开源:YOLO最强对手?D-FINE目标检测与实例分割框架深度解析
原创
开源:YOLO最强对手?D-FINE目标检测与实例分割框架深度解析
原创
CoovallyAIHub
发布于 2026-03-05 14:12:22
发布于 2026-03-05 14:12:22
在计算机视觉领域,实时目标检测与实例分割一直是工业界和学术界关注的焦点。Transformer架构的加入让这一领域焕发新生,但如何在保持低延迟的同时实现高精度的实例分割,依然是技术落地的难点。
今天,我们将深度解析一款刚刚开源的新框架——D-FINE-seg。它不仅继承了D-FINE在目标检测上的优势,更以轻量级设计和多后端部署能力,向YOLO系列发起了有力挑战。

图片1.png
项目地址:https://github.com/ArgolHA/D-FINE-seg 论文地址:https://arxiv.org/pdf/2602.23043v1
为什么D-FINE值得关注?
D-FINE系列的核心优势在于其端到端的Transformer架构。与需要非极大值抑制(NMS)的传统方法不同,D-FINE通过Transformer解码器直接输出预测结果,大幅简化了推理流程。其两大技术支柱尤为亮眼:
- 细粒度分布细化(FDR):通过迭代优化边界框的概率分布,而非直接预测坐标,显著提升定位精度。
- 全局最优定位自蒸馏(GO-LSD):将最终解码层的知识传递给浅层,实现自我优化,不增加推理成本。
这些设计让D-FINE在速度与精度之间取得了出色的平衡,而新发布的D-FINE-seg则将这一优势延伸到了实例分割任务。
图片2.png
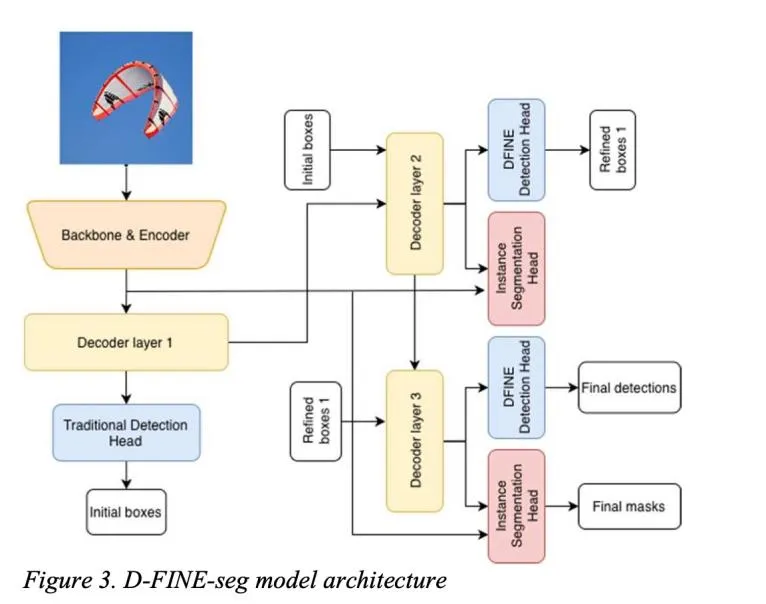
D-FINE-seg:为分割而生
D-FINE-seg在保留原检测架构的基础上,新增了一个轻量级掩码头。其设计灵感来自Mask DINO,但做了关键简化:
图片3.png
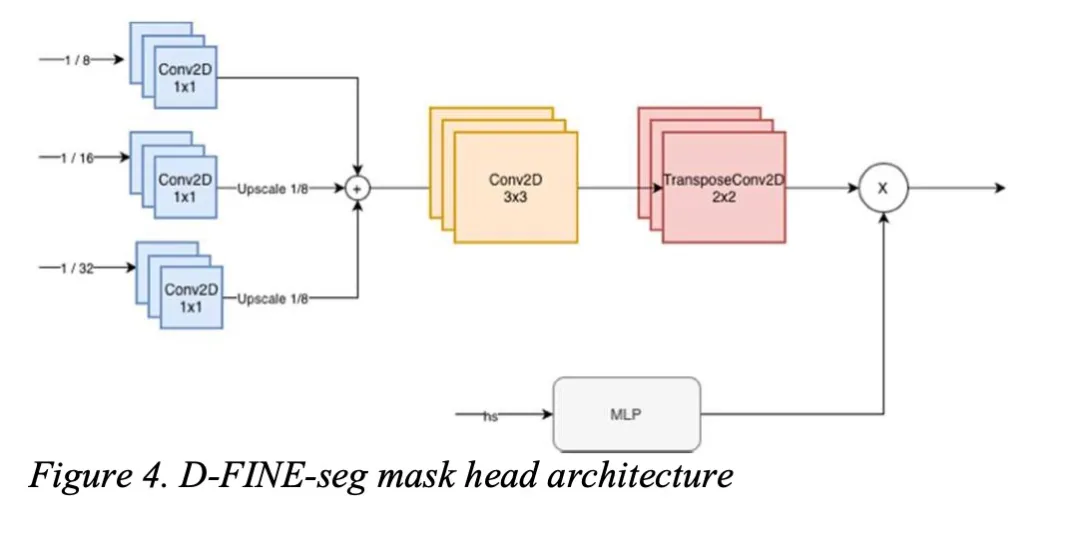
- 输入来源:仅使用混合编码器(HybridEncoder)的多尺度特征(步长8/16/32),避免引入高分辨率 backbone 特征,减少计算量。
- 特征融合:通过1×1卷积统一通道数,上采样至步长8后融合,再经3层卷积平滑。
- 掩码生成:利用解码器查询生成掩码嵌入,与图像特征做点积,得到1/4分辨率的掩码logits,后处理时再上采样至原图尺寸。
这种设计让掩码头足够轻量,对整体延迟影响极小,同时保持了不错的精度。
图片4.png
训练优化:不止是加个头
新增掩码分支后,训练策略也需要重新设计。D-FINE-seg在以下几方面做了针对性优化:
- 损失函数
在原有检测损失(Varifocal Loss、L1、GIoU、FGL、DDF)基础上,增加了两种掩码损失:
框裁剪的掩码二值交叉熵(BCE):仅在真实边界框内计算,并按区域面积归一化。
框裁剪的掩码Dice损失:关注掩码形状的相似性。
- 匹配策略
匈牙利匹配器在计算代价时,除了分类和框回归代价,还新增了:
掩码Dice代价
掩码Focal代价(全图计算,而非仅框内)
- 辅助监督
对解码器的中间层也施加掩码监督,同时引入去噪任务,帮助模型更快收敛,且不影响推理速度。
硬核部署能力
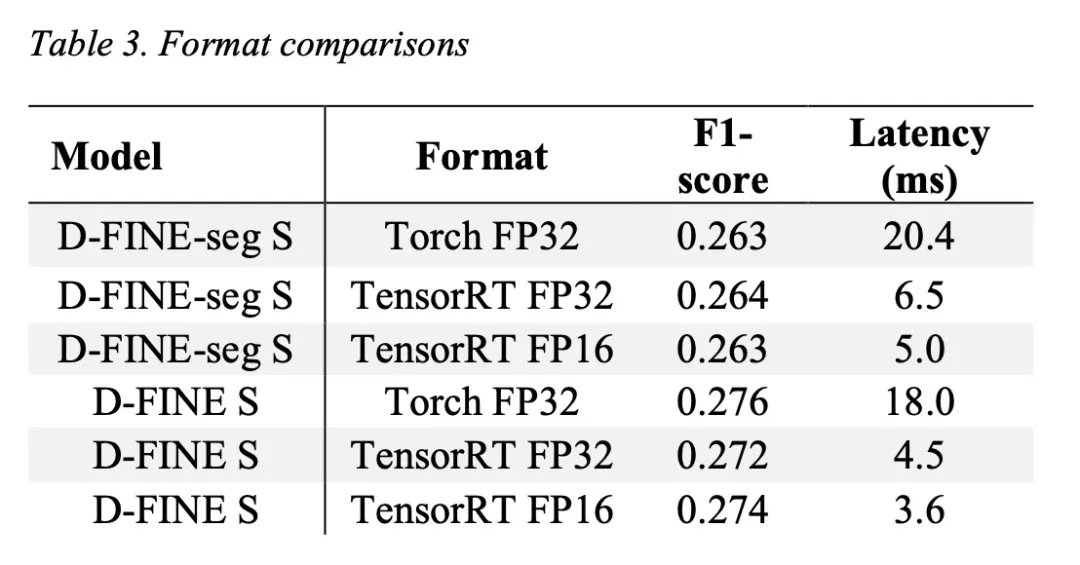
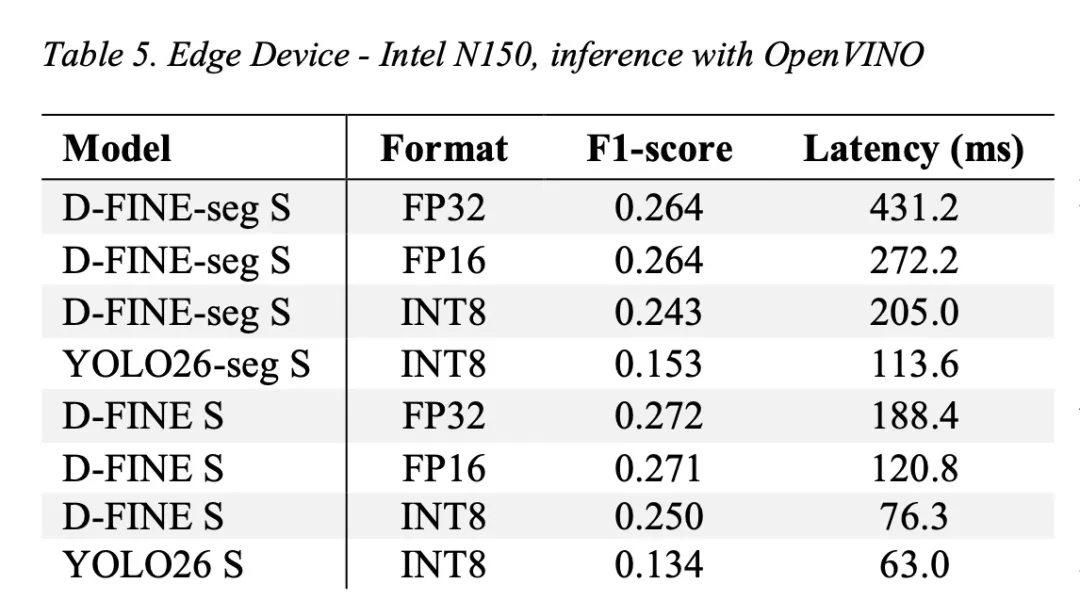
D-FINE-seg的一大亮点是其原生支持多后端部署。框架内置了完整的导出与推理模块,支持:
- ONNX、TensorRT、OpenVINO三大主流格式
- FP16 加速
- OpenVINO 的 INT8 量化感知训练
- 端到端的延迟基准测试(含预处理、推理、后处理)
这意味着从训练到落地,D-FINE-seg提供了一站式解决方案,开发者无需在模型转换和优化上耗费大量精力。
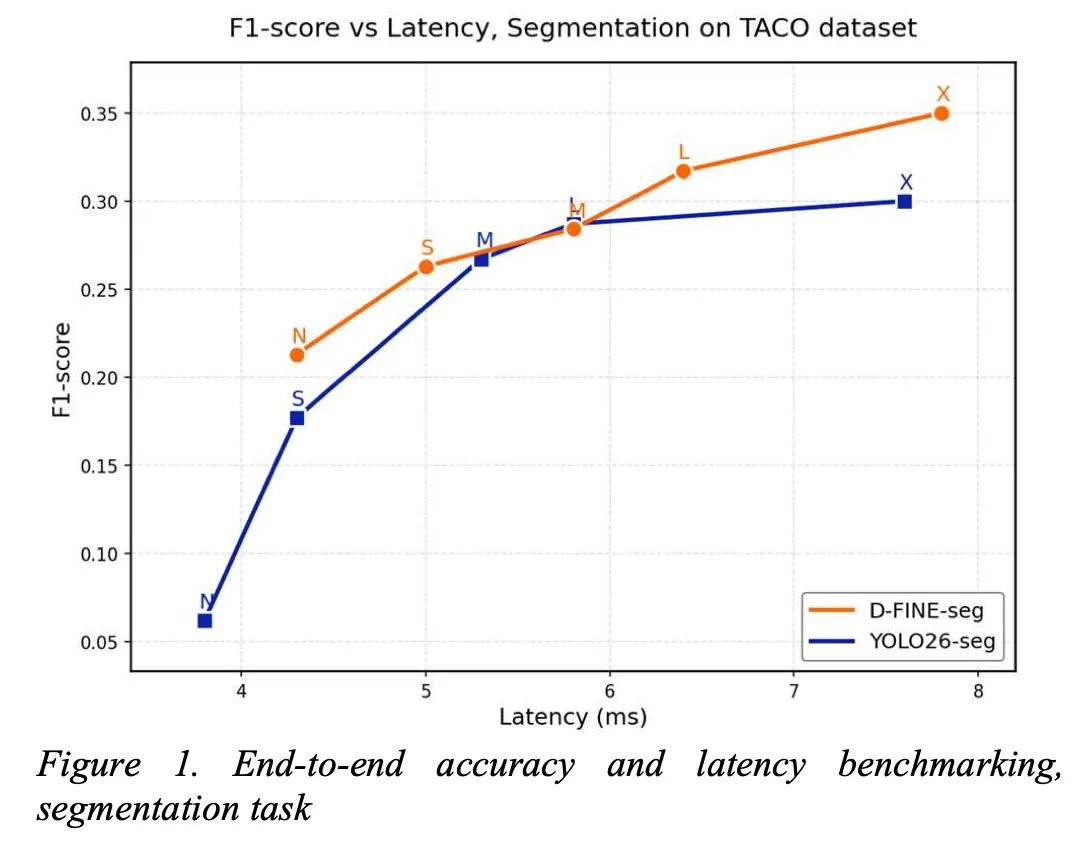
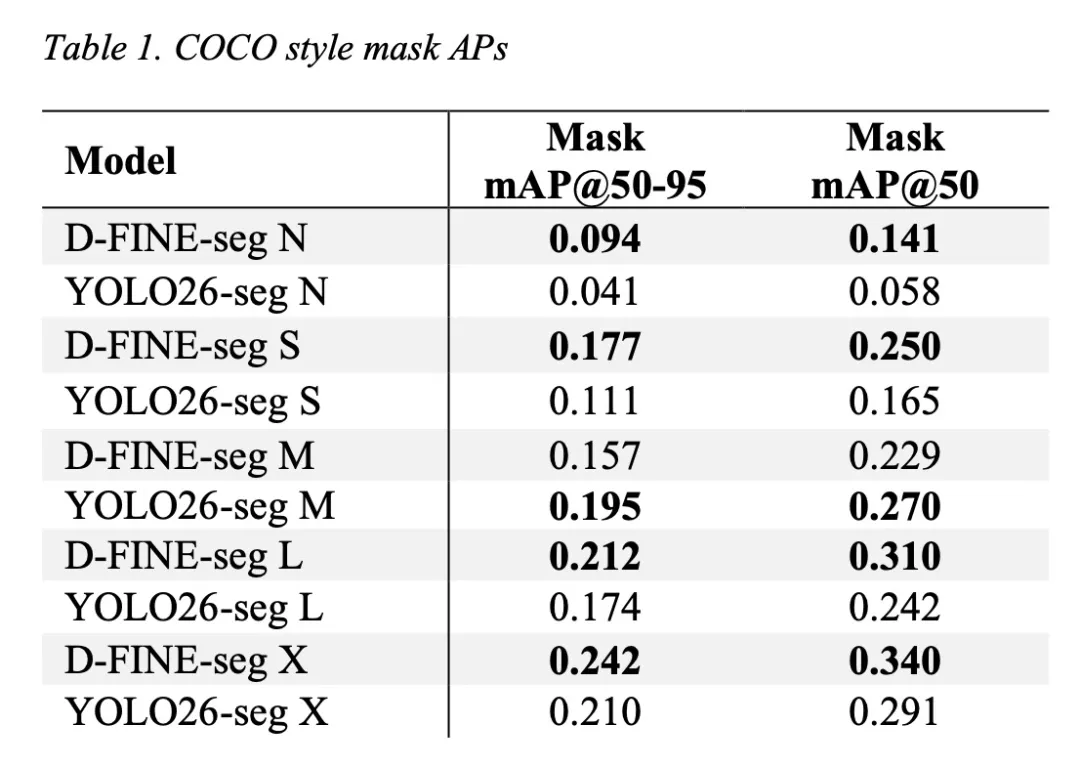
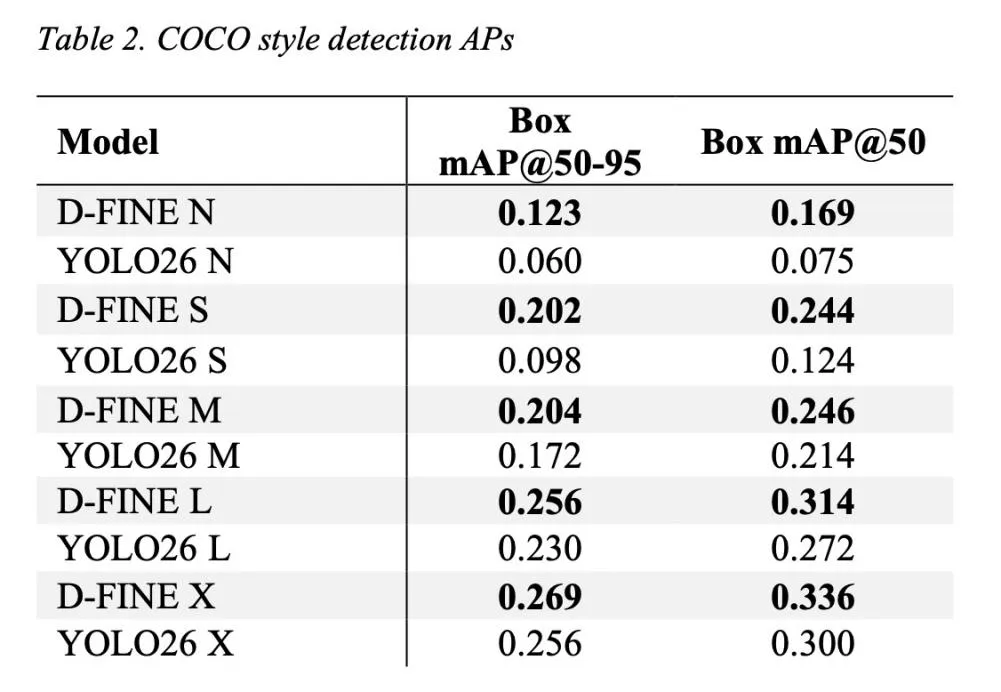
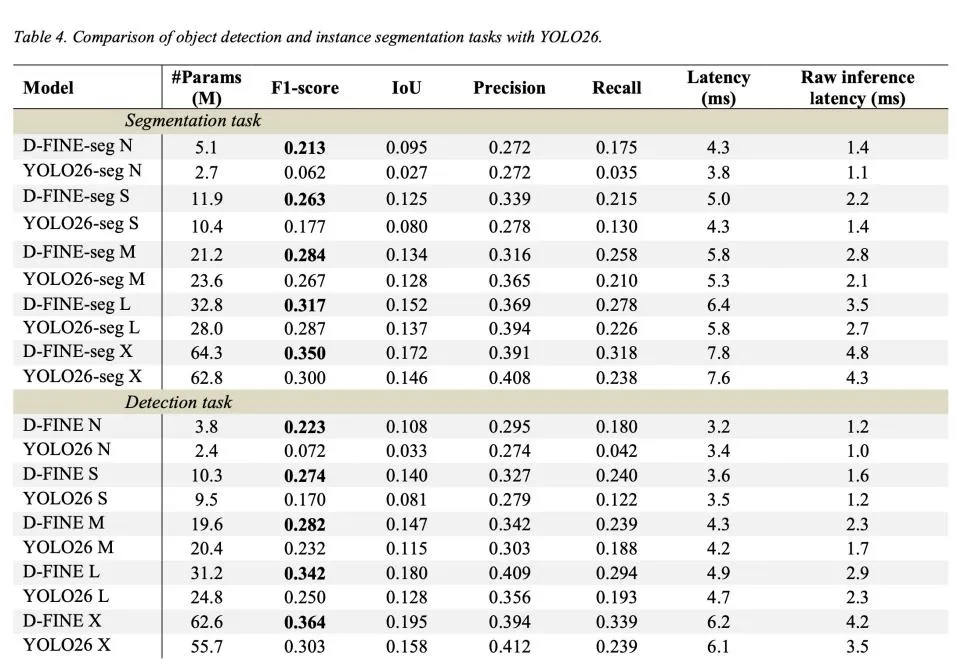
实战评测:与YOLO26正面对决
为了验证真实性能,作者在TACO数据集(1500张图像,59类废弃物)上,将D-FINE-seg与Ultralytics YOLO26进行了全面对比。评测条件非常贴近实际部署:
- 统一输入尺寸:640×640
- 均使用COCO预训练权重进行微调
- 统一转换为TensorRT FP16格式
- 端到端延迟测量:包含预处理、GPU前向、后处理全过程
- 使用框架默认置信度阈值(YOLO26为0.25,D-FINE-seg为0.5)
图片5.png
图片6.png
图片7.png
综合评价
D-FINE-seg的优势:
- 精度领先:在多数模型尺寸下,检测和分割精度均超越YOLO26
- 端到端设计:无需NMS,推理流程简洁
- 部署友好:原生支持ONNX/TensorRT/OpenVINO,提供完整基准测试工具
- 配置灵活:单配置文件管理训练、导出、推理全流程
- 开源协议宽松:Apache-2.0,商业应用友好
图片8.png
图片9.png
目前的局限性:
- 预训练权重待完善:掩码头尚未在COCO上预训练,当前需从随机初始化微调(作者已列为未来工作)
- 超大模型延迟略高:在X尺寸上,分割延迟比YOLO26高约0.6ms
- 生态成熟度:相比YOLO庞大的社区和工具链,D-FINE-seg尚属新生力量
总结
D-FINE-seg的发布,为实时实例分割领域带来了一个极具竞争力的新选择。它在精度上展现了明显优势,部署能力上考虑周全,且完全开源。虽然生态建设需要时间,但其技术路线的先进性已毋庸置疑。
对于追求高精度、需要端到端部署方案,且愿意尝试新架构的开发者,D-FINE-seg绝对值得加入候选列表。它或许还不是“YOLO杀手”,但无疑是当前最有力的挑战者。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号