仅960M参数,不仅干翻百亿大模型,速度还快了6倍!字节最新图像编辑模型EditMGT开源啦

仅960M参数,不仅干翻百亿大模型,速度还快了6倍!字节最新图像编辑模型EditMGT开源啦

AI生成未来
发布于 2025-12-31 19:02:45
发布于 2025-12-31 19:02:45
作者:Wei Chow,Linfeng Li等
解读:AI生成未来

文章链接:https://arxiv.org/pdf/2512.11715 Project Page: https://weichow23.github.io/EditMGT GitHub Repo: https://github.com/weichow23/EditMGT HuggingFace Dataset: https://huggingface.co/datasets/WeiChow/CrispEdit-2M
亮点直击
- 提出了EditMGT,这是首个基于MGT的图像编辑模型,它通过利用MGT的令牌翻转特性来显式地保留与编辑无关的区域,从而从根本上解决了扩散模型中存在的虚假编辑泄露问题。
- 提出了结合区域保持采样的多层注意力整合方法,以实现对编辑相关区域的自适应定位,从而解决了在无需手动预定义掩码的情况下确定编辑应用位置的挑战。
- 构建了CrispEdit-2M,这是一个包含7个不同类别、经过严格筛选的200万样本的高分辨率(≥1024)图像编辑数据集。
- 在四个流行基准测试上进行的大量实验验证了我们方法的有效性,紧凑的960M参数模型实现了比同类方法快6倍的编辑速度。
总结速览
解决的问题
- 扩散模型(DMs)在图像编辑中存在全局去噪动态性问题,导致对非目标区域的意外修改(编辑泄露)。
- 现有解决方案(如依赖高质量数据、预定义掩码或反转技术)存在灵活性不足、无法显式保证非相关区域不变或推理速度慢等局限。
提出的方案
- 提出了首个基于掩码生成Transformer(MGTs)的图像编辑框架——EditMGT。
- 构建了一个大规模高分辨率(≥1024)图像编辑数据集CrispEdit-2M,涵盖7个不同类别,用于训练模型。
应用的技术
- 自适应定位:利用MGT的交叉注意力机制提供定位信号,并设计了一种多层注意力整合方案,以细化注意力图,实现细粒度、精确的编辑相关区域定位。
- 显式区域保留:提出了区域保持采样技术,限制在低注意力区域进行令牌翻转,以抑制伪编辑,从而将修改限制在目标区域内,并保持周围非目标区域的完整性。
- 高效适配:通过注意力注入的方式,将预训练的文本到图像MGT模型适配为图像编辑模型,无需引入额外参数。
达到的效果
- 性能领先:在四个标准基准测试上,模型(参数量<1B)取得了图像相似度指标的最先进性能。在风格变更和风格迁移任务上分别提升了3.6%和17.6%。整体性能优于多个更大规模(6B-8B)的基线模型。
- 效率显著:实现了6倍的编辑速度提升(编辑1024×1024图像仅需2秒),同时内存占用仅为13.8 GB。
- 精确编辑:能够自适应定位编辑区域,并显式地保留非目标区域,有效解决了编辑泄露问题。
EditMGT:迈向基于MGT的图像编辑
首先介绍基于 MGT 的编辑架构实现,该架构利用注意力注入(attention injection)在不引入额外参数的情况下实现图像编辑。随后阐述了推理过程。重点分析了 MGT 模型中的注意力机制,提出了多层注意力整合(multi-layer attention consolidation)结合区域保持采样(region-hold sampling)的方法,以利用该机制确保在推理过程中保留无关区域。最后描述了 EditMGT 及其提出的 CrispEdit-2M 数据集的训练过程。
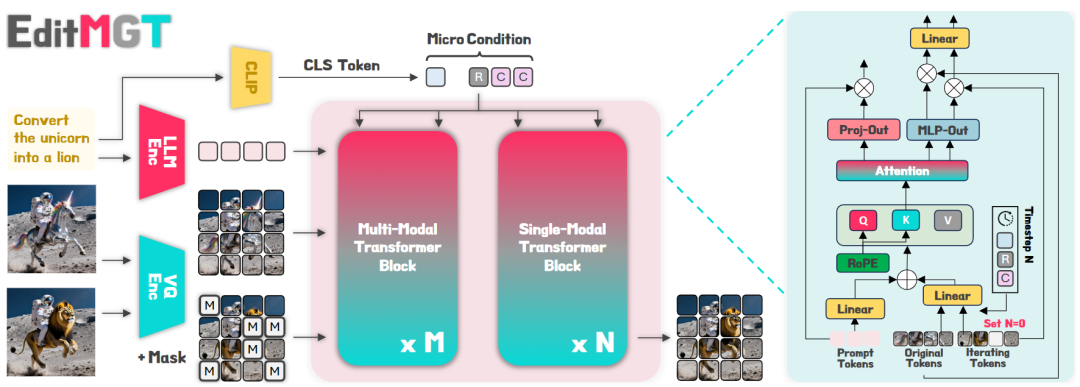
图 2 EditMGT 概述。我们的方法通过原始图像注意力注入来监督编辑图像的生成。 右图说明了多模态转换器块内的token交互,而单模态块则采用类似的架构。
图 2 EditMGT 概述。我们的方法通过原始图像注意力注入来监督编辑图像的生成。 右图说明了多模态转换器块内的token交互,而单模态块则采用类似的架构。
架构
预备知识。MGT 从一张所有视觉 token 都被掩盖(masked)的空白画布开始。在每次采样迭代中,所有缺失的 token 都会并行采样,并使用拒绝标准,模型似然度较低的 token 会被掩盖,并在下一次细化迭代中重新预测。本文定义图像和文本条件 token 分别为 和 ,其中 是嵌入维度, 和 分别是它们的 token 数量。
在 Meissonic 的实现中,每个 transformer 块首先应用旋转位置编码(RoPE)来编码 token。对于图像 token ,RoPE 根据 token 在 2D 网格中的位置 应用旋转矩阵:,其中 表示位置 处的旋转矩阵。文本 token 经过相同的变换,其位置设置为 。多模态注意力机制随后将连接后的位置编码 token 投影为查询(Query)、键(Key) 和值(Value) 表示。注意力权重计算如下:。然后, 和 的乘积在传播到下一个模块之前通过归一化层。 被赋予了丰富的语义信息,随后基于注意力权重纳入额外的图像条件,同时在推理过程中引入局部和全局引导。
**图像条件集成 (Image Conditional Integration)**。为了让原始图像监督图像生成过程,本文进一步定义了图像条件 token ,其形状与 相同。具体而言,本文设定 RoPE 矩阵满足:,这确保了原始图像与编辑后图像在空间上的对齐。如图 2 右侧所示, 与 共享参数并经历相同的迭代去噪步骤,但关键区别在于 的时间步长(timestep)在整个过程中始终固定为零。这一设计选择防止了 发生漂移,从而使其保持作为稳定调节信号的作用。
在训练阶段,模型 的优化目标是在大规模图像-文本数据集 上,最小化在给定未掩蔽(unmasked)token 和条件 token 的情况下重建被掩蔽 token 的负对数似然,其中 代表被掩蔽的 token:
其中 , 是应用于 token 的二进制掩码,用于选择索引 进行掩蔽, 指未被掩蔽的 token, 是 token 的预测概率。本文在训练中使用余弦调度策略,掩蔽率 采样自截断反余弦分布,其密度函数为 。
为了在推理过程中控制 的强度,遵循 [41] 的方法,本文在注意力权重中引入偏置项 ,即 ,其中 是调节拼接后的 token 之间注意力的偏置矩阵。该过程可表述如下:
该公式保留了每种 token 类型内部的原始注意力模式,同时将 和 之间的注意力权重缩放 。在测试时,设置 会移除条件的影响,而 则会增强它。通过这种方法,本文利用注意力机制无缝嵌入了调节条件,从而在不引入额外参数的情况下实现了从文生图(text-to-image)模型到图像编辑模型的转变。
推理
基于上述架构,本工作观察到 EditMGT 中的交叉注意力机制自然地为编辑相关区域的自适应定位提供了信息丰富的线索。如下图3所示,本工作研究了迭代图像 和指令 之间的交叉注意力机制(由于篇幅限制,省略了原始图像 与这两种模态之间的交叉注意力可视化)。
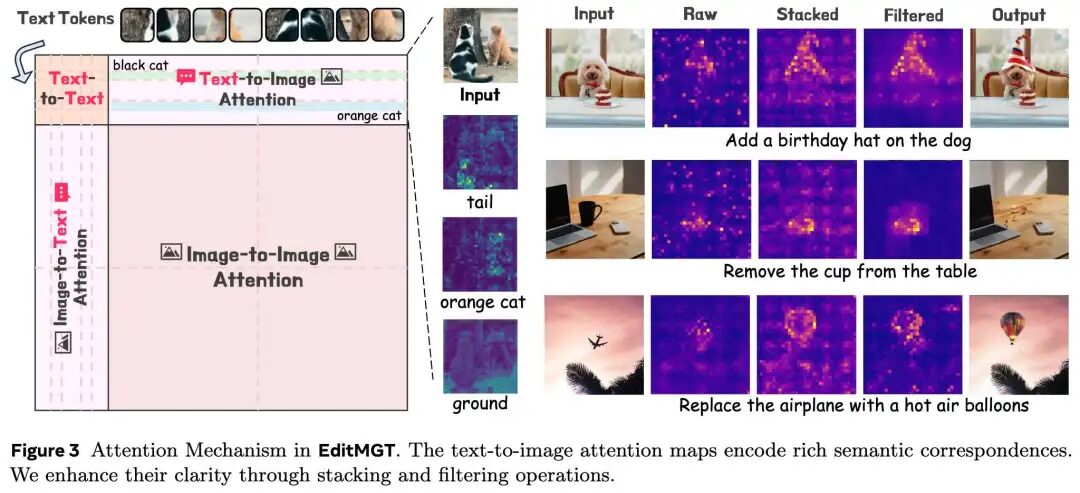
图3:EditMGT 中的注意力机制。文生图注意力图编码了丰富的语义对应关系。本工作通过堆叠和过滤操作增强了其清晰度
图3:EditMGT 中的注意力机制。文生图注意力图编码了丰富的语义对应关系。本工作通过堆叠和过滤操作增强了其清晰度
分析表明,MGT 模型中的每个文生图注意力权重都包含丰富的语义信息,建立了文本指令与视觉区域之间的有效对应关系。值得注意的是,模型可以在初始迭代中预测编辑图像中关键区域的样式。例如,在“给狗戴上生日帽”的例子中,MGT 直接描绘了帽子形状的轮廓。
多层注意力整合(Multi-layer Attention Consolidation)。来自单个中间块的原始注意力权重表现出不够突出且缺乏清晰焦点的问题,即使是从最连贯的层中提取也是如此。为了解决这一局限性,本工作提出了多层注意力整合,系统地增强注意力的清晰度。具体而言,聚合了从第 28 块到第 36 块的注意力权重,这些块选自连贯的单模态处理层,以放大信号强度。然而,观察发现聚合后的注意力权重仍然表现出不完整的激活区域,其特征是内部不连续和边界定义不清,这可能导致对象内部的 token 分类错误。为了减轻这些伪影,本工作结合了自适应过滤(Adaptive Filtering)以实现增强的清晰度和空间精度。
区域保持采样(Region-Hold Sampling)。在注意力机制的分析中,观察到 MGT 的注意力权重表现出丰富的语义信息,实现了良好对齐的文图对应关系。在图像生成过程中,MGT 通过迭代 token 翻转(token flipping)逐步细化目标图像。如下图4所示,EditMGT 准确地定位了编辑的关键区域。因此,本工作通过显式地将低注意力区域翻转回其原始 token 来保留未修改的区域。
定义 分别为第 层归一化后的 和 的注意力图。为了灵活控制翻转频率,引入阈值 来确定哪些 token 应恢复为原始图像。具体来说,可以按如下方式获取定位图:
其中 表示矩阵 的第 行切片, 是要选择的所有行索引的集合,且 (当且仅当选择整个 时等号成立)。如果仅使用指令中的关键词(例如特定对象),则可以使用 提取相应部分。在推理过程中,EditMGT 翻转具有高置信度的 token,同时保留低置信度 token 作为 [MASK] 以供后续细化。通过引入的采样方法,满足 的 token 被恢复为其原始对应物,从而保持采样调度器的完整性以及与源图像的一致性。
下图4 展示了编辑图像与 之间的关系——当 超过某个阈值时,输出变得与原始图像完全相同。
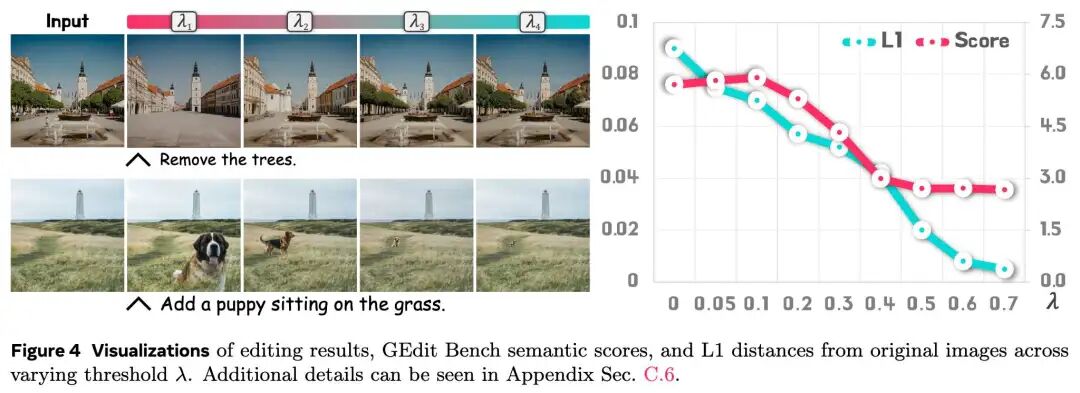
图4:不同阈值 下的编辑结果可视化、GEdit Bench 语义分数以及与原始图像的 L1 距离
图4:不同阈值 下的编辑结果可视化、GEdit Bench 语义分数以及与原始图像的 L1 距离
训练细节
鉴于高分辨率图像编辑数据集的稀缺,本工作构建了涵盖 7 个不同类别的 CrispEdit-2M 数据集。CrispEdit-2M 包含 200 万个短边 像素的样本,使用开源模型生成,并采用严格的过滤程序以确保数据质量。结合额外收集的 200 万个高分辨率样本,总共使用了 400 万个图像编辑数据样本进行训练。
EditMGT 基于 Meissonic 实现。由于 Meissonic 表现出生成卡通风格内容的偏好,且采用 CLIP 作为文本编码器,缺乏强大的语言理解能力(这是编辑模型的关键要求),因此将 EditMGT 的训练分为三个阶段:
- 阶段 1:基于 LLM 的基础模型。利用约 100 万个文本-图像对,直接采用 Gemma2-2B-IT 作为文本编码器,训练 5,000 步。
- 阶段 2:编辑模型全量微调。在完整的 400 万图像编辑数据集上进行 50,000 步的全量微调。
- 阶段 3:高质量微调。使用更高质量的编辑数据对模型进行 1,000 步的微调,以增强模型输出与人类偏好之间的对齐。
实验
为了验证 EditMGT 的有效性,本工作在三个像素级基准测试(Emu Edit, MagicBrush, AnyBench)和一个基于 GPT 的评估基准(GEdit-EN-full)上进行了全面评估。
主要结果
本工作在四个基准数据集上对 EditMGT 与基线方法进行了定量比较。
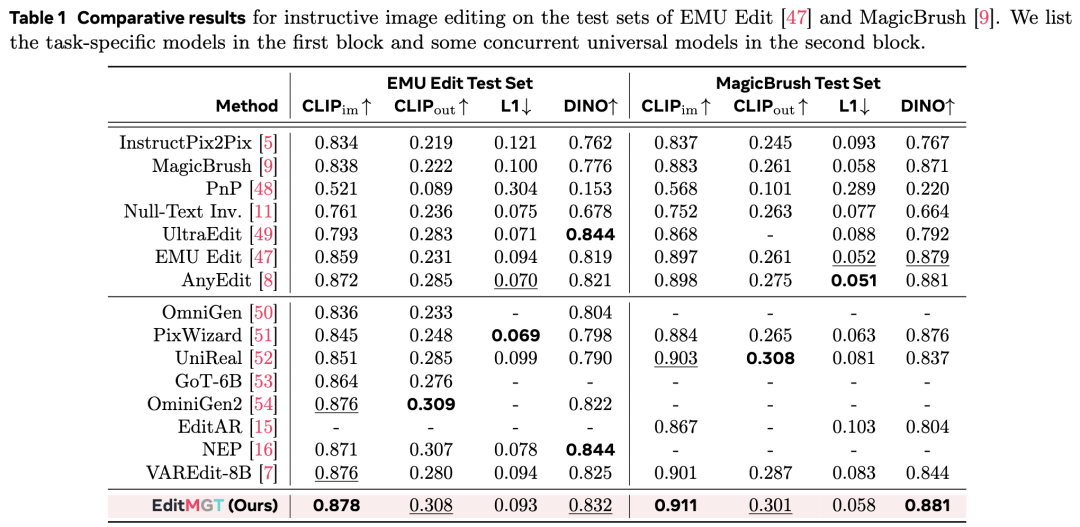
- Emu Edit & MagicBrush:如下表 1 所示,EditMGT 在图像相似度(CLIP)方面在所有评估模型中取得了 SOTA 性能,在 MagicBrush 上有 1.1% 的显著提升。在语义图像相似度(DINO)方面,该方法分别取得了第二佳和 SOTA 的结果。指令依从性指标显示了一致的强劲表现。尽管 L1 分数未显示显着优势,但这可能归因于 EditMGT 与预定目标图像之间固有的多样性差异。
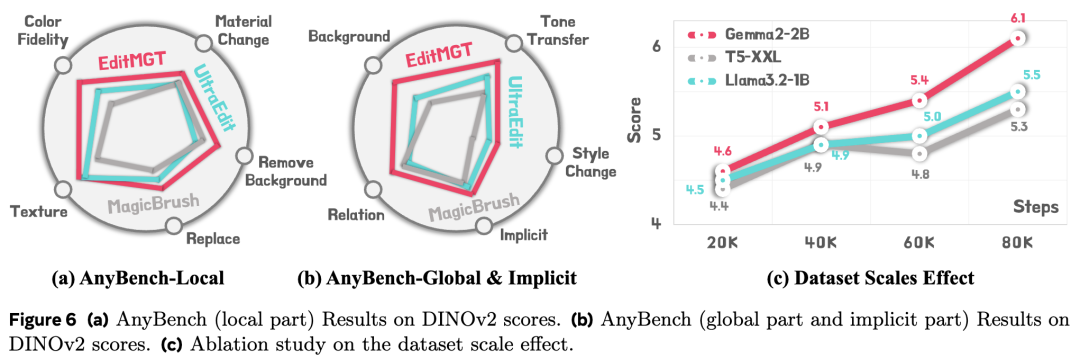
- AnyBench:如下图 6(a)(b) 所示,按任务类型分类时,EditMGT 在 AnyBench 评估的所有任务中均取得了最佳或接近最佳的性能。特别是在风格更改(style change)任务中,EditMGT 比第二名的方法大幅提升了 3.6%。对于隐式指令(implicit instruction)任务,EditMGT 始终取得 SOTA 结果,超过第二名 1.7%,表明该模型在处理隐式指令引导方面具有卓越能力。详细分数见表 6 和表 7。
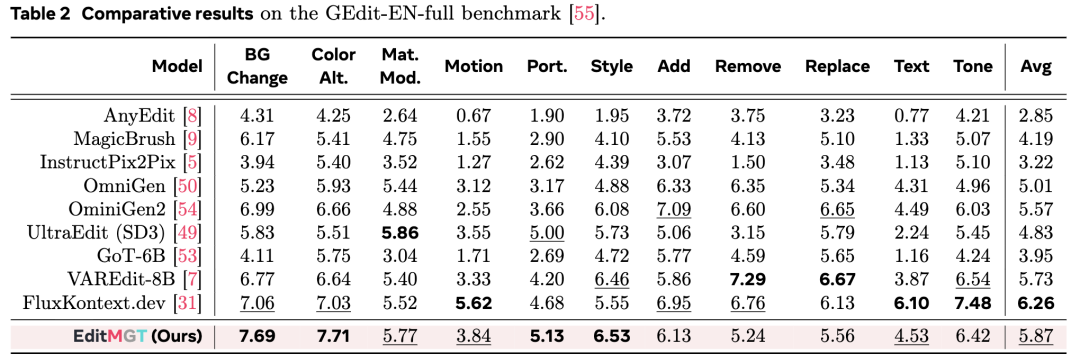
- GEdit-EN-full:如下表 2 所示,尽管模型大小仅为 960MB,但它实现了与 12B 参数量的 FluxKontext.dev 模型相当的竞争力,并表现出优于 VAREdit-8B、GoT-6B 和 OmniGen2 (7B) 的整体性能。值得注意的是,该模型在背景更改、颜色更改、人像编辑和风格迁移(style transfer)等几个具有挑战性的任务上优于 FluxKontext.dev,其中风格迁移提升了 17.6%。
定性结果
除定量指标外,如下图 5 所示,本工作将 EditMGT 与 UltraEdit (SD3)、GoT-6B、OmniGen2-7B 和 VAREdit-8B 进行了定性比较。观察结果如下:
- 卓越的指令理解能力:例如,对于“照片看起来有点发黄,请调整颜色”,其他模型错误地增加了黄色调,只有 EditMGT 正确地减少了暖色调以实现美白。
- 强大的对象属性理解:在“点亮所有蜡烛”的例子中,只有 EditMGT 成功点亮了所有蜡烛;对于“添加黑色长筒袜”,它准确理解了形容词“长”。
- 有效的结构保留:在生成皮克斯风格动画时,EditMGT 不仅成功渲染了角色,还保持了拍摄对象的原始姿势和位置。

深入分析
- 数据扩展(Data Scaling):如前图 6 所示,不同训练步骤的实验表明,即使更换文本编码器,模型架构也能保持一致的可扩展性。
- 架构消融(Architecture Ablation):主要研究了文本编码器的选择(见附录表 5)。经验分析表明,Gemma2-IT-2B 在评估的选项中取得了最佳性能。
- 推理算法有效性:如图 4 所示,增加 值会逐渐减少图像内的编辑区域。随着 增加,L1 距离减小,而语义分数先略微提高后急剧下降,证明了阈值控制的有效性。
- 速度优势:如下图 1(b) 所示,在 1024×1024 分辨率下,EditMGT 实现了比性能相似的模型快 6 倍的编辑速度(每次编辑仅需 2 秒)。

EditMGT 和 CrispEdit-2M 概述
EditMGT 和 CrispEdit-2M 概述
结论
EditMGT,首个基于掩码生成 Transformer(MGT)的图像编辑框架,利用 MGT 的局部解码范式来解决扩散模型中固有的编辑泄漏(editing leakage)问题。通过提出的多层注意力整合(multi-layer attention consolidation)和区域保持采样(region-hold sampling),EditMGT 实现了精确的编辑定位,同时显式地保留了非目标区域。尽管仅使用了 9.6 亿(960M)参数,该模型在四个基准测试中均达到了最先进的图像相似度性能,在风格更改和风格迁移任务上分别有 3.6% 和 17.6% 的显著提升。此外,EditMGT 提供了 6 倍的编辑速度,证明了 MGT 为图像编辑提供了一种极具竞争力的替代方案。
参考文献
[1] EditMGT: Unleashing Potentials of Masked Generative Transformers in Image Editing
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号