为了测试大模型的「搜商」,OpenAI 开源了测评基准 BrowseComp

为了测试大模型的「搜商」,OpenAI 开源了测评基准 BrowseComp

不二小段
发布于 2026-04-09 16:05:39
发布于 2026-04-09 16:05:39
先问大家两个问题:
各家 AI 现在都做了 Deep Research,那么如何比较不同的深度研究之间的能力高低呢? 假设一道题目客观上存在唯一正确答案,且相关信息线索绝对可以在互联网上搜到,在允许使用搜索引擎的情况下,你觉得自己能做出来吗?当下最先进的 AI Agent 呢?
为了验证大模型、Agent 网上冲浪的能力,OpenAI 编了一套超难的试卷,里面有 1266 道题目,用来测大模型智能体的搜商。
剧透一下,这套卷子里随便挑一道题目,给足两个小时的时间,人类能搜到答案的成功率也不到三成。

Illustration of papers scattered throughout the frame.
这个测试集我觉得非常有意思,花了很长时间研究和思考,值得给大家展开讲讲。
不知道还有多少人知道「搜商」(Search Quotient)这个词,搜商据说是中搜的陈沛最先提出的,简单来说就是在互联网上检索信息的能力,百度有段时间宣传过这个概念,更普遍的一种说法是信息素养、数字素养。
在开始之前,我找了几道题,大家试一下自己搜索,或者问问大模型,看能否找到正确答案。
第一题(简单):阿布特别喜欢到处游历,脑子里总是梦想着自己在长大成人后能够环游世界的探险之旅。阿布之所以有这种想法,是因为受法国一位科幻作家写的某个历险故事的启发,在那本书中男主人公是搭载____船舶(船名)从新加坡到香港的。
第二题(中等):6月28日是小王的生日,他是华中科技大学2008的本科生。在大四这年,为了庆祝生日,他和朋友们一起看了一场刚好在生日这天上映的国产玄幻电影。在这场电影中,饰演“炼丹大师”角色的演员曾经出家,请问他的法号是什么?
第三题(困难):请回答一位作家兼传记作者的笔名,作家著有多部作品,包括自传。1980 年,这位作家还为其父亲撰写了一部传记。这位作家爱上了一位哲学家的兄弟,该哲学家在家中排行第八。作家曾在 1940 年代离婚后再婚。
这几道题很旧,但对具备一定搜索经验的人来说应该不算难。
我们都知道:
- • 大模型自身存在幻觉,而且大模型对 next token 的预测本身是基于概率的,所以越是边边角角的 corner case 越容易出错;
- • 大模型的训练数据存在时效问题,目前还不可能做到实时更新、实时学习。
我们以开篇的第一道简单题为例,在不开搜索的情况下,大部分模型的回答都是错误的:
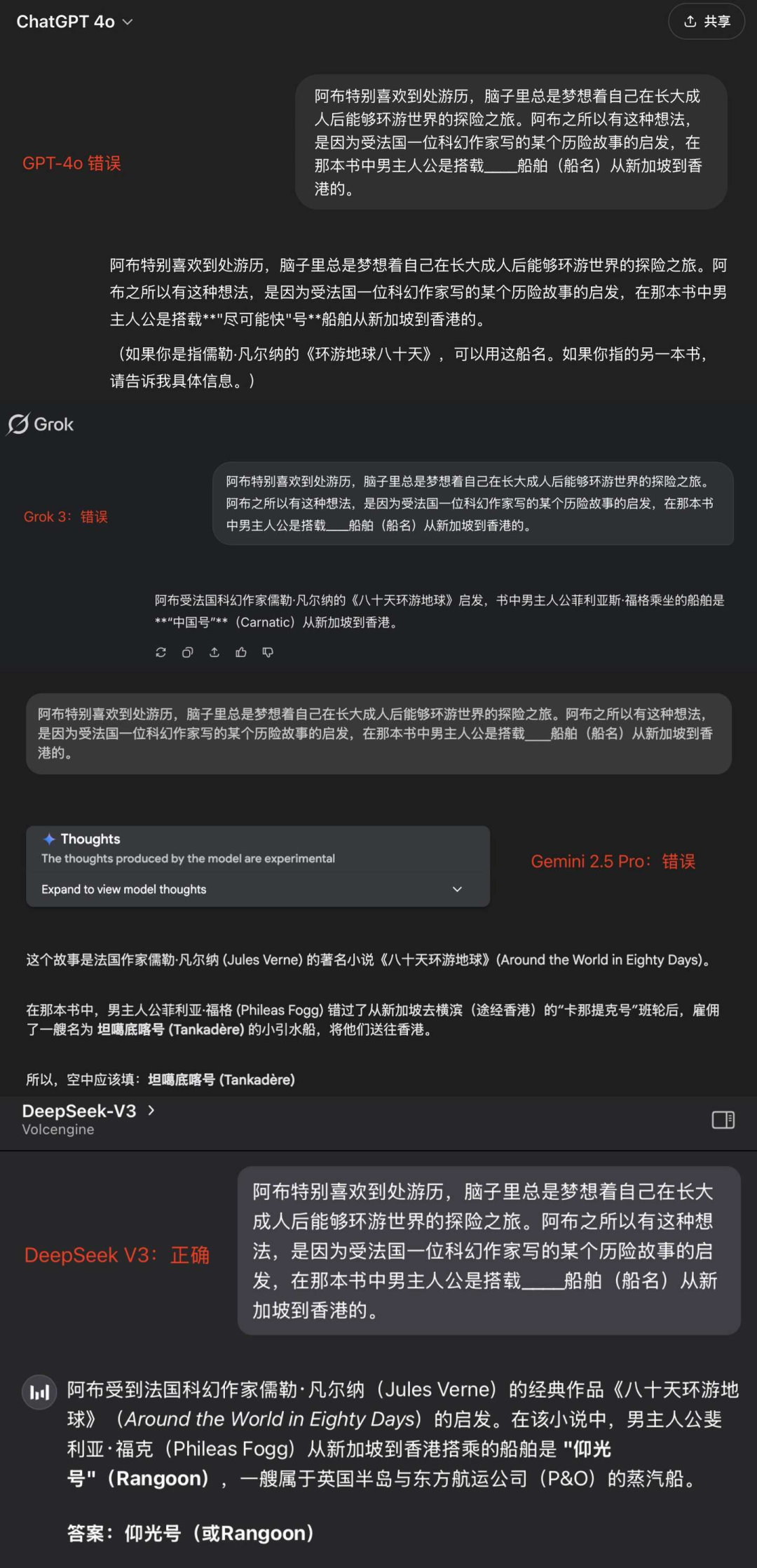
为了缓解大模型的幻觉和数据时效问题,最直观的做法就是赋予大模型 Browse 能力,也就是搜索以及浏览的能力,这也是构建一个 Agent 最基础的工具。
那么,假设有这样一个问题,它的答案的确存在于某个可以被搜索引擎检索到的互联网公开页面中,是否意味着大模型 / Agent 一定能借助搜索工具找到这个正确答案?
说实话目前很难做到,只存在理论上的可能性。因为互联网的信息极为繁杂,你搜索任何组合的关键词,都可能得到数以万计的页面,内容和信息远远超出了大模型的上下文窗口。所以不论搜索还是 RAG,实践中都只会参考召回的前 n 条内容,哪怕是更耗费算力的 Deep Research,最多也只会参考几百个页面。
更何况,很多搜索任务是需要多轮执行的。还是以第一道题为例。
ChatGPT 和 Grok 即便打开搜索功能,依然做不对,因为它们只执行了单轮搜索,而单轮搜索的结果中并没有直接回答问题的答案。只有 Gemini 则通过两步搜索,找到了正确答案:
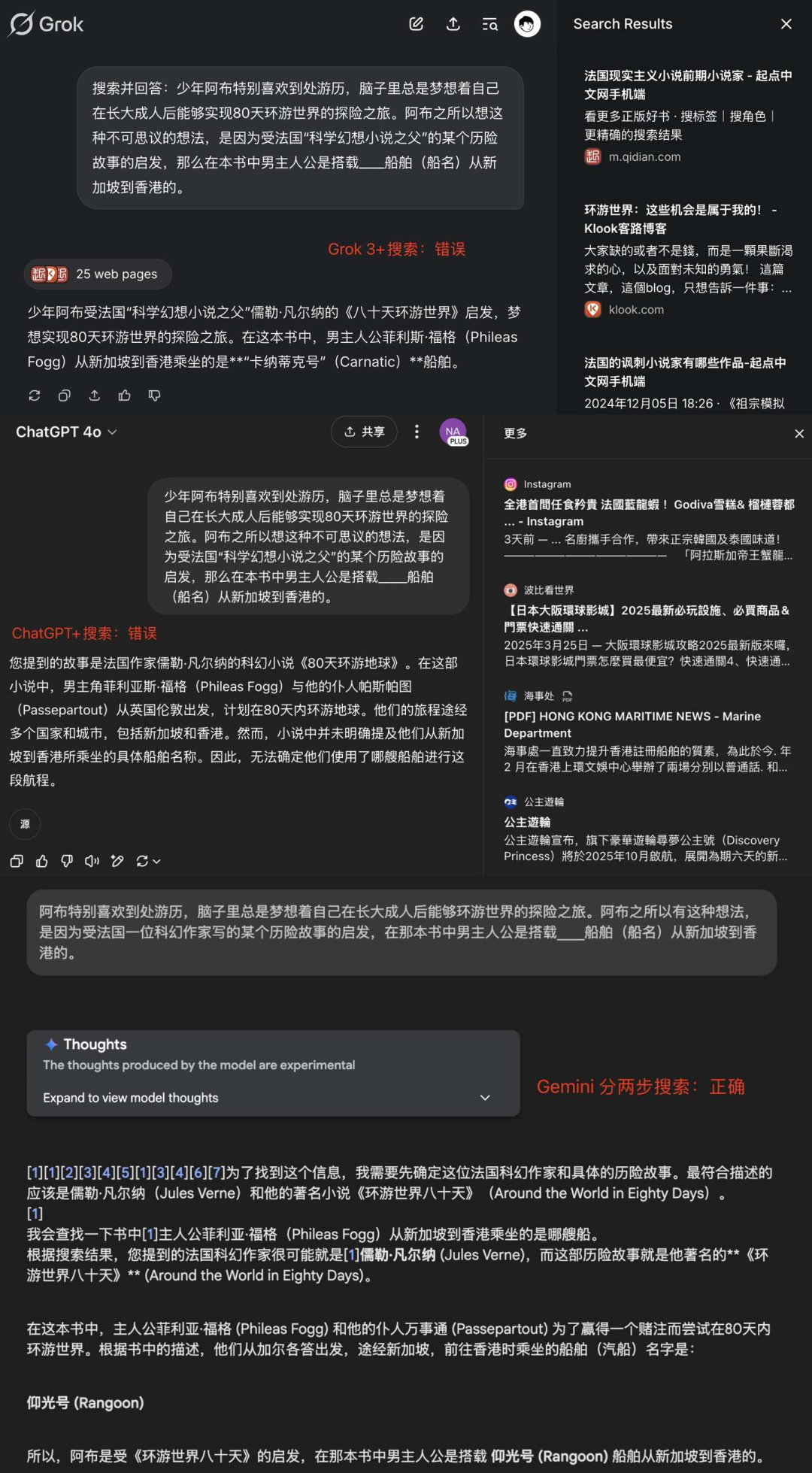
可以看出,这道「简单题」对大模型来说有点难,而我们则可以轻松地借助搜索引擎完成任务:
- 1. 第一步:法国、科幻作家、环游地球 → 凡尔纳的《80天环游地球》
- 2. 第二步:《80天环游地球》中新加坡到香港的船 → 仰光号
其实这道题就来自百度校园十多年前举办的高校搜索大赛,里面都是类似的题目。
在多轮搜索的过程中,既要有规划能力,也要有去伪存真的条件验证能力,人类在执行搜索时可以直接摒弃排除掉某个页面,而大模型则需要正确规划并在有限的上下文里「注意到」正确答案。
由此可以看出,这种需要**「规划+多轮搜索」**的问题,大模型自身也许难以完成,需要深度搜索或者能力更强的 Agent 工程才能解决。
BrowseComp:OpenAI 的终极试炼
这也正是 OpenAI 设计 BrowseComp 评测的思路,写了半天终于回归今天的主线内容了。
简单来说,OpenAI 认为,当前的大模型(GPT-4o + 搜索工具)已经能回答大多数简单题目,之前的 SimpleQA 测试集已趋近于饱和,所以他们编制了一个新的测试集,名为**「浏览竞赛」(Browse Competition)**,其中包含 1266 道题目。
BrowseComp 遵循 SimpleQA 的指导原则,旨在设计具有挑战性、寻求事实的问题,这些问题需要有唯一、无可争议且简短的答案,这些答案不会随时间而改变,且有证据可以支持。
BrowseComp 相比于 SimpleQA,难度大大提升。因为 OpenAI 在设计题目的时候,要求必须通过三项检查来确保问题足够具有挑战性:
- • 当前现有模型无法解决该问题:出题人被要求验证
GPT-4o(无论是否启用浏览功能)、o1以及早期版本的深度研究模型均未能解决这些问题。 - • 出题人需自己执行五次简单搜索,并确认答案未出现在搜索引擎结果的第一页任何位置。
- • 出题人需设计难度足够高的问题,确保其他人无法在十分钟内解决。部分问题会由第二位出题人尝试寻找答案。如果设计的问题被破解率超过 40%,则需修改题目。
如何炮制一道“变态”难题?
这么难的题,真的存在吗?或者说,出题人是怎么编出来的?出题还是比解题简单很多的,因为出卷人和答题者之间存在巨大的信息鸿沟。
具体来说,出题人并不像我们平时那样从一个问题出发去寻找答案,而是恰恰相反:他们会先从一个确定的事实开始,这个事实可以是一个人、一个事件或一件艺术品等,称之为种子 。
然后,围绕这个「种子」事实,去挖掘几个几乎不相关的特征,每个特征本身都对应着一个巨大的搜索空间。最后,将这些特征组合起来,就构成了一个问题 。
OpenAI 只公布了极少的部分题目示例,其余题目通过加密发布,并要求研究者不要在网上公开分享这些题目,以免污染测试集。
我们可以从这些示例题目中找到 OpenAI 的出题思路。比如这道题:
请告诉我一篇于 2018-2023 年间在 EMNLP 会议上发表的科学论文的标题,其第一作者的本科毕业于达特茅斯学院,而第四作者的本科毕业于宾夕法尼亚大学。
如果你已经知道了答案(也就是论文标题),想要验证它是否符合题目中的所有条件,其实非常简单。只需要进行几次搜索:确认论文的发表年份和会议,然后分别查证第一和第四作者的教育背景 ,整个验证过程可能花不了几分钟。
但反过来,如果你要从问题出发去寻找答案,难度就是指数级的。如果使用最朴素的暴力搜索方法,就需要:
- 1. 找到 2018 至 2023 年所有 EMNLP 会议的论文列表(这本身就是一个庞大的数字,可能有数千篇)。
- 2. 对于每一篇论文,都需要去查找其第一作者和第四作者的个人履历。
- 3. 找到作者的本科教育信息,并判断是否分别是达特茅斯学院和宾夕法尼亚大学。
这个过程不仅耗时巨大,而且极其繁琐,对人类和机器来说都是一个巨大的挑战 。
这种「验证容易,解答困难」的特性,被称为验证的不对称性。OpenAI 专门找专家出了一堆这种题目。他们认为,这种做法既能确保题目有足够的挑战性,又能让评分过程变得简单可靠。
为了确保答案的唯一性,OpenAI 要求出题人本身熟悉相关领域内容,同时尽可能增加更多约束条件,直到出题人有信心认为答案是唯一的,并要求测试人员尝试寻找其他答案。
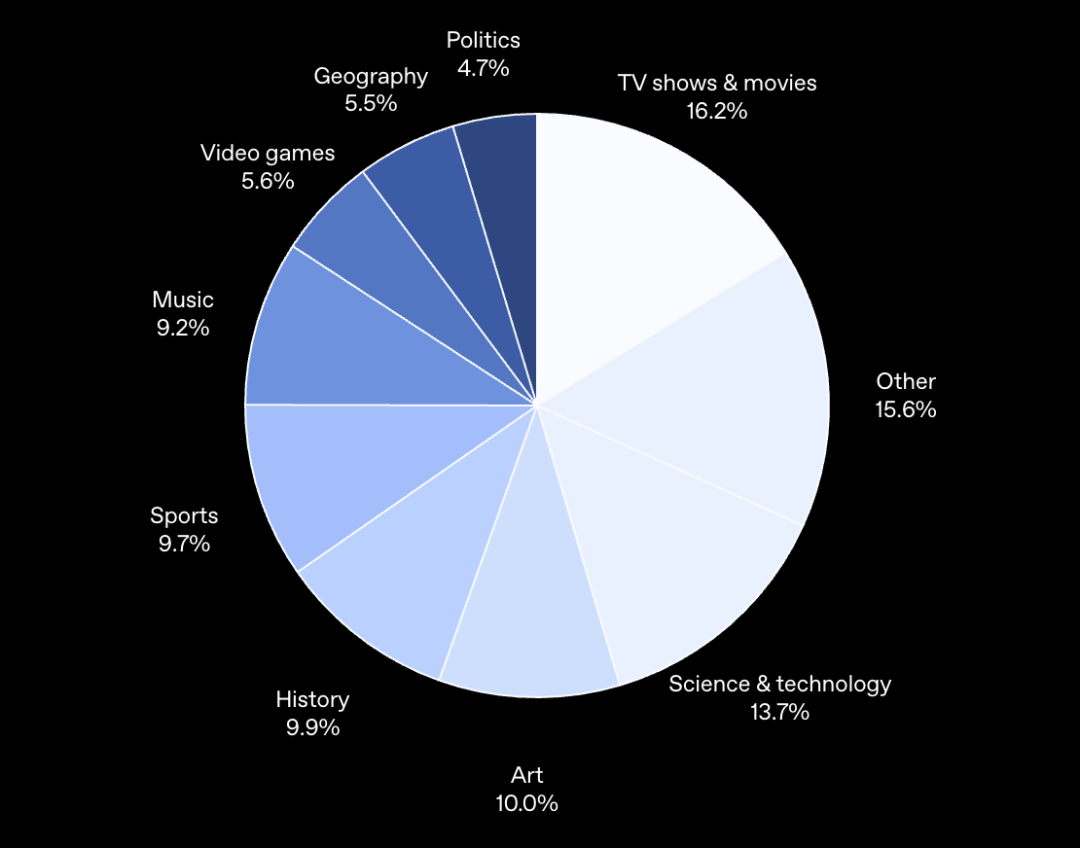
经过繁琐的出题和验证,最终得到了这套涵盖影视、科技、艺术、历史、体育、音乐、游戏、地理、政治等多个领域,共 1226 道题目的试卷。
人类亲自下场,结果惨不忍睹
为了衡量 BrowseComp 的真实难度,OpenAI 做了一个实验:让出题人自己下场去解答这些问题。当然,是互相解答别人出的题目。
同时,人类测试员只能使用搜索引擎,而不能使用任何 AI 工具。考虑到题目的极端难度,允许测试者在尝试了 2 个小时后,如果仍然找不到答案,可以选择放弃,并将问题标记为「无法解决」。
结果可以说相当惨烈。
在 1255 道被尝试的题目中,人类测试者在两个小时后放弃的比例高达 70.8%。注意,是在一道题上面花费超过两个小时!
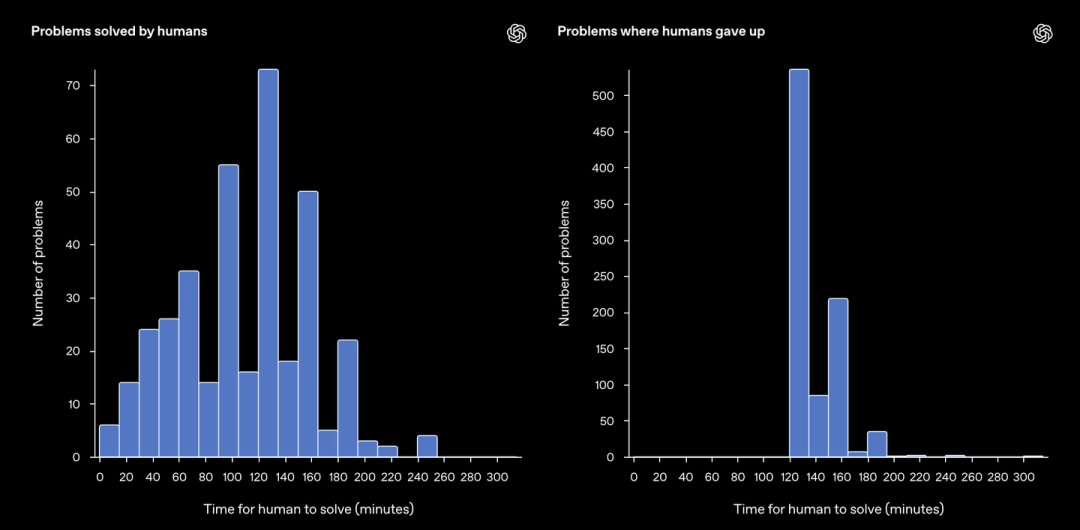
最终,只有 29.2% 的问题被标记为「可解决」。同时,在这些声称「可解决」的问题中,测试者给出的答案与标准答案完全一致的比例只有 86.4%。这意味着,即使是经验丰富的人类,在面对这些复杂问题时,也难免会出错。
OpenAI 模型成绩
OpenAI 对一系列自家模型进行了全面评测,结果非常有启发性。
- • 对于基础模型,
GPT-4o和GPT-4.5在不开启任何浏览工具的情况下,准确率几乎为零,分别只有 0.6% 和 0.9%。这说明:面对这些需要外部知识的超纲难题,单靠模型内部的知识储备是完全无能为力的。 - • 即便为
GPT-4o增加搜索功能,准确率也依然只有 1.9%。这说明:仅仅提供工具是远远不够的,模型还必须学会如何有策略地使用这个工具,比如如何规划搜索路径、如何解读返回结果、如何整合多源信息等。 - • 对于推理模型,不联网的
o1准确率来到了 9.9%,远高于使用搜索的GPT-4o。这表明,对于一部分BrowseComp问题,强大的推理能力可以直接从模型现有的知识中「推断」出答案,这反而比漫无目的的低效搜索更有效。 - • 最后,Deep Research 登场。这是一个为深度搜写任务专门训练的 Agent 模型。它的准确率直接飙升至 51.5%,解决了超过一半的问题。

OpenAI 坦言,Deep Research 就是专门为解决 BrowseComp 题目而训练的,反过来也可以说,BrowseComp 是专门为了验证 Deep Research 能力而设计的。
Deep Research 不仅仅是一个简单的「搜索-回答」工作流,而是能够自主地在网络上进行搜索,评估和综合来自多个来源的信息,并根据遇到的情况动态调整其搜索策略,有效处理大量信息的真正的智能体。
大力真的能出奇迹吗?
大模型的一大特点就在于 Scale law,从训练到推理,Scale law 成为很多人坚信模型能力能够继续提升的信仰。
同样,对于智能体来说,test-time scale law 依然存在。简单来说,就是花更多时间、用更多算力去想一个问题,答案往往会更好。
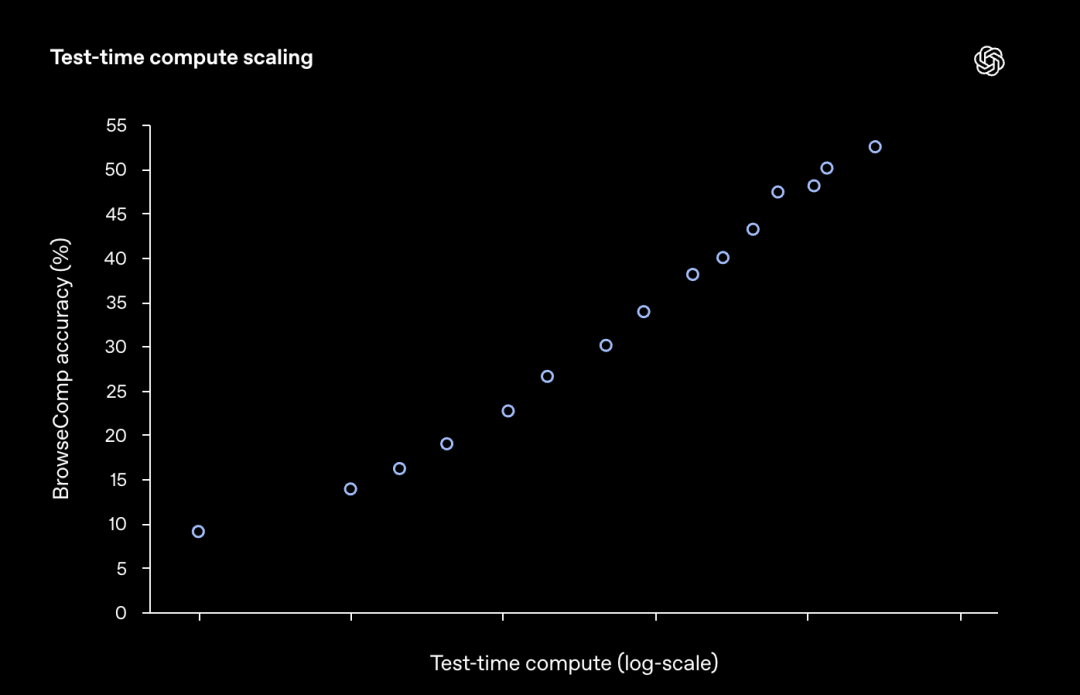
BrowseComp 的问题需要反复浏览大量网页并整合信息,这天然就为「大力出奇迹」提供了舞台。
实验结果也表明,模型的准确率随着算力的投入呈现出平滑的增长曲线。
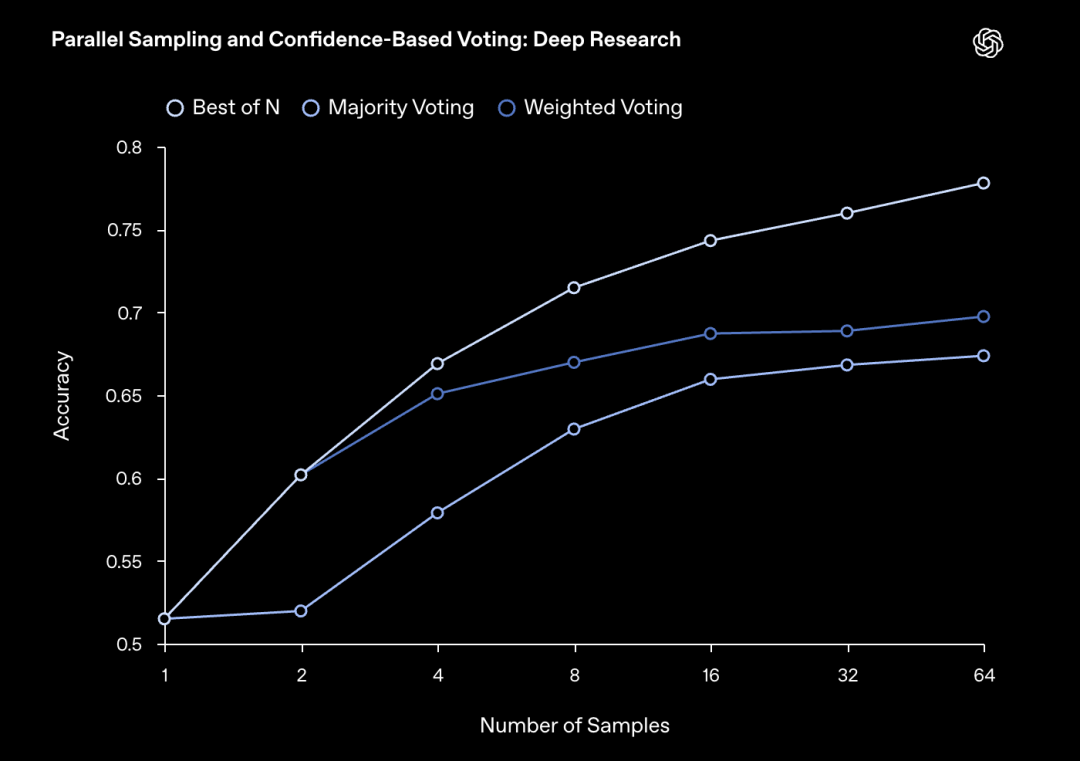
OpenAI 进一步允许Deep Research 模型对每个问题并行生成 64 个独立的解答,并测试了三种不同的「投票」策略来选出最终答案 :
- • 多数投票:简单粗暴,选择 64 个答案中出现次数最多的那个 。
- • 加权投票:模型在给出每个答案的同时,还会给出一个 0% 到 100% 的置信度分数。这个策略会根据置信度来为每个答案的投票加权 。
- • 最佳选择:最简单也最自信的策略,直接选择 64 个答案中置信度最高的那一个 。
结果显示,这三种方法都带来了显著的性能提升,准确率相比单次尝试提高了 15% 到 25%。其中,最佳选择(Best-of-N) 的效果最好,随着轮次始终保持着最高的准确率。
最后,对于那些 Deep Research 完全无法解决的问题,研究人员做了一个后续分析:他们直接把正确答案告诉模型,然后要求它去网上寻找支持该答案的证据。在大多数情况下,模型成功地找到了证据。
这说明,这些问题并非「无解」,而是「极难发现」。失败的原因不在于信息的缺失或模型无法验证,而在于寻找答案的过程本身。这要求模型具备超凡的战略毅力、灵活的搜索重构能力,以及将多个来源的零碎线索拼接起来的能力。
小结
当然了,专门设计出的这些题目未必全都符合现实生活的需要。你可能会觉得,这不就是在故意刁难?
没错,就是要用最难的题目,来找到模型的能力边界,给智能体一个需要研究如何突破的发展方向。
现在的前沿模型已经超越了人类能力,更不要说具有工具使用权限的智能体了,只有创造出足够困难的题目,才能测试到能力的边界。如果一个模型能在 BrowseComp 中取得高分,至少证明了它在定位和获取高难度信息方面能力出色。
参考来源:
- • BrowseComp: a benchmark for Browse agents(https://openai.com/index/browsecomp/)
- • BrowseComp: A Simple Yet Challenging Benchmark for Browse Agents(https://arxiv.org/abs/2504.12516)
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号