
在bigquery中使用DBSCAN进行聚类
我有一个Bigquery表,其中只有一个名为'point‘的列。它包含我希望使用ST_CLUSTERDBSCAN函数在BigQuery中进行聚类的位置坐标。
我使用以下查询:
SELECT ST_CLUSTERDBSCAN(point, 2000, 200) OVER () AS cluster_num
FROM mytable我知道这个错误:
查询执行期间超出的资源:无法在分配的内存中执行查询。峰值使用:上限的128%。顶级内存使用者:分析OVER()子句: 97%其他/未归因: 3%
据我所知,这是因为查询内存密集型。考虑到我的表包含数百万行,我是否可以使用集群数据?

回答 2
Stack Overflow用户
发布于 2021-08-16 22:58:19
BigQuery中的大多数解析函数目前在单个碎片(机器)上运行一个分区,因此分区大小在内存中限制为1GB左右的数据大小。在您的查询中,OVER ()意味着没有分区-所有数据都在一个分区中运行。
解决方案通常是在某个大粒度上对数据进行分区。例如,如果数据具有某种空间层次结构,则可以按该列进行分区--例如,执行OVER(PARTITION BY state)。当然,这意味着不存在跨态簇,所以结果并不完全相同,但是如果有自然的聚类,这通常是合理的。
如果这种内部层次结构不可用,另一种选择是使用一个短的地散列(只有很少的字母--为了避免资源超出错误而需要的字母)进行分区,类似于OVER(PARTITION BY st_geohash(point, 2))。一个很好的选择是S2_CellIDFromPoint(ST_Centroid(geo, level)),请参阅S2细胞尺寸来选择单元格级别。
Stack Overflow用户
发布于 2021-12-15 05:48:01
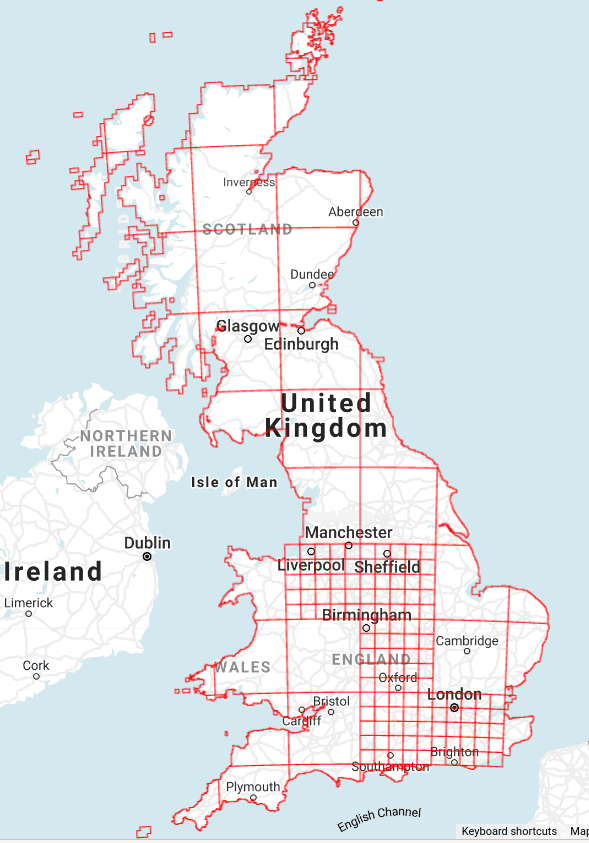
为了补充迈克尔的答案,我发现的一个问题是,S2网格是规则的,不匹配地面上不同的密度。因此,您最终往往会得到比您想要的更小的分区,这仅仅是因为您必须设置适合于最密集区域的S2级别。在英国,有不同规模的现成电网,我创建了一个100公里和20公里的混合电网,见下文。较小的广场覆盖了较大的城市。
另一种选择是使用六角网格,这是Carto通过jslibs.h3向BiqQuery提供的。
还有许多其他选项,比如递归地划分类似KD树结构的空间,直到最大的剩余输入分区被保证适合在一个碎片上。
根据您想要做的事情,还有一个额外的问题,那就是组合集群,这些集群跨越OVER子句中使用的任何细分。对此有一些解决方案,例如使用ST_Union和ST_Intersects以及合并相邻的集群,但这超出了最初的问题。最终,这就是您希望保持分区尽可能大的原因,但如果您想要这样做的话,它将减少重组集群所需的工作量。
https://stackoverflow.com/questions/68811457
复制




![linux ldd命令源代码,Linux中ldd命令的用法详解[通俗易懂]](https://ask.qcloudimg.com/http-save/yehe-8223537/629da835500ca7356f8ea1318f382b90.jpeg)





腾讯云开发者
