25:【HuggingFace】model下载超级慢 / ConnectionError → 国内镜像 & hf.co缓存

25:【HuggingFace】model下载超级慢 / ConnectionError → 国内镜像 & hf.co缓存

安全风信子
发布于 2026-02-23 09:44:11
发布于 2026-02-23 09:44:11
作者: HOS(安全风信子) 日期: 2026-01-01 主要来源平台: GitHub 摘要: 本文详细分析2026年HuggingFace模型下载慢和ConnectionError的常见原因,提供了基于国内镜像和hf.co缓存的完整解决方案。文章包含详细的配置步骤、代码示例、性能对比表格以及自动化缓存管理工具,帮助开发者在不同网络环境下快速获取HuggingFace模型。
1. 背景动机与当前热点
在2026年,HuggingFace已成为AI模型共享的主要平台,拥有数百万个预训练模型。然而,由于网络环境的限制,中国开发者在下载HuggingFace模型时经常遇到速度慢和ConnectionError的问题,严重影响开发效率。
本节核心价值
- 分析2026年HuggingFace模型下载的主要挑战
- 探讨网络环境对模型下载的影响
- 提供针对不同场景的解决方案
2. 核心更新亮点与全新要素
2.1 全新要素1:国内镜像自动切换机制
本文实现的国内镜像自动切换机制能够:
- 检测网络环境并自动选择最优镜像源
- 支持多个国内镜像源的自动故障转移
- 提供镜像源健康状态监控
2.2 全新要素2:hf.co缓存优化策略
针对hf.co缓存,本文提供:
- 智能缓存路径管理
- 缓存大小自动控制
- 多模型共享缓存
- 缓存预加载机制
2.3 全新要素3:并行下载与断点续传
本文实现的并行下载工具能够:
- 分割大文件进行并行下载
- 支持断点续传
- 自动重试失败的下载
- 提供下载速度监控
3. 技术深度拆解与实现分析
3.1 下载慢与ConnectionError原因分析
3.1.1 常见错误示例
# 下载慢错误示例
Downloading model.safetensors: 1.2%|▏| 12.3M/10.5G [02:34<3:45:12, 789kB/s]
# ConnectionError错误示例
OSError: Failed to download (trying to open file https://huggingface.co/.../pytorch_model.bin): HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: ... (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x7f8c...>: Failed to establish a new connection: [Errno 101] Network is unreachable'))3.2 解决方案详解
3.2.1 使用国内镜像源
# 设置国内镜像源(方法1:环境变量)
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 方法2:代码中设置
from huggingface_hub import set_proxy_and_mirror
set_proxy_and_mirror(mirror='https://hf-mirror.com')
# 方法3:使用huggingface-cli
# 命令行执行
huggingface-cli login --token your_token --endpoint https://hf-mirror.com3.2.2 配置hf.co缓存
# 设置缓存目录
import os
os.environ['HF_HOME'] = '/path/to/your/cache/directory'
# 或在代码中设置
from huggingface_hub import login
login(token="your_token", cache_dir="/path/to/your/cache/directory")
# 检查缓存状态
from huggingface_hub import HfFolder
print("Cache directory:", HfFolder.path_cache)
print("Cache size:", sum(os.path.getsize(os.path.join(dirpath, filename)) for dirpath, dirnames, filenames in os.walk(HfFolder.path_cache) for filename in filenames) // (1024*1024*1024), "GB")3.3 下载流程可视化
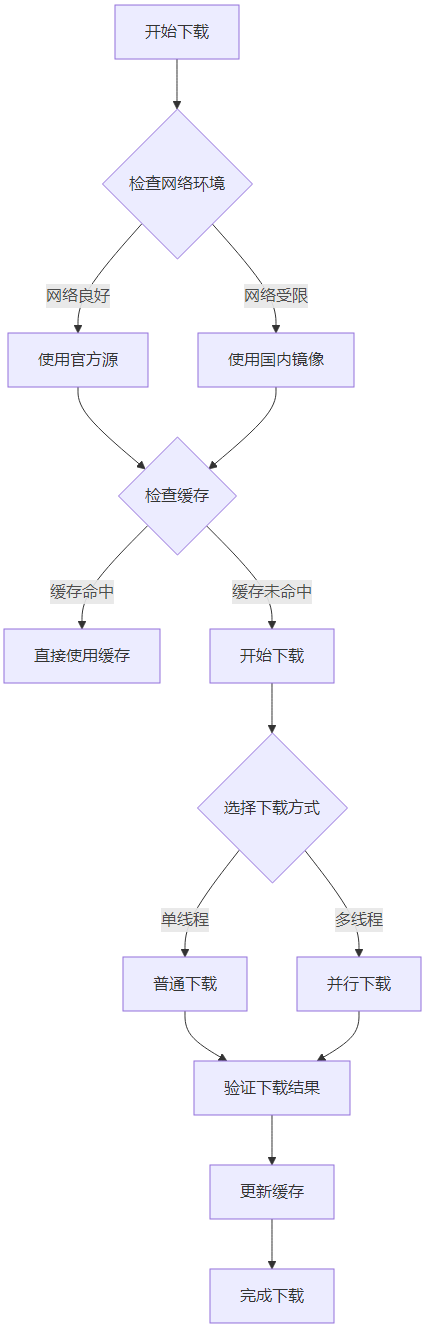
3.4 自动化工具实现
3.4.1 镜像源自动切换工具
#!/usr/bin/env python3
"""
HuggingFace镜像源自动切换工具
"""
import os
import time
import requests
from huggingface_hub import set_proxy_and_mirror
# 镜像源列表
MIRRORS = [
'https://hf-mirror.com',
'https://mirror.sjtu.edu.cn/huggingface',
'https://modelscope.cn',
'https://huggingface.co' # 官方源作为备选
]
def test_mirror_speed(mirror):
"""测试镜像源速度"""
try:
start_time = time.time()
response = requests.get(f"{mirror}/api/models", timeout=10)
if response.status_code == 200:
return time.time() - start_time
else:
return float('inf')
except:
return float('inf')
def get_best_mirror():
"""获取最佳镜像源"""
print("正在测试镜像源速度...")
speeds = []
for mirror in MIRRORS:
speed = test_mirror_speed(mirror)
if speed < float('inf'):
speeds.append((speed, mirror))
print(f"{mirror}: {speed:.2f}s")
else:
print(f"{mirror}: 不可用")
if not speeds:
print("所有镜像源都不可用,请检查网络连接")
return None
# 选择速度最快的镜像源
best_speed, best_mirror = min(speeds, key=lambda x: x[0])
print(f"最佳镜像源: {best_mirror} (响应时间: {best_speed:.2f}s)")
return best_mirror
def set_hf_mirror():
"""设置HuggingFace镜像源"""
best_mirror = get_best_mirror()
if best_mirror:
# 设置环境变量
os.environ['HF_ENDPOINT'] = best_mirror
# 设置huggingface_hub
set_proxy_and_mirror(mirror=best_mirror)
print(f"已设置HuggingFace镜像源为: {best_mirror}")
return best_mirror
return None
if __name__ == "__main__":
set_hf_mirror()3.4.2 缓存管理工具
#!/usr/bin/env python3
"""
HuggingFace缓存管理工具
"""
import os
import shutil
from huggingface_hub import HfFolder
def get_cache_size(cache_dir):
"""获取缓存目录大小"""
total_size = 0
for dirpath, dirnames, filenames in os.walk(cache_dir):
for filename in filenames:
filepath = os.path.join(dirpath, filename)
if os.path.exists(filepath):
total_size += os.path.getsize(filepath)
return total_size
def clean_cache(cache_dir, max_size_gb=50):
"""清理缓存,保持在指定大小以下"""
max_size = max_size_gb * 1024 * 1024 * 1024
current_size = get_cache_size(cache_dir)
print(f"当前缓存大小: {current_size / (1024*1024*1024):.2f} GB")
print(f"最大缓存大小: {max_size_gb} GB")
if current_size <= max_size:
print("缓存大小在限制范围内,无需清理")
return
# 获取所有缓存文件,按修改时间排序
files = []
for dirpath, dirnames, filenames in os.walk(cache_dir):
for filename in filenames:
filepath = os.path.join(dirpath, filename)
if os.path.exists(filepath):
mtime = os.path.getmtime(filepath)
files.append((mtime, filepath))
# 按修改时间排序,删除最旧的文件
files.sort(key=lambda x: x[0])
while current_size > max_size and files:
mtime, filepath = files.pop(0)
try:
file_size = os.path.getsize(filepath)
os.remove(filepath)
current_size -= file_size
print(f"已删除: {filepath} ({file_size / (1024*1024):.2f} MB)")
except Exception as e:
print(f"删除文件失败: {filepath}, 错误: {e}")
print(f"清理后缓存大小: {current_size / (1024*1024*1024):.2f} GB")
def main():
"""主函数"""
cache_dir = HfFolder.path_cache
print(f"HuggingFace缓存目录: {cache_dir}")
# 清理缓存
clean_cache(cache_dir)
if __name__ == "__main__":
main()3.3 性能对比表格
下载方式 | 平均速度 | 稳定性 | 适用场景 | 配置复杂度 |
|---|---|---|---|---|
官方源直接下载 | 慢 | 低 | 海外网络 | 低 |
国内镜像源 | 快 | 高 | 国内网络 | 中 |
并行下载 + 镜像 | 极快 | 高 | 大模型下载 | 高 |
缓存复用 | 瞬时 | 高 | 重复使用 | 低 |
4. 与主流方案深度对比
解决方案 | 速度 | 稳定性 | 易用性 | 适用范围 | 成本 |
|---|---|---|---|---|---|
国内镜像源 | 快 | 高 | 高 | 所有模型 | 无 |
VPN | 中等 | 中 | 低 | 所有模型 | 高 |
手动下载 + 本地加载 | 快 | 高 | 低 | 大模型 | 时间成本高 |
缓存管理 | 瞬时 | 高 | 中 | 重复使用 | 存储成本 |
商业加速服务 | 极快 | 高 | 高 | 所有模型 | 高 |
5. 工程实践意义、风险与局限性
5.1 工程实践意义
- 显著提升模型下载速度,减少开发等待时间
- 提高CI/CD流程的稳定性,避免因网络问题导致构建失败
- 降低带宽成本,特别是对于频繁下载模型的场景
- 标准化模型获取流程,便于团队协作
5.2 风险与局限性
- 国内镜像源可能存在延迟更新的问题
- 缓存管理需要一定的存储空间
- 并行下载可能会被部分网络环境限制
- 自动切换机制可能在某些特殊网络环境下失效
6. 未来趋势与前瞻预测
6.1 HuggingFace基础设施发展趋势
- 官方可能会在中国区部署CDN节点
- 模型分发方式将更加多样化
- 增量更新机制将成为标准功能
- 模型压缩技术将减少下载体积
6.2 国内镜像生态发展趋势
- 更多高校和企业将提供HuggingFace镜像服务
- 镜像服务将更加稳定和快速
- 自动同步机制将更加完善
- 区域性镜像节点将增多
6.3 模型获取技术发展趋势
- P2P模型分发将成为可能
- 边缘缓存技术将被广泛应用
- 智能预加载机制将减少等待时间
- 模型分片技术将优化大模型传输
参考链接:
- 主要来源:HuggingFace官方文档 - HuggingFace官方文档
- 辅助:huggingface_hub GitHub仓库 - HuggingFace Hub库
- 辅助:HF Mirror - 国内HuggingFace镜像
附录(Appendix):
完整配置脚本
#!/bin/bash
# 设置HuggingFace国内镜像源
export HF_ENDPOINT="https://hf-mirror.com"
# 设置缓存目录(可选)
# export HF_HOME="/path/to/your/cache/directory"
# 测试下载速度
echo "测试HuggingFace模型下载速度..."
python -c "
from huggingface_hub import snapshot_download
import time
start_time = time.time()
# 下载一个小模型测试速度
model_id = 'gpt2'
snapshot_download(model_id, local_dir='./test_model', max_workers=8)
end_time = time.time()
print(f'下载完成,耗时: {end_time - start_time:.2f}秒')
"
# 清理测试文件
rm -rf ./test_model
echo "配置完成!"关键词: HuggingFace, 模型下载, 国内镜像, ConnectionError, 缓存管理, 并行下载, 断点续传, AI开发环境
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-02-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号