深度拆解:AI如何挖深工业“护城河”?从强化学习看流程工程的降本增效
原创
深度拆解:AI如何挖深工业“护城河”?从强化学习看流程工程的降本增效
原创
走向未来
发布于 2026-01-30 14:12:41
发布于 2026-01-30 14:12:41
流程系统工程中的强化学习:应用现状、核心方法论和实践指南
走向未来
流程系统工程(Process Systems Engineering, PSE)的核心在于管理复杂过程,其本质是在不确定的条件下制定连续的决策。无论是操作一个分批补料的生物反应器,还是管理一个跨越全球的供应链,从业者始终面对一个根本性挑战:如何在平衡即时运营目标与长期系统性能之间做出最优选择,同时还要应对随机干扰和严格的操作限制。
传统方法,如模型预测控制(Model Predictive Control, MPC),在解决这些问题上展示了强大的能力,它们依赖精确的过程模型进行优化。然而,当系统展现出高度非线性、控制空间离散、或不确定性难以精确表述时,这些传统框架的有效性便会受限,尤其是在计算可行性方面。
强化学习(Reinforcement Learning, RL)为此提供了一个根本不同的解决路径。作为机器学习的一个分支,强化学习关注的是智能体如何通过与环境的直接互动,仅通过采样和经验,来学习一个最优的控制策略,以最小化累积成本。这种数据驱动的特性,使其能够绕过对完整、封闭形式的过程模型的需求,为解决流程系统工程中的复杂动态优化问题开辟了新的可能性。
本文旨在深度剖析强化学习方法在流程系统工程领域的应用现状、核心方法论、以及从理论到实践的演进路径。这不仅是对一个特定工程领域的AI应用总结,更揭示了一个通用人工智能技术在面对真实世界的高风险、高复杂度工业应用时,所必须经历的适应、特化与融合的成熟过程。本文的PDF版本及参考资料已收录于“走向未来”知识星球,供读者深入研习。
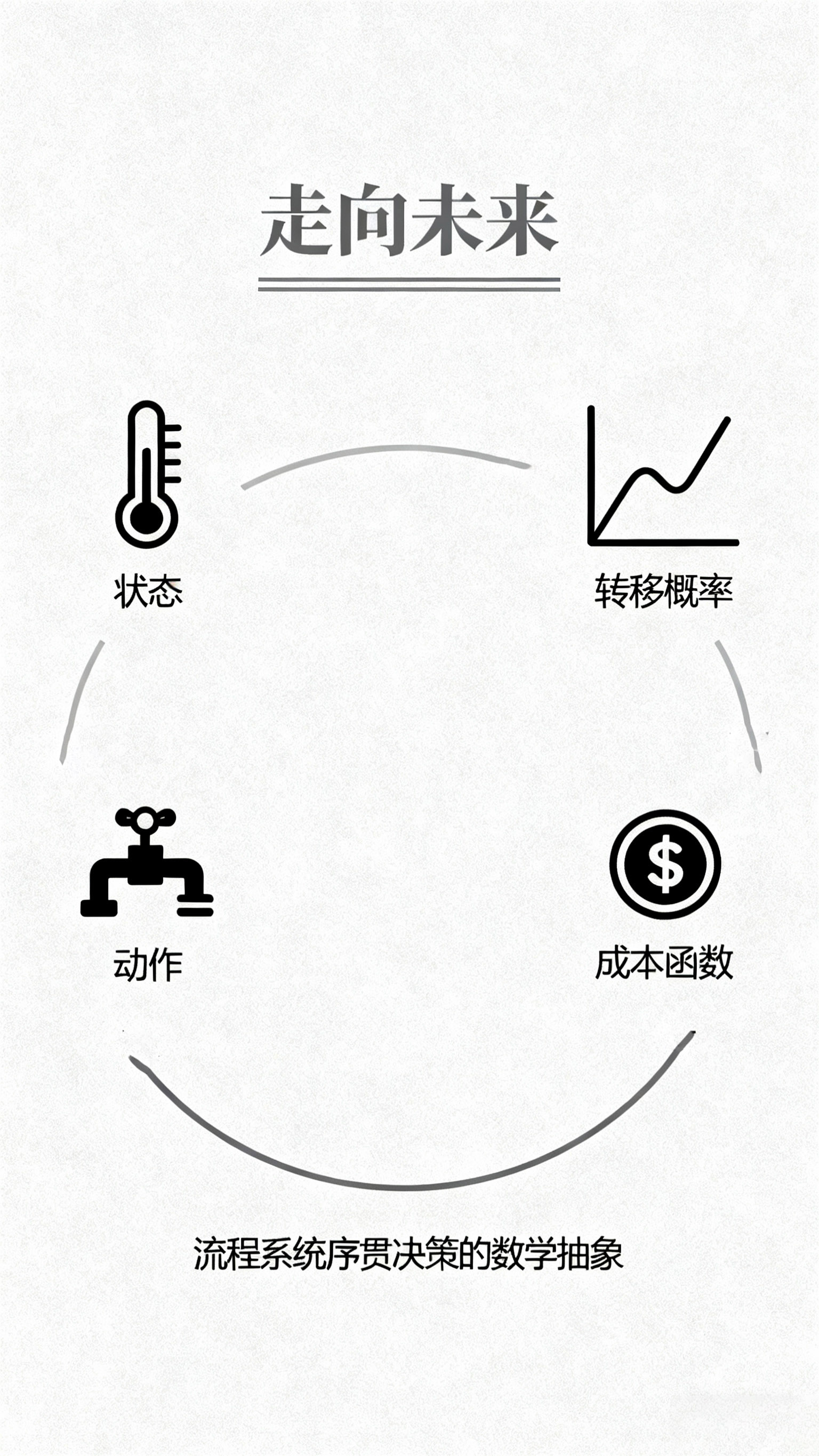
问题的数学抽象:马尔可夫决策过程
要理解强化学习如何应用于流程系统工程,首先必须建立一个共通的语言来描述问题。流程系统工程中的序贯决策问题,可以通过马尔可夫决策过程(Markov Decision Process, MDP)的框架进行数学形式化。
d/004.jpg
一个马尔可夫决策过程由状态、动作、转移概率、成本函数和折扣因子等关键元素定义。在流程工业的背景下,状态(State)对应于系统的可测量变量,如温度、压力、浓度或库存水平。动作(Action)则是控制系统可操作的变量,例如阀门开度、进料速率或订货量。
核心在于转移概率,它描述了在特定状态下执行一个动作后,系统转移到下一个状态的概率分布。这恰当地捕捉了流程工业中固有的随机性,例如原料波动、设备扰动或市场需求的不可预测性。成本函数则定义了在每个时间步上,特定状态和动作所带来的即时运营成本,如能耗、原料消耗或偏离设定点的惩罚。
强化学习的目标,就是寻找一个最优策略。策略本身是一个函数,它根据当前观测到的状态,映射出一个最优的动作。这个最优策略旨在最小化从初始状态开始,直到未来一个有限或无限时间范围内的累例期望成本。
在流程系统工程中的更复杂情景中,例如,当系统的所有状态不能被完全观测时,问题就转变为部分可观测马尔可夫决策过程(POMDP)。在这种情况下,智能体必须依赖其观测历史来推断系统的真实状态,这在许多实际应用中更为常见,因为传感器可能既昂贵又不完备。
动态规划的局限与强化学习的动机
在拥有完整的MDP模型(即所有状态、动作、转移概率和成本均已知)的前提下,动态规划(Dynamic Programming, DP)提供了求解最优策略的经典方法,如价值迭代和策略迭代。这些方法通过贝尔曼最优方程,以迭代方式计算出每个状态或状态-动作对的精确价值。

b/005.jpg
然而,动态规划在流程系统工程中的实际应用面临两大根本障碍。首先,它要求对系统动态有完美的、精确的知识,即转移概率必须已知。这对于复杂的化学反应或生物过程而言,几乎是不可能的。其次,动态规划遭受着“维度灾难”的困扰。随着状态或动作空间维度的增加,精确求解所需的计算资源呈指数级增长,这使得它无法处理具有成百上千个变量的真实工业过程。
正是这些局限性,催生了强化学习的需求。强化学习可以被视为一种近似动态规划,它保留了动态规划的核心思想(即通过价值函数和策略迭代来寻找最优解),但放弃了两个关键的假设:它不再需要一个已知的环境模型,并且它使用函数近似(如神经网络)来替代存储巨大的价值表,从而克服维度灾难。强化学习通过与真实系统或其模拟器进行交互,从采样数据中直接学习价值函数或策略,使其成为解决模型未知和高维复杂性问题的可行路径。
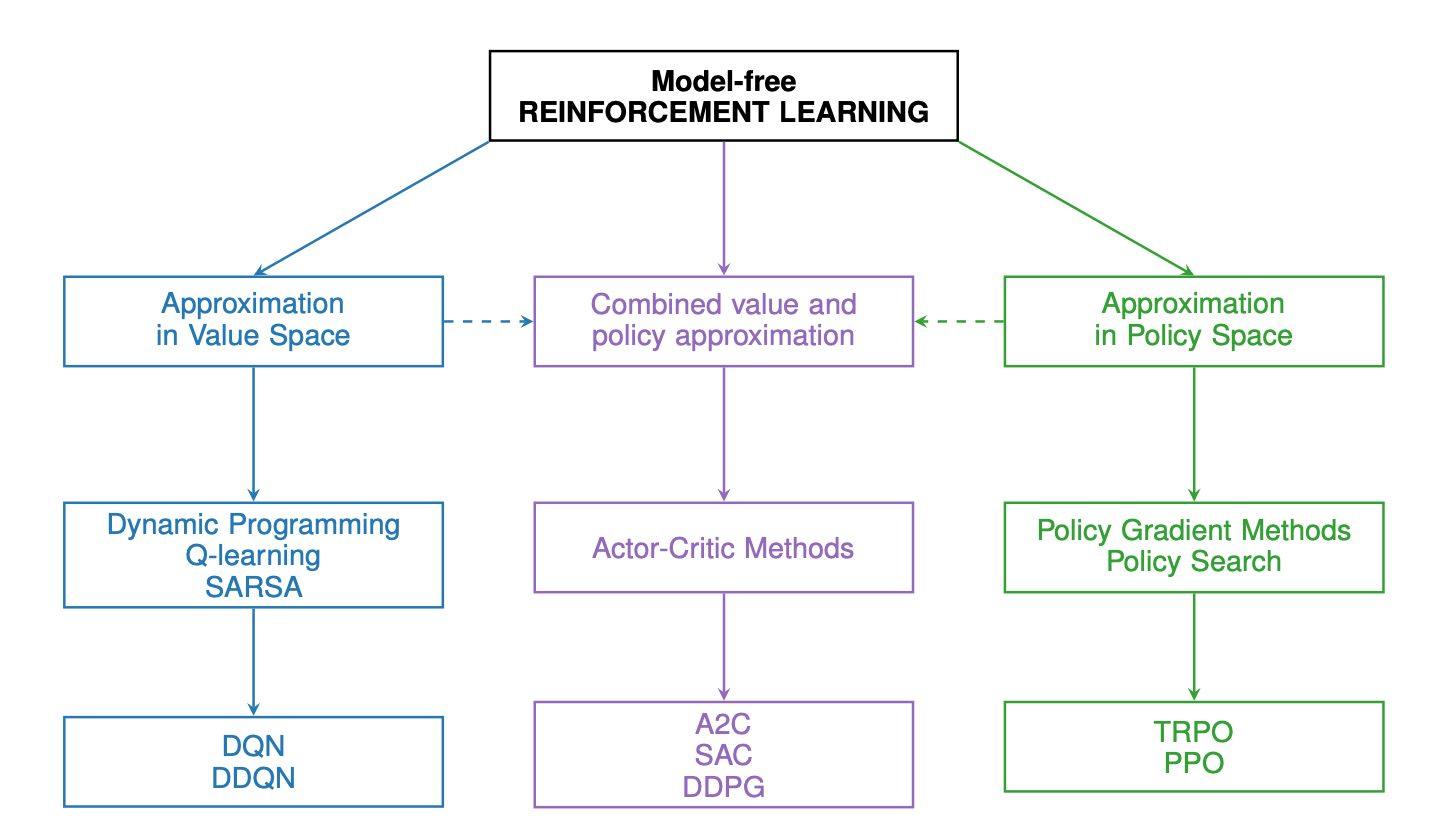
核心方法论:从无模型强化学习开始
强化学习算法包括几个主要家族,其中无模型(Model-Free)方法是研究最广泛、应用最基础的类别。无模型方法不试图学习环境的转移概率,而是直接从经验中学习最优策略或价值函数。
价值函数近似方法
这类方法的核心是学习一个状态-动作价值函数,即Q函数。Q函数预测了在特定状态下执行特定动作后,未来所能获得的累积回报。一旦获得了最优的Q函数,最优策略便不言自明:在任何状态下,只需选择那个能带来最低(或最高)Q值的动作。
蒙特卡洛(Monte Carlo, MC)方法是其中最直接的一种。它通过运行完整的“回合”(episode)来收集经验,例如一次完整的间歇反应过程。当一个回合结束后,它计算该回合中每一步的实际累积成本,并用这个实际观测值来更新对应状态-动作对的Q值估计。这种方法特别适用于具有明确开始和结束的有限时间范围问题,如间歇式生产,因为它能准确评估早期决策对最终产品质量的长期影响。
然而,许多流程控制问题是连续进行的,没有明确的回合结束点。时序差分(Temporal Difference, TD)学习解决了这个问题。TD方法不需要等待一个回合结束,而是在每一步之后立即更新价值估计。它利用当前的即时成本和下一个状态的估计价值,来“引导”当前状态的价值。
SARSA是一种“在策略”(on-policy)的TD算法,它使用当前策略所选择的下一个动作来更新Q值。而Q学习(Q-Learning)则是一种“离策略”(off-policy)算法,它在更新Q值时,总是假设在下一个状态会采取最优动作(即最小化Q值的动作),而不管实际执行了什么动作。这种离策略特性使得Q学习能够利用历史数据或探索性策略产生的数据,来学习最优策略,这使其应用更为广泛。
当状态空间变为连续(例如温度和浓度可以是任意实数值)时,使用表格来存储Q值变得不可行。深度Q网络(Deep Q-Network, DQN)通过使用深度神经网络来近似Q函数,解决了这一问题。DQN将当前状态作为神经网络的输入,输出对应每个(离散)动作的Q值。DQN的引入,通过经验回放和目标网络等技术,成功地将深度学习与Q学习结合,使其能够处理高维、连续的状态空间。
策略优化方法
与价值学习不同,策略优化方法不学习价值函数,而是直接参数化策略本身。策略被表示为一个函数(例如一个神经网络),输入是状态,输出是应该执行的动作(或动作的概率分布)。学习的目标是调整这个策略网络的参数,以最小化累积成本。
策略梯度(Policy Gradient)方法是这一家族的基石。它通过沿着预期累积成本关于策略参数的梯度方向更新参数。REINFORCE算法是一种经典的策略梯度方法,它使用蒙特卡洛采样来估计这个梯度。策略梯度的主要优势在于它能自然地处理连续的动作空间,这在流程控制中至关重要(例如调节一个阀门的精确开度)。然而,它的一个主要缺点是梯度估计的方差非常高,导致学习过程不稳定且收敛缓慢。
策略搜索(Policy Search)则采用了一种黑盒优化的视角。它不依赖于梯度的计算,而是使用诸如进化策略之类的无导数优化算法,直接在策略参数空间中搜索最优解。这种方法对于处理非微分或复杂的目标函数具有鲁棒性。
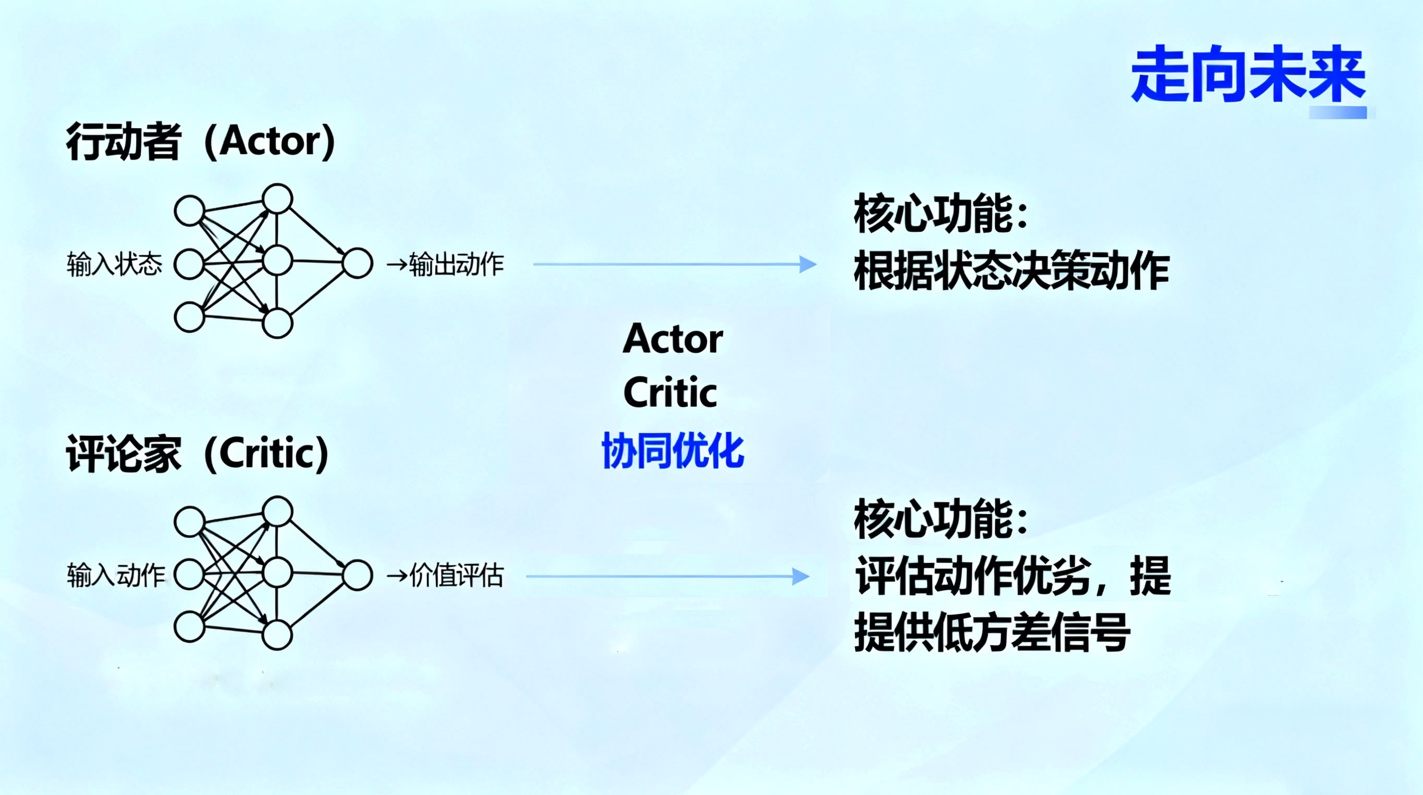
行动者-评论家方法
行动者-评论家(Actor-Critic)方法结合了价值学习和策略优化的优点,是当前流程系统工程应用中最主流和最成功的方法。它维护两个独立的网络:
b/003.jpg
- 行动者(Actor):即策略网络,负责根据当前状态决定要执行的动作。
- 评论家(Critic):即价值网络(通常是Q函数或状态价值函数),负责评估行动者所选择的动作有多好。
评论家的角色是学习一个准确的价值函数,并为行动者提供低方差的学习信号。行动者则根据评论家的“批评”来更新其策略。例如,如果评论家指出某个动作导致的后续成本低于预期,行动者就会调整参数以增加未来在该状态下选择该动作的概率。
诸如深度确定性策略梯度(DDPG)、信赖域策略优化(TRPO)、近端策略优化(PPO)和软行动者-评论家(SAC)等先进的Actor-Critic算法,已成为解决连续控制问题的默认选择。它们通过各种技术(如目标网络、经验回放、熵最大化)来稳定学习过程,使其能够应对复杂的动态系统。
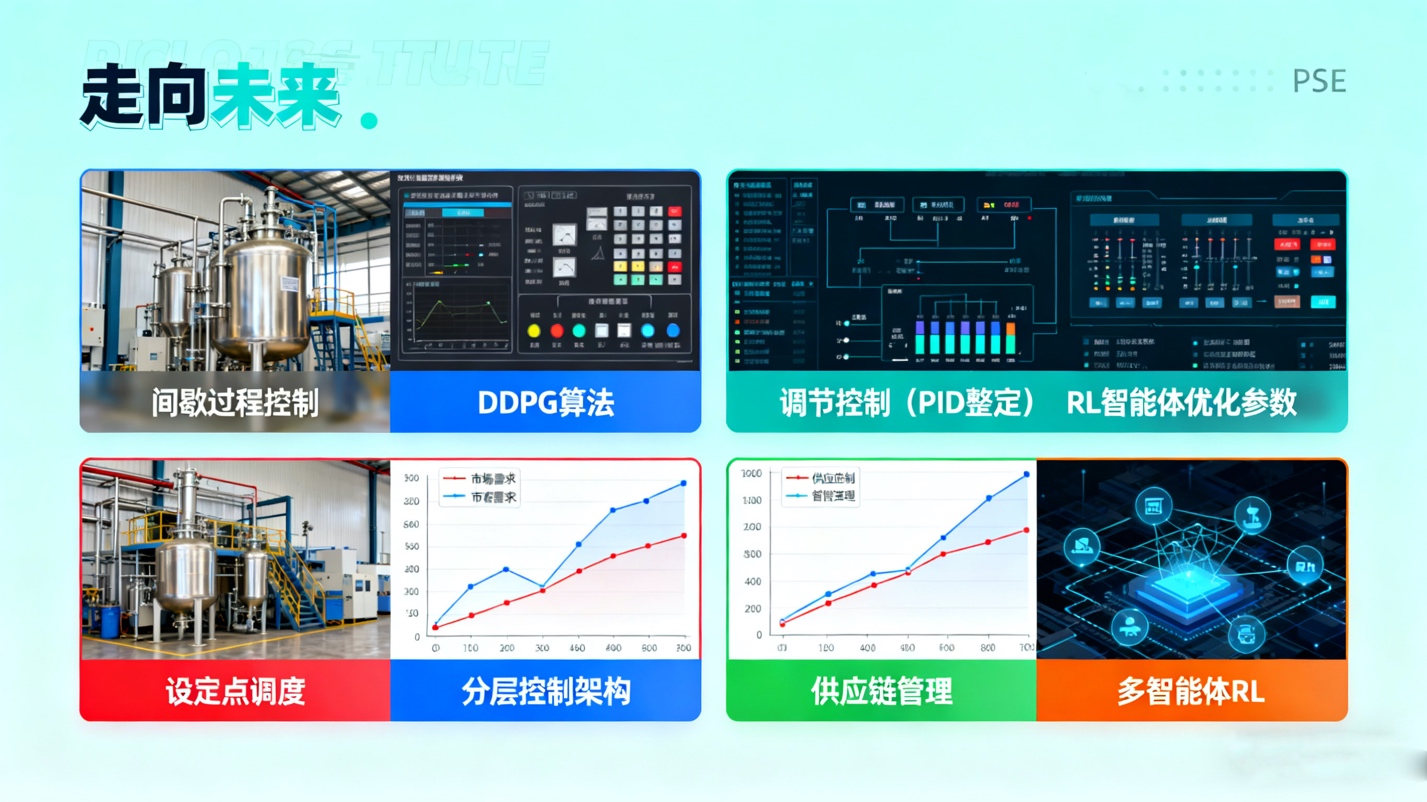
实际应用领域:强化学习的实践版图
强化学习在流程系统工程四大关键领域的具体应用,这些应用清晰地展示了不同RL算法如何匹配特定的工程挑战。
b/002.jpg
在间歇过程控制领域,如制药或特种化学品生产中,目标是优化最终的产品质量或收率。由于过程具有有限的时间范围和高度非线性的动态特性,DDPG等Actor-Critic方法被用于控制非线性的聚合反应器。同时,由于数据采集成本高昂(例如一次间歇反应可能需要数小时或数天),研究人员利用逆强化学习(IRL)从现有的专家控制策略(如NMPC)中推断奖励函数,或使用高斯过程Q学习来提升数据效率。
在调节控制层面,强化学习被用于自动整定PID控制器的参数。这通常是工业自动化的基础层。RL智能体可以通过与模拟过程的交互,快速找到适应不同工况的鲁棒PID参数,甚至可以设计控制理论知情的策略网络结构,将PID结构嵌入到RL策略中,以提高性能和数据效率。
在设定点调度层面,强化学习用于解决经济优化问题。此时,RL智能体不再是调节温度或压力,而是根据变化的市场条件(如电价、需求预测)来设定下层控制系统(如MPC)的经济目标(即设定点)。这种分层控制架构,允许高层的RL智能体专注于经济目标的长期优化,而低层的MPC则负责保证过程的稳定和约束的满足。
在供应链管理中,强化学习被用于制定库存和订购策略。这是一个典型的、充满不确定性(需求、交货时间)的序贯决策问题。研究显示,多智能体强化学习(MARL)提供了一个自然的框架来模拟供应链中的去中心化决策(例如,每个仓库或零售商作为一个独立的智能体),通过学习协调策略来优化整个链条的性能。
现实部署的鸿沟:向领域感知的智能演进
尽管无模型强化学习在模拟中取得了显著成功,但文献敏锐地指出,在将其部署到真实的、高风险的工业环境中时,仍然存在一个巨大的鸿沟。标准的RL算法通常数据效率低下、缺乏安全保证、难以利用历史数据,并且通常只为单一目标进行优化。

b/001.jpg
流程系统工程领域的最新研究,正致力于通过发展一系列“领域感知”的专业化RL子领域来弥补这一鸿沟。这些先进方法不再是通用的黑盒,而是深度融合了工程约束和领域知识的特定工具。
从数据饥渴到样本高效:模型基强化学习
无模型方法需要海量的真实环境交互来学习,这在昂贵且缓慢的化工过程中是不可接受的。模型基强化学习(Model-Based RL)通过学习一个环境动态的近似模型来解决这个问题。智能体可以使用这个学习到的模型在“内部”进行模拟和规划,产生大量的“虚拟”经验来更新策略,从而极大减少对真实环境的采样需求。
这种方法在概念上与模型预测控制(MPC)非常接近,后者也使用模型进行前瞻性规划。事实上,一个趋势是利用高斯过程等概率模型来构建动态模型,这不仅能预测未来状态,还能量化模型的不确定性,从而实现更鲁棒的策略优化。
从统计期望到硬性保证:约束强化学习
标准RL优化的是累积成本的“期望值”,这在安全攸关的系统中是远远不够的。一个导致反应器超温的低概率事件,即使在期望值上微不足道,在现实中也可能是灾难性的。约束强化学习(Constrained RL, CMDP)通过引入额外的辅助成本函数和约束阈值,来解决这个问题。
其目标是在最小化主成本函数的同时,确保其他成本(如安全违规成本)的期望累积值保持在预设的阈值以下。这通常通过拉格朗日松弛等约束优化技术来实现。更进一步的研究,正试图从这种“统计安全性”(满足期望约束)转向“硬性安全性”(在任何时间步都不违反约束),例如通过结合控制屏障函数或显式优化求解器,来保证智能体的每一个动作都停留在安全的可行域内。
从零开始到利用历史:离线强化学习
流程工业通常积累了海量的历史操作数据。然而,标准的RL算法(尤其是on-policy算法)无法有效利用这些静态的、固定的数据集。它们被设计为通过“主动探索”来学习。离线强化学习(Offline RL),也称为批量强化学习,专门解决如何仅从一个固定的数据集中学习最优策略的问题,而无需与环境进行任何新的交互。
离线RL的核心挑战在于“分布偏移”:学习到的策略可能会倾向于选择数据集中未曾出现过的动作,而模型对这些“分布外”动作的价值估计通常是错误的、过分乐观的。保守Q学习(CQL)等算法通过在标准Q学习的目标函数中加入一个正则化项,惩罚那些对未知动作的高价值估计,强制智能体学习一个“保守”的策略,即更倾向于选择数据集中已验证过的、安全的动作。离线RL为利用工业历史数据资产提供了一条极具价值的途径。
从单一目标到灵活适应:目标条件强化学习
在实际运营中,一个工厂可能需要根据订单生产不同规格的产品,或者一个控制器需要能够追踪任意给定的设定点。为每一个可能的目标单独训练一个RL策略是不现实的。目标条件强化学习(Goal-Conditioned RL, GCRL)通过将“目标”作为策略网络的额外输入,来学习一个通用的、多目标的策略。
一个GCRL智能体被训练为能达到任意给定的目标状态。例如,在流程控制中,策略网络同时接收当前状态和期望的设定点,输出一个能驱动系统达到该设定点的控制动作。这种方法通常与“事后经验回放”(HER)技术结合使用。HER允许智能体将在追求一个目标时失败的轨迹,重新标记为成功达到了另一个(即实际达到的)目标,从而极大地缓解了在稀疏奖励环境下的学习效率问题。GCRL使得智能体具备了前所未有的灵活性和适应性。
从平均表现到风险规避:分布式强化学习
最后,供应链管理或经济调度不仅关心平均利润,更关心极端风险,例如发生重大库存短缺或巨大损失的概率。标准RL关注的是回报的“期望”,完全忽略了回报的分布。分布式强化学习(Distributional RL)通过学习回报的完整概率分布来解决这个问题。

d/003.jpg
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号