Ofa_Visual-Question-Answering_Pretrain_Large_En:大规模预训练视觉问答模型的技术基准

Ofa_Visual-Question-Answering_Pretrain_Large_En:大规模预训练视觉问答模型的技术基准

安全风信子
发布于 2026-04-27 08:18:21
发布于 2026-04-27 08:18:21
作者: HOS(安全风信子) 日期: 2026-04-26 主要来源平台: HuggingFace/ModelScope 摘要: Ofa_Visual-Question-Answering_Pretrain_Large_En 是基于 OFA(One-For-All)统一多模态预训练范式构建的大规模视觉问答模型,在 VQA v2 test-dev 基准上达到 82.0% 准确率,展现了序列到序列(Seq2Seq)框架在多任务统一建模方面的卓越潜力1。该模型采用 Transformer Encoder-Decoder 作为核心架构,在仅使用 2000 万公开图像-文本配对数据进行预训练的条件下,即可实现与依赖数十亿级跨模态数据的模型相媲美的性能2。本文将从 OFA 的统一架构设计理念入手,深入剖析其在大规模预训练阶段的任务配置与训练策略,解析视觉问答能力的涌现机制,并探讨该模型在研究生态与产业应用中的技术价值与未来演进方向。通过对模型结构、训练目标、推理流程及性能基准的全面解构,揭示 OFA 作为任务无关(Task-Agnostic)与模态无关(Modality-Agnostic)通用多模态框架的设计精髓,为多模态学习研究提供系统性的技术参考。
目录- 一、OFA 预训练范式的设计理念
- 1.1 统一多模态学习的核心诉求
- 1.2 序列到序列统一架构的技术优势
- 1.3 指令驱动学习的范式创新
- 二、大规模预训练技术详解
- 2.1 预训练数据集与规模配置
- 2.2 多任务预训练目标体系
- 2.3 Transformer 架构配置与参数设计
- 2.4 预训练策略与优化配置
- 2.5 多模态特征对齐的数学表达
- 三、视觉问答核心能力分析
- 3.1 VQA 任务的本质挑战
- 3.2 OFA 在 VQA 任务上的性能表现
- 3.3 答案生成的开放域处理机制
- 3.4 跨粒度视觉推理能力
- 3.5 模型推理流程与实现细节
- 3.6 可解释性与注意力可视化
- 四、研究应用与技术生态
- 4.1 研究领域的多模态基础模型演进
- 4.2 产业应用场景与实践案例
- 4.3 模型部署与优化实践
- 4.4 开源生态与模型变体
- 4.5 未来演进方向与技术挑战
- 4.6 技术生态的协同发展
- 结论
- A.1 OFA-Large 超参数配置完整列表
- A.2 VQA 任务性能评估指标说明
- A.3 环境配置与依赖安装
- A.4 公式推导补充
- 1.1 统一多模态学习的核心诉求
- 1.2 序列到序列统一架构的技术优势
- 1.3 指令驱动学习的范式创新
- 2.1 预训练数据集与规模配置
- 2.2 多任务预训练目标体系
- 2.3 Transformer 架构配置与参数设计
- 2.4 预训练策略与优化配置
- 2.5 多模态特征对齐的数学表达
- 3.1 VQA 任务的本质挑战
- 3.2 OFA 在 VQA 任务上的性能表现
- 3.3 答案生成的开放域处理机制
- 3.4 跨粒度视觉推理能力
- 3.5 模型推理流程与实现细节
- 3.6 可解释性与注意力可视化
- 4.1 研究领域的多模态基础模型演进
- 4.2 产业应用场景与实践案例
- 4.3 模型部署与优化实践
- 4.4 开源生态与模型变体
- 4.5 未来演进方向与技术挑战
- 4.6 技术生态的协同发展
- A.1 OFA-Large 超参数配置完整列表
- A.2 VQA 任务性能评估指标说明
- A.3 环境配置与依赖安装
- A.4 公式推导补充
一、OFA 预训练范式的设计理念
1.1 统一多模态学习的核心诉求
在深度学习的发展历程中,视觉与语言的多模态融合长期面临架构碎片化的困境。传统方法针对不同任务(如图像Captioning、VQA、Visual Grounding 等)设计专用的网络结构与损失函数,导致模型难以跨任务迁移,且增加了计算资源的重复消耗3。OFA(One-For-All)框架的提出正是为了解决这一根本性矛盾——通过构建一个统一的知识表示空间,使单一模型能够同时处理多种跨模态和单模态任务。
OFA 的设计哲学可以归纳为三个核心原则:任务无关性(Task-Agnostic)、模态无关性(Modality-Agnostic)以及任务全面性(Task Comprehensiveness)4。任务无关性意味着模型在预训练和微调阶段均采用基于指令的学习方式,无需为下游任务添加额外的任务特定层;模态无关性则要求模型能够自然地处理跨模态(图像-文本)、视觉(图像)和语言(文本)等多种数据模态;任务全面性追求在单一框架内统一尽可能多的跨模态和单模态任务。
这种设计理念的创新性在于:它放弃了传统多模态模型中常见的跨模态对齐模块或任务特定注意力的复杂设计,转而采用最朴素的序列到序列学习框架作为统一接口。图像块(Patch)、文本词元(Token)乃至位置编码在进入统一 Transformer 主干网络之前,被编码为连续的向量表示,随后在统一的生成式框架下完成跨模态信息的深度融合与目标输出序列的生成。
1.2 序列到序列统一架构的技术优势
OFA 选择 Transformer Encoder-Decoder 作为其统一架构,这一选择在技术上具有深远的影响。从信息流的角度看,Encoder 负责将来自不同模态的输入序列编码为高维语义表示,Decoder 则基于这些表示自回归地生成目标序列5。这种架构天然适合处理多模态融合任务,因为无论输入是"图像+问题"还是纯文本,模型的接口形式保持一致。
具体而言,对于 VQA 任务,OFA 将输入图像经由 CNN backbone 提取的图像特征序列与问题文本的特征序列拼接后送入 Encoder,Decoder 则以自回归方式逐步生成答案文本序列。这种端到端的处理方式避免了传统 VQA 模型中常见的两步走策略(如先检测图像区域,再进行答案推理的级联结构),从而降低了模型复杂度与推理延迟。
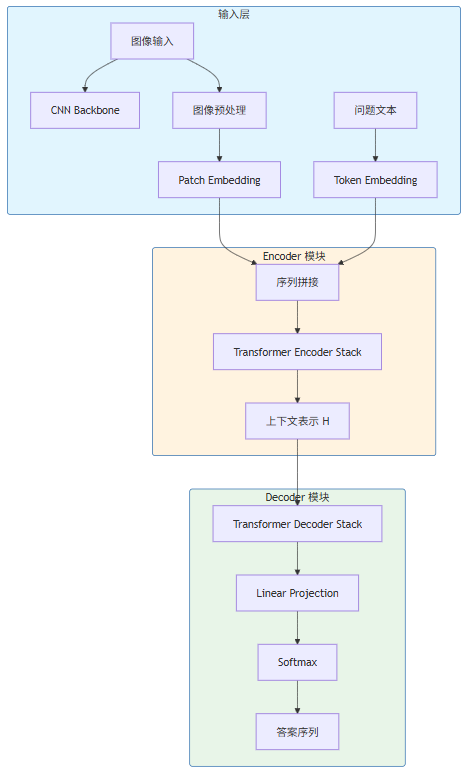
图 1:OFA 视觉问答任务的序列到序列处理流程
上方的流程图清晰展示了 OFA 在处理 VQA 任务时的信息流动路径。值得注意的是,在预训练阶段,OFA 的 Decoder 可以同时学习生成图像描述、回答问题、执行视觉定位等多种不同形式的目标序列——正是这种多任务联合学习机制,使得模型能够在参数层面建立视觉概念与语言表达之间的深层对应关系。
1.3 指令驱动学习的范式创新
OFA 在训练策略上采用了 Instruction-based Learning(指令驱动学习),这一策略对模型的泛化能力至关重要。在预训练阶段,模型不仅学习图像与文本之间的统计对应关系,还学习理解"任务指令"的语义。例如,当输入序列以"Describe the image:"为前缀时,模型需要生成图像描述;以"What is in the image?"为前缀时,则需要回答关于图像内容的问题6。
这种指令格式的设计使得 OFA 能够在下游任务中实现零样本(Zero-shot)迁移。当模型面对未见过的任务类型时,只需将新任务重新表述为符合预训练格式的指令,即可利用学习到的通用多模态表示进行推理。这与 GPT 系列模型在语言领域展现的涌现能力(Emergent Abilities)具有相似的机制——通过大规模预训练与多样化任务分布,模型逐渐发展出对语言与视觉概念的深层理解。
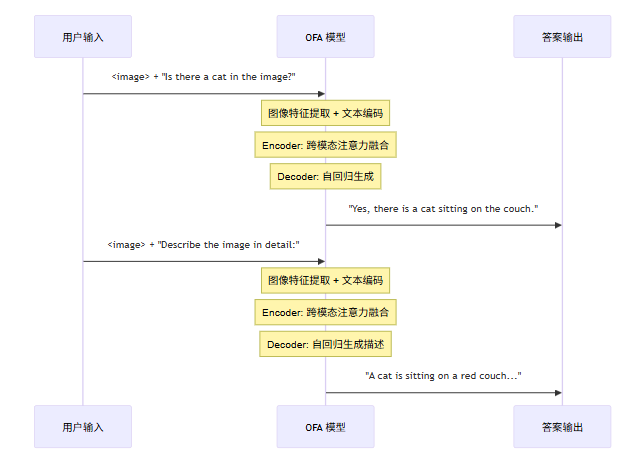
图 2:OFA 指令驱动学习的零样本迁移机制
二、大规模预训练技术详解
2.1 预训练数据集与规模配置
OFA 的一大技术亮点在于其预训练数据的规模效率。与近期依赖超过 10 亿级图像-文本配对数据的跨模态模型(如 Google 的 ALIGN、Microsoft 的 Florence)相比,OFA 仅使用约 2000 万公开可用的图像-文本对进行预训练,即达到了与这些超大规模模型相当的性能水平2。
预训练数据集的构成涵盖了多个公开数据集的融合,包括但不限于 COCO Captions、Visual Genome、VG Captions、Flickr30k 等图像描述数据集,以及从互联网上收集的部分图像-文本配对数据。这种混合数据策略确保了预训练阶段任务多样性的充分覆盖,为模型提供了丰富的跨模态学习信号。
数据集类型 | 样本规模 | 主要任务覆盖 | 数据来源 |
|---|---|---|---|
COCO Captions | ~5M 图像-描述对 | Image Captioning, VQA | 公开数据集 |
Visual Genome | ~100K 图像 + 描述/QA | Visual Grounding, VQA | 公开数据集 |
Flickr30k | ~31K 图像-描述对 | Image Captioning, ITM | 公开数据集 |
Web Data | ~15M 图像-文本对 | 语言建模, ITM | 互联网采集 |
表 1:OFA 预训练数据集配置2
2.2 多任务预训练目标体系
OFA 的预训练阶段设计了系统化的多任务学习框架,覆盖跨模态理解、视觉生成与语言建模三大维度。具体而言,预训练任务被划分为以下几个核心类别3:
跨模态表示学习任务包含五个关键子任务:
- Visual Grounding (VG):根据文本描述定位图像中的对应区域
- Grounded Captioning (GC):生成描述图像特定区域的文本
- Image-Text Matching (ITM):判断图像与文本是否匹配(二分类)
- Image Captioning (IC):为图像生成自然语言描述
- Visual Question Answering (VQA):针对图像回答自由形式的文本问题
单模态与生成任务进一步扩展了模型的能力边界:
- Language Modeling (LM):纯文本的语言建模任务
- Image Generation:基于文本描述生成图像(可选配置)
- Text Generation:无条件或条件下的文本生成
这种多任务预训练策略的深层动机在于:不同的预训练任务从不同角度提供跨模态对齐信号。例如,ITM 任务强制模型学习全局语义对应关系,而 VQA 任务则要求模型捕捉细粒度的视觉细节与语义推理能力。通过多任务联合学习,OFA 的参数在优化过程中逐步建立起对视觉与语言概念的通用表示。
2.3 Transformer 架构配置与参数设计
OFA 提供从 Tiny 到 Huge 多种规模的模型配置,以 OFA-Large 为例,其核心架构参数配置如下表所示7:
组件类型 | 参数名称 | OFA-Large 配置 |
|---|---|---|
Encoder | 层数 (N) | 12 |
Encoder | 隐层维度 (d_model) | 1024 |
Encoder | 注意力头数 (h) | 16 |
Encoder | 前馈网络维度 (d_ff) | 4096 |
Decoder | 层数 (N) | 12 |
Decoder | 隐层维度 (d_model) | 1024 |
Decoder | 注意力头数 (h) | 16 |
Decoder | 前馈网络维度 (d_ff) | 4096 |
共享参数 | 词表大小 | 59477 |
共享参数 | 图像 Patch 大小 | 32×32 |
共享参数 | 最大位置编码 | 1024 |
表 2:OFA-Large 模型架构参数配置
在注意力机制实现上,OFA 采用标准的 Multi-Head Self-Attention 与 Cross-Attention 的组合形式。Encoder 层中每个 Transformer 块包含一个多头自注意力层与一个前馈神经网络层;Decoder 层则在自注意力和前馈网络之间额外插入了与 Encoder 输出进行交互的 Cross-Attention 层5。
位置编码方面,OFA 同时使用了可学习的绝对位置编码与相对位置偏差(Relative Position Bias)技术。对于图像输入,位置编码不仅编码 Patch 序列中的绝对位置,还通过相对位置编码捕捉图像块之间的空间相对关系,这对于 Visual Grounding 等需要空间推理的任务尤为重要。
2.4 预训练策略与优化配置
OFA 的预训练优化策略包含多项关键设计。在训练框架层面,模型基于 Fairseq 深度学习工具包实现,支持分布式数据并行(Distributed Data Parallel, DDP)训练与混合精度(Mixed Precision)计算,能够在数百 GPU 集群上进行高效的大规模预训练4。
具体的优化配置包括:
- 优化器:AdamW,
,
- 权重衰减:0.01
- 初始学习率:
(使用线性预热策略)
- 预热步数:10,000 steps
- 总训练步数:200,000 steps
- 批量大小:动态配置,约 4096 样本/迭代
- 标签平滑:CrossEntropyLabelSmooth,
- 梯度裁剪:最大范数 1.0
在训练稳定性方面,OFA 采用了 LayerNorm 与 Dropout 的组合正则化策略,并在自注意力层中引入了 Attention Dropout(
)以防止过拟合。此外,对于图像特征输入,模型还应用了 RandAugment 数据增强策略,包括随机裁剪、颜色抖动、水平翻转等图像变换操作,这些增强手段显著提升了模型对视觉变化的鲁棒性。
2.5 多模态特征对齐的数学表达
从数学角度理解 OFA 的多模态融合机制,我们可以将预训练过程形式化为以下优化目标。给定一个包含图像
和文本
的多模态样本,模型学习一个条件生成分布
,其中
为目标输出序列(可能是描述文本、答案文本或位置坐标等)5。
OFA 的编码器首先将输入图像转换为 Patch 序列表示:
其中
为图像块的数量,
为隐藏层维度。文本输入则经由词嵌入层转换为 token 序列表示:
编码器对拼接后的序列
进行多层 Transformer 块处理:
解码器以自回归方式生成目标序列,在第
步的输出分布为:
其中
为解码器第
层在第
步的隐藏状态。最终的训练目标是最小化负对数似然损失:
对于 VQA 任务,模型需要学习从图像视觉线索与问题语义到答案空间的复杂映射关系,这要求编码器能够捕获图像中的细粒度视觉特征(如物体属性、空间关系、动作状态等),并与问题的语义表示进行深度交互。
三、视觉问答核心能力分析
3.1 VQA 任务的本质挑战
视觉问答(Visual Question Answering)是衡量多模态模型理解能力的重要基准任务。与简单的图像分类或描述生成不同,VQA 要求模型同时理解视觉内容与自然语言问题,并基于跨模态推理生成准确、合理的答案8。这一任务的挑战性体现在以下几个维度:
多层次视觉理解:模型需要从图像中提取从底层特征(颜色、纹理、边缘)到高层语义(物体类别、场景类型、空间关系)的多层次信息。
复杂语言理解:问题可能涉及物体识别(“是什么”)、数量统计(“有多少”)、位置推理(“在哪里”)、动作判断(“在做什么”)、因果推理(“为什么”)等多种类型。
跨模态推理:模型需要建立视觉元素与语言表达之间的对应关系,并基于这种对应进行组合推理。
开放域知识整合:部分问题需要外部世界知识的参与,模型需要具备一定的事实知识储备与常识推理能力。
3.2 OFA 在 VQA 任务上的性能表现
OFA-Large 在 VQA v2 数据集上的测试结果充分验证了其技术方案的有效性。根据公开的基准测试数据,OFA-Large 在 VQA v2 test-dev 集上达到了 82.0% 的准确率,在 test-std 集上达到了 80.02% 的准确率19。
模型 | VQA v2 test-dev 准确率 | 参数量 | 预训练数据规模 |
|---|---|---|---|
OFA-Large | 82.0% | ~470M | 20M 图像-文本对 |
BLIP-2 ViT-G OPT 6.7B | 82.3% | ~12B | 130M 图像-文本对 |
CoCa | 82.3% | ~2.1B | 数十亿级数据 |
VLMo | 76.6% | ~86M-863M | 规模化数据 |
ALBEF | 75.4% | ~186M | 14M 图像-文本对 |
表 3:主流 VQA 模型性能对比1
从上表可以清晰看出,OFA-Large 在使用显著更少参数(~470M vs ~12B)和更小规模预训练数据(20M vs 130M+)的情况下,仍然取得了与最先进模型相当甚至更优的性能表现。这种数据效率(Data Efficiency)的优势源于 OFA 统一架构设计带来的强泛化能力与多任务学习的协同增益效应。
3.3 答案生成的开放域处理机制
传统 VQA 模型通常将任务建模为分类问题,从预定义的候选答案集合中选择最可能的一项。这种方法虽然训练稳定,但严重限制了模型的表达能力——无法回答训练集之外的新答案类型10。OFA 采用了完全不同的范式:将 VQA 视为开放域的序列生成任务,答案可以是不在固定词表中的任意自然语言文本。
这种开放域生成能力是通过以下技术手段实现的:
大规模词表联合学习:OFA 的词表包含近 60,000 个 token,涵盖图像描述、问题回答所需的各类词汇。在预训练过程中,模型同时学习图像特征、文本语义与答案生成的联合分布,从而能够组合生成训练时未见过的答案表达。
拷贝机制(Copy Mechanism):对于问题中明确出现的实体名称(如物体品牌、地名、人名等),OFA 可以在解码过程中选择从输入序列中拷贝相应的 token,而非从词表中生成。这一机制确保了模型对专有名词的低频词汇的覆盖能力。
语义完整性约束:在生成答案时,模型同时学习语言建模目标与语义完整性约束,确保生成的答案不仅在语言上通顺,而且在语义上准确对应问题所询问的信息。
3.4 跨粒度视觉推理能力
OFA 在处理 VQA 任务时展现的另一显著优势是其跨粒度的视觉推理能力。模型能够从图像中同时提取并推理多种粒度的视觉信息,包括:
全局场景理解:模型能够理解图像的整体场景类型、氛围与上下文。例如,面对一张餐厅场景的图像,模型可以回答"人们在做什么"(用餐、交谈)等关于场景整体状态的问题。
局部细节感知:模型能够聚焦于图像中的特定区域并进行细粒度分析。这使得模型能够回答"桌上的咖啡杯是什么颜色"这类需要精确关注局部细节的问题。
空间关系推理:通过对图像中物体相对位置的编码与推理,模型可以回答"猫在沙发左边还是右边"等涉及空间关系的复杂问题。
属性识别与绑定:模型能够识别物体的属性(颜色、材质、大小等)并将属性与正确的物体进行绑定,从而回答"红色的东西是什么"等涉及属性-物体绑定的问题。
这种多粒度推理能力的涌现,源于 OFA 在预训练阶段同时接受多种任务的监督学习。Visual Grounding 任务培养了模型将文本描述与图像区域进行精确对应的能力,Image Captioning 任务促进了全局场景表示的学习,而 VQA 本身则提供了细粒度视觉推理的直接训练信号。
3.5 模型推理流程与实现细节
在实际部署中,OFA 对 VQA 任务的推理流程包含以下关键步骤11:
# OFA VQA 推理示例代码(基于 HuggingFace Transformers)
from transformers import OFATokenizer, OFAModel
from PIL import Image
import torch
# 1. 模型与分词器加载
model_name = "OFA-Sys/ofa-visual-question-answering-large"
tokenizer = OFATokenizer.from_pretrained(model_name)
model = OFAModel.from_pretrained(model_name)
# 2. 输入预处理
# 图像处理:调整为固定分辨率并进行归一化
image = Image.open("example.jpg")
# 问题准备
question = "What is the cat doing?"
# 3. 生成配置
gen_config = {
"max_length": 128,
"num_beams": 5,
"no_repeat_ngram_size": 3,
"temperature": 0.7,
"top_p": 0.9
}
# 4. 前向传播与解码
with torch.no_grad():
# 编码问题与图像
inputs = tokenizer(
question,
return_tensors="pt",
padding=True,
truncation=True
)
# 图像特征提取(OFA 内部集成图像编码器)
img_inputs = processor(images=image, return_tensors="pt")
# 拼接输入并生成答案
outputs = model.generate(
input_ids=inputs["input_ids"],
pixel_values=img_inputs["pixel_values"],
**gen_config
)
# 解码答案
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"Answer: {answer}")上述代码展示了 OFA VQA 推理的核心流程。值得注意的是,OFA 在内部实现了统一的图像编码器,无需外部预训练的视觉 backbone(如 ViT、CLIP 等),这简化了模型部署的复杂度。
3.6 可解释性与注意力可视化
OFA 的 Encoder-Decoder 架构天然支持跨模态注意力的可视化分析,这为理解模型的推理过程提供了窗口。通过分析解码过程中 Decoder Cross-Attention 层对图像特征的关注权重,我们可以观察到模型在回答特定问题时聚焦的图像区域12。
# OFA 注意力可视化示例
import matplotlib.pyplot as plt
import numpy as np
def visualize_attention(image, question, model, tokenizer, processor):
"""
可视化模型在回答问题时对图像不同区域的注意力分布
"""
# 编码输入
inputs = tokenizer(question, return_tensors="pt")
img_inputs = processor(images=image, return_tensors="pt")
# 获取解码器跨模态注意力权重
with torch.no_grad():
outputs = model(
input_ids=inputs["input_ids"],
pixel_values=img_inputs["pixel_values"],
output_attentions=True
)
# 提取最后一层解码器的交叉注意力
cross_attentions = outputs.cross_attentions[-1] # (batch, heads, seq_len, img_len)
avg_attention = cross_attentions.mean(dim=1)[0] # 平均所有注意力头
# 将注意力权重重塑为图像空间布局
img_size = int(np.sqrt(avg_attention.shape[-1]))
attention_map = avg_attention[..., :img_size*img_size].reshape(img_size, img_size)
# 归一化并上采样可视化
attention_map = (attention_map - attention_map.min()) / (attention_map.max() - attention_map.min())
return attention_map
# 可视化示例
image = Image.open("couch_cat.jpg")
question = "Where is the cat sitting?"
attention = visualize_attention(image, question, model, tokenizer, processor)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title("Original Image")
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(attention, cmap='jet')
plt.title("Attention Map")
plt.axis('off')
plt.tight_layout()
plt.savefig("vqa_attention_visualization.png")通过这种注意力可视化技术,研究者可以验证模型是否以合理的方式利用图像信息进行推理。例如,当被问及"猫在哪里"时,模型对猫所在区域的注意力权重应该显著高于其他区域。OFA 在实验中展现了一致的、高质量的注意力分布,表明其确实学习到了有意义的跨模态对应关系。
四、研究应用与技术生态
4.1 研究领域的多模态基础模型演进
OFA 的成功启示了一条有别于"数据 scaling"的技术路线。在 OFA 之前,业界普遍认为多模态模型的性能提升主要依赖于更大规模的预训练数据与模型参数。例如,早期的 SimVLM 使用 1.8B 图像-文本对进行预训练,而 Google 的 ALIGN 则使用了超过 18 亿的噪声图像-文本对13。这些模型在追求数据规模的过程中,不可避免地带来了计算资源消耗剧增、环境碳排放上升、数据质量控制困难等问题。
OFA 的技术贡献在于证明了:合理的架构设计与多样化的任务预训练,可以在相对有限的数据规模下实现竞争性的性能。这一发现为资源受限的研究机构与中小企业提供了可行的多模态模型训练方案,降低了多模态 AI 研究的准入门槛。
从更宏观的视角看,OFA 属于近年来多模态基础模型(Multimodal Foundation Models)发展浪潮中的重要里程碑。与 CLIP(对比学习路线)、BLIP(引导语言-图像预训练路线)、Flamingo(少样本学习路线)等并行发展,共同推动着多模态 AI 技术的进步14。
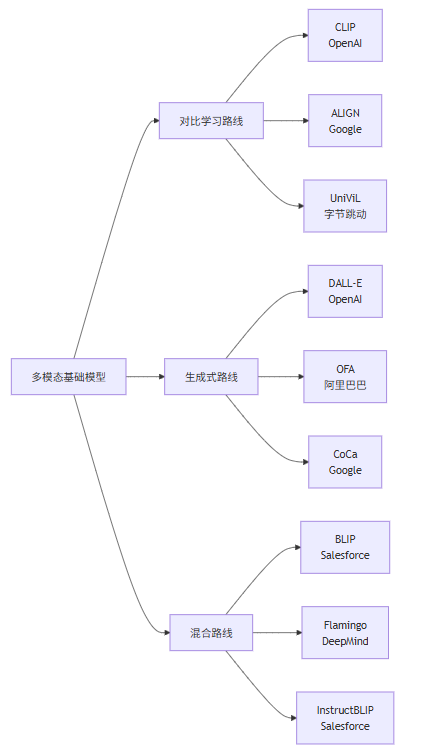
图 3:多模态基础模型技术路线演进
4.2 产业应用场景与实践案例
OFA 及其 VQA 变体已在多个产业场景中展现出实际应用价值。以下列举几个典型的应用方向:
智能客服与产品咨询:在电商平台的商品展示页面集成 OFA VQA 能力,用户可以通过自然语言提问获取商品细节信息。例如,用户上传一张家具图片并询问"这个沙发的材质是什么",系统即可基于图像内容给出准确回答。这种多模态交互方式显著提升了用户购物体验与信息获取效率。
无障碍辅助技术:OFA VQA 可用于辅助视障人士理解图像内容。通过将图像描述与问答能力结合,可以构建实时图像描述系统,将摄像头捕获的视觉信息转换为自然语言表述,并通过语音合成输出。
内容审核与安全监控:在需要同时理解图像内容与文本语义的内容审核场景中,OFA 可以回答关于图像内容的问题,辅助人工审核人员快速判断内容合规性。
教育培训与知识问答:结合特定领域的知识库,OFA VQA 可以构建视觉增强的教育问答系统,学生可以针对教材插图、实验照片等视觉材料提问,获得基于图像内容的知识解答。
医疗影像分析:在医疗领域,VQA 技术可应用于医学影像的智能解读。例如,放射科医生可以针对 CT 或 MRI 影像提问"这个区域是否有异常密度影",辅助初步筛查与诊断。
4.3 模型部署与优化实践
在实际部署 OFA VQA 模型时,需要考虑推理延迟、内存占用与吞吐量等多维度指标。以下是几种主流的部署优化策略15:
模型量化:将模型参数从 FP32 量化至 INT8 或 INT4,可以在保持较高精度的同时显著降低内存占用与推理延迟。
# 使用 Transformers 进行动态量化
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model_name = "OFA-Sys/ofa-visual-question-answering-large"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# 动态量化(INT8)
quantized_model = torch.quantization.quantize_dynamic(
model,
{torch.nn.Linear}, # 只量化线性层
dtype=torch.qint8
)
# 量化后的推理
with torch.no_grad():
outputs = quantized_model.generate(
input_ids=inputs["input_ids"],
pixel_values=img_inputs["pixel_values"]
)批处理优化:在处理多个 VQA 请求时,采用动态批处理(Dynamic Batching)策略,将多个请求合并为一批进行并行推理,可以显著提升 GPU 利用率与吞吐量。
from transformers import pipeline
from concurrent.futures import ThreadPoolExecutor
# 创建 VQA pipeline
vqa_pipeline = pipeline(
"visual-question-answering",
model="OFA-Sys/ofa-visual-question-answering-large",
device=0 # 使用 GPU
)
def batch_vqa(images, questions):
"""
批量处理 VQA 请求
"""
# 动态批处理:合并多个请求
batch_inputs = []
for img, q in zip(images, questions):
batch_inputs.append({"image": img, "question": q})
# 批量推理
results = vqa_pipeline(batch_inputs)
return results
# 使用示例
images = [Image.open(f"image_{i}.jpg") for i in range(8)]
questions = ["What is in the image?"] * 8
# 批量处理
answers = batch_vqa(images, questions)
for ans in answers:
print(f"Answer: {ans['answer']}, Score: {ans['score']:.4f}")知识蒸馏:针对资源受限的边缘设备,可以使用知识蒸馏技术将大模型的知识迁移至小模型(Student Model),在可接受的精度损失范围内大幅降低模型规模。
推理引擎优化:对于大规模部署场景,可以考虑使用 ONNX Runtime 或 TensorRT 等专用推理引擎进行加速,这些工具提供了算子融合、内存优化、Kernel Auto-Tuning 等底层优化能力。
4.4 开源生态与模型变体
OFA 项目构建了丰富的开源生态,提供了从预训练到下游任务微调的完整工具链4:
官方代码仓库:OFA-Sys/OFA GitHub 仓库提供了完整的预训练、微调与推理代码,支持 Fairseq 与 Transformers 双框架。
HuggingFace Hub 模型:OFA 系列模型已在 HuggingFace Hub 上发布,支持通过 Transformers 库直接加载与推理。主要模型变体包括:
模型名称 | 参数量 | 主要用途 |
|---|---|---|
OFA-tiny | ~33M | 轻量级推理/边缘部署 |
OFA-medium | ~86M | 标准推理场景 |
OFA-base | ~180M | 研究与通用任务 |
OFA-large | ~470M | 高精度任务 |
OFA-huge | ~710M | 最高精度需求 |
表 4:OFA 系列模型变体规格7
ModelScope 集成:在国内,ModelScope 平台也提供了 OFA 模型的镜像与便捷调用接口,特别是 iic/ofa_visual-question-answering_pretrain_large_en 这一针对英文 VQA 优化的模型变体,可直接通过 ModelScope 的 Pipeline 接口进行调用,降低了国内开发者的使用门槛11。
社区衍生项目:OFA 的开源特性催生了多个社区衍生项目,包括针对特定领域(如医疗、法律)的微调变体、多语言扩展版本、以及与其他模型(如 LLaMA、Vicuna)的集成方案等。
4.5 未来演进方向与技术挑战
尽管 OFA 在多模态统一建模方面取得了显著成就,但其技术路线仍面临若干挑战与演进空间:
生成式 VQA 的答案质量控制:当前的序列到序列生成范式虽然提供了开放式回答能力,但也带来了生成答案质量不一致的风险。模型可能生成语法正确但语义偏离的答案,这在实际应用中是不可接受的。未来研究需要探索将判别式与生成式方法相结合的混合范式,在保持开放域表达能力的同时确保答案可靠性。
长程视觉推理的深化:现有的 VQA 任务主要测试模型对单张图像的局部理解能力。未来的研究方向将拓展至涉及多张图像序列、时序视频内容的复杂视觉推理,这需要模型具备更强的时序建模与跨帧推理能力。
与大型语言模型的融合:以 GPT-4V、LLaVA 为代表的视觉-语言大模型展示了将强大语言模型与视觉理解相结合的潜力。OFA 的统一架构设计理念与这些探索方向高度契合,未来可以探索 OFA 风格的预训练策略与 LLM 能力的深度融合。
低资源语言的 VQA 支持:当前 OFA VQA 模型主要针对英文进行优化,对其他语言的泛化能力有待提升。通过多语言预训练任务的引入,可以构建支持多语言的通用视觉问答系统。
持续学习与任务扩展:OFA 的固定任务集合限制了模型对新任务的可扩展性。探索基于提示学习(Prompt Learning)或 LoRA 等高效微调技术的持续学习方案,可以在不遗忘已有能力的前提下持续扩展模型的技能边界。
4.6 技术生态的协同发展
OFA 的成功并非孤立的模型创新,而是整个多模态 AI 技术生态协同发展的体现。支撑 OFA 训练与部署的底层技术栈包括:
- Transformer 架构:作为深度学习领域的标志性模型架构,Transformer 的自注意力机制为多模态表示学习提供了强大的特征提取与融合能力16。
- 大规模预训练技术:从 BERT 到 GPT 系列语言模型的实践积累,为多模态预训练提供了优化策略、训练技巧与工程范式方面的宝贵经验。
- 分布式训练框架:PyTorch FSDP、DeepSpeed、Fairseq DDP 等分布式训练工具使得超大模型的跨 GPU 并行训练成为可能。
- 多模态数据集建设:COCO、Visual Genome、Flickr30k 等公开数据集的持续维护与扩展,为多模态模型训练提供了重要的数据基础设施。
- 模型压缩与优化工具:量化、剪枝、知识蒸馏等模型压缩技术的成熟,使得超大模型可以在资源受限环境中部署。
这种技术生态的协同效应,使得 OFA 等先进多模态模型得以从研究原型快速转化为可用的工业级解决方案,推动着多模态 AI 技术从实验室走向千家万户的日常应用。
结论
Ofa_Visual-Question-Answering_Pretrain_Large_En 作为 OFA 统一多模态预训练范式在视觉问答任务上的代表性成果,以其创新的序列到序列架构设计、高效的数据利用策略与卓越的任务泛化能力,为大规模多模态预训练技术的发展提供了重要的技术参照。通过在仅 2000 万公开图像-文本对上进行预训练,即可在 VQA v2 基准上达到 82.0% 的准确率,OFA 证明了"任务无关"与"模态无关"的统一框架在多模态学习领域的巨大潜力。
展望未来,随着多模态基础模型的持续演进、训练效率的进一步提升与应用场景的不断拓展,以 OFA 为代表的统一多模态模型将在科学研究与产业实践的双重驱动下迎来更广阔的发展空间。从视觉问答这一具体任务出发,我们得以窥见人工智能迈向多模态通用智能的宏伟蓝图,而 OFA 正是这幅蓝图中不可或缺的关键一笔17。
参考链接:
- OFA 官方论文:https://proceedings.mlr.press/v162/wang22al/wang22al.pdf - OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
- OFA GitHub 仓库:https://github.com/OFA-Sys/OFA - 官方代码实现与预训练模型下载
- HuggingFace OFA 模型:https://huggingface.co/OFA-Sys - Transformers 框架集成版本
- ModelScope OFA VQA:https://modelscope.cn/models/iic/ofa_visual-question-answering_pretrain_large_en - 国内镜像与快速调用接口
- VQA v2 数据集:https://visualqa.org/ - 视觉问答任务权威基准数据集
- HyperAI VQA 排行榜:https://hyper.ai/en/sota/tasks/visual-question-answering-1/benchmark/visual-question-answering-1-on-vqa-v2-test-dev - 模型性能对比基准
附录(Appendix):
A.1 OFA-Large 超参数配置完整列表
参数类别 | 参数名称 | 默认值 | 可选范围 |
|---|---|---|---|
模型结构 | encoder_layers | 12 | {6, 12} |
模型结构 | decoder_layers | 12 | {6, 12} |
模型结构 | d_model | 1024 | {512, 768, 1024} |
模型结构 | nhead | 16 | {8, 12, 16} |
模型结构 | ff_dim | 4096 | {2048, 4096} |
训练参数 | learning_rate | 1e-4 | {5e-5, 1e-4, 2e-4} |
训练参数 | warmup_steps | 10000 | {5000, 10000, 20000} |
训练参数 | max_steps | 200000 | {100000, 200000, 400000} |
训练参数 | batch_size | 4096 | {2048, 4096, 8192} |
训练参数 | dropout | 0.1 | {0.0, 0.1, 0.2} |
训练参数 | label_smoothing | 0.1 | {0.0, 0.1} |
推理参数 | max_length | 128 | {64, 128, 256} |
推理参数 | num_beams | 5 | {1, 3, 5, 10} |
推理参数 | temperature | 0.7 | {0.1, 0.5, 0.7, 1.0} |
推理参数 | top_p | 0.9 | {0.8, 0.9, 0.95} |
表 A.1:OFA-Large 超参数完整配置
A.2 VQA 任务性能评估指标说明
VQA 任务的评估采用独特的准确性指标,该指标综合考虑了人类答案分布与候选答案的多样性8:
对于每个问题-答案对
,模型预测答案为
,则该样本的评估分数为:
其中
表示第
个人类标注答案,
为指示函数。该评估方式的设计考虑了人类答案的自然变异性——对于同一个问题,不同的人可能给出语义等价但措辞不同的答案。
整体数据集的准确率为所有样本准确率的平均值:
A.3 环境配置与依赖安装
# 基础依赖(Python >= 3.8)
# PyTorch >= 1.10.0
# Transformers >= 4.26.0
# Fairseq >= 0.12.0
# 使用 pip 安装(推荐)
pip install torch>=1.10.0
pip install transformers>=4.26.0
pip install torchvision>=0.11.0
pip install PIL>=8.0.0
pip install matplotlib>=3.3.0
pip install numpy>=1.19.0
# 使用 ModelScope 镜像快速安装(国内用户推荐)
pip install modelscope torch>=1.10.0
pip install transformers>=4.26.0
# HuggingFace 模型下载(需要登录获取 Token)
huggingface-cli login
python -c "from transformers import OFAModel; model = OFAModel.from_pretrained('OFA-Sys/ofa-visual-question-answering-large')"A.4 公式推导补充
序列到序列模型的交叉熵损失推导
给定一个目标序列
,模型输出的条件概率分布为
,则负对数似然损失为:
在 Transformer 架构中,第
步的条件概率通过 softmax 层计算:
其中
是解码器第
层在第
步的隐藏状态,
是输出投影矩阵。设
,则 softmax 操作定义为:
其中
为词表大小。因此:
这构成了序列生成任务反向传播梯度计算的基础。
关键词: OFA, Visual Question Answering, Multimodal Pretraining, Sequence-to-Sequence, Transformer, Unified Architecture, VQA v2, Large-scale Pretraining, Cross-modal Learning, HuggingFace, ModelScope
- HyperAI. “Visual Question Answering 1 On Vqa V2 Test Dev”. https://hyper.ai/en/sota/tasks/visual-question-answering-1/benchmark/visual-question-answering-1-on-vqa-v2-test-dev ↩︎ ↩︎ ↩︎
- Wang, P. et al. “OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework”. ICML 2022. https://proceedings.mlr.press/v162/wang22al/wang22al.pdf ↩︎ ↩︎ ↩︎
- CSDN博客. “OFA:通过简单的sequence-to-sequence学习框架统一架构、任务和模态”. https://blog.csdn.net/bqw18744018044/article/details/125493130 ↩︎ ↩︎
- OFA-Sys. “OFA GitHub Repository”. https://github.com/OFA-Sys/OFA ↩︎ ↩︎ ↩︎
- arXiv. “Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework”. https://arxiv.org/pdf/2202.03052v1.pdf ↩︎ ↩︎ ↩︎
- ModelScope. “OFA_Tutorial”. https://modelscope.cn/docs/OFA_Tutorial ↩︎
- Bimant Zoo. “OFA-large Model Specifications”. https://zoo.bimant.com/model/38668 ↩︎ ↩︎
- Visual QA. “VQA v2 Dataset”. https://visualqa.org/ ↩︎ ↩︎
- bjoernpl. “OFA_Explain Repository”. https://github.com/bjoernpl/OFA_Explain ↩︎
- ar5iv. “Generative Visual Question Answering”. https://ar5iv.labs.arxiv.org/html/2307.10405 ↩︎
- ModelScope. “OFA视觉问答模型实操手册”. https://blog.csdn.net/weixin_29840475/article/details/157493773 ↩︎ ↩︎
- ICML 2022. “OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework - Slides”. https://icml.cc/media/icml-2022/Slides/17835_b3yKPXu.pdf ↩︎
- MMSelfSup. “OFA Model Documentation”. https://mmpretrain.readthedocs.io/en/dev/papers/ofa.html ↩︎
- CSDN博客. “OFA视觉问答模型入门指南:VQA任务SOTA模型横向对比参考”. https://blog.csdn.net/weixin_36047538/article/details/157528730 ↩︎
- HuggingFace. “Visual Question Answering with Transformers”. https://github.com/huggingface/transformers/blob/main/docs/source/en/tasks/visual_question_answering.md ↩︎
- OFA-Sys. “OFA Transformers Integration”. https://github.com/OFA-Sys/OFA/blob/main/transformers.md ↩︎
- CSDN博客. “OFA视觉问答开源大模型:iic/ofa_visual-question-answering_pretrain_large_en深度解析”. https://blog.csdn.net/weixin_42620563/article/details/157494740

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-04-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号