200行代码实现Claude Code青春版


关注腾讯云开发者,一手技术干货提前解锁👇
01
写在最前面的闲聊
很早就开始尝试用AI辅助写代码,当时的感受是:对于一些不需要太多上下文的小需求(最终的产物是代码片段,直接复制粘贴改改输入一般就能用)还是非常好用的;但当用于完整项目中时就一言难尽了,早期我用cursor最常遇到的是AI"小题大作",直接往项目里各种新增脚本,新增大量的代码,有被无语到,以至于使用频率降低到最后退订(当然这里还存在我自己的问题,对于让AI Coding的需求不够具体)
下半年伴随着各种AI编程助手的进一步产品化,Spec Coding的大火,AI Coding成为了AI落地最快最大规模的领域之一,各种Coding Agent被迅速神化。由于带着前期的偏见,迟迟不愿尝试,直到近两个月看到各种大幅提效的案例后重新入坑,不得不说一句:真香!
大量的市场营销和Coding Agent领域新名词、新技术的出现使其变得格外"性感",容易给人一种错觉:它好像会思考、会规划、会自主完成复杂工程任务、10倍程序员、智能的跃迁等。然而,这种拟人化的叙事反而构成了理解其技术边界的认知迷雾。
在帮助了几位开发or产品同学理解、科学使用AI Coding来解决一些问题后,决定写下这篇文章,希望能够帮忙大家理解Coding Agent本质,从而合理预期其能力边界、更有效地使用这些工具,真正做到从从容容、游刃有余(狗头)
不太性感的事实
即使是效果惊艳的Coding Agent的本质其实是一个 while 循环,加上一整套上下文工程,OVER
02
从产品体验总结规律
为了避免被产品形态、UI 设计和营销语言干扰,我们先做一个极端抽象:忽略工具名字,忽略品牌,只看系统在做什么。不管是 Claude Code、Cursor 还是 Cline,当你连续使用它们一段时间后,会发现一个非常稳定的共同模式:
- 你提出一个目标
- 系统读取一些代码或环境信息
- 模型输出一个"下一步行动"
- 如果这个行动需要访问外部世界,就调用工具
- 工具执行完后,把结果再交还给模型
- 重复以上过程,中途也可以人工干预这个流程会一直持续,直到模型认为"任务已经完成"。这里有一个关键点:系统本身并不知道"任务是否完成"。结束条件并不是程序判断的,而是LLM在某一次输出中,选择不再调用工具。
从工程实现角度看,你可以试着把任何一个 AI Coding Agent 的行为,用伪代码表达出来,几乎都会收敛到如下结构:
while not done:
observation = collect_context()
action = llm(observation)
if action is tool_call:
result = execute(action)
append_to_context(result)
else:
done = True这不是某一个产品的实现方式,而是所有这类系统的必然形态。
原因也很简单:只要系统的"决策逻辑"在模型中,而LLM本身是无状态的,那么你就只能通过不断重放上下文,来模拟"持续思考"。
所谓 Agent,其实就是用循环,模拟连续性。
03
真正的复杂性在哪里:不在循环,在上下文
如果控制流如此简单,那为什么这些Coding Agent看起来仍然"很聪明"?
答案在于:复杂性被转移了位置。
在传统软件系统中,复杂性可能主要体现在:
- 状态机设计
- 数据结构
- 算法与约束
而在 AI Coding Agent 中,这些复杂性被大量挤压、甚至直接消失了。取而代之的,是一种新的工程重心:上下文工程(Context Engineering),上下文工程不是一个学术名词,而是一个非常工程化的事实描述:如何决定“这一轮模型调用时,让模型看到什么”。
模型不会记住过去;模型也不会理解系统;模型只会基于当前输入文本,生成下一个输出。
于是,Agent (在使用相同模型情况下)的能力高低,几乎完全取决于以下问题:
- 你给它看了哪些文件?
- 你如何压缩历史对话?
- 你用什么方式表达规则?
- 你是否让工具输出“可供下一轮使用”的结构化信息?
04
同样是while+context:以前做不到,现在能了?
有个强大的LLM是展示Coding Agent能力不可或缺的,以前还没有足够强的LLM的时候,基于while循环的Agent,可能模型会乱来、状态会对不上、很快跑偏;随着LLM的长上下文能力、多步推理能力、可被 prompt 约束成"角色 + 目标 + 工具使用规范"不断提高,现在才“工程可用”。
05
重新理解那些“听起来很高级”的概念
首先抓住请求LLM时的本质:每次请求其实就是把"System Prompt + 对话历史"作为输入发送给LLM,这输入就是上下文的全部。所有的优化和差异化都体现在如何构建这个上下文。
5.1 MCP连接万物
有些信息对于很多使用者来说都是需要用到的上下文,MCP server的作用其实就是标准化的上下文提供者。听起来像是新一代 Agent 架构,但从工程角度看,它解决的仍然是同一个问题:如何把外部信息,稳定、可控地塞进模型上下文。
5.2 Rules是系统提示词的补充
很多人把 .cursorrules 当作配置文件,但它本质上是系统提示词的硬编码补丁。如果没有规则,模型必须从概率分布中“猜”你想用 TypeScript 还是 JavaScript。 当你在 .cursorrules 里写下“总是使用 Tailwind CSS”时,你实际上是在系统层面对模型的生成树进行了剪枝,减少熵增,防止模型在无限的可能性中跑偏。
5.3 SpecCoding是提示词的重复
“Vibe Coding”最大的问题是:随着 while 循环的进行,早期的对话会被挤出上下文窗口,模型会“遗忘”最初的需求。Spec Coding 通过引入 AGENTS.md 或 spec.md,给 Agent 挂载了一块“只读存储器(ROM)”。无论循环跑了多少轮,Agent 被强制要求在行动前先读取这个文件,从而拥有持久化的上下文锚点。能够一定程度对抗“上下文漂移”(Context Drift),解决长任务中的健忘症。
5.4 SKILLS还是提示词
没有网上吹的那么神(也不是否认它对生态的重要性)!skills就是个markdown文件+tools,本质上进入大模型的也还是个prompt,并不能让你的agent起飞,它的智能来源于你原来的prompt+tools有多智能,并不能真的让agent更加智能。它的优势在于更像是上下文的动态链接库,用完即走,避免一开始就把所有文档塞进上下文撑爆窗口。
5.5 未来新名词也还是提示词
比如这几天有些热度的Smart Forking号称永久记忆的工具,也还是通过一些策略把对话历史存档,然后检索到后贴进了上下文里。毕竟,现阶段的LLM都是无状态的,它给出的回答全部依赖"System Prompt + 对话历史",因此,延伸出再多的新名词在做的事情都是在把一些提示让LLM能够看到。
06
丢掉幻想,掌控上下文才能用好编程助手
理解了各种花里胡哨的新名词的本质都还是把一些提示喂给LLM后,我们可以来思考下自己拿Coding Agent做的一些事情是不是make sense,这里举两个使用不当的例子:
- X产品同学听说Coding Agent能帮忙分析各种数据,于是把一整个数据表塞给AI,然后就开始了vibe analysis。一些专用、定制化的Agent确实能够辅助做一些数据分析,但它们往往是依赖一些工具对原始数据进行了处理,AI并不能帮你把数据都读了来处理,先不说上下文够不够读下原始数据,一些分析能力它甚至不如excel。
- Y开发同学听说Coding Agent辅助项目代码开发很方便,于是挂上整个代码仓库就开始了AI Coding,但是业务代码往往有很多的代码依赖,AI上下文没那么大,并不是真的把你的代码仓库都读进去了,那在缺失代码依赖信息的情况下你是不能指望AI写出满意的代码的。这也是为什么现在spec coding能够更加work的原因,把代码依赖(也就是需要的上下文信息)说明清楚,才能够创造有价值的内容。
因此,大家在使用Coding Agent或其他AI时都建议要掌控上下文,才能抓住它的能力边界!祝大家都不要被AI幻觉所欺骗!
07
Talk is cheap,200行代码实现
为了进一步加强大家的感受,我们来构建一个AI Coding Agent的最小实现
- 工具定义:Agent 能做什么,完全由工具决定
def execute_bash(command: str) -> str:
def read_file(path: str) -> str:
def write_file(path: str, content: str) -> str:
def list_files(path: str = ".") -> str:Agent 没有能力,只有工具。大模型不会“执行代码”,它只会决定要不要调用某个工具。
- Tool Schema:MCP 的最小等价形式
TOOLS_SCHEMA = [
{
"type": "function",
"function": {
"name": "read_file",
"description": "...",
"parameters": {...}
}
}
]这正是 MCP 的本质:用结构化方式,把工具能力描述进 prompt。没有魔法。
- system prompt:Rules / Skills 的本体
system_prompt = """
你是一个智能编程助手。
工作原则:
1. 修改前先读文件
2. 修改后尽量运行测试
"""这就是:Rules、Best Practices、Coding Guideline,全部都是 system prompt。
- Agent 主循环
while True: # ← 内层循环:Agent 自主执行
# Think: LLM 推理
response = client.chat.completions.create(
messages=messages, # ← 完整的上下文历史
tools=TOOLS_SCHEMA, # ← 可用工具列表
)
# Act: 执行工具
if message.tool_calls:
for tool_call in message.tool_calls:
result = AVAILABLE_FUNCTIONS[func_name](**func_args)
# Observe: 将结果反馈给 Agent
messages.append({
"role": "tool",
"content": result, # ← 执行结果注入 context
})
continue # ← 继续循环
else:
break # ← 没有工具调用,任务完成这就是 ReAct 模式(Reasoning + Acting):
- Reasoning:LLM 思考下一步该做什么
- Acting:调用工具执行动作
- Observing:观察结果,更新上下文
- 循环:重复上述过程直到任务完成
这就是 AI Coding Agent 的完整控制流,无论是Claude Code、Cline、Cursor都万变不离其中。但是对于对AI来说:只有「下一轮 prompt」是什么
- 完整代码实现,只要替换一个openai兼容的key就可以跑起来
import os
import json
import subprocess
from openai import OpenAI
# =============================================================================
# 1. 定义工具 (Define Tools)
# =============================================================================
def execute_bash(command: str) -> str:
"""执行 Bash 命令"""
print(f" > [执行命令] \033[93m{command}\033[0m")
print(f" > [执行中] {command}")
result = subprocess.run(
command, shell=True, capture_output=True, text=True, timeout=30
)
output = result.stdout + result.stderr
if output:
print(f" > [输出]\n{output.rstrip()}")
# 截断过长的输出
if len(output) > 2000:
output = output[:2000] + "\n... (输出过长已截断)"
return output.strip() or "(无输出)"
def read_file(path: str) -> str:
"""读取文件内容"""
print(f" > [读取文件] {path}")
if not os.path.exists(path):
return f"文件不存在: {path}"
with open(path, "r", encoding="utf-8") as f:
content = f.read()
# 给代码加上行号,方便 Agent 指定修改位置
lines = content.splitlines()
numbered_lines = [f"{i+1:4d} | {line}" for i, line in enumerate(lines)]
return "\n".join(numbered_lines)
def write_file(path: str, content: str) -> str:
"""写入文件内容"""
print(f" > [写入文件] {path}")
os.makedirs(os.path.dirname(os.path.abspath(path)), exist_ok=True)
with open(path, "w", encoding="utf-8") as f:
f.write(content)
return f"成功写入 {len(content)} 字节到 {path}"
def list_files(path: str = ".") -> str:
"""列出当前目录下的文件结构"""
print(f" > [列出文件] {path}")
# 简单的递归列出文件
file_list = []
for root, dirs, files in os.walk(path):
for file in files:
if not file.startswith('.'):
rel_path = os.path.relpath(os.path.join(root, file), path)
file_list.append(rel_path)
result = "\n".join(file_list[:50]) # 限制返回数量
print(f" > 包含文件:\n{result}")
return result
# =============================================================================
# 2. 定义工具描述 (Define Tool Schemas)
# =============================================================================
TOOLS_SCHEMA = [
{
"type": "function",
"function": {
"name": "execute_bash",
"description": "执行 shell 命令。用于运行测试、安装依赖或文件操作。",
"parameters": {
"type": "object",
"properties": {
"command": {"type": "string", "description": "要执行的 bash 命令"}
},
"required": ["command"],
},
},
},
{
"type": "function",
"function": {
"name": "read_file",
"description": "读取文件内容。内容会包含行号。",
"parameters": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "文件路径"}
},
"required": ["path"],
},
},
},
{
"type": "function",
"function": {
"name": "write_file",
"description": "创建或覆盖文件内容。",
"parameters": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "文件路径"},
"content": {"type": "string", "description": "要写入的完整内容"},
},
"required": ["path", "content"],
},
},
},
{
"type": "function",
"function": {
"name": "list_files",
"description": "列出当前项目的文件结构。",
"parameters": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "目录路径,默认为 '.'"}
},
"required": [],
},
},
},
]
AVAILABLE_FUNCTIONS = {
"execute_bash": execute_bash,
"read_file": read_file,
"write_file": write_file,
"list_files": list_files,
}
# =============================================================================
# 3. Agent 主循环 (The Agent Loop)
# =============================================================================
def run_toy_claude():
client = OpenAI()
# 系统提示词:设定人设
system_prompt = """
你是一个智能编程助手。
你的目标是帮助用户编写、调试和理解代码。
工作原则:
1. 在修改代码前,先使用 list_files 查看项目结构,或使用 read_file 读取相关文件。
2. 每次修改文件后,尽量运行代码或测试来验证修改(使用 execute_bash)。
3. 保持回答简洁,专注于解决问题。
"""
messages = [{"role": "system", "content": system_prompt}]
print("🤖 Toy Claude Code 已启动 (输入 'exit' 退出)")
print("--------------------------------------------")
# 外层循环:处理用户输入 (REPL)
while True:
try:
user_input = input("\n👤 你: ")
if user_input.lower() in ['exit', 'quit']:
print("再见!")
break
messages.append({"role": "user", "content": user_input})
# 内层循环:Agent 自主执行 (Think -> Act -> Observe)
# 只要 Agent 还在调用工具,就一直在这个循环里
while True:
response = client.chat.completions.create(
model="gpt-5-codex",
messages=messages,
tools=TOOLS_SCHEMA,
)
message = response.choices[0].message
messages.append(message)
if message.tool_calls:
print(f"\n🤖 思考: {message.content or '(准备调用工具...)'}")
for tool_call in message.tool_calls:
func_name = tool_call.function.name
func_args = json.loads(tool_call.function.arguments)
if func_name in AVAILABLE_FUNCTIONS:
# 执行工具
result = AVAILABLE_FUNCTIONS[func_name](**func_args)
else:
result = f"错误: 未知工具 {func_name}"
# 将结果反馈给 Agent
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"name": func_name,
"content": result,
})
else:
# 没有工具调用,说明是最终回复
print(f"\n🤖 回复:\n{message.content}")
break
except KeyboardInterrupt:
print("\n操作已取消。")
break
except Exception as e:
print(f"\n发生错误: {e}")
break
if __name__ == "__main__":
run_toy_claude()我们再来看一下这样一个简单的工具是不是真的能跑起来
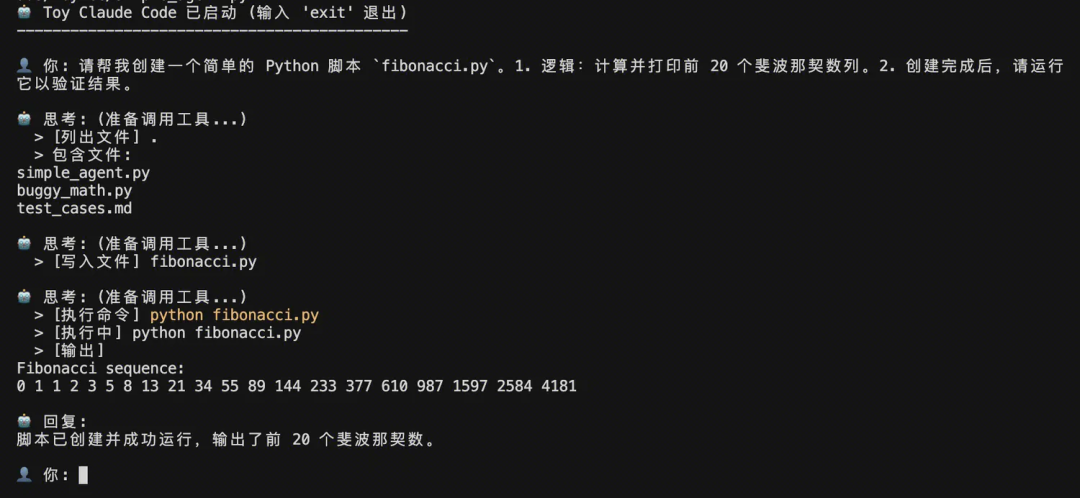
- 请帮我创建一个简单的 Python 脚本 fibonacci.py。1. 逻辑:计算并打印前 20 个斐波那契数列。2. 创建完成后,请运行它以验证结果。
- 修改代码
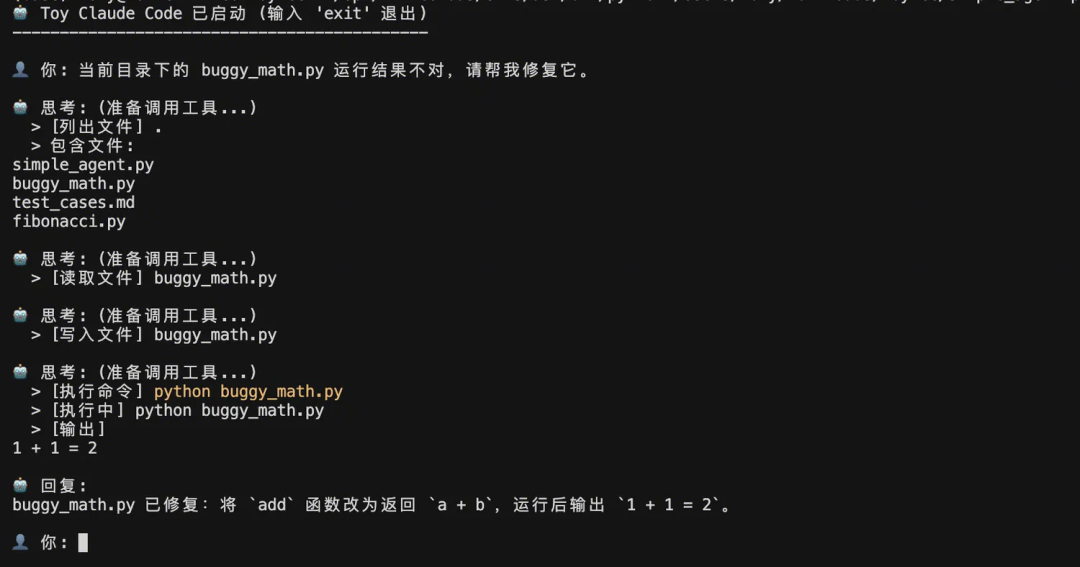
假设当前目录下有个脚本buggy_math.py
def add(a, b):
return a - b # 错误:应该是加法
print(f"1 + 1 = {add(1, 1)}")当前目录下的 buggy_math.py 运行结果不对,请帮我修复它。
08
Finally
理解并实现一个Coding Agent并不难,但是把这样一个产品做好却是很艰难的。致敬各种AI Coding工具包括公司内的CodeBuddy(让白嫖了好多外部高级模型的token)。
每一代工具,都会逼迫工程师重新理解自己的角色。AI Coding Agent 并没有消灭软件工程,它只是把一部分执行成本,压缩到了极低。
在这个过程中,最重要的能力迁移发生在于:从“如何写代码”,转向“如何设计约束、上下文和验证机制”。
理解 Agent 的本质是为了避免在幻觉中做错误决策。当你真正看清它只是一个 while 循环 + 上下文工程时,你反而会更清楚—— 哪些事情,仍然必须由人来完成。
-End-
原创作者|陈铭豪
感谢你读到这里,不如关注一下?👇

你对本文内容有哪些看法?同意、反对、困惑的地方是?欢迎留言,我们将邀请作者针对性回复你的评论,欢迎评论留言补充。我们将选取1则优质的评论,送出腾讯云定制文件袋套装1个(见下图)。3月10日中午12点开奖。

扫码领取腾讯云开发者专属服务器代金券!

图片





本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号