_arima
})
# 将预测结果保存到新的Excel文件中
df_forecast.to_excel('预测销售数据.xlsx', index=False)
```
此脚本会生成一个包含三列预测销售金额的Excel文件。这些列分别对应于SARIMA、Prophet和ARIMA模型的预测结果。4、
您给出的代码中包含了六种不同的时间序列预测方法,分别是:
- SARIMAX
- Prophet
- ARIMA
- ExponentialSmoothing
- 移动平均
- ExponentialSmoothing(另一种方法)
根据您的需求,我将这些方法的代码合并,并将预测结果保存到Excel文件的不同列中。请注意,预测方法的参数可能需要根据您的实际数据进行调整。此外,这里的代码仅适用于包含年月和销售金额两列的Excel文件。
import pandas as pd
from statsmodels.tsa.statespace.sarimax import SARIMAX
from prophet import Prophet
from pmdarima import auto_arima
from statsmodels.tsa.holtwinters import ExponentialSmoothing as ES1
from statsmodels.tsa.api import ExponentialSmoothing as ES2
# 读取Excel文件
df = pd.read_excel('销售数据.xlsx')
# 将年月列转换为时间格式
df['年月'] = pd.to_datetime(df['年月'])
# 将年月列设置为索引
df.set_index('年月', inplace=True)
# 初始化SARIMA模型
model_sarima = SARIMAX(df['销售金额'], order=(1, 1, 1), seasonal_order=(1, 1, 1, 12))
# 训练模型
model_sarima_fit = model_sarima.fit(disp=False)
# 预测未来12个月的销售金额
forecast_sarima = model_sarima_fit.predict(start=len(df), end=len(df)+11)
# Prophet
df_prophet = df.reset_index().rename(columns={'年月': 'ds', '销售金额': 'y'})
# 初始化Prophet模型
model_prophet = Prophet()
# 训练模型
model_prophet.fit(df_prophet)
# 创建未来12个月的日期框架
future = model_prophet.make_future_dataframe(periods=12, freq='MS')
# 进行预测
forecast_prophet = model_prophet.predict(future)
df_forecast_prophet = forecast_prophet[['ds', 'yhat']][-12:]
# ARIMA
model_arima = auto_arima(df['销售金额'], seasonal=True, m=12)
# 使用选择的模型进行预测
forecast_arima = model_arima.predict(n_periods=12)
# ExponentialSmoothing预测方法1
model_es1 = ES1(df['销售金额'], trend='add', seasonal='add', seasonal_periods=12)
model_es1_fit = model_es1.fit()
forecast_es1 = model_es1_fit.predict(start=len(df), end=len(df)+11)
# ExponentialSmoothing预测方法2
model_es2 = ES2(df['销售金额'], trend='add', seasonal='add', seasonal_periods=12)
model_es2_fit = model_es2.fit()
forecast_es2 = model_es2_fit.forecast(steps=12)
# 移动平均预测
df['移动平均'] = df['销售金额'].rolling(window=36).mean()
forecast_ma = [df['移动平均'].iloc[-1]] * 12 # 使用最后一个移动平均值作为所有未来月份的预测值
# 创建一个新的DataFrame来保存预测结果
df_forecast = pd.DataFrame({
'年月': pd.date_range(start=df.index[-1] + pd.DateOffset(months=1), periods=12, freq='MS'),
'SARIMA预测销售金额': forecast_sarima.values,
'Prophet预测销售金额': df_forecast_prophet['yhat'].values,
'ARIMA预测销售金额': forecast_arima,
'ExponentialSmoothing方法1预测销售金额': forecast_es1.values,
'ExponentialSmoothing方法2预测销售金额': forecast_es2,
'移动平均预测销售金额': forecast_ma
})
# 将预测结果保存到新的Excel文件中
df_forecast.to_excel('预测销售数据.xlsx', index=False)
5、把全部变量改为中文变量
import pandas as pd
from statsmodels.tsa.statespace.sarimax import SARIMAX
from prophet import Prophet
from pmdarima import auto_arima
from statsmodels.tsa.holtwinters import ExponentialSmoothing as ES1
from statsmodels.tsa.api import ExponentialSmoothing as ES2
# 读取Excel文件
数据 = pd.read_excel('销售数据.xlsx')
# 将年月列转换为时间格式
数据['年月'] = pd.to_datetime(数据['年月'])
# 将年月列设置为索引
数据.set_index('年月', inplace=True)
# 初始化SARIMA模型
模型_sarima = SARIMAX(数据['销售金额'], order=(1, 1, 1), seasonal_order=(1, 1, 1, 12))
# 训练模型
模型_sarima_fit = 模型_sarima.fit(disp=False)
# 预测未来12个月的销售金额
预测_sarima = 模型_sarima_fit.predict(start=len(数据), end=len(数据)+11)
# Prophet
数据_prophet = 数据.reset_index().rename(columns={'年月': 'ds', '销售金额': 'y'})
# 初始化Prophet模型
模型_prophet = Prophet()
# 训练模型
模型_prophet.fit(数据_prophet)
# 创建未来12个月的日期框架
未来 = 模型_prophet.make_future_dataframe(periods=12, freq='MS')
# 进行预测
预测_prophet = 模型_prophet.predict(未来)
预测数据_prophet = 预测_prophet[['ds', 'yhat']][-12:]
# ARIMA
模型_arima = auto_arima(数据['销售金额'], seasonal=True, m=12)
# 使用选择的模型进行预测
预测_arima = 模型_arima.predict(n_periods=12)
# ExponentialSmoothing预测方法1
模型_es1 = ES1(数据['销售金额'], trend='add', seasonal='add', seasonal_periods=12)
模型_es1_fit = 模型_es1.fit()
预测_es1 = 模型_es1_fit.predict(start=len(数据), end=len(数据)+11)
# ExponentialSmoothing预测方法2
模型_es2 = ES2(数据['销售金额'], trend='add', seasonal='add', seasonal_periods=12)
模型_es2_fit = 模型_es2.fit()
预测_es2 = 模型_es2_fit.forecast(steps=12)
# 移动平均预测
数据['移动平均'] = 数据['销售金额'].rolling(window=36).mean()
预测_移动平均 = [数据['移动平均'].iloc[-1]] * 12 # 使用最后一个移动平均值作为所有未来月份的预测值
# 创建一个新的DataFrame来保存预测结果
预测数据 = pd.DataFrame({
'年月': pd.date_range(start=数据.index[-1] + pd.DateOffset(months=1), periods=12, freq='MS'),
'SARIMA预测销售金额': 预测_sarima.values,
'Prophet预测销售金额': 预测数据_prophet['yhat'].values,
'ARIMA预测销售金额': 预测_arima,
'ExponentialSmoothing方法1预测销售金额': 预测_es1.values,
'ExponentialSmoothing方法2预测销售金额': 预测_es2,
'移动平均预测销售金额': 预测_移动平均
})
# 将预测结果保存到新的Excel文件中
预测数据.to_excel('预测销售数据.xlsx', index=False)
6、修改代码,一次只预测未来一个月的预测值。
使用
# 创建一个空的DataFrame来保存所有的预测结果
df_all_forecasts = pd.DataFrame()
for i in range(48, 60):
rows_to_read = i
df_subset = df[:rows_to_read]
等方法,循环遍历多个年月数据预测
import pandas as pd
from statsmodels.tsa.statespace.sarimax import SARIMAX
from prophet import Prophet
from pmdarima import auto_arima
from statsmodels.tsa.holtwinters import ExponentialSmoothing as ES1
from statsmodels.tsa.api import ExponentialSmoothing as ES2
# 读取Excel文件
数据 = pd.read_excel('销售数据.xlsx')
# 将年月列转换为时间格式
数据['年月'] = pd.to_datetime(数据['年月'])
# 将年月列设置为索引
数据.set_index('年月', inplace=True)
# 创建一个空的DataFrame来保存所有的预测结果
所有预测 = pd.DataFrame()
for i in range(48, len(数据)):
# 创建一个数据子集,包含到当前迭代的所有行
数据子集 = 数据[:i+1]
# 初始化SARIMA模型
模型_sarima = SARIMAX(数据子集['销售金额'], order=(1, 1, 1), seasonal_order=(1, 1, 1, 12))
# 训练模型
模型_sarima_fit = 模型_sarima.fit(disp=False)
# 预测下个月的销售金额
预测_sarima = 模型_sarima_fit.predict(start=len(数据子集), end=len(数据子集))
# Prophet
数据_prophet = 数据子集.reset_index().rename(columns={'年月': 'ds', '销售金额': 'y'})
# 初始化Prophet模型
模型_prophet = Prophet()
# 训练模型
模型_prophet.fit(数据_prophet)
# 创建未来1个月的日期框架
未来 = 模型_prophet.make_future_dataframe(periods=1, freq='MS')
# 进行预测
预测_prophet = 模型_prophet.predict(未来)
预测数据_prophet = 预测_prophet[['ds', 'yhat']].iloc[-1]
# ARIMA
模型_arima = auto_arima(数据子集['销售金额'], seasonal=True, m=12)
# 使用选择的模型进行预测
预测_arima = 模型_arima.predict(n_periods=1)
# ExponentialSmoothing预测方法1
模型_es1 = ES1(数据子集['销售金额'], trend='add', seasonal='add', seasonal_periods=12)
模型_es1_fit = 模型_es1.fit()
预测_es1 = 模型_es1_fit.predict(start=len(数据子集), end=len(数据子集))
# ExponentialSmoothing预测方法2
模型_es2 = ES2(数据子集['销售金额'], trend='add', seasonal='add', seasonal_periods=12)
模型_es2_fit = 模型_es2.fit()
预测_es2 = 模型_es2_fit.forecast(steps=1)
# 移动平均预测
数据子集['移动平均'] = 数据子集['销售金额'].rolling(window=36).mean()
预测_移动平均 = [数据子集['移动平均'].iloc[-1]] # 使用最后一个移动平均值作为预测值
# 创建一个新的DataFrame来保存预测结果
预测数据 = pd.DataFrame({
'年月': [数据子集.index[-1] + pd.DateOffset(months=1)],
'SARIMA预测销售金额': 预测_sarima.values,
'Prophet预测销售金额': [预测数据_prophet['yhat']],
'ARIMA预测销售金额': 预测_arima,
'ExponentialSmoothing方法1预测销售金额': 预测_es1.values,
'ExponentialSmoothing方法2预测销售金额': 预测_es2,
'移动平均预测销售金额': 预测_移动平均
})
# 将预测结果追加到所有预测中
所有预测 = 所有预测.append(预测数据)
# 将预测结果保存到新的Excel文件中
所有预测.to_excel('预测销售数据.xlsx', index=False)
7、增加一个python程序功能:将上面的预测得到的结果,绘制为散点图
import matplotlib.pyplot as plt
# 将日期设置为索引
所有预测.set_index('年月', inplace=True)
plt.figure(figsize=(12, 6))
# 绘制SARIMA预测结果
plt.scatter(所有预测.index, 所有预测['SARIMA预测销售金额'], label='SARIMA预测销售金额', color='red')
# 绘制Prophet预测结果
plt.scatter(所有预测.index, 所有预测['Prophet预测销售金额'], label='Prophet预测销售金额', color='green')
# 绘制ARIMA预测结果
plt.scatter(所有预测.index, 所有预测['ARIMA预测销售金额'], label='ARIMA预测销售金额', color='blue')
# 绘制ExponentialSmoothing方法1预测结果
plt.scatter(所有预测.index, 所有预测['ExponentialSmoothing方法1预测销售金额'], label='ExponentialSmoothing方法1预测销售金额', color='yellow')
# 绘制ExponentialSmoothing方法2预测结果
plt.scatter(所有预测.index, 所有预测['ExponentialSmoothing方法2预测销售金额'], label='ExponentialSmoothing方法2预测销售金额', color='purple')
# 绘制移动平均预测结果
plt.scatter(所有预测.index, 所有预测['移动平均预测销售金额'], label='移动平均预测销售金额', color='orange')
# 添加图例
plt.legend()
# 显示图形
plt.show()
8、
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# import matplotlib.pyplot as plt
# 指定字体为微软雅黑,用于正确显示中文
myfont = FontProperties(fname='C:/Users/Administrator/Desktop/GPT4预测2023.5.24/msyh.ttc')
# 生成假数据
data = pd.DataFrame({
'方法1': [1, 3, 2, 5, 4],
'方法2': [2, 3, 1, 2, 6],
'方法3': [3, 4, 2, 1, 5]
})
# 设置图像大小
plt.figure(figsize=(12, 6))
# 绘制方法1的数据
plt.scatter(data.index, data['方法1'], label='方法1', color='red')
# 绘制方法2的数据
plt.scatter(data.index, data['方法2'], label='方法2', color='green')
# 绘制方法3的数据
plt.scatter(data.index, data['方法3'], label='方法3', color='blue')
# # 添加图例
# plt.legend()
# 添加图例
plt.legend(prop=myfont)
# 显示图像
# plt.show() #plt.show() 和 plt.savefig() 同时使用。这两个函数不能同时使用,应该只选用一个。plt.show() 会显示图像窗口,如果同时使用 plt.savefig() 保存图像,该图像窗口会被保存,导致保存的图像为空白。
# 保存图像
plt.savefig('scatter_plot.png')
9、牛B
# -*- coding: utf-8 -*-
"""
Created on Thu May 25 17:23:53 2023
@author: Administrator
"""
import pandas as pd
from statsmodels.tsa.statespace.sarimax import SARIMAX
from prophet import Prophet
from pmdarima import auto_arima
from statsmodels.tsa.holtwinters import ExponentialSmoothing as ES1
from statsmodels.tsa.api import ExponentialSmoothing as ES2
# 读取Excel文件
数据 = pd.read_excel('销售数据.xlsx')
# 将年月列转换为时间格式
数据['年月'] = pd.to_datetime(数据['年月'])
# 将年月列设置为索引
数据.set_index('年月', inplace=True)
# 创建一个空的DataFrame来保存所有的预测结果
所有预测 = pd.DataFrame()
for i in range(48, len(数据)):
# 创建一个数据子集,包含到当前迭代的所有行
数据子集 = 数据[:i+1]
# 初始化SARIMA模型
模型_sarima = SARIMAX(数据子集['销售金额'], order=(1, 1, 1), seasonal_order=(1, 1, 1, 12))
# 训练模型
模型_sarima_fit = 模型_sarima.fit(disp=False)
# 预测下个月的销售金额
预测_sarima = 模型_sarima_fit.predict(start=len(数据子集), end=len(数据子集))
# Prophet
数据_prophet = 数据子集.reset_index().rename(columns={'年月': 'ds', '销售金额': 'y'})
# 初始化Prophet模型
模型_prophet = Prophet()
# 训练模型
模型_prophet.fit(数据_prophet)
# 创建未来1个月的日期框架
未来 = 模型_prophet.make_future_dataframe(periods=1, freq='MS')
# 进行预测
预测_prophet = 模型_prophet.predict(未来)
预测数据_prophet = 预测_prophet[['ds', 'yhat']].iloc[-1]
# ARIMA
模型_arima = auto_arima(数据子集['销售金额'], seasonal=True, m=12)
# 使用选择的模型进行预测
预测_arima = 模型_arima.predict(n_periods=1)
# ExponentialSmoothing预测方法1
模型_es1 = ES1(数据子集['销售金额'], trend='add', seasonal='add', seasonal_periods=12)
模型_es1_fit = 模型_es1.fit()
预测_es1 = 模型_es1_fit.predict(start=len(数据子集), end=len(数据子集))
# ExponentialSmoothing预测方法2
模型_es2 = ES2(数据子集['销售金额'], trend='add', seasonal='add', seasonal_periods=12)
模型_es2_fit = 模型_es2.fit()
预测_es2 = 模型_es2_fit.forecast(steps=1)
# 移动平均预测
数据子集['移动平均'] = 数据子集['销售金额'].rolling(window=36).mean()
预测_移动平均 = [数据子集['移动平均'].iloc[-1]] # 使用最后一个移动平均值作为预测值
# 创建一个新的DataFrame来保存预测结果
预测数据 = pd.DataFrame({
'年月': [数据子集.index[-1] + pd.DateOffset(months=1)],
'SARIMA预测销售金额': 预测_sarima.values,
'Prophet预测销售金额': [预测数据_prophet['yhat']],
'ARIMA预测销售金额': 预测_arima,
'ExponentialSmoothing方法1预测销售金额': 预测_es1.values,
'ExponentialSmoothing方法2预测销售金额': 预测_es2,
'移动平均预测销售金额': 预测_移动平均
})
# 将预测结果追加到所有预测中
所有预测 = 所有预测.append(预测数据)
# 将预测结果保存到新的Excel文件中
所有预测.to_excel('预测销售数据.xlsx', index=False)
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
# 指定字体为微软雅黑,用于正确显示中文
myfont = FontProperties(fname='C:/Users/Administrator/Desktop/GPT4预测2023.5.24/msyh.ttc')
plt.figure(figsize=(12, 6))
# 绘制SARIMA预测结果,注意label参数要使用fontproperties设置字体
plt.scatter(所有预测.index, 所有预测['SARIMA预测销售金额'], label='SARIMA预测销售金额', color='red')
# 绘制Prophet预测结果
plt.scatter(所有预测.index, 所有预测['Prophet预测销售金额'], label='Prophet预测销售金额', color='green')
# 绘制ARIMA预测结果
plt.scatter(所有预测.index, 所有预测['ARIMA预测销售金额'], label='ARIMA预测销售金额', color='blue')
# 绘制ExponentialSmoothing方法1预测结果
plt.scatter(所有预测.index, 所有预测['ExponentialSmoothing方法1预测销售金额'], label='ExponentialSmoothing方法1预测销售金额', color='yellow')
# 绘制ExponentialSmoothing方法2预测结果
plt.scatter(所有预测.index, 所有预测['ExponentialSmoothing方法2预测销售金额'], label='ExponentialSmoothing方法2预测销售金额', color='purple')
# 绘制移动平均预测结果
plt.scatter(所有预测.index, 所有预测['移动平均预测销售金额'], label='移动平均预测销售金额', color='orange')
# 添加图例
plt.legend(prop=myfont)
# 显示图像
# plt.show() #plt.show() 和 plt.savefig() 同时使用。这两个函数不能同时使用,应该只选用一个。plt.show() 会显示图像窗口,如果同时使用 plt.savefig() 保存图像,该图像窗口会被保存,导致保存的图像为空白。
# 保存图像
plt.savefig('scatter_plot.png')
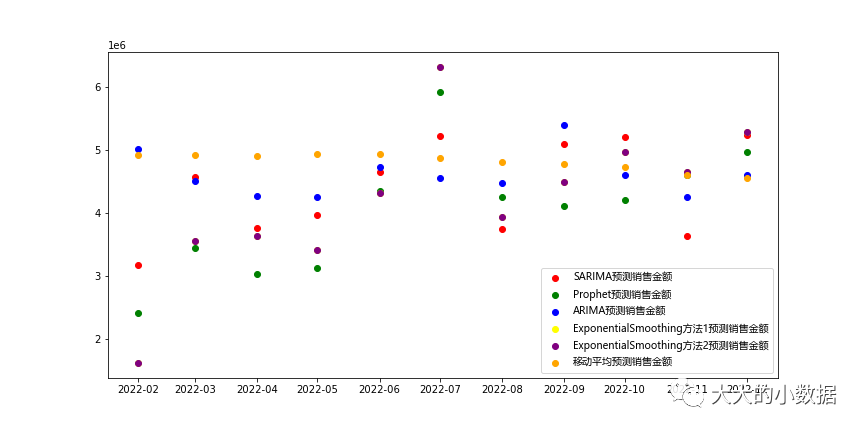
10、改为折线图
11、动态图片
Python有很多可以用于绘制动态图片的库,其中一些常用的库包括:
Matplotlib:Matplotlib 是 Python 的一个绘图库,它可以用于绘制静态和动态的图形,例如折线图、散点图、柱状图、饼图等。
Plotly:Plotly 是一个交互式可视化工具,通过它你可以创建精美的数据可视化应用,包括动态图形。
Seaborn:Seaborn 继承了 Matplotlib 的优点,它提供了更多的可视化选项和更好的默认样式。
Bokeh:Bokeh 是一个 Python 交互式可视化库,它能够在网页浏览器中绘制丰富多彩的图表。
这些库都可以通过 Python 的命令行或者在 Jupyter Notebook 中使用,在进行动态图片绘制时,你需要了解其中一些基础的动态图示的原理,例如使用动画、更新数据和实时数据接收等技术。1. Matplotlib - 静态图形绘制库,可以生成各种图表,但没有交互性。
2. Plotly - 交互式绘图库,可以在线生成各种动态图表,包括散点图,折线图,柱状图,箱线图等。并支持离线导出静态图像。
3. Bokeh - 用于在web浏览器中进行交互式数据可视化的库。可以生成各种图表,并在网页中展示,交互性很强。
4. Pygal - 可以生成各种图表,支持 SVG 和 PNG 格式,比较适合生成静态的图表。
5. Seaborn - 基于 Matplotlib 的绘图库,样式更美观,更适合统计绘图。与Matplotlib同为静态图表。
6. Plotnine - 与R语言的ggplot2类似,基于Grammar of Graphics理念,也适用于静态图表绘制。
7. Altair - 基于Vega和Vega-Lite,可以通过简明的语法进行交互式数据可视化,输出为Vega/Vega-Lite的json文件或直出html。
8. hvPlot - 基于HoloViews和Plotly,提供简洁打印式API,可以求各种动态/交互图表。
9. 等等
这些库各有特点,主要可以分为:
静态图库:Matplotlib, Seaborn, Plotnine, Pygal等 - 适用于生成图片
动态图库:Plotly, Bokeh, Altair, hvPlot等 - 适用于交互式数据可视化和在线展示
如果要生成静态图片,Matplotlib是最常用的选择。如果要网页中展示动态图表,Bokeh和Altair都很好。而Plotly既可以生成静态图片,也可以在线交互展示,所以功能最为强大全面。12、
# -*- coding: utf-8 -*-
"""
Created on Thu May 25 17:23:53 2023
@author: Administrator
"""
import pandas as pd
from statsmodels.tsa.statespace.sarimax import SARIMAX
from prophet import Prophet
from pmdarima import auto_arima
from statsmodels.tsa.holtwinters import ExponentialSmoothing as ES1
from statsmodels.tsa.api import ExponentialSmoothing as ES2
# 读取Excel文件
数据 = pd.read_excel('销售数据.xlsx')
# 将年月列转换为时间格式
数据['年月'] = pd.to_datetime(数据['年月'])
# 将年月列设置为索引
数据.set_index('年月', inplace=True)
# 创建一个空的DataFrame来保存所有的预测结果
所有预测 = pd.DataFrame()
for i in range(48, len(数据)):
# 创建一个数据子集,包含到当前迭代的所有行
数据子集 = 数据[:i+1]
# 初始化SARIMA模型
模型_sarima = SARIMAX(数据子集['销售金额'], order=(1, 1, 1), seasonal_order=(1, 1, 1, 12))
# 训练模型
模型_sarima_fit = 模型_sarima.fit(disp=False)
# 预测下个月的销售金额
预测_sarima = 模型_sarima_fit.predict(start=len(数据子集), end=len(数据子集))
# Prophet
数据_prophet = 数据子集.reset_index().rename(columns={'年月': 'ds', '销售金额': 'y'})
# 初始化Prophet模型
模型_prophet = Prophet()
# 训练模型
模型_prophet.fit(数据_prophet)
# 创建未来1个月的日期框架
未来 = 模型_prophet.make_future_dataframe(periods=1, freq='MS')
# 进行预测
预测_prophet = 模型_prophet.predict(未来)
预测数据_prophet = 预测_prophet[['ds', 'yhat']].iloc[-1]
# ARIMA
模型_arima = auto_arima(数据子集['销售金额'], seasonal=True, m=12)
# 使用选择的模型进行预测
预测_arima = 模型_arima.predict(n_periods=1)
# ExponentialSmoothing预测方法1
模型_es1 = ES1(数据子集['销售金额'], trend='add', seasonal='add', seasonal_periods=12)
模型_es1_fit = 模型_es1.fit()
预测_es1 = 模型_es1_fit.predict(start=len(数据子集), end=len(数据子集))
# ExponentialSmoothing预测方法2
模型_es2 = ES2(数据子集['销售金额'], trend='add', seasonal='add', seasonal_periods=12)
模型_es2_fit = 模型_es2.fit()
预测_es2 = 模型_es2_fit.forecast(steps=1)
# 移动平均预测
数据子集['移动平均'] = 数据子集['销售金额'].rolling(window=36).mean()
预测_移动平均 = [数据子集['移动平均'].iloc[-1]] # 使用最后一个移动平均值作为预测值
# 创建一个新的DataFrame来保存预测结果
预测数据 = pd.DataFrame({
'年月': [数据子集.index[-1] + pd.DateOffset(months=1)],
'SARIMA预测销售金额': 预测_sarima.values,
'Prophet预测销售金额': [预测数据_prophet['yhat']],
'ARIMA预测销售金额': 预测_arima,
'ExponentialSmoothing方法1预测销售金额': 预测_es1.values,
'ExponentialSmoothing方法2预测销售金额': 预测_es2,
'移动平均预测销售金额': 预测_移动平均
})
# 将预测结果追加到所有预测中
所有预测 = 所有预测.append(预测数据)
# 将预测结果保存到新的Excel文件中
所有预测.to_excel('预测销售数据.xlsx', index=False)
'''
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
# 指定字体为微软雅黑,用于正确显示中文
myfont = FontProperties(fname='C:/Users/Administrator/Desktop/GPT4预测2023.5.24/msyh.ttc')
plt.figure(figsize=(12, 6))
# 绘制SARIMA预测结果,注意label参数要使用fontproperties设置字体
plt.scatter(所有预测.index, 所有预测['SARIMA预测销售金额'], label='SARIMA预测销售金额', color='red')
# 绘制Prophet预测结果
plt.scatter(所有预测.index, 所有预测['Prophet预测销售金额'], label='Prophet预测销售金额', color='green')
# 绘制ARIMA预测结果
plt.scatter(所有预测.index, 所有预测['ARIMA预测销售金额'], label='ARIMA预测销售金额', color='blue')
# 绘制ExponentialSmoothing方法1预测结果
plt.scatter(所有预测.index, 所有预测['ExponentialSmoothing方法1预测销售金额'], label='ExponentialSmoothing方法1预测销售金额', color='yellow')
# 绘制ExponentialSmoothing方法2预测结果
plt.scatter(所有预测.index, 所有预测['ExponentialSmoothing方法2预测销售金额'], label='ExponentialSmoothing方法2预测销售金额', color='purple')
# 绘制移动平均预测结果
plt.scatter(所有预测.index, 所有预测['移动平均预测销售金额'], label='移动平均预测销售金额', color='orange')
# 添加图例
plt.legend(prop=myfont)
# 显示图像
# plt.show() #plt.show() 和 plt.savefig() 同时使用。这两个函数不能同时使用,应该只选用一个。plt.show() 会显示图像窗口,如果同时使用 plt.savefig() 保存图像,该图像窗口会被保存,导致保存的图像为空白。
# 保存图像
plt.savefig('scatter_plot.png')
'''
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
# 指定字体为微软雅黑,用于正确显示中文
myfont = FontProperties(fname='C:/Users/Administrator/Desktop/GPT4预测2023.5.24/msyh.ttc')
plt.figure(figsize=(120, 60))
# 绘制SARIMA预测结果,注意label参数要使用fontproperties设置字体
plt.plot(所有预测.index, 所有预测['SARIMA预测销售金额'], label='SARIMA预测销售金额', color='red')
# 绘制Prophet预测结果
plt.plot(所有预测.index, 所有预测['Prophet预测销售金额'], label='Prophet预测销售金额', color='green')
# 绘制ARIMA预测结果
plt.plot(所有预测.index, 所有预测['ARIMA预测销售金额'], label='ARIMA预测销售金额', color='blue')
# 绘制ExponentialSmoothing方法1预测结果
plt.plot(所有预测.index, 所有预测['ExponentialSmoothing方法1预测销售金额'], label='ExponentialSmoothing方法1预测销售金额', color='yellow')
# 绘制ExponentialSmoothing方法2预测结果
plt.plot(所有预测.index, 所有预测['ExponentialSmoothing方法2预测销售金额'], label='ExponentialSmoothing方法2预测销售金额', color='purple')
# 绘制移动平均预测结果
plt.plot(所有预测.index, 所有预测['移动平均预测销售金额'], label='移动平均预测销售金额', color='orange')
# 添加图例
plt.legend(prop=myfont)
# 显示图像
# plt.show()
# 保存图像
plt.savefig('line_plot.png')
import plotly.graph_objects as go
# import plotly.graph_objects as go
import plotly.subplots
import plotly.io as pio
# 创建一个Figure对象
fig = go.Figure()
# 添加SARIMA预测结果到图形中
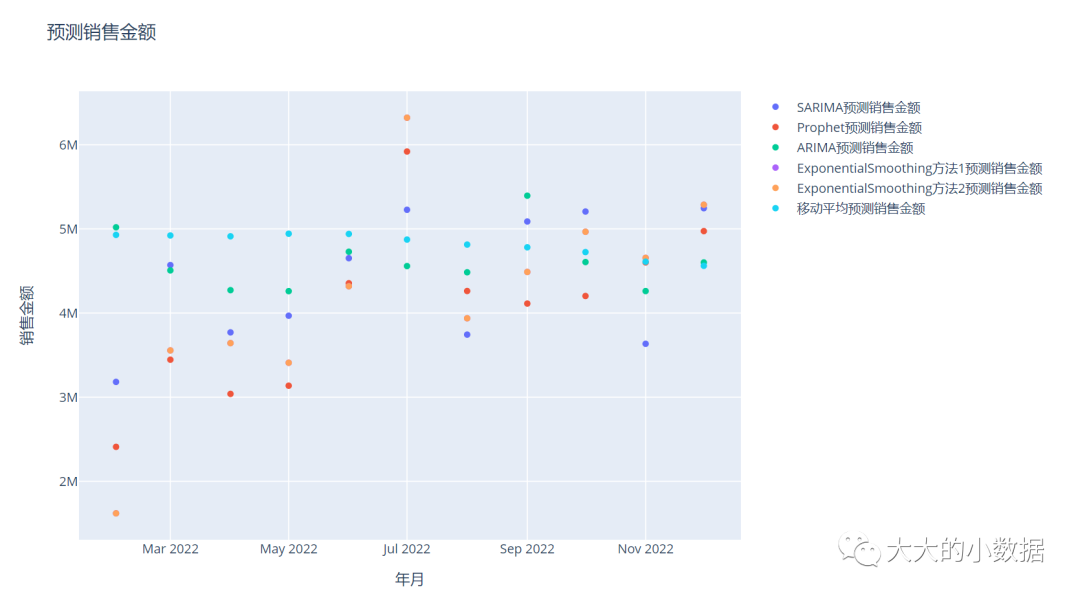
fig.add_trace(go.Scatter(x=所有预测.index, y=所有预测['SARIMA预测销售金额'], mode='markers', name='SARIMA预测销售金额'))
# 添加Prophet预测结果到图形中
fig.add_trace(go.Scatter(x=所有预测.index, y=所有预测['Prophet预测销售金额'], mode='markers', name='Prophet预测销售金额'))
# 添加ARIMA预测结果到图形中
fig.add_trace(go.Scatter(x=所有预测.index, y=所有预测['ARIMA预测销售金额'], mode='markers', name='ARIMA预测销售金额'))
# 添加ExponentialSmoothing方法1预测结果到图形中
fig.add_trace(go.Scatter(x=所有预测.index, y=所有预测['ExponentialSmoothing方法1预测销售金额'], mode='markers', name='ExponentialSmoothing方法1预测销售金额'))
# 添加ExponentialSmoothing方法2预测结果到图形中
fig.add_trace(go.Scatter(x=所有预测.index, y=所有预测['ExponentialSmoothing方法2预测销售金额'], mode='markers', name='ExponentialSmoothing方法2预测销售金额'))
# 添加移动平均预测结果到图形中
fig.add_trace(go.Scatter(x=所有预测.index, y=所有预测['移动平均预测销售金额'], mode='markers', name='移动平均预测销售金额'))
# 设置图形标题和轴标签
fig.update_layout(title='预测销售金额', xaxis_title='年月', yaxis_title='销售金额')
# # 显示图形
# fig.show()
# 保存为svg文件
fig.write_image("预测销售金额.svg", width=1000, height=600)
# fig.write_image(fig, '预测销售金额.jpg', engine='jpeg')
# pio.write_image(fig, '预测销售金额.jpg', width=1000, height=600)
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-05-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号