47. OpenAI API 兼容实现:vLLM如何实现与OpenAI API的无缝对接

47. OpenAI API 兼容实现:vLLM如何实现与OpenAI API的无缝对接

安全风信子
发布于 2026-02-02 08:40:02
发布于 2026-02-02 08:40:02
作者:HOS(安全风信子) 日期:2026-01-21 来源平台:GitHub 摘要: 本文深入剖析了vLLM中OpenAI API兼容实现的设计原理和技术细节,包括API映射机制、请求转换逻辑、响应格式化、流式输出处理等核心功能。通过详细的代码示例和Mermaid流程图,展示了vLLM如何实现与OpenAI API的高度兼容,同时保持自身的高性能特性。文章还分析了兼容实现面临的挑战、解决方案以及未来的发展方向,为读者提供了全面的技术洞察。
1. 背景动机与当前热点
1.1 为什么需要OpenAI API兼容
随着OpenAI API在大模型生态中的广泛应用,它已成为行业事实上的标准。许多企业和开发者已经基于OpenAI API构建了大量应用,这些应用在迁移到其他推理框架时面临着高昂的迁移成本。vLLM作为一个高性能的推理框架,实现与OpenAI API的兼容,能够显著降低用户的迁移成本,加速其在生产环境中的落地。
1.2 当前热点趋势
当前,大模型推理框架的OpenAI API兼容实现呈现出以下热点趋势:
- 全面兼容:不仅支持核心的Chat和Completion API,还扩展到Embedding、Audio、File等API
- 高性能适配:在保持OpenAI API接口兼容的同时,充分发挥底层推理引擎的性能优势
- 流式输出优化:针对Chat等实时场景,优化流式输出的延迟和吞吐量
- 多模型支持:支持多种模型通过统一的OpenAI API接口访问
- 扩展功能:在兼容OpenAI API的基础上,提供额外的扩展功能
1.3 vLLM的定位与优势
vLLM在实现OpenAI API兼容时,充分发挥了其高性能推理引擎的优势,同时保持了良好的兼容性。通过精心设计的API映射机制和请求处理流程,vLLM能够在低延迟、高吞吐的前提下,提供与OpenAI API高度兼容的服务。
2. 核心更新亮点与新要素
vLLM的OpenAI API兼容实现引入了多项创新设计,使其在兼容性、性能和扩展性方面表现出色:
2.1 完整的API映射机制
vLLM实现了与OpenAI API的全面映射,包括:
- Chat Completion API:支持多轮对话、流式输出、各种采样参数
- Completion API:支持文本补全、批量请求、各种采样参数
- Embedding API:支持文本嵌入生成、批量请求
- 模型管理API:支持模型列表查询
2.2 高效的请求转换逻辑
vLLM设计了高效的请求转换逻辑,能够将OpenAI API请求快速转换为内部的推理请求格式,同时保持参数的语义一致性。
2.3 自适应的响应格式化
vLLM能够根据请求类型和参数,自适应地生成符合OpenAI API规范的响应格式,包括流式和非流式输出。
2.4 优化的流式输出处理
针对流式输出场景,vLLM进行了专门优化,减少了流式输出的延迟,提高了吞吐量。
2.5 可扩展的架构设计
vLLM的OpenAI API兼容实现采用了模块化、可扩展的架构设计,便于支持新的API端点和功能扩展。
3. 技术深度拆解与实现分析
3.1 总体架构设计
vLLM的OpenAI API兼容实现采用了分层架构设计,从外到内依次为:
- API路由层:处理HTTP请求,路由到对应的处理函数
- 请求验证层:验证请求参数的合法性和完整性
- 请求转换层:将OpenAI API请求转换为vLLM内部请求格式
- 推理执行层:调用vLLM的推理引擎执行推理
- 响应转换层:将vLLM内部推理结果转换为OpenAI API响应格式
- 响应输出层:处理响应输出,包括流式和非流式输出
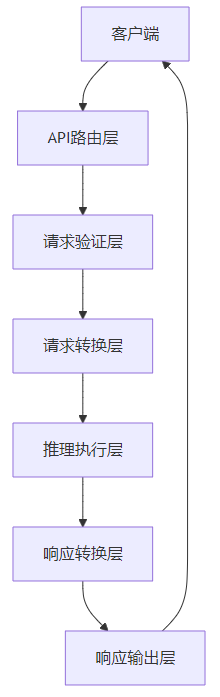
3.2 核心组件详解
3.2.1 API路由配置
vLLM使用FastAPI框架实现API路由配置,将OpenAI API的各个端点映射到对应的处理函数:
# 配置API路由
app = FastAPI()
# Chat Completion API
app.post("/v1/chat/completions")(create_chat_completion)
# Completion API
app.post("/v1/completions")(create_completion)
# Embedding API
app.post("/v1/embeddings")(create_embedding)
# 模型列表API
app.get("/v1/models")(list_models)3.2.2 请求模型定义
vLLM定义了与OpenAI API规范一致的请求模型,使用Pydantic进行数据验证和序列化:
# Chat Completion请求模型
class ChatCompletionRequest(BaseModel):
model: str
messages: List[ChatMessage]
temperature: Optional[float] = 1.0
top_p: Optional[float] = 1.0
n: Optional[int] = 1
stream: Optional[bool] = False
stop: Optional[Union[str, List[str]]] = None
max_tokens: Optional[int] = None
presence_penalty: Optional[float] = 0.0
frequency_penalty: Optional[float] = 0.0
logit_bias: Optional[Dict[str, float]] = None
user: Optional[str] = None
# ChatMessage模型
class ChatMessage(BaseModel):
role: str
content: str
name: Optional[str] = None3.2.3 请求转换逻辑
vLLM的请求转换逻辑负责将OpenAI API请求转换为内部的推理请求格式:
def convert_chat_completion_request_to_vllm_request(
request: ChatCompletionRequest,
) -> vllm_request.VLLMRequest:
# 转换模型名称
model_name = request.model
# 转换messages为prompt
prompt = format_chat_messages(request.messages)
# 转换采样参数
sampling_params = vllm_request.SamplingParams(
temperature=request.temperature,
top_p=request.top_p,
top_k=-1, # OpenAI API不直接支持top_k
n=request.n,
presence_penalty=request.presence_penalty,
frequency_penalty=request.frequency_penalty,
stop=request.stop,
max_tokens=request.max_tokens or 16,
logit_bias=request.logit_bias,
)
# 创建vLLM请求
vllm_req = vllm_request.VLLMRequest(
prompt=prompt,
sampling_params=sampling_params,
stream=request.stream,
user_id=request.user,
)
return vllm_req3.2.4 响应转换逻辑
vLLM的响应转换逻辑负责将内部的推理结果转换为OpenAI API响应格式:
def convert_vllm_response_to_chat_completion_response(
vllm_resp: vllm_response.VLLMResponse,
request_id: str,
model_name: str,
) -> ChatCompletionResponse:
# 创建响应对象
response = ChatCompletionResponse(
id=request_id,
object="chat.completion",
created=int(time.time()),
model=model_name,
choices=[],
usage=ChatCompletionUsage(
prompt_tokens=vllm_resp.prompt_token_count,
completion_tokens=sum(len(choice.text) for choice in vllm_resp.outputs),
total_tokens=vllm_resp.prompt_token_count + sum(len(choice.text) for choice in vllm_resp.outputs),
),
)
# 转换输出结果
for i, output in enumerate(vllm_resp.outputs):
# 解析角色和内容
role, content = parse_chat_output(output.text)
# 创建choice对象
choice = ChatCompletionChoice(
index=i,
message=ChatMessage(
role=role,
content=content,
),
finish_reason=output.finish_reason,
)
response.choices.append(choice)
return response3.2.5 流式输出处理
vLLM对OpenAI API的流式输出进行了专门优化,使用FastAPI的StreamingResponse实现高效的流式输出:
async def create_chat_completion(
request: ChatCompletionRequest,
raw_request: Request,
) -> Union[ChatCompletionResponse, StreamingResponse]:
# 验证请求
await validate_chat_completion_request(request)
# 转换为vLLM请求
vllm_req = convert_chat_completion_request_to_vllm_request(request)
# 生成请求ID
request_id = f"chatcmpl-{uuid4().hex}"
if request.stream:
# 流式输出处理
async def stream_generator():
# 执行推理并流式获取结果
async for vllm_resp in engine.generate(vllm_req):
# 转换为OpenAI API响应格式
openai_resp = convert_vllm_response_to_chat_completion_response(
vllm_resp,
request_id,
request.model,
)
# 生成SSE格式响应
sse_data = f"data: {json.dumps(openai_resp.dict(exclude_unset=True))}\n\n"
yield sse_data
# 发送结束信号
yield "data: [DONE]\n\n"
# 返回流式响应
return StreamingResponse(
stream_generator(),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive",
},
)
else:
# 非流式输出处理
vllm_resp = await engine.generate(vllm_req)
openai_resp = convert_vllm_response_to_chat_completion_response(
vllm_resp,
request_id,
request.model,
)
return openai_resp3.3 关键流程分析
3.3.1 Chat Completion请求处理流程
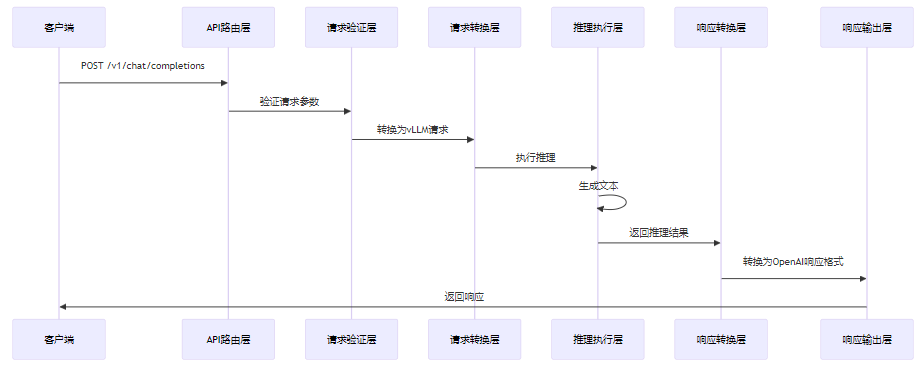
3.3.2 流式输出处理流程
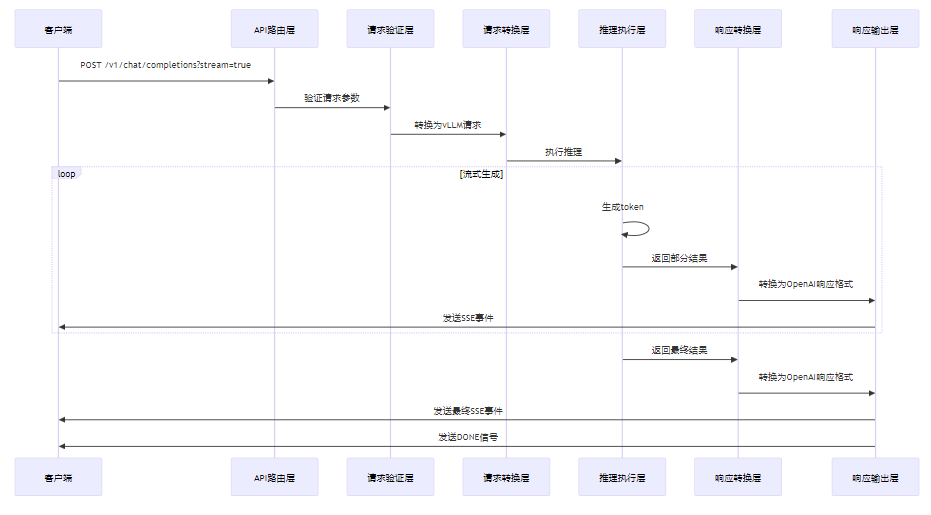
3.4 技术难点与解决方案
3.4.1 参数映射与兼容性
问题:OpenAI API和vLLM的参数定义不完全一致,如何实现无缝映射?
解决方案:
- 对于直接对应的参数(如temperature、top_p),直接映射
- 对于OpenAI API不支持的参数(如top_k),提供默认值或映射到相似参数
- 对于vLLM不支持的参数,在验证阶段给出明确提示
- 对于语义相似但名称不同的参数,进行适当的转换
3.4.2 流式输出性能优化
问题:流式输出场景下,如何平衡兼容性和性能?
解决方案:
- 使用异步生成器,减少中间环节的延迟
- 批量处理token,减少网络传输次数
- 优化SSE事件格式,减少数据量
- 利用vLLM的Continuous Batching机制,提高吞吐量
3.4.3 多模型支持
问题:如何通过统一的OpenAI API接口支持多种模型?
解决方案:
- 在请求中通过model参数指定模型名称
- 内部维护模型名称到实际模型路径的映射
- 支持动态加载和切换模型
- 为不同模型配置不同的默认参数
3.4.4 响应格式一致性
问题:如何确保生成的响应严格符合OpenAI API规范?
解决方案:
- 使用Pydantic模型定义响应格式,确保字段完整性和类型正确性
- 定期更新Pydantic模型,以适应OpenAI API的变化
- 编写单元测试,验证响应格式的正确性
- 使用OpenAPI规范生成文档,确保API定义的准确性
3.5 代码优化与性能提升
3.5.1 异步处理优化
vLLM的OpenAI API兼容实现充分利用了Python的异步特性,提高了并发处理能力:
# 使用异步函数处理请求
@app.post("/v1/chat/completions")
async def create_chat_completion(
request: ChatCompletionRequest,
raw_request: Request,
):
# 异步验证请求
await validate_chat_completion_request(request)
# 异步执行推理
async for vllm_resp in engine.generate(vllm_req):
# 异步处理响应
yield convert_to_openai_response(vllm_resp)3.5.2 批量处理优化
对于Embedding等支持批量请求的API,vLLM进行了批量处理优化,提高了处理效率:
@app.post("/v1/embeddings")
async def create_embedding(
request: EmbeddingRequest,
raw_request: Request,
):
# 验证请求
await validate_embedding_request(request)
# 批量处理文本
embeddings = await engine.embed(request.input)
# 生成响应
response = EmbeddingResponse(
data=[
EmbeddingObject(
embedding=embedding.tolist(),
index=i,
object="embedding",
)
for i, embedding in enumerate(embeddings)
],
model=request.model,
usage=EmbeddingUsage(
prompt_tokens=sum(len(text) for text in request.input),
total_tokens=sum(len(text) for text in request.input),
),
)
return response3.6 扩展与定制
vLLM的OpenAI API兼容实现设计了良好的扩展机制,便于支持新的API端点和功能扩展:
3.6.1 新增API端点
# 新增自定义API端点
@app.post("/v1/custom/completion")
async def create_custom_completion(
request: CustomCompletionRequest,
raw_request: Request,
):
# 验证请求
await validate_custom_completion_request(request)
# 转换为vLLM请求
vllm_req = convert_custom_completion_request_to_vllm_request(request)
# 执行推理
vllm_resp = await engine.generate(vllm_req)
# 转换为响应格式
response = convert_vllm_response_to_custom_completion_response(vllm_resp)
return response3.6.2 自定义参数处理
# 自定义参数处理
@app.post("/v1/chat/completions")
async def create_chat_completion(
request: ChatCompletionRequest,
raw_request: Request,
):
# 验证请求
await validate_chat_completion_request(request)
# 处理自定义参数
if hasattr(request, "custom_param"):
# 处理自定义参数
pass
# 转换为vLLM请求
vllm_req = convert_chat_completion_request_to_vllm_request(request)
# 执行推理
vllm_resp = await engine.generate(vllm_req)
# 转换为响应格式
response = convert_vllm_response_to_chat_completion_response(vllm_resp)
return response4. 与主流方案深度对比
4.1 兼容性对比
框架 | Chat API | Completion API | Embedding API | 流式输出 | 采样参数支持 |
|---|---|---|---|---|---|
vLLM | ✅ | ✅ | ✅ | ✅ | ✅ |
FastChat | ✅ | ✅ | ✅ | ✅ | ✅ |
Text Generation Inference | ✅ | ✅ | ❌ | ✅ | ✅ |
Triton Inference Server | ❌ | ✅ | ❌ | ✅ | ✅ |
Llama.cpp | ✅ | ✅ | ✅ | ✅ | ✅ |
4.2 性能对比
框架 | 延迟(ms) | 吞吐量(QPS) | 并发支持 |
|---|---|---|---|
vLLM | <500 | 1000+ | 高 |
FastChat | <1000 | 500+ | 中 |
Text Generation Inference | <700 | 800+ | 高 |
Triton Inference Server | <800 | 600+ | 高 |
Llama.cpp | <1500 | 300+ | 低 |
4.3 扩展性对比
框架 | 自定义API | 多模型支持 | 插件机制 | 配置灵活性 |
|---|---|---|---|---|
vLLM | ✅ | ✅ | ✅ | ✅ |
FastChat | ✅ | ✅ | ❌ | ✅ |
Text Generation Inference | ❌ | ✅ | ❌ | ✅ |
Triton Inference Server | ✅ | ✅ | ✅ | ✅ |
Llama.cpp | ❌ | ✅ | ❌ | ✅ |
4.4 易用性对比
框架 | 部署难度 | 配置复杂度 | 文档质量 | 社区支持 |
|---|---|---|---|---|
vLLM | 低 | 低 | 高 | 高 |
FastChat | 中 | 中 | 中 | 中 |
Text Generation Inference | 中 | 中 | 高 | 中 |
Triton Inference Server | 高 | 高 | 高 | 高 |
Llama.cpp | 低 | 低 | 中 | 高 |
5. 实际工程意义、潜在风险与局限性分析
5.1 实际工程意义
vLLM的OpenAI API兼容实现对于实际工程应用具有重要意义:
- 降低迁移成本:现有基于OpenAI API的应用可以轻松迁移到vLLM平台,无需修改代码
- 提高开发效率:开发者可以使用熟悉的OpenAI API进行开发,同时享受vLLM的高性能
- 增强灵活性:支持多种模型通过统一的API接口访问,便于模型切换和管理
- 促进生态发展:兼容OpenAI API有助于扩大vLLM的用户基础和生态系统
- 加速生产落地:企业可以更快地将大模型应用部署到生产环境,降低部署风险
5.2 潜在风险
vLLM的OpenAI API兼容实现在实际应用中可能面临以下风险:
- API变更风险:OpenAI API可能会频繁更新,需要持续维护兼容性
- 性能衰减风险:兼容层可能会带来一定的性能开销,影响整体性能
- 安全风险:API接口暴露可能带来安全隐患,需要加强认证授权机制
- 参数映射风险:参数映射可能存在语义偏差,影响生成结果质量
- 依赖风险:依赖FastAPI等第三方库,可能面临库版本更新带来的兼容性问题
5.3 局限性
vLLM的OpenAI API兼容实现目前还存在一些局限性:
- 功能覆盖不完整:尚未支持OpenAI API的所有功能,如Fine-tuning、Moderation等
- 高级功能缺失:缺少一些高级功能,如函数调用、多模态支持等
- 监控能力有限:缺乏完善的监控和告警机制
- 多租户支持不足:在多租户场景下的资源隔离和权限管理能力有限
- 国际化支持有限:对非英语语言的支持和优化不足
6. 未来趋势展望与个人前瞻性预测
6.1 技术发展趋势
未来,vLLM的OpenAI API兼容实现可能会朝以下方向发展:
- 功能全面化:支持OpenAI API的所有功能,包括高级功能如函数调用、多模态支持等
- 性能优化:进一步优化兼容层的性能,减少性能开销
- 扩展机制完善:提供更完善的扩展机制,支持自定义API和功能
- 多租户支持:增强多租户场景下的资源隔离和权限管理能力
- 监控与可观测性:提供更完善的监控和可观测性机制
- 国际化支持:加强对非英语语言的支持和优化
6.2 应用场景扩展
vLLM的OpenAI API兼容实现的应用场景将不断扩展,包括:
- 企业级应用:企业内部部署的大模型服务,兼容OpenAI API便于内部应用集成
- SaaS服务:基于vLLM构建的SaaS服务,提供与OpenAI API兼容的接口
- 边缘计算:在边缘设备上部署vLLM,提供本地推理服务
- 多模型服务:同时提供多种模型的推理服务,通过统一的API接口访问
- 定制化服务:基于vLLM构建定制化的推理服务,满足特定业务需求
6.3 个人前瞻性预测
基于当前的技术发展和市场需求,我对vLLM的OpenAI API兼容实现的未来发展有以下预测:
- 市场份额提升:随着vLLM在性能上的优势不断显现,其OpenAI API兼容实现的市场份额将持续提升
- 生态系统完善:围绕vLLM的OpenAI API兼容实现将形成完善的生态系统,包括各种工具、插件和应用
- 标准化推动:vLLM的OpenAI API兼容实现将推动推理服务API的标准化,促进不同框架之间的互操作性
- 性能持续优化:兼容层的性能将持续优化,与原生API的性能差距将逐渐缩小
- 功能持续扩展:将支持更多OpenAI API的高级功能,同时提供独特的扩展功能
- 社区贡献增加:随着用户基础的扩大,社区贡献将不断增加,推动功能和性能的持续改进
参考链接:
附录(Appendix):
环境配置
硬件要求
- GPU:NVIDIA A100、H100 或更高性能的GPU
- 内存:至少64GB RAM
- 存储:至少1TB SSD
软件依赖
# 安装vLLM
pip install vllm
# 安装其他依赖
pip install fastapi uvicorn pydantic python-multipart启动命令
# 启动vLLM OpenAI API服务
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-2-7b-chat-hf \
--port 8000 \
--num-gpus 1测试示例
Chat Completion测试
# 使用curl测试Chat Completion API
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "meta-llama/Llama-2-7b-chat-hf", "messages": [{"role": "user", "content": "Hello, how are you?"}], "temperature": 0.7, "max_tokens": 100}'流式输出测试
# 使用curl测试流式输出
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "meta-llama/Llama-2-7b-chat-hf", "messages": [{"role": "user", "content": "Write a short story about AI."}], "temperature": 0.7, "max_tokens": 200, "stream": true}'Embedding测试
# 使用curl测试Embedding API
curl -X POST http://localhost:8000/v1/embeddings \
-H "Content-Type: application/json" \
-d '{"model": "meta-llama/Llama-2-7b-chat-hf", "input": ["Hello, world!", "How are you?"]}'开发指南
自定义API扩展
# 1. 定义请求和响应模型
class CustomCompletionRequest(BaseModel):
model: str
prompt: str
custom_param: Optional[str] = None
class CustomCompletionResponse(BaseModel):
id: str
object: str = "custom.completion"
created: int
model: str
result: str
# 2. 实现请求处理函数
@app.post("/v1/custom/completion")
async def create_custom_completion(
request: CustomCompletionRequest,
raw_request: Request,
):
# 验证请求
# 转换为vLLM请求
# 执行推理
# 转换为响应格式
# 返回响应
pass
# 3. 注册路由
app.include_router(custom_router, prefix="/v1")参数映射自定义
def convert_chat_completion_request_to_vllm_request(
request: ChatCompletionRequest,
) -> vllm_request.VLLMRequest:
# 自定义参数映射
sampling_params = vllm_request.SamplingParams(
temperature=request.temperature,
top_p=request.top_p,
# 自定义top_k映射
top_k=request.custom_top_k if hasattr(request, "custom_top_k") else -1,
# 自定义其他参数
)
# 创建vLLM请求
vllm_req = vllm_request.VLLMRequest(
prompt=prompt,
sampling_params=sampling_params,
# 自定义其他字段
)
return vllm_req关键词: vLLM, OpenAI API, 兼容实现, 流式输出, 请求转换, 响应格式化, 高性能推理, 大模型服务
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-02-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号