35000 token 压缩到 920——claude-mem 如何用渐进式披露解决 AI 的记忆问题

35000 token 压缩到 920——claude-mem 如何用渐进式披露解决 AI 的记忆问题

智能时代蛮子
发布于 2026-06-10 20:57:01
发布于 2026-06-10 20:57:01
GitHub: https://github.com/thedotmack/claude-mem
一句话总结
Claude Code 生态中最成熟的持久记忆插件,通过「Observer Agent + 渐进式上下文披露」架构,让 AI 在会话间保持项目知识连续性,6.5 个月迭代至 v10.6、39K stars。
值得关注的理由
- 解决真实痛点:Claude Code 每次会话无状态,开发者反复解释项目上下文的时间浪费是普遍痛点。claude-mem 用「LLM 观察 LLM」的方式自动提取和压缩知识
- 渐进式上下文披露:不是粗暴的 RAG 全量注入,而是「先给目录(~800 token),Agent 自主决定获取详情(~120 token/条)」——从 ~35,000 token 降到 ~920,这个模式可迁移到任何 AI Agent 系统
- 极高速迭代的工程参考:6.5 个月内 1,490 次提交、228 个版本、从 v3 到 v10 的 7 次大版本演进,是独立开发者驱动开源项目的典型范本
项目展示
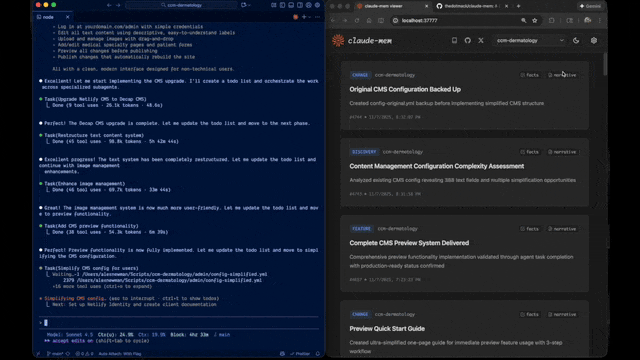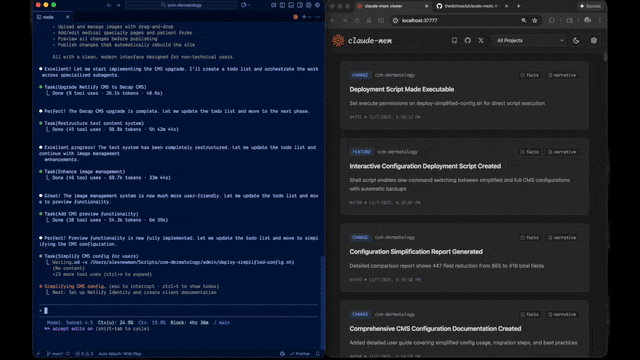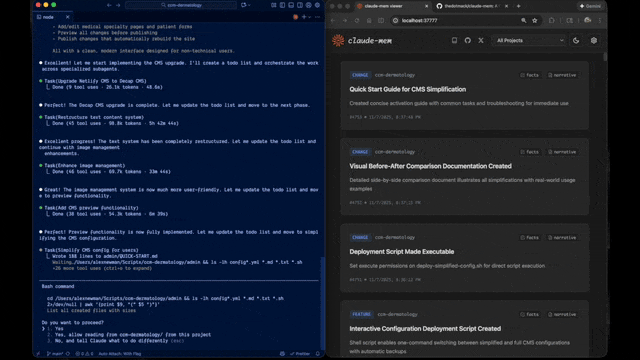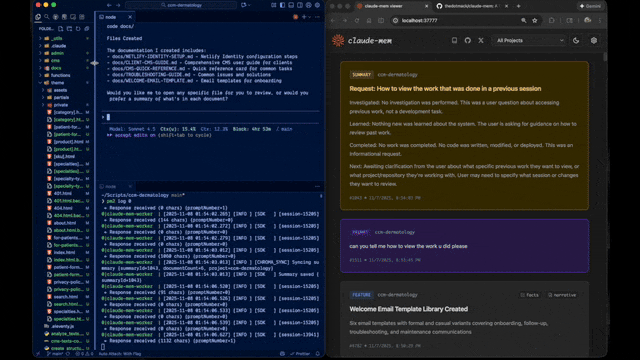
claude-mem preview
claude-mem 工作流程预览:自动捕获工具调用 → Observer Agent 提取观察 → 渐进式注入下次会话
项目画像
维度 | 数据 |
|---|---|
GitHub | https://github.com/thedotmack/claude-mem |
Star / Fork | 39,033 / 2,840 |
代码行数 | 136,417 行(JavaScript 55.4%, TypeScript 33.6%) |
项目年龄 | 6.5 个月(2025-08-31 创建) |
开发阶段 | 高速成长期(1,490 commits,228 个版本标签,约 1.2 天/版本) |
贡献模式 | 单人主导(thedotmack 86.6%,73 位贡献者) |
质量评级 | 代码[良好] 文档[优秀] 测试[良好] |
作者视角:为什么存在这个项目
创始人/作者背景
Alex Newman(thedotmack),15 年 GitHub 资历的独立开发者,92 个公开仓库。近期全力投入 claude-mem 及衍生生态(OpenClaw 网关、crabspace、aims),正在围绕 claude-mem 构建完整的商业化产品线。
问题判断
核心发现:AI Agent 的上下文不是越多越好,而是存在「注意力预算」的经济学问题。传统 RAG 方案一次性注入 ~35,000 token 的历史信息,其中仅 ~6% 与当前任务相关,浪费 94% 的注意力预算。简单的 CLAUDE.md 维护方案信息密度低且不可搜索。时机上,Claude Code 用户高速增长但生态工具极度匮乏,是典型的「需求井喷但供给不足」的窗口期。
解法哲学
- 非侵入式观察:Claude Code 是闭源二进制,通过 Hook 系统从外部观察而非修改内部行为
- 压缩而非存储:不存原始对话,而是用另一个 Claude 实例(Observer Agent)提取结构化「观察」——包含类型、概念、事实、叙事的知识单元
- 渐进式披露:借鉴信息架构领域的 Progressive Disclosure 原则——先给索引让 Agent 自己决定看什么,Agent 控制自己的上下文消费
- 明确不做:不做全量对话存储、不做传统 RAG 全量检索、不修改 Claude Code 本身
战略意图
从 v3 到 v10 的演进揭示清晰的平台化战略:
- 基础能力(v3-v5):transcript 压缩 → Hook 系统 → Web Viewer UI
- 搜索智能化(v6-v8):MCP 搜索工具、Chroma 向量数据库、混合搜索
- 平台化(v9-v10):OpenClaw 网关、Cursor IDE 支持、多 AI Provider、Mode 系统、Smart Explore
核心价值提炼
创新之处
- 渐进式上下文披露(新颖度 4/5 | 实用性 5/5 | 可迁移性 5/5)
- 将信息架构的 Progressive Disclosure 应用到 AI Agent 上下文管理。3 层架构:索引(~800 token)→ 时间线 → 完整详情。Agent 成为自己上下文消费的决策者,从 ~35,000 token 降到 ~920
- Observer Agent 模式(新颖度 4/5 | 实用性 4/5 | 可迁移性 4/5)
- 启动独立的 Claude 子进程作为「观察者」,禁用所有工具,只观察主会话的工具调用并生成结构化 XML 知识单元。「用 LLM 观察 LLM」的元认知模式
- Token 经济学可视化(新颖度 3/5 | 实用性 4/5 | 可迁移性 4/5)
- 每个观察记录存储「发现成本」(原始 token)和「阅读成本」(压缩后 token),让用户直观感受记忆系统的 ROI
- Smart Explore(Tree-sitter AST 代码导航)(新颖度 3/5 | 实用性 5/5 | 可迁移性 4/5)
- 用 tree-sitter 解析 9 种语言 AST,提供 3 层导航:smart_search → smart_outline → smart_unfold。对比传统 Glob→Grep→Read 流程节省 6-12x token
- 边缘隐私处理(新颖度 2/5 | 实用性 4/5 | 可迁移性 5/5)
- <private> 标签在 Hook 层(数据流最前端)剥离,数据永远不到达 Worker/数据库。含 ReDoS 防护
- Mode 继承系统(新颖度 2/5 | 实用性 4/5 | 可迁移性 4/5)
- JSON 配置 + 深度合并实现模式继承(如 code--ko 继承 code 模式只覆盖 prompts),无代码改动扩展到新语言/新领域
可复用的模式与技巧
模式 | 简述 | 适用场景 |
|---|---|---|
索引→选择→详情 三层检索 | 先返回轻量索引(含 token 成本),Agent 选择后返回完整内容 | 任何向 AI Agent 提供上下文的系统 |
Hook 驱动非侵入式观察 | 通过外部 Hook 观察闭源系统 → 异步处理 → 下次启动注入 | 给不可修改系统添加记忆 |
结构化知识提取 Pipeline | 原始数据 → LLM 提取 → XML 解析 → SQLite → Chroma → 混合检索 | 从非结构化数据到可搜索知识的流水线 |
多 Provider 回退策略 | Claude SDK → Gemini → OpenRouter,共享 prompt 和解析器 | 需要成本优化的 LLM 应用 |
版本缓存智能安装 | .install-version 文件标记版本,启动时比对跳过重复安装 | 任何需要启动时检查依赖的插件系统 |
单 HTML 嵌入式 UI | esbuild 将 React 应用打包为单个 HTML,由 Express 直接返回 | 开发者工具的嵌入式 Web UI |
竞品格局与定位
差异化护城河
- 渐进式上下文披露:唯一做到「让 Agent 控制自己的上下文消费」的方案
- 完整端到端系统:从捕获到搜索到可视化的全链路
- 生态广度:30+ 语言、Cursor 支持、OpenClaw 集成、Mode 系统、Smart Explore
竞争风险
- zilliztech/memsearch 是最具威胁的竞品:Markdown-first 架构更简洁透明,且有 Milvus/Zilliz 企业背景支撑
- Claude Code 官方:如果 Anthropic 在 Claude Code 中内置记忆功能,所有第三方方案都将面临生存危机
- 复杂度反噬:573 个文件、多个外部依赖,安装门槛可能将非技术用户推向更简单的方案
生态定位
Claude Code 插件生态的「记忆基础设施」,是目前功能最完整、社区最活跃的持久记忆方案。在 Claude Code → 多 Agent 编排(OpenClaw)→ 跨 IDE 扩展(Cursor)的方向上扩展。
套利机会分析
- 信息差:无套利空间——39K stars、多语言 README、Discord 社区,信息已充分传播。但其「渐进式上下文披露」的设计理念在中文技术社区传播有限
- 技术借鉴:渐进式上下文披露模式、Observer Agent 模式、Token 经济学可视化——这三个模式可直接迁移到任何 AI Agent 的上下文管理系统
- 生态位:填补了 Claude Code 无状态会话的记忆空白。但这个空白可能被 Anthropic 官方填补
- 趋势判断:仍在高速增长(日均数百 star),符合 AI Agent 工具链的爆发趋势
风险与不足
- 平台依赖风险:高度依赖 Claude Code 的 Hook API,Anthropic 任何 API 变更都可能导致插件失效
- 官方替代风险:如果 Claude Code 内置记忆功能,整个项目的存在价值将受到根本性挑战
- $CMEM 代币:将开源项目与加密货币绑定,引入金融化因素,可能影响技术社区信任
- Worker API 无认证:HTTP API 默认无认证(Issue #1157),仅靠 localhost 绑定保护
- 复杂度过高:573 个文件、41 个依赖、多个外部服务,对独立开发者的维护能力是重大挑战
- AGPL-3.0 许可证:对企业用户有合规限制
行动建议
- 如果你要用它:适合 Claude Code 重度用户,每天多次使用且需要跨会话保持项目知识。安装后通过 claude-mem search 验证搜索功能正常。如果只需简单记忆保持,severity1/auto-memory(维护 CLAUDE.md)可能更轻量
- 如果你要学它:重点关注三个文件:src/services/worker/worker-agent.ts(Observer Agent 实现)、src/services/context/(渐进式上下文披露架构)、src/services/worker/search-strategies.ts(混合搜索策略模式)
- 如果你要 fork 它:改进方向:(1) 添加 Worker API 认证机制 (2) CI 中配置自动化测试运行 (3) 简化安装流程降低入门门槛
知识入口
资源 | 链接 |
|---|---|
DeepWiki | 已收录 |
Zread.ai | 已收录 |
官方文档 | docs.claude-mem.ai |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号