AI 收费时代来了:别让 Token 白白烧掉

AI 收费时代来了:别让 Token 白白烧掉

AI 生命克劳德
发布于 2026-05-12 09:56:46
发布于 2026-05-12 09:56:46
如果你最近还觉得 AI 可以随便用,豆包这次付费测试算是一个警钟。
据媒体报道,豆包 App Store 页面出现了付费版本服务说明:标准版包月 68 元,加强版包月 200 元,专业版包月 500 元。豆包官方回应也比较克制:基础服务会继续保留免费,更多增值服务还在测试阶段,主要面向 PPT 生成、数据分析、影视制作这类复杂生产力场景。
真正值得注意的是:当 AI 从聊天工具变成 Agent,它每一次观察、推理、试错、回退,都在消耗 Token。
你以为自己只是多问了几句。系统背后可能已经跑过一串模型调用、页面截图、工具调用、结果校验和路径重试。
所以这篇文章只解决一个问题:
以后怎么别让 Token 白白烧掉。
你读完至少能拿走三件事:
- 哪些任务不该直接交给 Agent;
- 为什么 AI 会在“反复摸路”里烧掉成本;
- 怎么把高频任务沉淀成 Prompt、SOP、模板和 Skill。
这篇不是劝你少用 AI。
我更想讨论的是:怎么把 AI 用得更清楚、更省。
成本藏在反复摸路里
过去一年,很多人对 AI 的体感是免费、随便用。但只要你真的用 AI 做复杂任务,就会发现它和普通软件不一样。
普通软件运行一次,边际成本很低。AI 每多读一段上下文,每多推理一步,每多尝试一条路径,都在消耗 Token、推理时间和算力。
尤其到了 Agent 阶段,这个问题会更明显。
你让 AI 帮你操作网页、查资料、填表、分析数据,它已经不只是回答一句话。
它要观察页面,理解当前状态,决定下一步,执行动作,检查结果,失败后再重新尝试。
用户看到的是“AI 正在帮我干活”。
但真正烧钱的地方,常常藏在那些看不见的重复动作里:反复理解同一个任务,重新探索同一个网页,重新猜同一个输出格式。
这就是 Token 被白白烧掉的入口。
Autobrowse 讲清了一个问题
Browserbase 最近发布的 Autobrowse,讲的正是这个问题。
它指出浏览器 Agent 有一个典型问题:失忆。
Agent 第一次进入一个网站,要探索页面、识别按钮、理解结构、找到路径,这很正常。第一次探索有学习成本。
真正的问题出现在第二次、第三次,甚至第一百次执行类似任务时。
如果它还要重新探索同一个网站、重新理解同一类页面、重新猜测同一个按钮,成本就开始被浪费。
这就像你雇了一个员工,每天上班都要重新培训一次。
Autobrowse 的做法,是让 Agent 在真实网站上完成真实任务,然后读取自己的执行记录。
它会分析哪里走了弯路,哪里浪费了 Token,哪里可以用更确定的方式解决。等路径稳定以后,再把成功经验沉淀成一个 Skill。
第一次探索可以贵,但贵得要有价值。它不能只换来一次结果,还应该换来下次更省、更稳定的路径。
官方案例里,Craigslist 任务从大约 0.22 美元、71 秒,降到大约 0.12 美元、27 秒。另一个表单任务,从每次 1.40 美元降到 0.24 美元。
成本下降的原因很直接:系统减少了无效探索。
这件事对普通用户也有启发:省 Token 的核心,不是少问两句话,重点是减少 AI 的重复理解、重复猜测和重复试错。
有些任务,不值得上 Agent
Autobrowse 还有一个反面案例,很适合提醒我们。
一个 167 行的静态 HTML 表格,本来用 fetch 加 Python 就能处理。
结果他们让高自治 Agent 跑了几轮,花了大约 24 美元还没完整做完。后来换成确定性脚本,几乎不需要推理成本就解决了。
这个例子很扎心。
问题不在 AI 能力,问题在工具用错了。
能用确定性工具解决的,不要交给大模型反复思考。我的建议是记住这四句话:
静态网页,先 fetch。 结构化数据,先表格或脚本。 固定格式,先模板。 复杂判断,再让 Agent 上场。
很多人用 AI 成本高,根源常常在任务分配太粗糙。
所有问题都交给大模型,成本自然会被抬高。
使用 AI 前,先做一次分流
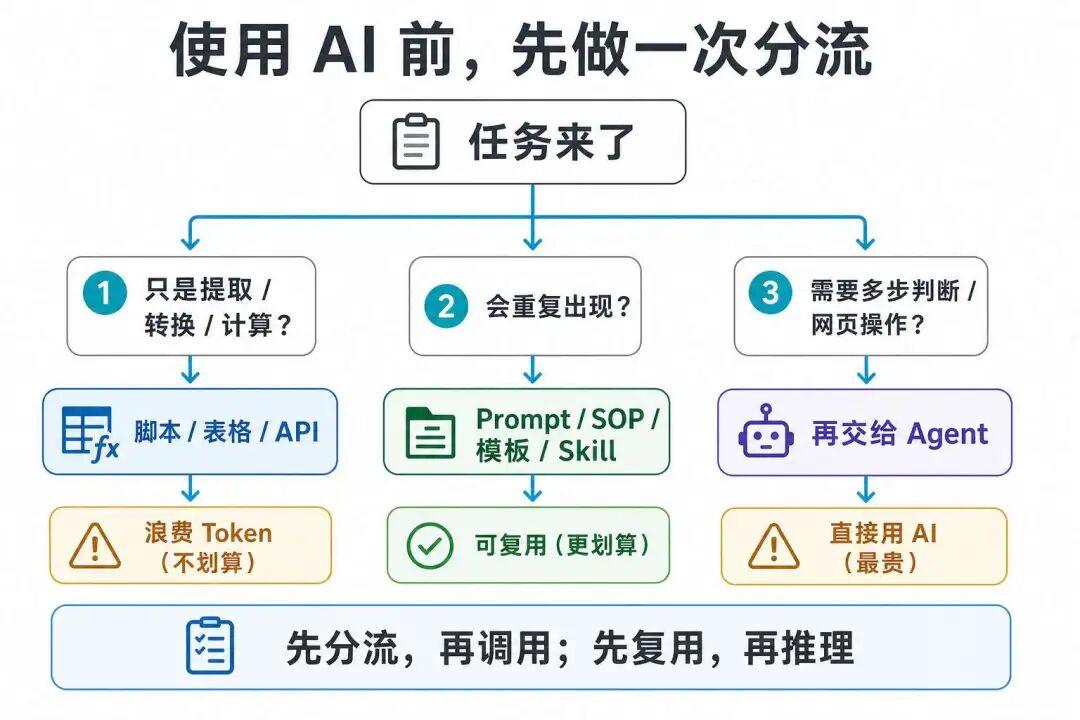
以后每次使用 AI 前,可以先停 10 秒,做一次简单分流。
先问:这件事需要判断,还是只是处理?
如果只是提取、转换、整理、计算,优先用脚本、表格、规则、API。大模型适合处理不确定性,不适合承担所有机械劳动。
再问:这件事以后会不会重复?
如果一周会做两次以上,就别每次重新提问。
周报、选题、会议纪要、资料整理、竞品分析,都应该有稳定输入和稳定输出。你要沉淀的不是某一次答案,重点是一套下次还能用的流程。
最后问:这次任务完成后,有没有留下下次能复用的东西?
如果只有一个结果,那就是一次性消费。如果留下了流程、模板、检查清单、脚本、提示词和 Skill,它才开始变成资产。
这里有一个很简单的动作:每次 AI 帮你完成复杂任务后,不要急着关掉对话,补一句:
请把这次任务整理成下次可复用的操作手册,并标出哪些步骤可以减少 Token 消耗。
这句话很实用。
因为 AI 浪费 Token 的地方,往往不在最终输出,而在中间过程:反复确认目标、反复理解格式、反复寻找路径、反复修正错误。
你把中间过程沉淀下来,下次自然会更省。
上下文给太多,也会变贵
还有一个常见误区:给 AI 的资料越多,结果越好。
实际使用中,上下文越乱,AI 找重点的成本越高,跑偏概率也越大。
更好的方式是分阶段。
先让它理解目标,再让它整理材料;先输出结构,再生成正文或结果;最后单独做检查和修订。
每一步只给必要上下文,每一步都有明确输出。这样不只是省 Token,也能减少返工。
这其实是工程里的常识:不要把所有问题都交给高成本、不确定性更强的模块。
AI 时代,只是把这个问题摆到了每个普通用户面前。
省 Token,是管理成本
豆包开始测试收费以后,很多人会开始关心“我要不要付费”。
但我觉得更重要的问题是:你有没有能力把 AI 用得更省。
省 Token 不是抠门。它本质上是在减少无效沟通、减少重复试错、减少每次从头开始。
未来 AI 产品收费会越来越常见,Agent 也会越来越强。越强的 Agent,越容易在后台做大量你看不见的推理和尝试。
如果你没有自己的流程,它每次都要重新理解你。
如果你没有自己的模板,它每次都要重新猜格式。
如果你没有自己的 Skill,它每次都要重新探索路径。
这样用 AI,成本一定会越来越高。
真正成熟的 AI 使用方式,是把每次成功经验沉淀下来。
Prompt 是资产,模板是资产,脚本是资产,SOP 是资产,Skill 也是资产。
Token 是账单,流程才是长期生产资料。
以后判断一个 AI 工作流是否成熟,可以看一个标准:任务完成以后,它有没有留下下次可复用的东西。
没有沉淀,每一次调用都在消费。
有了沉淀,每一次调用都在让你的系统变厚。
《AI成本账》,从这篇开始
这篇文章算是一个开篇。大家兴趣较大的话,我就准备把这个方向做成一个小专栏,名字想好了叫《AI成本账》。
这个专栏不只是聊“哪个 AI 工具便宜”。我更想记录的是:普通人和开发者,怎么用更少的 Token、更少的订阅、更少的试错,搭建更可复用的 AI 工作流,优化大家对于AI的投入产出。AI 成本节约不是抠门,而是用成本意识倒逼工作流升级。真正成熟的 AI 使用,不是每次都让模型重新理解世界,而是把高频任务、稳定经验和个人偏好沉淀成可复用的能力系统。
这个系列主要写给几类人:
- 已经开始为 AI 工具付费,但不知道怎么选的人;
- 经常用 ChatGPT、Claude、Cursor、Codex,但感觉成本越来越高的人;
- 想把 AI 放进工作流里,而不是偶尔玩一玩的人;
- 开发者、内容创作者、知识工作者、独立开发者;
- 对 Agent、Skill、自动化、个人生产力系统感兴趣的人。
结合最近的热点和讨论,我先列 6 个后续选题,大家如果不满意可以抛出自己使用AI的成本痛点一起探讨一下:
- AI 会员怎么选:ChatGPT、Claude、豆包、Cursor 这些订阅,到底哪些值得长期付费?
- Tokenmaxxing 的陷阱:为什么用掉更多 Token,不一定带来更高产出?
- Prompt Caching 到底怎么省钱:为什么稳定上下文比反复复制粘贴更重要?
- AI 编程助手怎么省钱:Codex、Claude Code、Cursor 这类工具,成本到底花在哪里?
- 什么时候该用 Agent,什么时候该用脚本:别把所有任务都交给大模型。
- 普通人的 AI 工具预算表:一个月到底该为 AI 花多少钱,怎么配才不浪费?
这些题背后,其实都是同一个问题:
AI 会越来越强,也会越来越贵。普通人真正需要的,不是盲目追新工具,而是学会管理自己的 AI 使用成本。
往期相关推荐
OpenAI Codex团队推崇新开发模式
Codex 新增 /goal 后,AI 编程更像带人干活了
你和高手用 AI 的差距,不在模型
资料来源
- Browserbase:《Autobrowse: The Mythos moment for Browser Agents is here》
- Browserbase:《We built caching into Stagehand. Here's how it works》
- Jellyfish:《Is “tokenmaxxing” cost effective? New data from Jellyfish explains.》
- IT之家:《豆包将在免费模式外新增付费订阅:68 元 / 200 元 / 500 元三档,主打生产力场景》
- The Verge:《You’re about to feel the AI money squeeze》
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号