给大家推荐一个工具:不仅能省 Token,更能大幅提升 Claude Code 表现

给大家推荐一个工具:不仅能省 Token,更能大幅提升 Claude Code 表现

随机比特
发布于 2026-05-20 12:45:58
发布于 2026-05-20 12:45:58
如果你注意观察最近各大开发社区的讨论,会发现一个普遍现象:大家拿到 Claude Code 觉得编程体验极佳,但经常触及限额,很多人才发现一次复杂的重构会消耗远超预期的上下文 Token。
为什么这些 AI 终端写起代码来这么费钱?
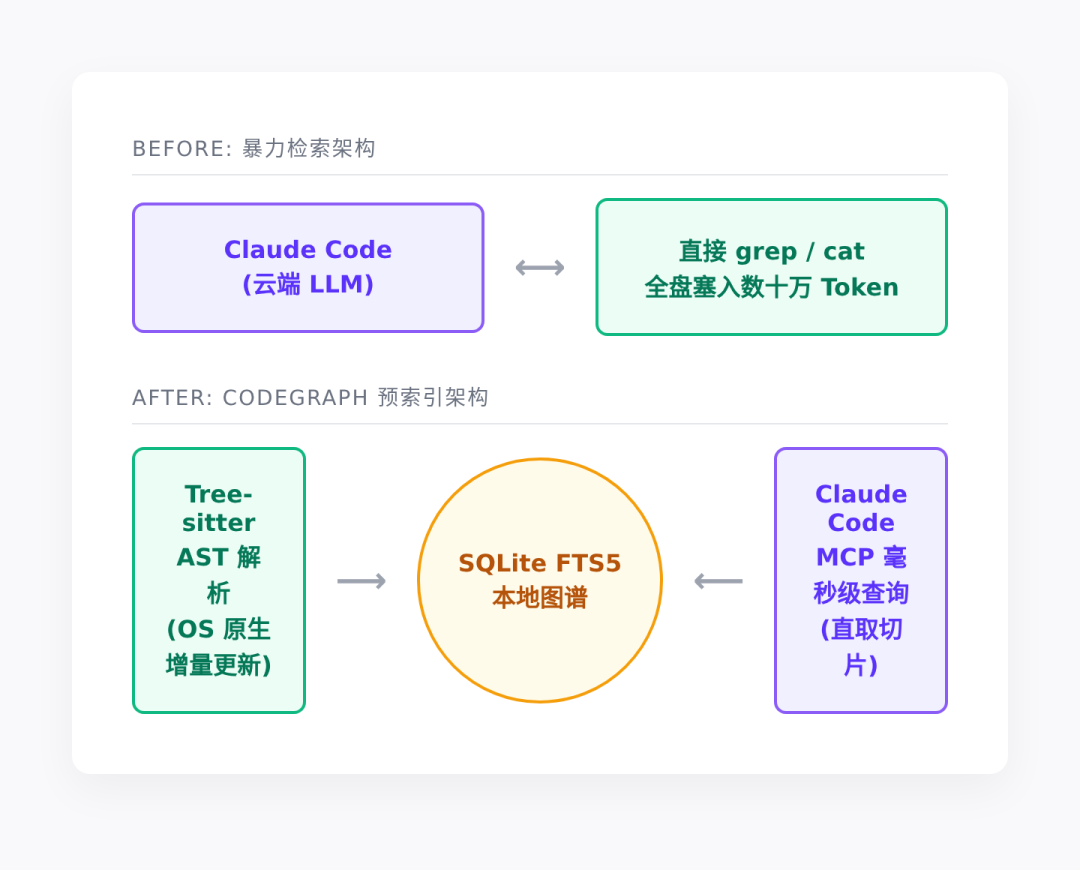
问题出在它的检索机制上。当 AI 需要修改一段深层路由逻辑时,它默认会像一个迷路的新手:先 ls 一下目录,再 grep 猜一下关键词,最后把几个好几千行的文件全盘读取塞进上下文。
这好比每次查生僻字都要把整本字典读一遍。把全库扫描交给 LLM,本质上是在用最高单价的计算资源做最低价值的检索。
01-codegraph-mechanism
这正是 Codegraph 这种本地索引工具最近受到关注的原因。它用一套古典且极其高效的本地技术栈,把大模型从“全量读文件”的体力活里解放了出来。
不要用高射炮打代码依赖
在 Codegraph 之前,解决“大模型找不到代码”的流行思路是不断扩充上下文窗口,硬塞进去。
但这违背了工程效率的常识。计算密集型的模糊逻辑推理应该交给云端大模型,而确定性的规则解析与结构索引,必须沉淀在本地。
Codegraph 把这件事做得极其干净:
- AST 提取:用底层解析器 tree-sitter 静默扫描代码。它支持 19 种语言,将源码转为抽象语法树。函数和类被提炼成节点,调用与继承固化为边。
- 轻量本地库:所有元数据直接存进项目本地的 SQLite 数据库,并借助 FTS5 实现毫秒级全文搜索。摒弃了花哨的向量检索,回归最稳健的文本与关系查询。
- 系统级无感热更:它在后台通过操作系统的原生事件(macOS FSEvents 或 Linux inotify)监听文件变动。只要你改了代码,它就会瞬间完成增量更新,完全不需要手动触发。
Token 要花在刀刃上
当这套本地环境就绪后,Claude Code 的行为模式被彻底扭转了。
它不再反复执行那些高成本的系统命令。取而代之的是,它通过 MCP(Model Context Protocol)直接向 Codegraph 查询结构化索引。
大模型拿到的不再是夹杂着大量冗余代码的原始文件,而是精准的符号关系网和核心切片。
按项目方在 VS Code、Excalidraw 等 6 个真实开源库中的 Benchmark 实测,当面对复杂 的代码追踪任务时,传统依靠 grep 和 cat 的 AI 就像无头苍蝇(平均需要三四十次 工具调用);而接入 Codegraph 后,不仅**工具调用次数暴降了 92%**,探索耗时缩短 了 71%,最恐怖的是:在所有测试用例中,大模型的文件读取(File Reads)次数全部降为 0。
在 Swift Compiler 这种包含两万多文件的超大库中,传统模式查一次关联逻辑需要两分多钟、耗费近 10 万 Token;而 Codegraph 仅用 35 秒、3 次查询就拿到了精准答案。
告别“幻觉改码”,提升重构准确率
如果你以为它仅仅是个“省钱工具”,那就低估了本地图谱的价值。在实际编码中,它对 AI 代码准确率的提升,甚至比省下的 Token 更关键。
传统的 grep 方式极易导致大模型在庞大的代码库中迷失方向,也就是所谓的“探索疲劳”(Exploration Fatigue)。一旦 AI 找不到正确的上下文,它就会开始根据变量名瞎猜,进而引发灾难性的“幻觉改码”。
而在接入 Codegraph 的测试中:
- 防爆破修改:凭借专属的
codegraph_impact工具,AI 在动手改代码前,能瞬间查清一个函数被哪些地方调用了(Impact Radius)。这就像是给 AI 戴上了透视镜,极大降低了因遗漏调用方而导致的“改一处崩全局”的惨案。 - 深度链路追踪:在 Alamofire 的源码测试中,Codegraph 仅用一次调用,就帮模型揪出了一条长达 9 层的深度调用链路。如果是传统的递归
grep,AI 极大概率在中途就会因上下文被冲刷而彻底跟丢。 - 跨语言免迷路:当面对 Python 和 Rust 混编的复杂工程时,本地图谱能让 AI 跨越语言壁垒,顺滑追踪依赖关系。实测表明,接入图谱后,AI 完全停止了盲目的文件扫描,100% 信任并依赖图谱返回的确切关系。
过去一年,行业里有一种大力出奇迹的迷思:只要把上下文拉长,一切工程问题都能被模型“原生”解决。但账单和层出不穷的 Bug 打醒了开发者。
把代码图谱这种确定的、强规则的索引剥离出来,作为 Agent 的本地缓存,才是目前最具性价比的解法。下一个阶段决定 AI 编程效率的,不再是谁的模型能吃下两百万 Token,而是谁能把端侧索引做得更薄、更准。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号