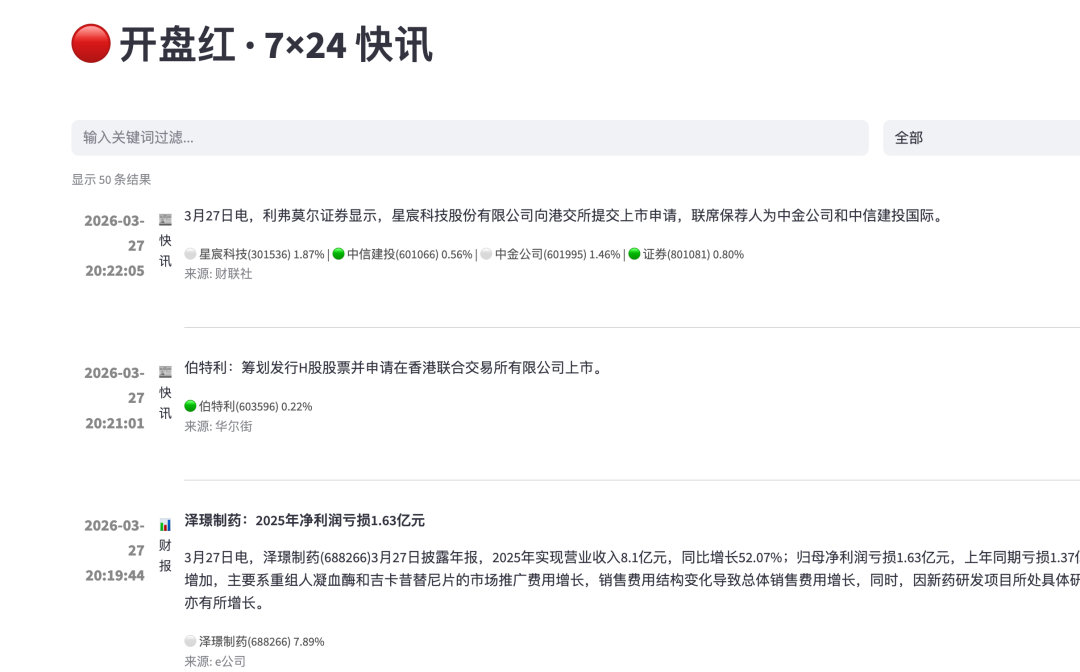
推荐一个多渠道消息数据源开盘红快讯


之前写了一篇文章 , 我用Python写了个“新闻概念挖掘机”,秒懂A股炒作逻辑! 当时数据源用的 财联社, 自己用langchain + llm大模型实现的 关联板块、 股票数据。
最近看开盘啦推出新的APP 开盘红, 看到一个有意思的功能。 AI快讯,里面开盘啦抓取了 不同数据源的 资讯数据,并进行了 关联股票分析(包括股票涨跌幅)。 这个功能挺不错的, 之前我曾经想过获取多渠道数据源,没想到 开盘啦实现了,不错。
我大致看了下 有 财联社、华尔街、e公司、界面新闻等多个消息渠道。
由于涉及到爬虫,这里具体的url就不写了。 有需求可以自行去爬取。
这里说一下网络爬取的步骤。
这里以mac的charles为例, charles下载地址:https://www.charlesproxy.com/download/
注册码网上找一找,没有也可以无限试用的。 软件使用还是比较友好的。
配置Chares
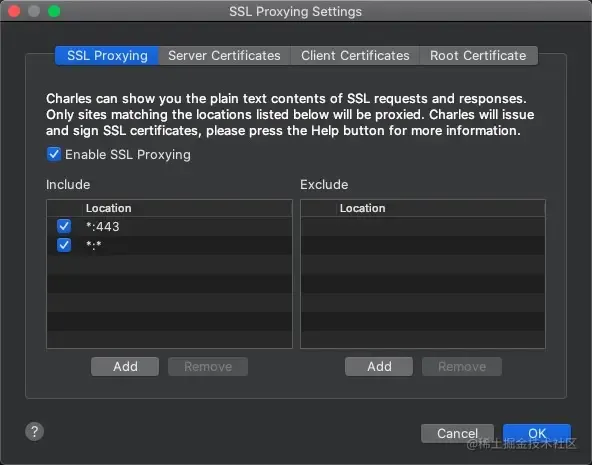
1、SSL Proxying Settings
找到 Proxy - SSL Proxying Settings,点击 Add,Host填*,Port填*或者443。两个都填也行。
图片
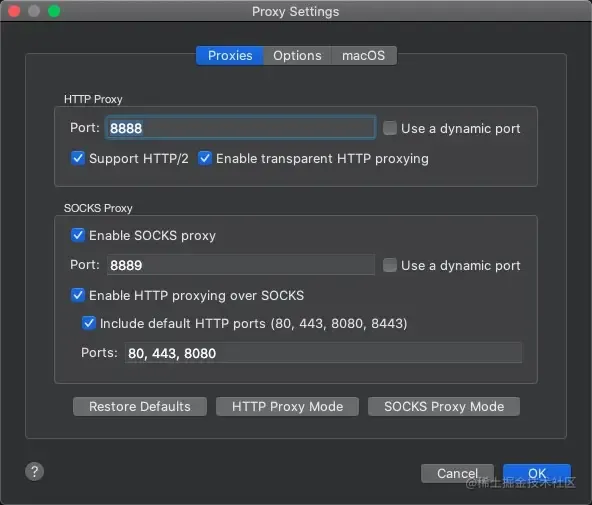
2、Proxy Settings
找到 Proxy - Proxy Settings,Port我们还是8888就行,该沟的就沟上。
图片
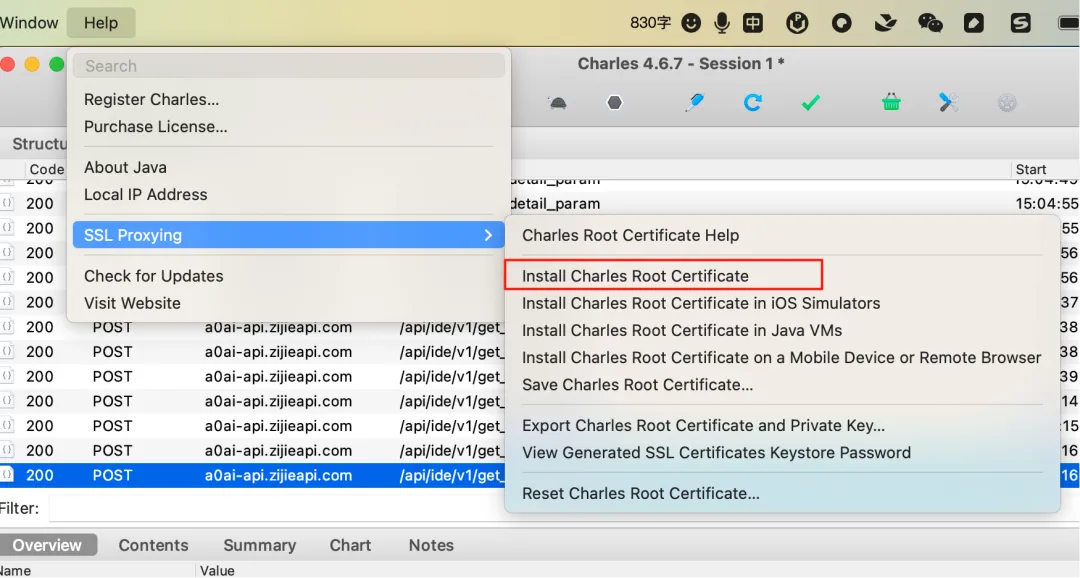
3、安装根证书:
图片
安装根证书,默认不信任,需要到钥匙串里,点击信任:这个是网上的一张截图,示意下。
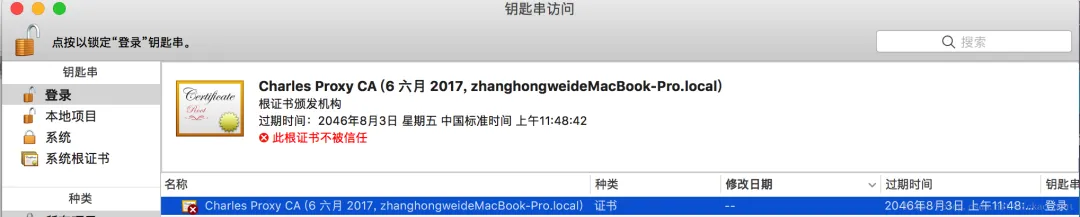
信任证书
代理配置成功后,网络请求出现在Charles主界面 。需要注意一下, 网络抓包的时候可能需要关闭 电脑里的其他代理软件,比如v2rayU什么的。
由于mac电脑可以安装开盘啦APP版本,我就开始直接抓包演示了。 如果你是windows ,你可以选择安装 手机或PC模拟器安装对应的软件。
代码可以参考下思路:
"""
开盘红 · 7×24 快讯 Streamlit 展示
"""
import streamlit as st
import requests
from datetime import datetime, timezone, timedelta
from streamlit_autorefresh import st_autorefresh
API_URL = (
"XXXXX"
)
CST = timezone(timedelta(hours=8))
st.set_page_config(page_title="开盘红 · 快讯", page_icon="🔴", layout="wide")
@st.cache_data(ttl=60) # 60 秒缓存
def fetch_newsflash(page_index: int = 0, count: int = 50) -> dict:
"""获取开盘红快讯数据"""
url = API_URL.replace("Index=0", f"Index={page_index}").replace(
"st=50", f"st={count}"
)
resp = requests.get(url, timeout=15)
resp.raise_for_status()
return resp.json()
def ts_to_str(ts) -> str:
"""Unix 时间戳 → 可读时间"""
try:
dt = datetime.fromtimestamp(int(ts), tz=CST)
return dt.strftime("%H:%M")
except (ValueError, OSError):
return ts
def full_time(ts) -> str:
"""Unix 时间戳 → 完整日期时间"""
try:
dt = datetime.fromtimestamp(int(ts), tz=CST)
return dt.strftime("%Y-%m-%d %H:%M:%S")
except (ValueError, OSError):
return str(ts)
def classify_title(title: str, content: str) -> str:
"""根据内容关键词给新闻打标签"""
text = (title + content).lower()
if any(
k in text
for k in ["净利", "营收", "年报", "财报", "业绩", "eps", "利润"]
):
return "📊 财报"
if any(k in text for k in ["涨停", "跌停", "龙虎", "连板", "封板"]):
return "🔥 涨跌停"
if any(k in text for k in ["央行", "降息", "降准", "利率", "货币政策"]):
return "🏦 央行动态"
if any(k in text for k in ["并购", "收购", "重组", "定增", "增持", "回购"]):
return "💼 资本运作"
if any(k in text for k in ["芯片", "半导体", "ai", "人工智能", "大模型"]):
return "🤖 科技"
if any(k in text for k in ["关税", "贸易", "出口", "进口", "制裁"]):
return "🌍 国际贸易"
if any(k in text for k in ["原油", "石油", "天然气", "黄金", "铜"]):
return "🛢️ 大宗商品"
return "📰 快讯"
def render_stock_badge(stock: list) -> str:
"""渲染关联股票标签"""
if not stock or len(stock) < 2:
return ""
code, name = stock[0], stock[1]
pct = stock[2] if len(stock) > 2 else ""
color = "🟢" if pct.startswith(("+", "0")) and not pct.startswith("-") else "🔴" if pct.startswith("-") else "⚪"
return f"{color} {name}({code}) {pct}"
# ---------- 主界面 ----------
st.title("🔴 开盘红 · 7×24 快讯")
# 侧边栏
with st.sidebar:
st.header("⚙️ 设置")
refresh_interval = st.selectbox(
"自动刷新间隔", [30, 60, 120, 300], index=1, format_func=lambda x: f"{x} 秒"
)
count = st.selectbox("每页条数", [20, 50, 100], index=1)
show_full_time = st.checkbox("显示完整时间", value=False)
st.divider()
st.markdown(
"""
**数据说明**
- 7×24 财经快讯
- 每条快讯关联相关股票
- 涨跌幅为板块/个股实时数据
"""
)
st_autorefresh(interval=refresh_interval * 1000, key="news_refresh")
# 拉取数据
try:
data = fetch_newsflash(page_index=0, count=count)
news_list = data.get("List", [])
server_time = full_time(data.get("Time", 0))
except Exception as e:
st.error(f"获取数据失败: {e}")
st.stop()
if not news_list:
st.warning("暂无快讯数据")
st.stop()
# 搜索 & 筛选
search_col, tag_col = st.columns([2, 1])
with search_col:
search_query = st.text_input(
"🔍 搜索快讯", placeholder="输入关键词过滤...", label_visibility="collapsed"
)
with tag_col:
all_tags = sorted(set(classify_title(n.get("Title", ""), n.get("Content", "")) for n in news_list))
selected_tag = st.selectbox("🏷️ 分类筛选", ["全部"] + all_tags, label_visibility="collapsed")
# 过滤
filtered = news_list
if search_query:
q = search_query.lower()
filtered = [n for n in filtered if q in (n.get("Title", "") + n.get("Content", "")).lower()]
if selected_tag != "全部":
filtered = [n for n in filtered if classify_title(n.get("Title", ""), n.get("Content", "")) == selected_tag]
st.caption(f"显示 {len(filtered)} 条结果")
# 时间线展示
for i, news in enumerate(filtered):
title = news.get("Title", "").strip()
content = news.get("Content", "").strip()
source = news.get("Source", "")
stocks = news.get("Stocks", [])
ts = news.get("Time", "")
# 时间
time_str = full_time(ts) if show_full_time else ts_to_str(ts)
# 标签
tag = classify_title(title, content)
# 构建卡片
with st.container():
cols = st.columns([0.6, 0.15, 8])
with cols[0]:
st.markdown(
f'<div style="font-size:1.1em;color:#888;font-weight:bold;text-align:right;padding-top:4px">{time_str}</div>',
unsafe_allow_html=True,
)
with cols[1]:
st.markdown(
f'<div style="font-size:0.9em;padding-top:6px">{tag}</div>',
unsafe_allow_html=True,
)
with cols[2]:
# 标题
if title:
st.markdown(f"**{title}**")
# 内容 - 清理开头的【】重复
display_content = content
if title and content.startswith(f"【{title}】"):
display_content = content[len(f"【{title}】") :].lstrip()
if display_content:
st.markdown(display_content, unsafe_allow_html=False)
# 关联股票
if stocks:
stock_html = " | ".join(render_stock_badge(s) for s in stocks)
st.markdown(
f'<div style="font-size:0.85em;color:#555;margin-top:4px">{stock_html}</div>',
unsafe_allow_html=True,
)
# 来源
if source:
st.caption(f"来源: {source}")
st.divider()本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号