从 Hugging Face 模型到 Ollama 模型的转换和量化

从 Hugging Face 模型到 Ollama 模型的转换和量化

用户4176869
发布于 2026-06-22 16:56:33
发布于 2026-06-22 16:56:33
从 Hugging Face 模型到 Ollama 模型的转换和量化
在本地部署大语言模型时,Ollama 凭借简洁的交互体验成为热门选择,但它主要支持 GGUF 格式模型;而 Hugging Face 平台的模型多为 PyTorch(.safetensors/.bin)格式,需经过格式转换才能适配 Ollama。
本文将详细拆解从 Hugging Face 模型获取、格式转换到 Ollama 加载运行的全流程。
一、前期准备:确认工具与文件
在开始转换前,需确保环境和文件齐全,避免后续操作卡顿。
1. 必备工具安装
- Python 3.8+:用于执行模型转换脚本,安装时务必勾选 “Add Python to PATH”,有Anconda的直接用conda环境即可。
- Ollama:本地模型运行工具,已安装可跳过(官网下载:ollama.com,安装后打开命令提示符输入
ollama -v验证是否正常)。 - llama.cpp:核心转换工具,支持将 Hugging Face 模型转为 GGUF 格式,选择Source code下载的文件夹。
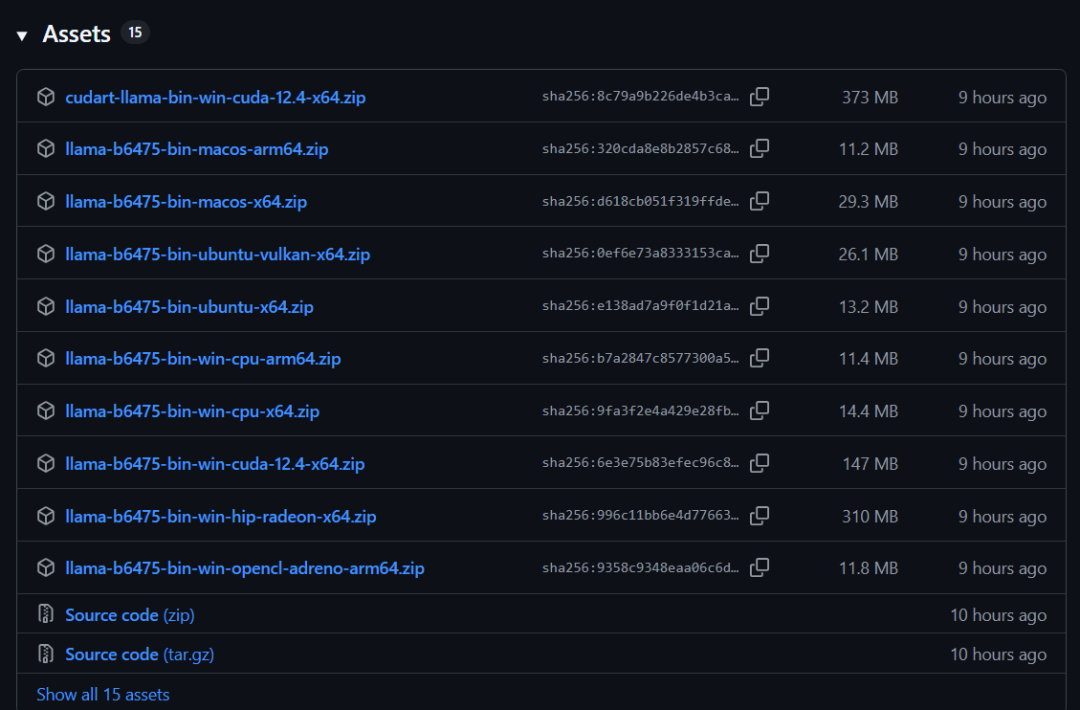
- llama预编译二进制包:负责模型量化、运行(避免手动编译,下载地址:llama.cpp Releases,选 Windows 版本如
llama-cpp-win64.zip;若显卡支持 CUDA,可选带cuda后缀的版本)。
2. 模型文件准备
从 Hugging Face 下载目标模型(以常见的 .safetensors 格式为例),确保文件夹(如 D:\DongPo)包含以下核心文件:
- 模型权重文件:
model-00001-of-00004.safetensors、model.safetensors.index.json; - 分词器文件:
tokenizer.json、tokenizer_config.json; - 模型配置文件:
config.json(部分模型含generation_config.json)。
注意:若模型文件夹含 Git 合并冲突标记(如
<<<<<<< HEAD)的文件(如README.md、model_card.yaml),需先删除冲突标记,否则后续转换会触发 YAML 解析错误。
二、核心步骤
GGUF 是 Ollama 支持的主流格式,转换过程依赖 llama.cpp 的脚本,需严格按步骤执行。
1. 解压并配置 llama.cpp
将下载的 llama-cpp解压到简单路径(如 D:\llama),确保文件夹内有转换脚本(如 convert_hf_to_gguf.py)和量化工具(quantize.exe`);
打开命令提示符(CMD),进入文件夹里
2. 安装转换依赖库
转换脚本需依赖 torch、transformers 等库,在命令提示符中执行安装命令(联网状态下):
pip install torch transformers sentencepiece mistral-common
若提示 “ModuleNotFoundError: No module named 'mistral_common'”,
补充执行 pip install mistral-common -i https://pypi.tuna.tsinghua.edu.cn/simple(国内源加速)。
3. 执行格式转换(生成基础 GGUF 模型)
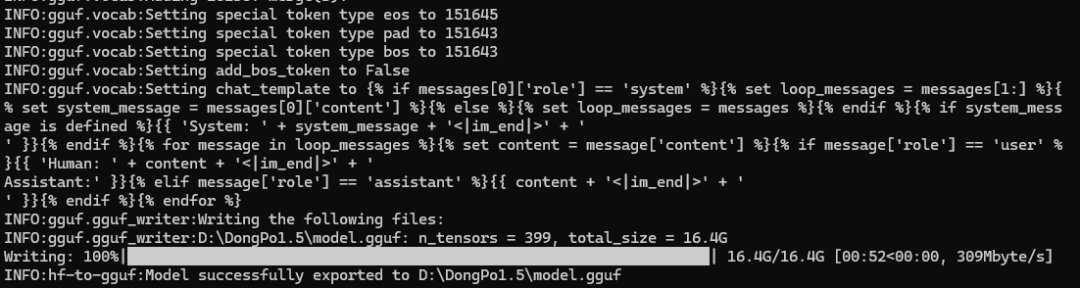
在 llama.cpp 目录下,执行转换命令,将 Hugging Face 模型,这里我以https://huggingface.co/QingYuYunTu/DongPo1.5这个模型为例,是基于Qwen3-8B微调的苏东坡角色扮演大模型,我们下载好模型文件存放在(`D:\DongPo1.5`),现在将其转为 GGUF 格式,输出到模型文件夹(如 D:\DongPo1.5\model.gguf):
python convert_hf_to_gguf.py D:\DongPo1.5 --outfile D:\DongPo1.5\model.gguf
- 转换过程中会显示权重文件处理进度(如
blk.35.ffn_gate.weight, torch.bfloat16 --> F16),耐心等待完成(耗时取决于模型大小,如 7B 模型约 5-10 分钟)。 - 如果出现报错,把模型里的README文档先删除
4. 模型量化:减小体积 + 提升速度
若电脑配置一般(如 8GB 内存),建议对 GGUF 模型进行量化(降低精度,平衡性能与体积),常用 q4_0 格式(兼顾精度和速度): 进入前面下载好的llama-cpp-win64.zip,(不是源码llama cpp)`解压后在目录下执行量化命令:
llama-quantize.exe D:\DongPo1.5\model.gguf D:\DongPo1.5\model-q4_0.gguf q4_0
- 量化后会生成
model-q4_0.gguf(如 7B 模型量化后体积从 13GB 降至 4GB 左右),后续优先使用量化模型加载。
三、关键配置
转换出 GGUF 模型后,需通过 Modelfile 配置 Ollama 加载规则,确保交互格式匹配。
1. 编写 / 修改 Modelfile
在模型文件夹(D:\DongPo1.5)中创建或修改 Modelfile(用记事本打开),核心配置如下:
# 指向量化后的 GGUF 模型(未量化则写 FROM model.gguf)
FROM model-q4_0.gguf
# 定义对话模板(适配模型交互格式,避免输出错乱)
TEMPLATE """{{ if .System }}System: {{ .System }}<|im_end|>
{{ end }}{{ range .Messages }}{{ if eq .Role "user" }}Human: {{ .Content }}<|im_end|>
Assistant:{{ else if eq .Role "assistant" }}{{ .Content }}<|im_end|>
{{ end }}{{ end }}"""
# 设置停止符(与模板中的 <|im_end|> 对应,避免模型无意义输出)
PARAMETER stop "<|im_end|>"
# 配置上下文长度(根据模型支持的最大长度设置,如 4096、8192)
PARAMETER num_ctx 4096
- 模板中的
Human:/Assistant:/<|im_end|>需与模型训练时的格式一致,若模型原格式为User:/Bot:,需对应修改。
2. 构建 Ollama 模型
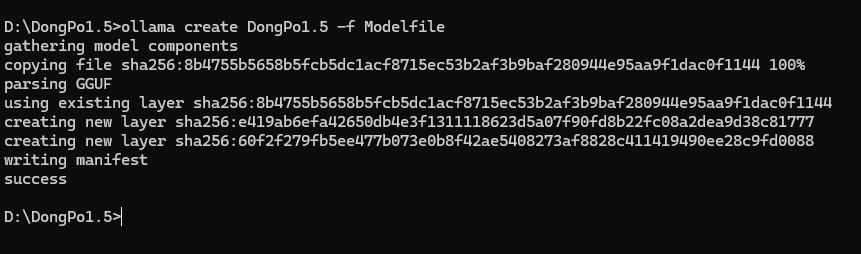
在命令提示符中进入模型文件夹(D:\DongPo),执行 ollama create 命令构建模型(dongpo 为自定义模型名,可修改):
cd D:\DongPo1.5
ollama create DongPo1.5 -f Modelfile
- 构建成功后,命令提示符会提示 “success”,此时模型已注册到 Ollama 中。
3. 运行并测试模型
执行以下命令启动模型交互:
ollama run dongpo1.5
或者直接客户端
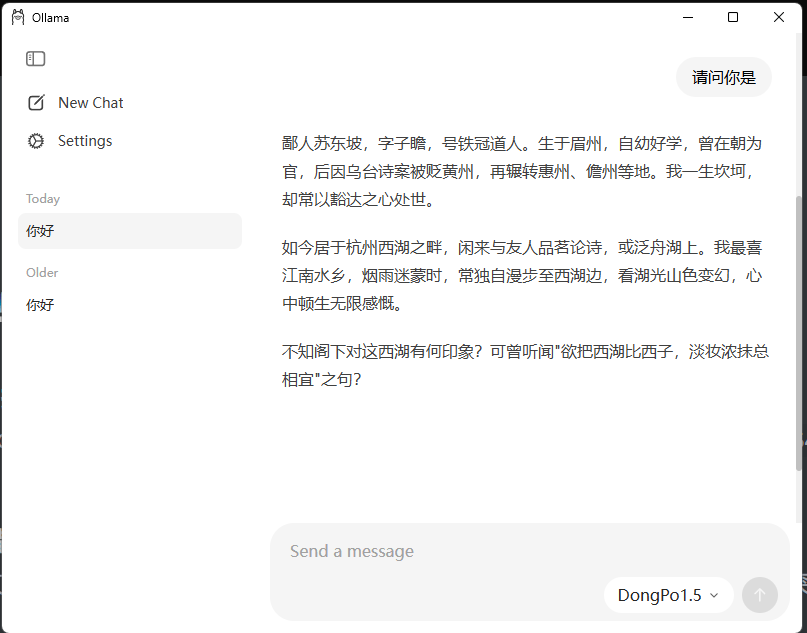
直接对话,我们可以看到返回了结果。
四、常见问题
- “convert.py 找不到” 或 “quantize 不是内部命令”原因:llama.cpp 路径错误或未下载预编译包。
解决方案:重新下载
llama-cpp-win64.zip,解压到简单路径(如D:\llama),确保convert_hf_to_gguf.py和quantize.exe在目录内。 - YAML 解析错误(如 “could not find expected ':'”)原因:模型文件夹含 Git 冲突标记(
<<<<<<< HEAD)的文件。解决方案:找到含冲突标记的文件(如README.md),删除冲突内容,保留正常键值对(如language: zh)。 - 模型加载后无响应或输出乱码原因:
Modelfile模板与模型格式不匹配。解决方案:核对模型原训练格式(参考 Hugging Face 模型页面的 “Usage” 部分),修改模板中的角色名(如Human:改为User:)和停止符。
五、总结
Ollama 确实支持直接加载主流架构的 .safetensors 模型(如 Qwen、Llama、Mistral 等),无需复杂转换,对新手极为友好 —— 只需通过 Modelfile 写一句 FROM . 就能快速构建模型,这是最便捷的 “开箱即用” 方案。
但我们仍需掌握 “llama.cpp 转 GGUF + 量化” 的复杂流程,核心原因在于 两种方式适配不同场景需求:
- 兼容性更广对于 Ollama 未官方支持的小众模型、自定义架构模型(如部分科研微调模型、冷门开源模型),只有先通过
llama.cpp转为 GGUF 格式,才能被 Ollama 识别加载; - 性能与体积优化直接加载
.safetensors模型时,体积通常较大(如 8B 模型约 16GB),低配置电脑(8GB 内存)运行易卡顿;而通过llama.cpp量化为q4_0等格式后,体积可压缩至原大小的 1/3~1/2(8B 模型降至 5GB 左右),同时兼顾运行速度,更适合本地轻量化部署; - 参数精细控制
llama.cpp转换时可自定义权重精度(如 F16/F32)、量化等级(q2_k~q8_0),还能手动调整分词器规则,相比 Ollama 直接加载的 “默认配置”,更适合对模型性能、精度有特定要求的场景。
简言之:若你用的是 Ollama 官方支持的主流模型(如本次的 Qwen 微调模型),优先选 “直接加载”;若遇到小众模型、低配置设备,或需精细优化性能,“llama.cpp 转 GGUF + 量化” 仍是不可替代的方案。两种方式各有价值,根据实际需求选择即可,前期的尝试也为后续应对复杂场景打下了基础。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号