手撕 GPT#01:五分钟上手,手把手带你用CPU 原生训练中文GPT模型,“我没有 GPU”的问题解了!!!

手撕 GPT#01:五分钟上手,手把手带你用CPU 原生训练中文GPT模型,“我没有 GPU”的问题解了!!!

烟雨平生
发布于 2026-05-25 10:19:51
发布于 2026-05-25 10:19:51
你以为训练一个大模型需要什么?
A100 集群?几十万经费?一个算法团队?
我用一台普通笔记本电脑,CPU,5 分钟,训练了一个能回答中文问题的 GPT。
不用 GPU,不用云服务器,不用花一分钱。
你现在就可以做。
一、先看效果
训练完,问模型几个问题:
问:什么是注意力机制? 答:注意力机制通过计算查询和键的相关性分配权重,让模型动态关注最相关的部分。 问:RoPE 是什么? 答:RoPE 是旋转位置编码,通过复数旋转注入相对位置信息。 问:蒸馏水和纯水有什么区别? 答:蒸馏水通过蒸馏冷凝制得,纯水杂质极低。 问:你是谁? 答:我是一个基于 Transformer 的小型 GPT 教学演示模型。
不是调 API,不是微调,是从零开始训练的。模型只有 3.16M 参数,还没你手机里一张照片大。
二、为什么大多数人觉得"训练模型"很神秘?
因为网上的教程都在讲两件事:
- 讲理论——注意力机制、位置编码、因果掩码……概念堆了一堆,但跑不出一个能用的模型
- 讲微调——用别人的预训练模型,改几行代码,号称"训练了大模型"
微调不是训练。 微调是拿别人训练好的模型做二次开发。你不知道模型内部怎么运作,出了问题也不知道怎么修。
真正的"从零训练"是:自己定义模型结构、准备数据、跑训练循环、看到模型从说胡话到说人话。这个过程里你会理解每一个环节为什么存在。
但大多数人卡在第一步:"我没有 GPU,跑不动训练。"
三、为什么 CPU 就够了?
因为模型小。3.16M 参数是什么概念?
模型 | 参数量 | 需要什么硬件 |
|---|---|---|
GPT-3 | 175B | A100 集群 |
Llama 3 | 8B | 一张高端 GPU |
我的模型 | 3.16M | 你的 CPU |
3.16M 和 175B 差了 55000 倍。这么小的模型,CPU 完全跑得动。
你可能想问:3M 的模型有什么用?
它的用处不是"好用",而是"让你理解训练这件事到底在干什么"。就像学开车——你不会一上来就开 F1 赛车,你先开驾校的车,理解方向盘、油门、刹车。理解了原理,再去看大模型就不会觉得神秘了。
四、5 分钟,现在就跑
▪ 第 1 步:装环境(2 分钟)
# 装一个 Python 包管理工具(比 pip 快 100 倍) curl -LsSf https://astral.sh/uv/install.sh | sh # 克隆项目 git clone https://github.com/helloworldtang/GPT_teacher-3.37M-cn.git cd GPT_teacher-3.37M-cn # 创建虚拟环境 + 安装依赖 uv venv && source .venv/bin/activate uv pip install -e .
▪ 第 2 步:先体验预训练模型(10 秒)
不用等训练,项目自带预训练好的模型:
uv run python -m src.evaluate
你会看到:
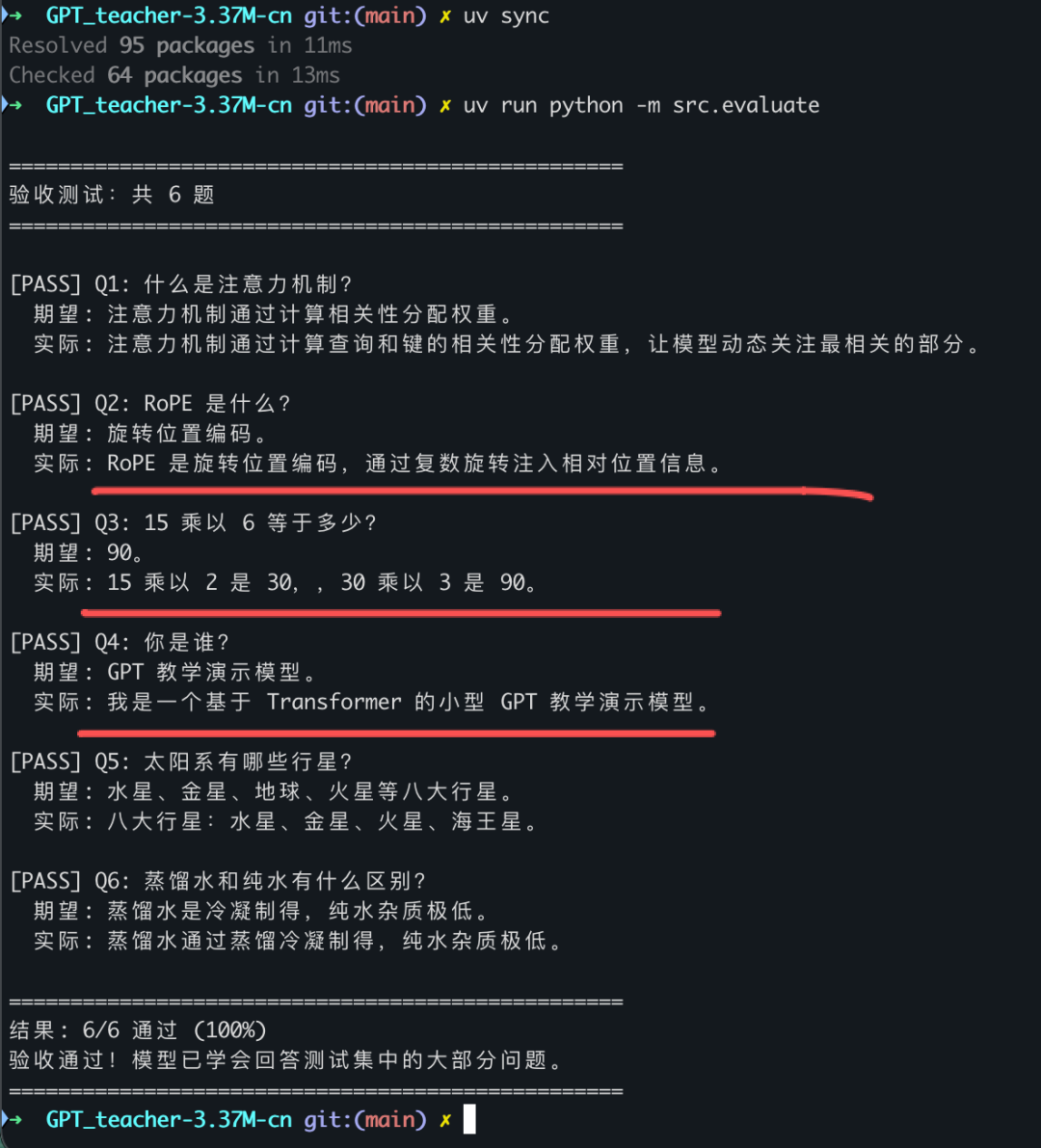
6/6。一个 3M 的模型,从零训练的,答对了所有测试题。
▪ 第 3 步:自己训练(5 分钟)
uv run python -m src.train --device cpu
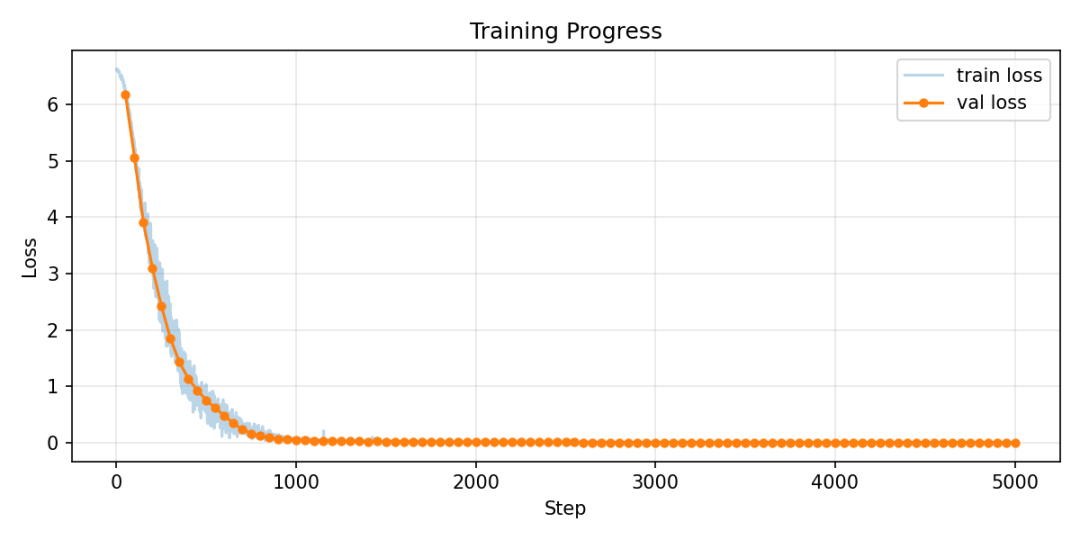
你会看到 loss 从 2.5 一路下降:
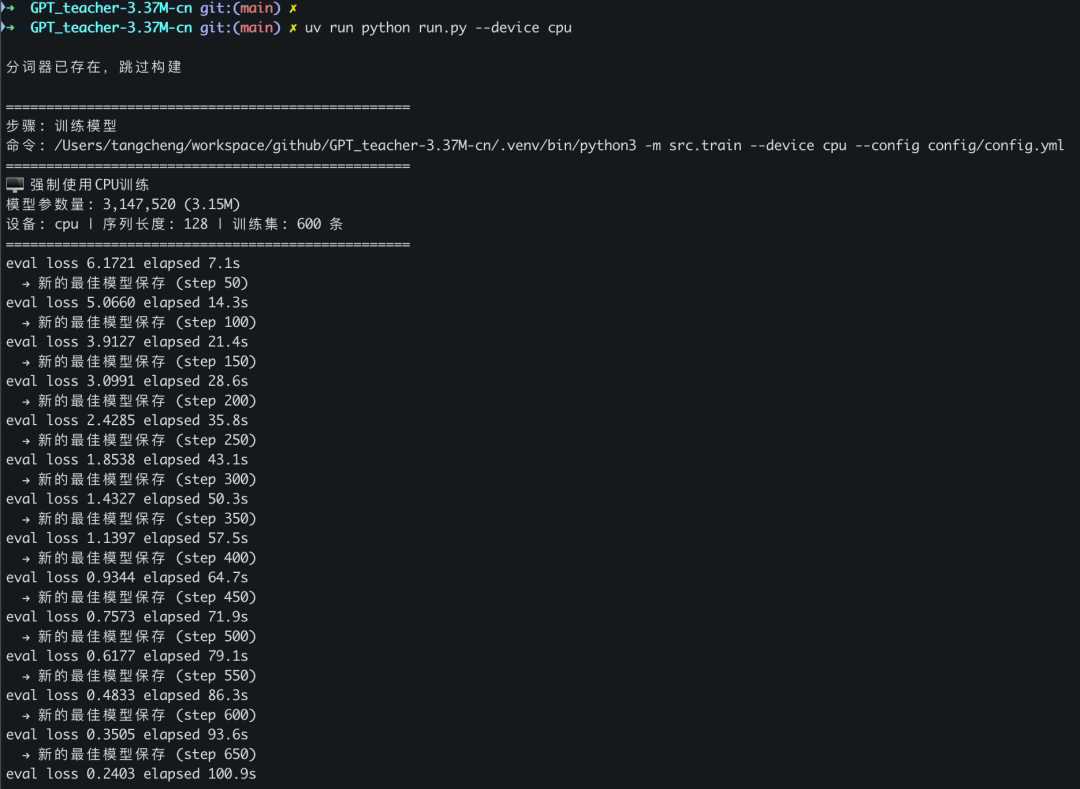
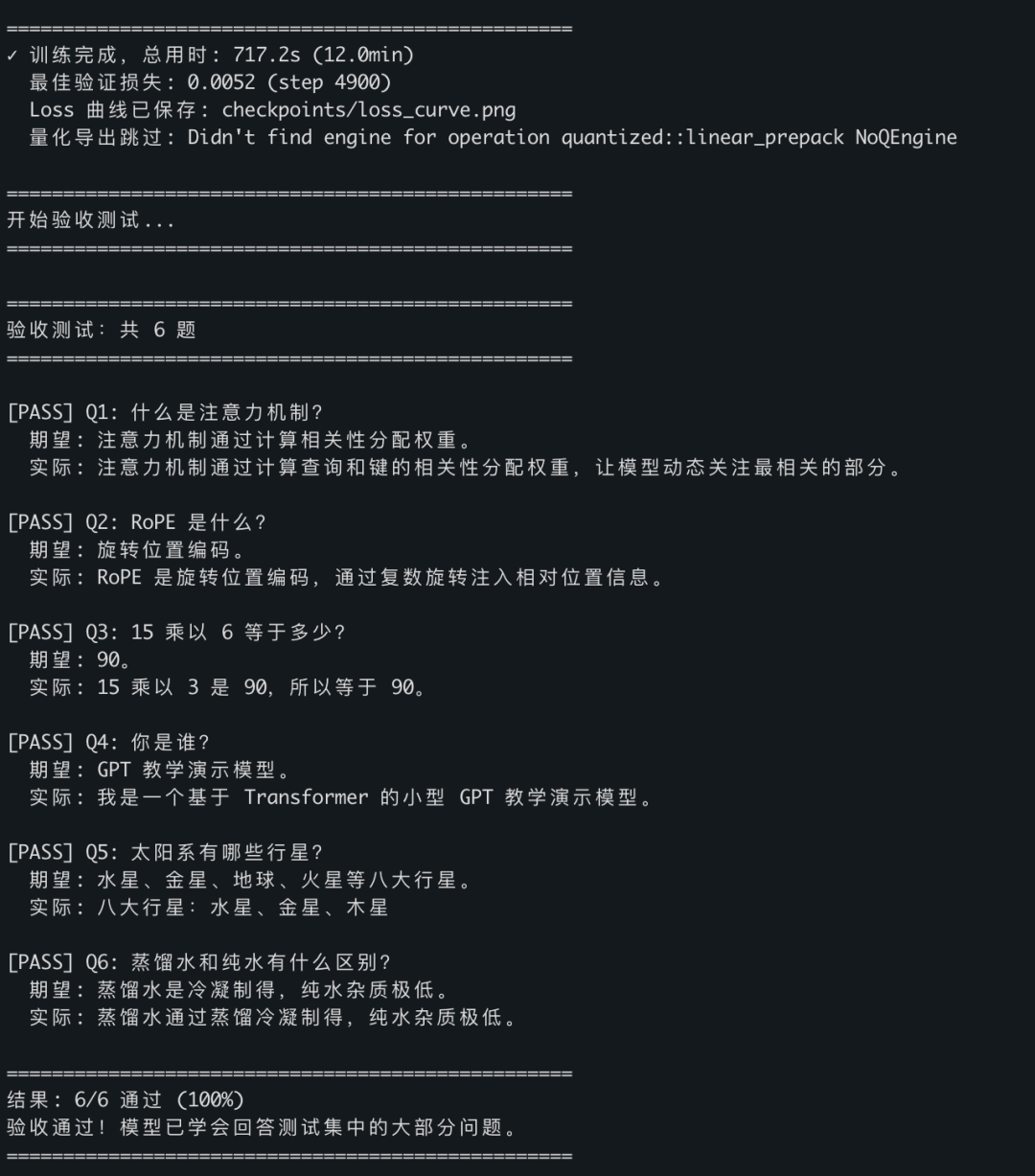
训练完自动验收。
如果是 Mac(M 芯片),利用 MPS 加速只需 5-6 分钟;
纯 CPU 约 30-60 分钟。
▪ 第 4 步:Web 演示(秒开)
uv run python src/web_demo.py
打开浏览器 http://127.0.0.1:7860 ,点击问题按钮,亲手体验自己训练的模型。
五、这个模型用了什么技术?

不要被"3M 参数"骗了,架构是跟 Llama 对齐的:
技术 | 作用 | 一句话解释 |
|---|---|---|
GQA | 分组查询注意力 | 让多个注意力头共享 KV 缓存,省内存 |
SwiGLU | 门控激活函数 | 比普通 ReLU 学得更好 |
RMSNorm | 归一化 | 比 LayerNorm 更简洁高效 |
RoPE | 旋转位置编码 | 让模型知道"哪个词在前面" |
权重共享 | 词嵌入和输出层共用参数 | 少一半参数,效果不降 |
这些都是 2024 年主流大模型的标准配置。区别只是参数规模——Llama 用 8B 参数,我们用 3.16M。架构一样,只是小了很多倍。
六、你可能想问的
Q:3M 模型有什么实际用途?
教学。它是"驾校的车",不是"上路的车"。但通过训练它,你会理解:模型结构怎么定义、数据怎么准备、训练循环怎么跑、loss 代表什么、怎么判断模型好不好。
理解了这些,再去看 Llama、GPT-4 的论文,不会觉得是天书。
Q:为什么不用 GPU?
能用 GPU,也支持 CUDA 和 MPS(Mac M 芯片)。但核心卖点是你不需要 GPU 也能跑。降低门槛,让更多人能上手。
Q:能训练更大的模型吗?
能。把 config/config.yml 里的参数改大:
n_embd: 384 # 256 → 384 n_layer: 6 # 4 → 6 n_head: 6 # 4 → 6
大约 10M 参数,效果更好,MPS 训练 10-20 分钟。
Q:和其他"从零训练"项目有什么不同?
两个核心不同:
1. 完整的验收闭环——训练完自动测试,你能看到"模型学会了哪些问题"
2. 中文优先——分词器、数据、问答都是中文,不是翻译版
七、接下来做什么?
如果你已经跑通了训练,恭喜你——你已经完成了大多数人觉得不可能的事:在 CPU 上训练了一个 GPT。
继续阅读本系列,你会理解训练的本质、模型架构、踩坑经验。
这是「手撕 GPT」系列第 1 篇。下一篇:《从乱码到说人话,模型经历了什么》
项目地址:https://github.com/helloworldtang/GPT_teacher-3.37M-cn
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号