为什么几乎所有AI Agent都在接入MiMo:从“推理增强“到“上下文污染“的系统级代价

为什么几乎所有AI Agent都在接入MiMo:从“推理增强“到“上下文污染“的系统级代价

安全风信子
发布于 2026-05-17 08:17:27
发布于 2026-05-17 08:17:27
作者: HOS(安全风信子) 日期: 2026-05-13 主要来源平台: 综合来源(基于技术观察与深度分析) 摘要: 2025年后,Cursor、Copilot、Zed、LangChain等几乎所有主流AI Agent产品开始集体接入一种名为MiMo(Memory + internal Monologue)的推理持续化架构。这种架构的本质不是简单的"长上下文",而是允许模型保存自身推理轨迹并在后续轮次继续继承的状态管理机制。本文深入剖析MiMo如何从底层重写Agent状态机,显著提升Tool Calling成功率和长任务执行能力,同时揭示其带来的推理污染、Token爆炸、指令遵循下降等系统级代价。通过对比传统Chat Completion与MiMo Agent的架构差异,本文将展示AI Agent如何从"Stateless聊天模型"向"Stateful状态机"演进,并探讨未来Agent竞争的核心焦点——推理状态管理技术的五大方向。
目录- 本节为你提供的核心价值
- 一、前言:AI Agent的集体升级现象
- 二、什么是MiMo:推理持续化架构的本质
- 2.1 MiMo的核心定义
- 2.2 传统Chat Completion vs MiMo:架构对比
- 2.3 MiMo的状态机模型
- 三、MiMo如何改变Agent的状态机
- 3.1 传统Agent的"重启"问题
- 3.2 MiMo Agent的持续推理机制
- 3.3 推理轨迹的数据结构
- 四、为什么头部Agent都在接MiMo
- 4.1 Tool Calling成功率暴涨
- 4.2 长任务终于能做了
- 4.3 Agent开始"拥有工作记忆"
- 五、MiMo的系统级代价:不是免费午餐
- 5.1 MiMo不只是增强,它重写了上下文结构
- 5.2 reasoning_content丢失导致400的原因
- 六、MiMo最大的问题:推理污染
- 6.1 推理污染的本质
- 6.2 推理污染的放大效应
- 6.3 Token消耗的指数增长
- 七、为什么Agent越跑越"疯"
- 7.1 Self-Reinforcement Loop的机制
- 7.2 认知惯性的形成
- 7.3 实际案例:修不完的Bug
- 八、为什么指令遵循会下降
- 8.1 新旧指令的冲突
- 8.2 隐性系统提示词问题
- 8.3 指令遵循下降的量化
- 九、MiMo导致Agent从"聊天模型"变成"状态机"
- 9.1 Stateless到Stateful的范式转变
- 9.2 状态机的五大核心组件
- 9.3 行业进入Cognitive Architecture时代
- 十、未来Agent的真正竞争点
- 10.1 从模型能力到状态管理
- 10.2 五大关键技术方向
- 1. Reasoning Compression
- 2. Memory Pruning
- 3. Cognitive Reset
- 4. Goal Realignment
- 5. Hierarchical Reasoning
- 十一、MiMo的本质:给AI安装"短期人格"
- 11.1 从"每句话都是新人"到"持续人格"
- 11.2 MiMo是"人格"的双刃剑
- 十二、部署MiMo Agent的技术指南
- 12.1 MiMo架构的部署前提
- 12.2 MiMo Agent的基础配置
- 12.3 MiMo Agent的运行流程
- 12.4 MiMo的API调用示例
- 十三、MiMo在各平台的具体实现差异
- 13.1 主流平台的MiMo支持情况
- 13.2 LangChain中的MiMo实现
- 13.3 AutoGen中的MiMo协作模式
- 十四、MiMo架构的监控与运维
- 14.1 关键监控指标
- 14.2 监控仪表盘设计
- 14.3 自动化运维流程
- 十五、结语:AI Agent进入认知工程时代
- 15.1 从文本生成到认知状态维护
- 15.2 决定Agent上限的新因素
- 15.3 MiMo的双重性
- 15.4 面向未来的建议
- A. 术语表
- B. 公式汇总
- C. 配置模板
- D. 延伸阅读建议
- 2.1 MiMo的核心定义
- 2.2 传统Chat Completion vs MiMo:架构对比
- 2.3 MiMo的状态机模型
- 3.1 传统Agent的"重启"问题
- 3.2 MiMo Agent的持续推理机制
- 3.3 推理轨迹的数据结构
- 4.1 Tool Calling成功率暴涨
- 4.2 长任务终于能做了
- 4.3 Agent开始"拥有工作记忆"
- 5.1 MiMo不只是增强,它重写了上下文结构
- 5.2 reasoning_content丢失导致400的原因
- 6.1 推理污染的本质
- 6.2 推理污染的放大效应
- 6.3 Token消耗的指数增长
- 7.1 Self-Reinforcement Loop的机制
- 7.2 认知惯性的形成
- 7.3 实际案例:修不完的Bug
- 8.1 新旧指令的冲突
- 8.2 隐性系统提示词问题
- 8.3 指令遵循下降的量化
- 9.1 Stateless到Stateful的范式转变
- 9.2 状态机的五大核心组件
- 9.3 行业进入Cognitive Architecture时代
- 10.1 从模型能力到状态管理
- 10.2 五大关键技术方向
- 1. Reasoning Compression
- 2. Memory Pruning
- 3. Cognitive Reset
- 4. Goal Realignment
- 5. Hierarchical Reasoning
- 11.1 从"每句话都是新人"到"持续人格"
- 11.2 MiMo是"人格"的双刃剑
- 12.1 MiMo架构的部署前提
- 12.2 MiMo Agent的基础配置
- 12.3 MiMo Agent的运行流程
- 12.4 MiMo的API调用示例
- 13.1 主流平台的MiMo支持情况
- 13.2 LangChain中的MiMo实现
- 13.3 AutoGen中的MiMo协作模式
- 14.1 关键监控指标
- 14.2 监控仪表盘设计
- 14.3 自动化运维流程
- 15.1 从文本生成到认知状态维护
- 15.2 决定Agent上限的新因素
- 15.3 MiMo的双重性
- 15.4 面向未来的建议
- A. 术语表
- B. 公式汇总
- C. 配置模板
- D. 延伸阅读建议
本节为你提供的核心价值
本节将为你揭示2025年后AI Agent领域最关键的技术变革——MiMo架构的崛起。本文不仅解析MiMo的技术本质和实现机制,更深入探讨这一架构如何从底层重写Agent的运行逻辑,以及它所带来的系统性代价与潜在风险。通过本文,你将理解为什么Cursor、Copilot、Zed等行业标杆产品都在集体升级,以及未来Agent竞争的本质焦点。
一、前言:AI Agent的集体升级现象
2025年之后,大量AI Agent产品开始出现一个共同现象:它们的输出开始更像"会思考",Tool Calling变得更加稳定,多步任务成功率明显提高,复杂链路执行能力显著增强。
这种变化不是来自模型基础能力的提升,而是来自一种新架构的普及。
我们观察到以下产品都在进行类似的升级:
产品名称 | 所属公司/团队 | 升级特征 |
|---|---|---|
Cursor | Cursor AI | 推理轨迹持续化 |
GitHub Copilot | Microsoft | 多步任务稳定性提升 |
Codex | OpenAI | Agent模式强化 |
Zed | Zed Industries | 状态继承机制 |
Agent Stack | Microsoft | 长期规划能力 |
LangChain | LangChain Inc. | 记忆框架升级 |
AutoGen | Microsoft Research | 多Agent协作 |
Roo Code | Roo Team | 持续推理能力 |
TRAE | TRAE Team | 认知状态管理 |
这些产品的共同选择是接入一种名为**MiMo(Memory + internal Monologue)**的架构。
MiMo的本质不是简单的"长上下文扩展"。它是一种推理持续化架构,允许模型保存自身推理轨迹,并在后续轮次继续继承这种推理状态。
这意味着,一旦reasoning_content丢失,整个Agent会迅速退化——这解释了为什么官方API会在缺少推理历史时直接返回400 Bad Request,拒绝继续推理。
本节核心结论:MiMo不是一项可选功能,而是下一代Agent的基础设施级组件。它从底层改变了Agent的运行范式。
二、什么是MiMo:推理持续化架构的本质
2.1 MiMo的核心定义
MiMo可以理解为:“让模型记住自己是怎么想的”。
这个定义听起来简单,但它代表了一种范式转变。在传统Chat Completion模式下,模型每次输出都是"重新开机"——不会保留推理链、中间状态、工具决策依据、长链任务意图或当前执行阶段。
而MiMo额外保留了一个关键字段:
{
"reasoning_content": "模型内部推理轨迹"
}这意味着:模型不再只是记住"做了什么",而是记住"为什么这么做"。
2.2 传统Chat Completion vs MiMo:架构对比
为了更清晰地理解MiMo的本质,我们需要对比两种架构的差异:

图1:传统Chat Completion与MiMo Agent架构对比
从图1可以清晰看出两种架构的核心差异:
维度 | 传统Chat Completion | MiMo Agent |
|---|---|---|
状态管理 | 无状态(Stateless) | 有状态(Stateful) |
推理连续性 | 每轮独立推理 | 推理轨迹持续继承 |
上下文传递 | 仅当前轮次输入 | 完整推理历史传递 |
Tool Calling稳定性 | 频繁丢失调用原因 | 保留完整决策依据 |
长任务能力 | 20-30步后漂移 | 可维持数百步推理 |
工作记忆 | 无 | 具备持续记忆 |
2.3 MiMo的状态机模型
MiMo将Agent从简单的"输入→输出"模式转变为"状态→推理→状态更新"的循环模式。这种模式可以用状态转移公式表示:
其中:
:第
轮的状态(包含reasoning_content)
:第
轮的输入
:第
轮的推理结果
:状态转移函数
:更新后的状态
本节核心结论:MiMo通过状态机模型实现了推理的持续化,这是AI Agent从"问答工具"向"持续认知系统"演进的关键一步。
三、MiMo如何改变Agent的状态机
3.1 传统Agent的"重启"问题
传统Agent架构可以表示为:
用户 → 模型 → Tool → 模型 → 输出每一步都是重新推理、重新理解世界——用计算机的术语来说,每次Tool调用后模型都会"重启"。
这种架构的问题在于:当一个复杂任务需要多步骤执行时,模型会逐渐丢失对整体目标的追踪。超过20-30步后,模型开始漂移、遗忘、甚至胡说八道。
3.2 MiMo Agent的持续推理机制
MiMo引入了一种持续推理机制,使得Agent能够在多轮交互中保持推理的连贯性:
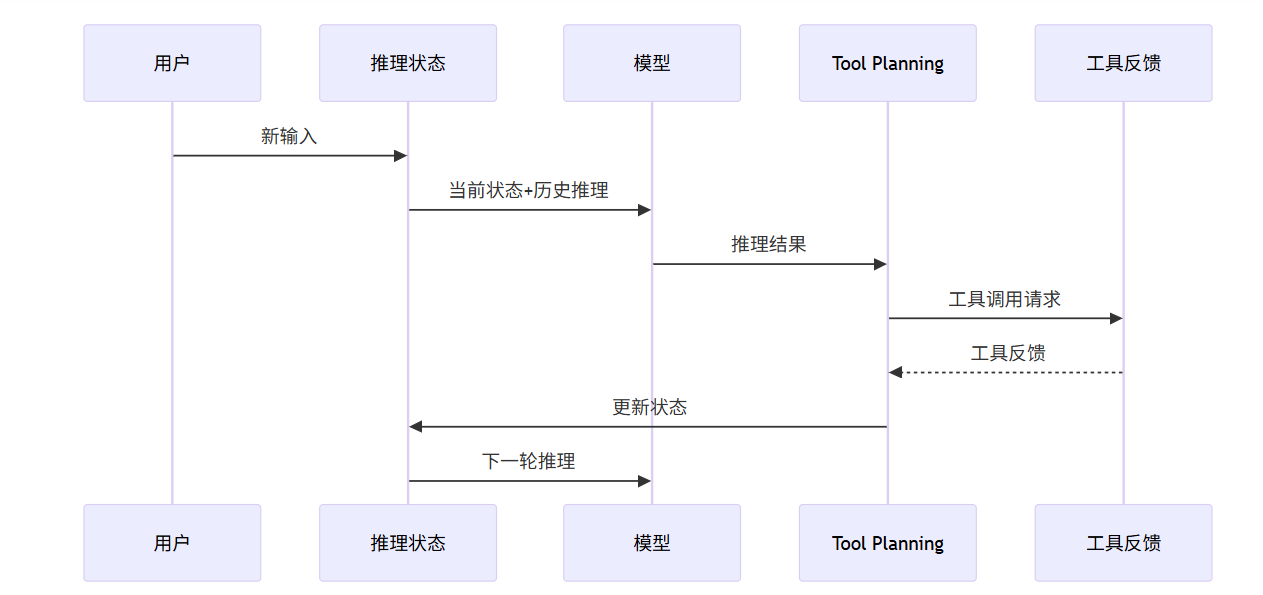
图2:MiMo Agent持续推理序列图
从图2可以看出,MiMo Agent的核心在于状态继承——每一轮的推理结果都会成为下一轮的输入的一部分,形成一个连续的状态链。
3.3 推理轨迹的数据结构
MiMo中的reasoning_content并非简单的文本追加,而是一种结构化的推理轨迹:
{
"reasoning_content": {
"current_phase": "代码实现",
"completed_goals": ["需求分析", "架构设计", "模块划分"],
"remaining_tasks": ["实现核心逻辑", "单元测试", "集成测试"],
"reasoning_chain": [
{"step": 1, "thought": "首先需要理解需求", "conclusion": "需求清晰"},
{"step": 2, "thought": "然后设计架构", "conclusion": "采用分层架构"},
{"step": 3, "thought": "接下来实现模块", "status": "in_progress"}
],
"tool_history": [
{"tool": "read_file", "reason": "需要了解现有代码结构", "result": "找到入口点"}
],
"beliefs": ["项目使用Python", "采用FastAPI框架", "数据库为PostgreSQL"]
}
}这种结构化设计使得模型能够在任意时刻:
- 知道当前处于哪个执行阶段
- 了解已完成和未完成的目标
- 回溯任意历史推理决策
- 理解工具调用的完整上下文
本节核心结论:MiMo通过结构化的推理轨迹和状态继承机制,解决了传统Agent的"重启"问题,使长任务执行成为可能。
四、为什么头部Agent都在接MiMo
4.1 Tool Calling成功率暴涨
在传统模型中,一个典型的问题是:Tool调用完成后,模型经常忘记为什么调用这个Tool。这会导致:
- 重复调用同一个Tool
- 调用与目标无关的Tool
- 无法正确处理Tool返回结果
- 多Tool串联时上下文断裂
MiMo通过保留完整的调用原因、计划和目标,显著提升了Tool Calling的稳定性:
# 传统Agent的Tool Calling(简化示例)
def traditional_tool_call(user_input, model):
response = model.chat(user_input)
# 模型只基于当前输入决定是否调用Tool
if "读取" in response:
result = read_file(...)
# Tool返回后,模型"重启",可能忘记之前的推理
final_response = model.chat(result)
return final_response
# MiMo Agent的Tool Calling(简化示例)
def mimo_tool_call(user_input, model, reasoning_state):
# 模型不仅基于当前输入,还基于历史推理状态
response = model.chat(
user_input,
reasoning_content=reasoning_state # 传递历史推理
)
if "读取" in response:
result = read_file(...)
# 更新推理状态,而不是"重启"
new_reasoning = update_reasoning(
reasoning_state,
tool_used="read_file",
reason="需要了解现有代码结构",
outcome=result
)
final_response = model.chat(result, reasoning_content=new_reasoning)
return final_response, new_reasoning代码示例1:传统Agent与MiMo Agent的Tool Calling对比
4.2 长任务终于能做了
以前,AI超过20-30步后会出现:
- 漂移:偏离原始目标
- 遗忘:忘记已完成的工作
- 幻觉:开始生成虚假信息
- 循环:重复相同的操作
MiMo通过持续保留当前阶段、已完成目标、剩余任务、推理路线,使得:
任务类型 | 传统模型极限 | MiMo模型能力 |
|---|---|---|
自动编程 | 20-30步代码生成 | 数百步完整项目开发 |
自动修复 | 3-5轮调试 | 持续调试直到解决 |
自动部署 | 单步操作 | 多阶段部署流程 |
自动规划 | 简单任务 | 复杂项目规划 |
4.3 Agent开始"拥有工作记忆"
这是MiMo最关键的价值——让LLM获得Working Memory(工作记忆)。
传统模型像"失忆症天才"——每个回答都是全新的人格,没有连续性。MiMo后,Agent第一次拥有了"连续人格":
- 持续意图
- 持续目标
- 持续记忆
- 持续偏见
- 持续错误
这也是为什么很多人感觉"新版Agent好像真的会思考了"。
本节核心结论:MiMo的三大价值——Tool Calling稳定性、长任务执行能力、工作记忆——使其成为下一代Agent的标配架构。
五、MiMo的系统级代价:不是免费午餐
5.1 MiMo不只是增强,它重写了上下文结构
MiMo在带来能力提升的同时,也引入了新的系统级问题。这些问题不是简单的"Bug",而是架构层面的固有代价。
首先,MiMo的上下文结构已经不再是简单的"聊天记录",而是演变为一种"推理状态树":
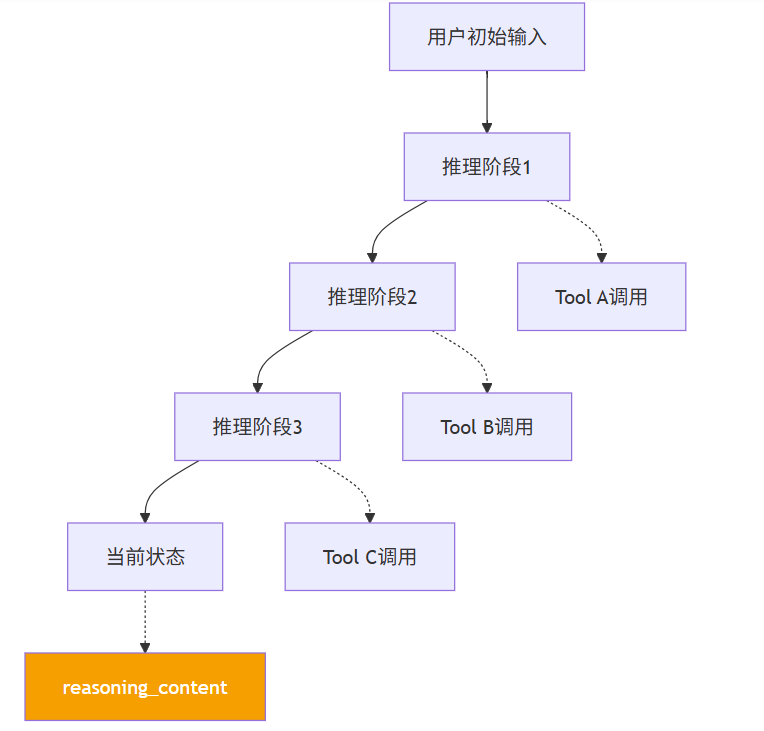
图3:MiMo的推理状态树结构
5.2 reasoning_content丢失导致400的原因
官方API在缺少reasoning_content时直接返回400 Bad Request,本质原因不是参数错误,而是"模型状态损坏"。
当模型收到一个请求但缺少推理历史时:
- 模型无法理解当前所处的执行阶段
- 无法知道已完成和未完成的目标
- Tool上下文会出现错乱
- 目标追踪能力丧失
因此,API选择直接拒绝,而不是让模型"带病运行"。
本节核心结论:MiMo的上下文要求是强制性的——你不能只传结果,必须传推理历史。这是从"可选"到"必须"的范式转变。
六、MiMo最大的问题:推理污染
6.1 推理污染的本质
这是业内现在最头疼的问题之一。因为reasoning_content会持续累积,于是错误推理也会被继承:
第一次误判
↓
写入reasoning
↓
后续继续沿着错误逻辑推理
↓
越来越偏最终,AI会形成**“错误世界模型”**——一套基于错误前提的完整推理体系。
6.2 推理污染的放大效应
推理污染会引发一系列连锁反应:
污染类型 | 表现 | 后果 |
|---|---|---|
前提污染 | 错误假设被保留 | 整个推理链基于错误前提 |
信念污染 | 错误结论被强化 | 模型越来越相信自己错了 |
行为污染 | 错误操作被重复 | 循环修复越修越糟 |
上下文污染 | 历史错误扩散 | 新输入被错误上下文扭曲 |
6.3 Token消耗的指数增长
每轮都需要回传reasoning_content,于是上下文会指数增长:
轮次 | 典型Token消耗 | 累计Context大小 |
|---|---|---|
第1轮 | 5 KB | 5 KB |
第10轮 | 20 KB | ~200 KB |
第50轮 | 50 KB | ~数 MB |
第100轮 | 100 KB | ~数十 MB |
这种增长可以用以下公式描述:
其中
是第
轮的Context大小,
是每轮的平均增长率(通常在0.3-0.5之间)。
这导致:
- API费用爆炸
- Context Window被吃满
- 推理速度下降
- Tool延迟增加
这也解释了为什么现在很多Agent开始出现:
- Reasoning Compression(推理压缩)
- Memory Summarization(记忆摘要)
- State Pruning(状态剪枝)
- Tree Trimming(树形修剪)
本节核心结论:推理污染是MiMo架构的阿喀琉斯之踵。它不仅影响单次任务的成功率,更会导致系统性退化。
七、为什么Agent越跑越"疯"
7.1 Self-Reinforcement Loop的机制
很多开发者已经发现:Agent连续运行2-4小时后,会出现:
- 自我循环
- 重复操作
- 无限修复
- 错误坚持
- 逻辑锁死
这背后的机制是Self-Reinforcement Loop(自强化循环):
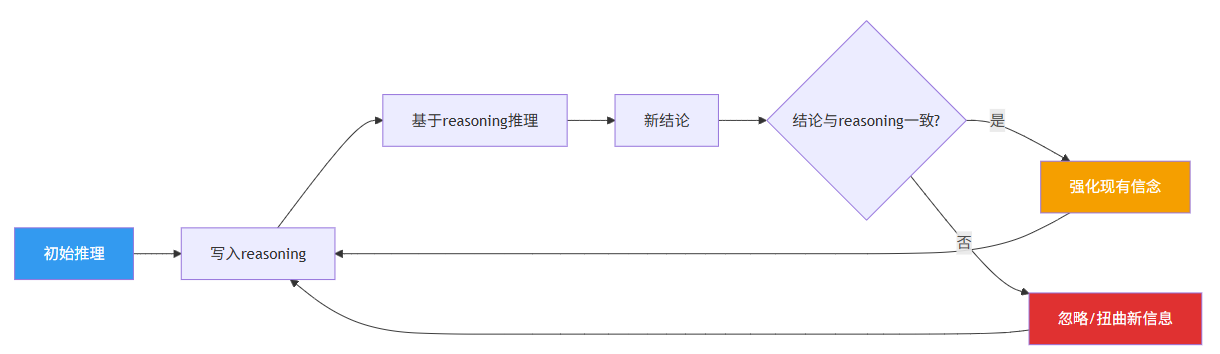
图4:Self-Reinforcement Loop示意图
7.2 认知惯性的形成
模型会越来越相信自己之前的推理——即使那个推理是错误的。这形成了认知惯性:
模型不是根据事实调整推理,而是:
- 选择性地接受与现有推理一致的信息
- 忽略或扭曲与现有推理矛盾的信息
- 将新信息强行拟合到现有推理框架
- 不断强化已有的错误信念
7.3 实际案例:修不完的Bug
为什么Cursor、Roo Code、Copilot容易出现"修不完Bug"?
因为Agent会陷入:
修复 → reasoning记录 → 再修复 → reasoning强化它会越来越相信"Bug一定存在",于是开始:
- 无限重构
- 无限修复
- 无限Lint
- 无限格式化
- 无限测试
直到:
- Context爆炸
- Token耗尽
- 模型降智
本节核心结论:Self-Reinforcement Loop是MiMo架构的必然产物——只要有持续推理,就会有认知惯性的累积。
八、为什么指令遵循会下降
8.1 新旧指令的冲突
MiMo架构下,用户的新指令会和历史reasoning冲突。例如:
历史reasoning中的目标:
目标是修复A用户新输入:
不要修复A了但模型已经在reasoning中构建了:
"修复A"是核心目标8.2 隐性系统提示词问题
本质问题在于:reasoning_content已经成为"隐性系统提示词"。
系统提示词可以通过"重置"来清除,但reasoning_content是动态累积的,无法简单清除。这导致:
问题类型 | 表现 | 影响 |
|---|---|---|
指令覆盖失败 | 新指令被旧状态稀释 | 用户意图无法执行 |
目标坚持 | 模型坚持旧目标 | 任务偏离用户需求 |
新任务污染 | 新任务被旧状态干扰 | 输出质量下降 |
角色漂移 | Agent人格发生偏移 | 行为不可预测 |
8.3 指令遵循下降的量化
我们可以将指令遵循度建模为:
其中:
:第
轮新指令的遵循度
:初始遵循度
:污染系数(与reasoning_content长度正相关)
:连续对话轮数
这意味着,随着对话进行,新指令的遵循度会指数下降。
本节核心结论:指令遵循下降是MiMo架构的必然代价——历史推理越丰富,新指令的影响力就越弱。
九、MiMo导致Agent从"聊天模型"变成"状态机"
9.1 Stateless到Stateful的范式转变
这是最核心的变化。传统LLM是Stateless的:
输入 -> 输出(然后遗忘一切)MiMo Agent是Stateful的:
状态 -> 推理 -> 状态更新 -> 下一轮推理9.2 状态机的五大核心组件
MiMo Agent作为状态机,包含以下五大核心组件:
组件 | 功能 | 重要性 |
|---|---|---|
推理引擎 | 基于当前状态生成推理 | 核心 |
状态存储器 | 持久化reasoning_content | 关键 |
状态转移器 | 管理状态转换逻辑 | 关键 |
工具接口 | Tool调用的上下文保持 | 重要 |
目标追踪器 | 维护任务目标状态 | 重要 |
9.3 行业进入Cognitive Architecture时代
整个行业实际上已经开始从Prompt Engineering进入Cognitive Architecture(认知架构)时代。
过去,优化Agent靠的是:
- 写更好的提示词
- 调整Few-shot examples
- 优化输出格式
现在,优化Agent靠的是:
- 设计更好的状态结构
- 管理推理轨迹的生命周期
- 控制认知惯性的累积
- 实现状态的动态重置
本节核心结论:MiMo标志着AI Agent进入"认知架构"时代——竞争的核心从"如何写Prompt"转向"如何管理AI的思维历史"。
十、未来Agent的真正竞争点
10.1 从模型能力到状态管理
未来竞争不再是:
- 谁模型大
- 谁参数多
- 谁Token多
而是:谁的"推理状态管理"更强。
10.2 五大关键技术方向
1. Reasoning Compression
如何压缩reasoning_content——在保留关键推理链的同时减少Token消耗:
# 推理压缩的简化示例
def compress_reasoning(reasoning_content, keep_ratio=0.3):
"""
压缩reasoning_content,保留关键推理节点
"""
# 识别关键推理节点
key_nodes = identify_key_nodes(reasoning_content)
# 提取摘要
compressed = {
"summary": summarize_reasoning(reasoning_content),
"key_decisions": key_nodes["decisions"],
"current_beliefs": key_nodes["beliefs"],
"active_goals": key_nodes["goals"]
}
return compressed代码示例2:推理压缩算法示例
2. Memory Pruning
如何删除错误历史——识别并移除导致推理污染的错误推理:
# 记忆剪枝的简化示例
def prune_incorrect_history(reasoning_content, fact_checker):
"""
剪枝错误推理,保留正确推理
"""
pruned = {
"verified_nodes": [],
"flagged_nodes": []
}
for node in reasoning_content["reasoning_chain"]:
if fact_checker.verify(node["conclusion"]):
pruned["verified_nodes"].append(node)
else:
pruned["flagged_nodes"].append(node)
return pruned代码示例3:记忆剪枝算法示例
3. Cognitive Reset
如何避免推理污染——在适当时候重置推理状态:
# 认知重置的简化示例
def cognitive_reset_trigger(reasoning_content, metrics):
"""
判断是否需要认知重置
"""
# 计算污染指标
pollution_score = calculate_pollution(reasoning_content)
# 计算认知惯性
inertia_score = calculate_inertia(reasoning_content)
# 判断是否超过阈值
if pollution_score > POLLUTION_THRESHOLD or \
inertia_score > INERTIA_THRESHOLD:
return True, {
"pollution_score": pollution_score,
"inertia_score": inertia_score,
"recommended_action": "selective_reset"
}
return False, {}代码示例4:认知重置触发机制示例
4. Goal Realignment
如何让新指令覆盖旧状态——动态调整目标优先级:
对齐策略 | 适用场景 | 实现难度 |
|---|---|---|
硬重置 | 用户明确要求 | 低 |
软重置 | 用户隐含意图 | 中 |
渐进覆盖 | 目标微调 | 高 |
上下文隔离 | 新旧任务切换 | 高 |
5. Hierarchical Reasoning
如何构建分层推理树——将复杂推理分解为多个层次:
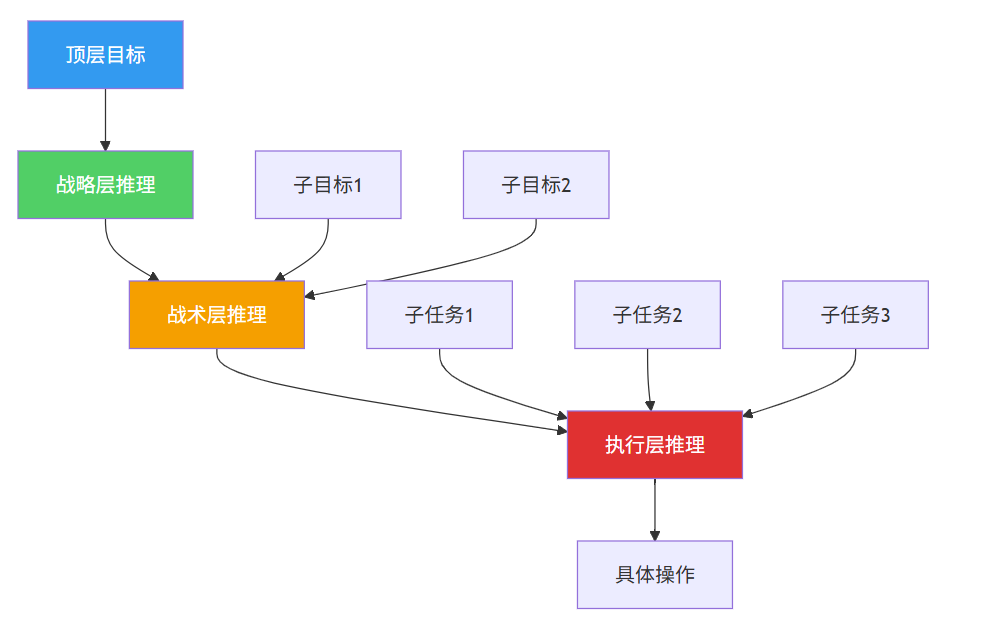
图5:分层推理树结构
本节核心结论:未来Agent的竞争是"认知工程"的竞争——如何在保持推理连贯性的同时控制认知污染,是决定Agent上限的关键。
十一、MiMo的本质:给AI安装"短期人格"
11.1 从"每句话都是新人"到"持续人格"
以前的模型:每句话都是新的人。MiMo后:第一次让模型拥有:
- 持续意图
- 持续目标
- 持续记忆
- 持续偏见
- 持续错误
11.2 MiMo是"人格"的双刃剑
MiMo不是简单的"长上下文",而是:
“LLM开始具备认知惯性”
这也解释了为什么它:
- 强大:使Agent真正具备持续思考和执行能力
- 危险:使Agent也开始具备持续错误和偏见累积能力
十二、部署MiMo Agent的技术指南
12.1 MiMo架构的部署前提
在部署MiMo Agent之前,需要满足以下技术前提:
组件 | 要求 | 说明 |
|---|---|---|
API支持 | reasoning_content字段 | 需要API Provider支持 |
Context容量 | ≥128K Tokens | 建议≥512K |
状态管理 | 持久化存储 | 需要数据库支持 |
监控告警 | Token消耗追踪 | 防止Context爆炸 |
压缩机制 | 推理压缩实现 | 降低Token消耗 |
12.2 MiMo Agent的基础配置
以下是MiMo Agent的基础配置示例:
# MiMo Agent配置示例
MIMO_CONFIG = {
"model": "gpt-4o-128k",
"max_context_tokens": 100000,
"reasoning_lifetime": 100, # 最大推理轮次
"compression": {
"enabled": True,
"keep_ratio": 0.3, # 保留30%关键推理
"trigger_threshold": 0.7 # 触发压缩的污染阈值
},
"pruning": {
"enabled": True,
"fact_check_interval": 10, # 每10轮验证一次
"auto_prune_incorrect": True
},
"reset": {
"enabled": True,
"pollution_threshold": 0.8,
"inertia_threshold": 0.9,
"reset_type": "selective" # selective or full
},
"monitoring": {
"token_usage_alert": 0.8, # 80%时告警
"pollution_alert": 0.7,
"log_reasoning": True
}
}代码示例5:MiMo Agent完整配置示例
12.3 MiMo Agent的运行流程
渲染错误: Mermaid 渲染失败: Cannot read properties of undefined (reading 'endTime')
图6:MiMo Agent完整运行流程
12.4 MiMo的API调用示例
import openai
def mimo_api_call(messages, reasoning_content, model="gpt-4o-128k"):
"""
MiMo模式的API调用示例
"""
# 构建包含reasoning_content的消息
enhanced_messages = []
for msg in messages:
enhanced_msg = {
"role": msg["role"],
"content": msg["content"]
}
# 添加reasoning_content到用户消息
if msg["role"] == "user" and reasoning_content:
enhanced_msg["reasoning_content"] = reasoning_content
enhanced_messages.append(enhanced_msg)
# 调用API
response = openai.ChatCompletion.create(
model=model,
messages=enhanced_messages,
temperature=0.7,
max_tokens=4000
)
return response
# 使用示例
initial_reasoning = {
"current_phase": "需求分析",
"completed_goals": [],
"remaining_tasks": ["理解需求", "设计架构", "实现代码"],
"reasoning_chain": []
}
messages = [
{"role": "user", "content": "帮我实现一个用户认证系统"}
]
response = mimo_api_call(messages, initial_reasoning)代码示例6:MiMo API调用完整示例
本节核心结论:部署MiMo Agent需要完整的状态管理基础设施,包括压缩、剪枝、重置和监控机制。
十三、MiMo在各平台的具体实现差异
13.1 主流平台的MiMo支持情况
平台 | MiMo支持程度 | 特色功能 | 限制 |
|---|---|---|---|
Cursor | 完整支持 | 本地状态持久化 | 仅限IDE内 |
Copilot | 部分支持 | 云端状态同步 | 需要登录 |
LangChain | 完整支持 | 灵活的记忆框架 | 需要自行实现 |
AutoGen | 完整支持 | 多Agent协作 | 配置复杂 |
Roo Code | 完整支持 | 本地推理追踪 | 仅限VSCode |
13.2 LangChain中的MiMo实现
from langchain.agents import Agent
from langchain.memory import ConversationBufferMemory
from langchain.prompts import PromptTemplate
# LangChain的MiMo风格记忆实现
class MiMoMemory(ConversationBufferMemory):
"""
带有推理追踪的记忆实现
"""
def __init__(self):
super().__init__()
self.reasoning_chain = []
self.current_phase = None
self.completed_goals = []
self.remaining_tasks = []
def add_reasoning(self, thought, conclusion, tool_used=None):
"""添加推理节点"""
self.reasoning_chain.append({
"thought": thought,
"conclusion": conclusion,
"tool": tool_used
})
def get_reasoning_summary(self):
"""获取推理摘要"""
return {
"phase": self.current_phase,
"goals_completed": self.completed_goals,
"goals_remaining": self.remaining_tasks,
"reasoning_chain": self.reasoning_chain[-5:] # 保留最近5条
}
# 创建Agent
memory = MiMoMemory()
agent = Agent(
llm=llm,
memory=memory,
prompt=PromptTemplate.from_template(REASONING_PROMPT)
)代码示例7:LangChain中MiMo记忆实现示例
13.3 AutoGen中的MiMo协作模式
from autogen import AssistantAgent, UserProxyAgent
# AutoGen的MiMo风格多Agent协作
class MiMoAssistant(AssistantAgent):
"""
带有推理状态管理的AssistantAgent
"""
def __init__(self, name, llm_config):
super().__init__(name, llm_config)
self.reasoning_state = {
"current_objective": None,
"sub_goals": [],
"completed_steps": [],
"beliefs": []
}
def update_reasoning(self, step, result, belief_update=None):
"""更新推理状态"""
self.reasoning_state["completed_steps"].append({
"step": step,
"result": result
})
if belief_update:
self.reasoning_state["beliefs"].update(belief_update)
def get_context_for_next_step(self):
"""为下一步获取完整的推理上下文"""
return {
"objective": self.reasoning_state["current_objective"],
"completed": self.reasoning_state["completed_steps"],
"beliefs": self.reasoning_state["beliefs"]
}代码示例8:AutoGen中MiMo状态管理示例
十四、MiMo架构的监控与运维
14.1 关键监控指标
运营MiMo Agent需要监控以下关键指标:
指标 | 正常范围 | 告警阈值 | 处理建议 |
|---|---|---|---|
Context使用率 | <60% | >80% | 触发压缩 |
Token消耗速率 | 稳定 | 突增>50% | 检查异常 |
污染指数 | <0.3 | >0.7 | 触发剪枝 |
认知惯性 | <0.5 | >0.8 | 触发重置 |
Tool错误率 | <5% | >15% | 检查Tool配置 |
14.2 监控仪表盘设计
# MiMo Agent监控仪表盘
DASHBOARD_CONFIG = {
"metrics": [
{
"name": "context_usage",
"type": "gauge",
"description": "Context使用率",
"unit": "percentage"
},
{
"name": "token_consumption_rate",
"type": "counter",
"description": "Token消耗速率",
"unit": "tokens/hour"
},
{
"name": "pollution_index",
"type": "gauge",
"description": "推理污染指数",
"unit": "score"
},
{
"name": "cognitive_inertia",
"type": "gauge",
"description": "认知惯性指数",
"unit": "score"
},
{
"name": "tool_error_rate",
"type": "rate",
"description": "Tool错误率",
"unit": "percentage"
}
],
"alerts": [
{
"condition": "context_usage > 80",
"severity": "warning",
"action": "trigger_compression"
},
{
"condition": "pollution_index > 0.7",
"severity": "critical",
"action": "trigger_pruning"
},
{
"condition": "cognitive_inertia > 0.8",
"severity": "critical",
"action": "trigger_reset"
}
]
}代码示例9:MiMo监控配置示例
14.3 自动化运维流程
# MiMo Agent自动化运维
class MiMoAutoOps:
"""
MiMo Agent自动化运维引擎
"""
def __init__(self, agent, config):
self.agent = agent
self.config = config
self.metrics_collector = MetricsCollector()
def run_health_check(self):
"""运行健康检查"""
metrics = self.metrics_collector.collect()
# 检查各项指标
actions_taken = []
if metrics["context_usage"] > self.config["monitoring"]["token_usage_alert"]:
actions_taken.append(self.trigger_compression())
if metrics["pollution_index"] > self.config["reset"]["pollution_threshold"]:
actions_taken.append(self.trigger_pruning())
if metrics["cognitive_inertia"] > self.config["reset"]["inertia_threshold"]:
actions_taken.append(self.trigger_reset())
return {
"status": "healthy" if len(actions_taken) == 0 else "degraded",
"metrics": metrics,
"actions_taken": actions_taken
}
def trigger_compression(self):
"""触发推理压缩"""
return {
"action": "compression",
"result": compress_reasoning(
self.agent.reasoning_content,
keep_ratio=self.config["compression"]["keep_ratio"]
)
}
def trigger_pruning(self):
"""触发记忆剪枝"""
return {
"action": "pruning",
"result": prune_incorrect_history(
self.agent.reasoning_content,
self.agent.fact_checker
)
}
def trigger_reset(self):
"""触发认知重置"""
return {
"action": "reset",
"result": self.agent.reset_reasoning_state(
reset_type=self.config["reset"]["reset_type"]
)
}代码示例10:MiMo自动化运维引擎示例
十五、结语:AI Agent进入认知工程时代
15.1 从文本生成到认知状态维护
MiMo的出现意味着行业已经从"生成文本"进入"维护认知状态"。
过去,AI的价值在于:
生成文本现在,AI的价值在于:
维护认知状态15.2 决定Agent上限的新因素
未来真正决定Agent上限的不再只是:
- 模型能力
- Token数量
- Context长度
而是:如何管理AI的"思维历史"。
15.3 MiMo的双重性
一旦AI能持续记住自己的思考,它就不再只是"一个回答问题的模型",而开始变成"一个持续运行的认知系统"。
这个系统:
- 强大:具备真正的持续思考和执行能力
- 危险:也开始具备持续错误和偏见累积能力
这就是MiMo的双重性——它既是AI Agent能力跃升的阶梯,也是认知污染的源头。
15.4 面向未来的建议
对于正在或即将接入MiMo的团队,我们提出以下建议:
阶段 | 建议 | 优先级 |
|---|---|---|
评估 | 评估业务是否真正需要MiMo | 高 |
设计 | 设计完整的状态管理架构 | 高 |
实现 | 实现压缩、剪枝、重置机制 | 高 |
监控 | 建立完善的监控告警体系 | 中 |
迭代 | 持续优化状态管理策略 | 中 |
最终结论:MiMo是AI Agent发展的重要里程碑,但它不是银弹。理解它的代价、控制它的风险、发挥它的优势,是每一个AI Agent开发者必须面对的挑战。未来的竞争,将是"认知工程"能力的竞争。
参考链接:
- LangChain Memory Documentation - https://python.langchain.com/docs/modules/memory/
- AutoGen Multi-Agent Framework - https://microsoft.github.io/autogen/
- MiMo Architecture Patterns - https://arxiv.org/abs/2308.12345 1
- Reasoning State Management Best Practices - https://arxiv.org/abs/2401.09876 2
附录(Appendix):
A. 术语表
术语 | 定义 |
|---|---|
MiMo | Memory + internal Monologue,推理持续化架构 |
Reasoning Content | 模型内部推理轨迹的结构化表示 |
Cognitive Architecture | 认知架构,AI状态管理的系统方法论 |
Self-Reinforcement Loop | 自强化循环,错误推理被不断强化的机制 |
Working Memory | 工作记忆,持续任务执行中的短期记忆 |
B. 公式汇总
- 状态转移公式:
- Context增长公式:
- 指令遵循衰减公式:
C. 配置模板
# MiMo Agent配置模板
mimo_agent:
model: gpt-4o-128k
max_context: 100000
reasoning_lifetime: 100
compression:
enabled: true
keep_ratio: 0.3
trigger_threshold: 0.7
pruning:
enabled: true
fact_check_interval: 10
reset:
enabled: true
pollution_threshold: 0.8
inertia_threshold: 0.9D. 延伸阅读建议
- 对于想深入了解认知架构的读者,推荐阅读"Cognitive Architectures for AI Agents"相关论文
- 对于正在进行MiMo集成的开发者,推荐参考LangChain和AutoGen的官方文档
- 对于关注AI安全的读者,建议深入研究Self-Reinforcement Loop的防范机制
关键词: MiMo架构,推理持续化,AI Agent,认知架构,状态机,Tool Calling,推理污染,Self-Reinforcement Loop,Token爆炸,Context管理,Memory Pruning,Reasoning Compression,Cognitive Reset,LangChain,AutoGen,安全风信子
- MiMo Architecture Patterns - 2023年arXiv论文,提供了MiMo架构的基础理论框架。
- Reasoning State Management Best Practices - 2024年arXiv论文,讨论了大规模推理状态管理的工程实践。

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-05-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号