lmdeploy v0.13.0 升级:支持新模型、新端点、TurboQuant、Anthropic兼容服务、Mixed Modality 与多项核心优化,推理服务能力全面进化

lmdeploy v0.13.0 升级:支持新模型、新端点、TurboQuant、Anthropic兼容服务、Mixed Modality 与多项核心优化,推理服务能力全面进化

福大大架构师每日一题
发布于 2026-05-20 13:40:56
发布于 2026-05-20 13:40:56

在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
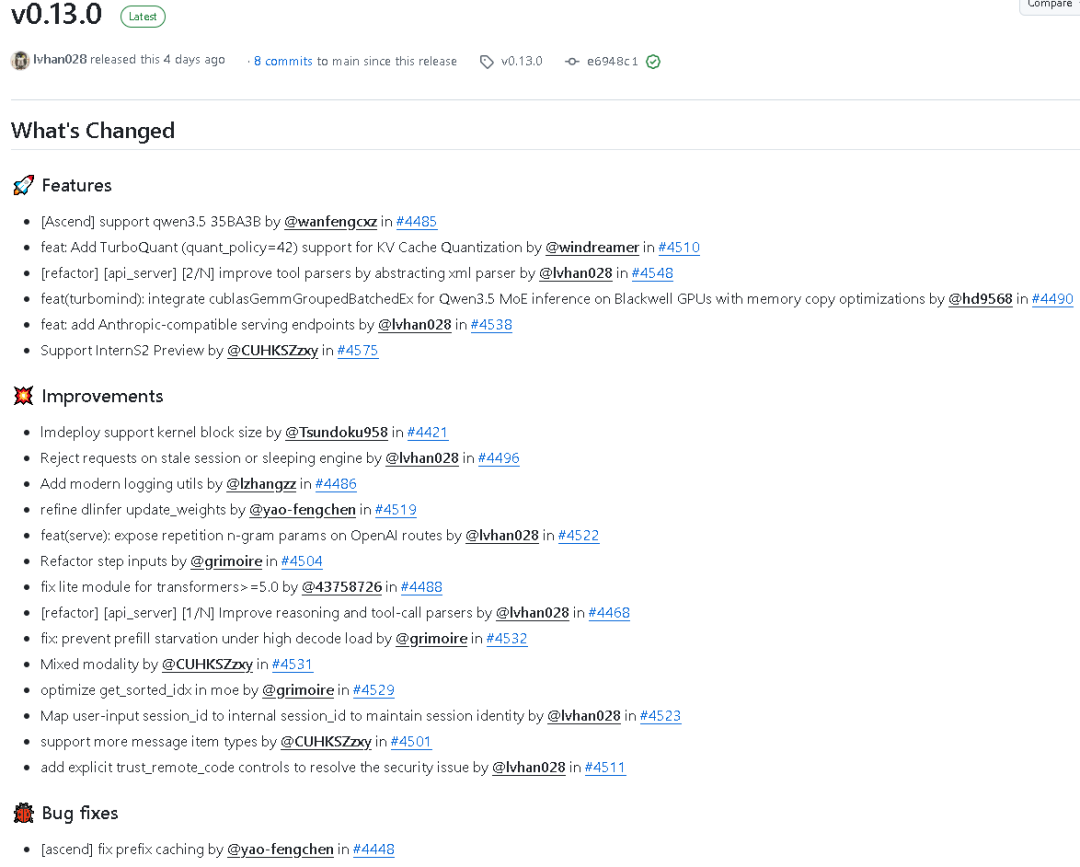
lmdeploy v0.13.0 已正式发布,这一版本覆盖范围非常广,既包含新模型支持,也包含推理服务、量化、缓存、工具解析、调度、日志、端点兼容性等多个方面的升级。整体来看,v0.13.0 不是单点修复式更新,而是一次面向推理能力、服务能力和工程稳定性的系统性增强。
如果你正在关注 lmdeploy 在大模型推理、服务部署、量化优化、工具调用、缓存管理、多模态输入以及不同硬件平台适配方面的演进,那么这一版值得重点关注。下面按照功能模块,对 v0.13.0 的所有更新内容进行详细梳理。
一、模型与平台支持继续扩展
v0.13.0 首先最直观的变化,就是对更多模型和平台的支持进一步增强。
1. 支持 qwen3.5 35BA3B
这一版本新增了对 qwen3.5 35BA3B 的支持,面向 Ascend 场景进行了适配。这意味着在相关硬件平台上,可以更好地运行该模型版本,进一步扩展了 lmdeploy 的模型覆盖范围。
2. 支持 InternS2 Preview
v0.13.0 还增加了对 InternS2 Preview 的支持。这表明 lmdeploy 继续在新模型接入速度上保持推进,为后续更多模型版本落地打下基础。
3. Mixed modality
这一版本还带来了 Mixed modality 能力,说明 lmdeploy 在多模态输入处理方面继续增强。结合后面“支持更多 message item types”的更新,可以看到这一版对于复杂输入结构的适配更加完整。
4. 支持更多 message item types
v0.13.0 增加了对更多 message item types 的支持,这类更新对多轮对话、复杂消息结构以及多模态/混合模态输入非常关键。它让服务端对不同消息元素的理解更完整,减少兼容性问题。
二、量化与缓存能力明显增强
这一版本在量化与 KV Cache 量化方面有非常重要的更新,直接关系到推理效率和显存占用。
1. TurboQuant 支持
新增 TurboQuant 支持,使用 quant_policy=42 作为 KV Cache Quantization 的支持方案。这个变化说明 lmdeploy 在缓存量化方向继续推进,为降低显存压力、提升推理部署灵活性提供了新能力。
2. 支持 kernel block size
lmdeploy 增加了 kernel block size 支持。这个能力与底层 kernel 调度和缓存布局相关,对性能调优和底层执行效率有重要意义。
3. 修复 kernel-block-size
与此同时,这一版还对 kernel-block-size 相关问题进行了修复,说明在引入相关能力后,工程实现层面也进行了进一步完善。
4. 修复 cache sizing 和 cache block layout edge cases
缓存尺寸和缓存块布局的边界问题也在 v0.13.0 中得到修复。这类修复虽然看起来比较底层,但对实际服务稳定性非常关键,尤其是在不同负载、不同长度请求以及复杂缓存场景下,可以减少异常行为。
5. block_offsets padding 0
这一版本还修复了 block_offsets padding 为 0 的处理问题,继续完善缓存和块管理相关逻辑。
6. 修复 Ascend 场景下的 prefix caching
在 Ascend 场景中,prefix caching 得到了修复。前缀缓存是提升推理性能的重要技术之一,这类修复有助于提升实际服务效果。
7. 修复 evicted seqs 的 reprefill 问题
对于被驱逐序列在 reprefill 过程中使用无效 draft tokens 的问题,这一版也做了修复。该修复有助于提升长上下文或复杂调度场景下的正确性。
三、推理性能与调度优化继续推进
v0.13.0 在调度、吞吐、性能瓶颈和 decode/prefill 平衡方面也有不少改进。
1. 防止高 decode 负载下 prefill starvation
这是本版本非常重要的一项改进:修复了在高 decode 负载下 prefill 饥饿的问题。这个问题直接影响在线服务体验,尤其在高并发场景下,prefill 可能被持续压制,从而导致请求延迟升高。修复后,服务调度会更加平衡。
2. 优化 moe 中的 get_sorted_idx
针对 moe 相关逻辑,v0.13.0 优化了 get_sorted_idx 的实现。这类优化通常直接面向性能路径,对 MoE 推理效率有帮助。
3. 支持 cublasGemmGroupedBatchedEx
在 turbomind 中,v0.13.0 集成了 cublasGemmGroupedBatchedEx,用于 Blackwell GPU 上的 Qwen3.5 MoE 推理,并配合内存拷贝优化。这是一个非常有针对性的性能增强,说明 lmdeploy 正在围绕新硬件架构和 MoE 推理做底层优化。
4. Refactor step inputs
这一版本对 step inputs 做了重构。虽然这属于内部结构调整,但往往意味着推理执行链路更清晰,也更有利于后续维护和功能扩展。
5. 修复 mp engine
多进程引擎相关问题在本版本得到修复,进一步增强了服务端在多进程部署场景下的稳定性。
6. 修复 ray mem leak
ray 内存泄漏问题也得到了修复,这对采用分布式或 ray 相关方案的部署环境非常重要。
7. 修复 stale session 或 sleeping engine 的请求处理
v0.13.0 增加了对 stale session 或 sleeping engine 请求的拒绝机制。这个更新让服务行为更明确,也减少了对不可用会话或睡眠状态引擎的无效请求。
8. 睡眠状态下取消请求并阻止新输入
相关地,这一版还修复了睡眠状态下取消请求并阻止新输入的逻辑,进一步保证服务状态一致性。
9. 映射 user-input session_id 到 internal session_id
为了维护 session identity,v0.13.0 增加了将用户输入 session_id 映射到内部 session_id 的机制。这个设计对会话一致性和跟踪管理非常关键。
四、OpenAI 路由与服务端能力增强
v0.13.0 在 serving 层面的增强非常明显,说明 lmdeploy 正在继续强化其对外服务接口的实用性和兼容性。
1. OpenAI 路由暴露 repetition n-gram 参数
这一版本在 OpenAI 路由中暴露了 repetition n-gram 参数,使用户可以在服务层直接控制更多生成行为。这提升了接口的可配置性。
2. 添加 Anthropic 兼容服务端点
这是本版本的重点功能之一:新增 Anthropic-compatible serving endpoints。这个变化显著扩大了 lmdeploy 的接口兼容面,使其能够服务更多依赖 Anthropic 风格接口的应用场景。
3. 改进 tool parsers
api_server 相关的 tool parsers 得到了两轮重构与改进。第一轮聚焦 reasoning 和 tool-call parsers,第二轮通过抽象 xml parser 来进一步提升工具解析能力。这表明 lmdeploy 在工具调用链路上的兼容性和可维护性都在增强。
4. ResponseParser 在非流式模式下修复 tag 截断问题
这一版修复了 ResponseParser 在非 stream 模式下忘记去除 tag 的问题。此类问题虽然细小,但会直接影响返回结果的整洁性与兼容性。
5. 处理 prompt processing 异常时的 yield 错误
当 prompt processing 遇到异常时,v0.13.0 修复了 yield error 的问题。这会让异常链路更稳定,减少服务异常扩散。
五、工具调用、推理解析与 reasoning 能力持续完善
随着大模型工具调用和 reasoning 场景越来越常见,lmdeploy 在这一版中明显强化了相关基础能力。
1. 工具与 reasoning 测试补充
本版本新增了 tool 和 reasoning 相关测试。这意味着 lmdeploy 对这些能力的验证更加系统,有利于保持后续迭代的稳定性。
2. 改进 reasoning 和 tool-call parsers
api_server 的 reasoning 与 tool-call parsers 做了持续改进。结合 xml parser 抽象,可以看出这部分是在为更复杂的工具调用协议做准备。
3. 支持更多 message item types
前面提到的 message item types 扩展,也会间接增强 reasoning 和工具调用在复杂消息结构下的表现。
六、模型和推理细节层面的修复完善
v0.13.0 对多个模型相关问题做了修复,进一步提升正确性。
1. 修复 qwen35 dp
修复了 qwen35 dp 相关问题。
2. 修复 qwen3.5-moe 在 tp>1 下的 mtp 问题
对于 qwen3.5-moe,在 tp>1 条件下的 mtp 问题得到了修复。这类修复对于多卡或张量并行部署尤为关键。
3. 修复 mtp
多个与 mtp 相关的问题在本版本中被修复,包括普通 mtp、rl 场景下的 mtp、以及 fp8 相关支持。
4. 支持 mtp fp8
v0.13.0 支持 mtp fp8,进一步增强了在低精度推理方面的能力。
5. 修复 reprefill 中的 draft token 问题
针对被驱逐序列 reprefill 使用无效 draft tokens 的问题,本版本给出了修复。
七、硬件平台和模型后端适配继续推进
本版本对多个硬件与后端路径都做了适配和修正。
1. Ascend 相关支持与修复
- • 支持 qwen3.5 35BA3B
- • 修复 prefix caching
这些内容表明 Ascend 场景仍然是重要的适配方向。
2. turbomind 的 MoE 推理优化
在 Blackwell GPU 上,turbomind 集成了 cublasGemmGroupedBatchedEx,并加入内存拷贝优化,面向 Qwen3.5 MoE 推理做了更深度的底层增强。
3. dlinfer update_weights 优化
update_weights 逻辑得到 refine,说明权重更新流程在本版本中更加完善。
4. 模块在 transformers>=5.0 下的兼容性修复
lite 模块针对 transformers>=5.0 做了修复,提升了上层依赖升级后的兼容性。
5. 用环境变量控制 recurrent state dtype
新增环境变量 LMDEPLOY_FP32_MAMBA_SSM_DTYPE,用于控制 recurrent state 的 dtype。这个改动提升了运行时配置灵活性,便于在不同环境下进行精度控制。
八、安全、配置与工程化改进
除了模型和性能,v0.13.0 也对安全和工程配置做了实用增强。
1. 显式 trust_remote_code 控制
这一版本增加了显式 trust_remote_code 控制,以解决安全问题。这是非常值得关注的改动,说明项目在安全边界上更加明确。
2. 修复 seed=0 被忽略的问题
过去 seed=0 可能会被静默忽略,本版本改成使用 is not None 判断,避免这个问题。这个修复对于实验可复现性很重要。
3. modern logging utils
日志工具得到了现代化升级,有助于提升排障、观察性和工程可维护性。
4. docker 相关补丁与脚本整理
本版本新增了 docker/Dockerfile_patch,并对 messages.py 和 setup.py 做了小幅调整,同时还移除了一些使用较少的 skills,并加入了 docker-build skill。说明工程构建和容器化流程也在继续整理优化。
5. 修复 mutable default arguments
这一版还修复了 mutable default arguments 的问题,这是典型的 Python 工程细节修复,能够避免潜在的隐藏 bug。
6. 修复若干 typo
包括 turbomind.py 和 model.py 中的一些拼写问题也被修正,虽小但体现了版本的整体打磨。
九、测试与 CI 体系持续补强
v0.13.0 并不只是功能堆叠,也做了不少测试体系优化。
1. 增加 tool 和 reasoning 测试
提升关键能力的覆盖度。
2. 更新 h config 并增加 glm4.7 mtp test
对相关测试配置进行了更新,并新增 glm4.7 mtp 测试。
3. CI 中将 test whl 切换到 python 312 并使用测试镜像
这有助于提升 CI 的一致性和测试环境的可控性。
4. hotfix 解决 v0.13.0 的测试问题
在正式发布前,还通过 hotfix 解决了测试问题,说明版本发布流程较为完整。
十、这次 v0.13.0 的整体价值
如果用一句话总结 lmdeploy v0.13.0,可以概括为:
这是一次围绕新模型接入、推理性能、缓存量化、服务端兼容性、工具调用解析和工程稳定性进行的全面升级。
从能力上看,它补齐了:
- • 新模型支持
- • 多模态和混合模态输入
- • KV Cache Quantization
- • Anthropic 兼容端点
- • OpenAI 路由参数增强
- • 工具与 reasoning 解析改进
- • 更完善的缓存与调度修复
从工程上看,它强化了:
- • 现代日志
- • 安全控制
- • 会话身份映射
- • CI 流程
- • Docker 相关支持
- • 依赖兼容性修复
从性能上看,它推进了:
- • 高 decode 负载下的 prefill 公平性
- • MoE 推理优化
- • Blackwell GPU 适配
- • 缓存块和布局优化
- • 低精度与量化相关能力
所以,v0.13.0 并不是简单的“修几个 bug”,而是明显朝着“更强模型适配、更稳服务端、更高推理效率、更好接口兼容”的方向迈进。
结语
代码地址:github.com/InternLM/lmdeploy
对于正在使用 lmdeploy 的开发者来说,v0.13.0 是一个值得升级和验证的版本。它既有新能力,也有大量稳定性修复,同时还补足了不少服务端与推理链路中的关键细节。无论你关注的是模型支持、量化缓存、工具调用、Anthropic 兼容,还是高并发下的稳定推理,这一版都提供了明确提升。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号