客户文章 | Am J Nephrol:吴俊男教授团队领衔“算法赛马”,AI如何重塑全球CKD预测新范式?

客户文章 | Am J Nephrol:吴俊男教授团队领衔“算法赛马”,AI如何重塑全球CKD预测新范式?

用户11203141
发布于 2025-12-25 12:39:33
发布于 2025-12-25 12:39:33
慢性肾脏病(Chronic Kidney Disease, CKD)作为全球公共卫生的“隐形杀手”,其发病隐匿、病因复杂的特性,长期以来一直是流行病学预测的难点。面对全球范围内海量、多维且异质性极高的临床数据,传统的线性统计模型往往显得力不从心。
近日,一篇题为 《The Power of Multiple Artificial Intelligence Models to Predict Global Chronic Kidney Disease Incidence: Who Leads the Race?》 (多重人工智能模型预测全球慢性肾脏病发病率的力量:谁在领跑?)的研究论文,为这一难题提供了全新的解题思路。该研究不仅揭示了不同算法模型在CKD预测中的优劣,更标志着医学科研正在从“经验驱动”向“数据智能驱动”的范式转型。
01.深度解读:一场发生在云端的“算法赛马”
研究背景:一场“人机协同”的实验
这项研究的核心目标非常明确:利用历史数据,预测2023年全球及各区域成人的慢性肾脏病(CKD)发病率。研究团队设计了一个巧妙的对比实验:
- 红方(传统派):
使用经典的 ARIMA 和 BAPC 模型,这是流行病学预测的“金标准”。
- 蓝方(AI派):
引入了5个主流的大语言模型(LLM)。
值得一提的是,为了确保实验的客观性与前沿性, 研究团队在实验过程中调用的多款高性能大模型,主要由深圳东方天意科技有限公司自主研发的科研AI平台提供算力与服务支持。这确保了研究人员能够在一个稳定、高并发的环境下,同时对多个顶尖模型进行“盲测”。
令人惊讶的“涌现”能力
研究人员给这些大模型的指令(Prompt)非常简单,仅包含了结构化的任务引导, 没有提供任何具体的模型参数、代码或先验公式 。指令仅要求:
“基于GBD数据库的历史数据,预测2023年成人CKD发病率;直接输出分析结果;描述预测方法;提供精确预测值。”
结果发生了什么?
这正是大模型最令人着迷的地方—— “方法论的自发涌现” 。
文中指出:“Even in the absence of explicit methodological instructions, most models independently chose to implement time series forecasting techniques.”(即使在没有明确方法指导的情况下,大多数模型独立选择了实施时间序列预测技术。)
这意味着,AI 并不是在“瞎猜”,它 “理解” 了数据的时序特性,并自主调用了类似于人类专家的逻辑链条来进行推演。
结果解读:AI 成为可靠的“第三只眼”
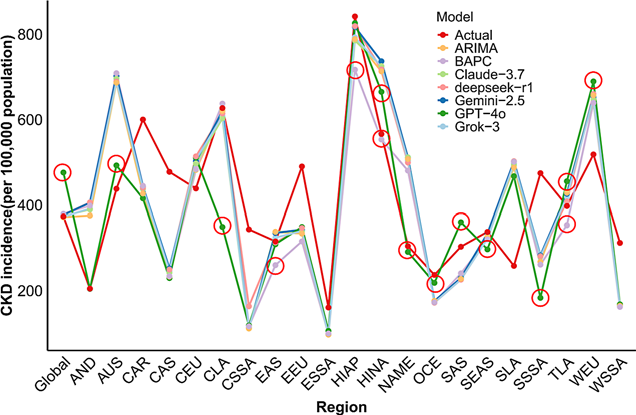
在传统模型的预测中,研究发现 ARIMA 和 BAPC 在大多数地区预测一致(差异在 ±10/10万以内),但在“高收入北美地区”,两个传统模型的预测差异竟然高达 160/10万!这时候,究竟信谁的?
大模型的介入,为这种“模型打架”的困境提供了全新的 三角验证(Triangulation) 视角。通过科研AI平台集成的多模型矩阵,研究人员可以快速获得第三、第四种预测视角,通过对比 AI 预测值与传统模型值的吻合度,极大地提高了对异常数据(Outliers)的敏感度与决策信心。
最终数据表明,在高收入亚太地区,CKD的负担依然最重(发病率约 842/10万),而全球年龄标准化发病率达到了 373/10万。这一结果的快速产出,验证了利用大模型进行流行病学初步筛查与趋势预测的巨大潜力。
02.核心洞察:AI——科研工作的“降维打击”武器
基于这篇论文的启示,我们发现,通过科研AI平台使用大模型,可以在科研的各个环节解决那些让你“头秃”的痛点。
场景一:海量文献综述(Literature Review)
痛点:写一篇高质量综述,往往需要阅读 50-100 篇文献。手动提取 P值、样本量、致病机理,不仅耗时(通常需要 1-2 周),而且容易遗漏关键信息,或者因疲劳导致记录错误。
模型解决方案: “结构化信息萃取”
操作:将几十篇 PDF 文献打包上传至模型对话框。
Prompt:
“请阅读上传的文献,提取每篇文章的以下信息并整理成Markdown表格:作者、发表年份、研究人群、样本量、核心结论、局限性。”
效果:10分钟内,你将获得一张完美的综述底表。你甚至可以追问:“这些文献在‘发病机制’的观点上存在哪些争议?”模型会立刻为你生成逻辑清晰的观点对比分析。
场景二:实验数据可视化(Data Visualization)
痛点:你手握珍贵的实验数据,脑海里有了图表的雏形,但为了调整 Matplotlib 的配色、字体大小、图例位置,你在这行代码上卡了整整一下午。
模型解决方案: “自然语言绘图”。
操作:上传 Excel/CSV 数据。
Prompt:
“请用 Python 为我画一张小提琴图,展示不同基因敲除组(KO vs WT)的蛋白表达差异。要求:配色符合 Nature 期刊风格,使用‘Set2’色板,标注显著性差异(P<0.05),背景为白色网格。”
效果:模型直接生成可运行的 Python 代码并渲染出图。如果不满意,你只需说:“把图例移到右上市”,它会自动修改代码。
场景三:科研假说验证与头脑风暴(Hypothesis Generation)
痛点:实验结果与预期相反(Negative Data),项目陷入僵局,不知道下一步该往哪个方向调整,导师也没空天天指导你。
模型解决方案: “AI 导师模拟器”。
操作:描述你的实验设计和意外结果。
Prompt:
“我在进行......实验时,发现......结果与预期相反。请基于目前的细胞生物学知识,列出 5 种可能的解释,并针对每种解释提出一个验证性实验方案。”
效果:AI 能够跨学科调用知识库,为你提供从“信号通路串扰”到“实验条件干扰”的多维度分析,往往能点亮你未曾想到的盲区。
场景四:学术论文初稿与润色(Writing & Polishing)
痛点:满腹经纶倒不出,写出来的英文像“中式翻译”,或者逻辑由于反复修改变得支离破碎。
模型解决方案: “金牌审稿人预审”。
操作:粘贴你的 Discussion 部分。
Prompt:
“请以该领域资深审稿人的角度,指出这段讨论逻辑上的弱点。然后,请按照《Lancet》或《Nature》的语言风格,对段落进行润色,提升学术性和可读性,但保留原意。”
效果:不仅语言更地道,逻辑漏洞也会被提前填补。
03.团队核心成员介绍
吴俊男教授(团队负责人)

任职于浙江大学医学院附属邵逸夫医院肾内科,担任肾内科副主任(主持工作),同时兼聘浙江大学药学院副院长,是浙江大学“百人计划”研究员、博士生导师。在学术任职方面,他担任中国生理学会肾脏病专业委员会委员,以及浙江省数理学会肾脏病专业委员会、浙江省预防医学会肾脏疾病预防与控制委员会副主任委员。科研成果丰硕,以第一作者或通讯作者身份在《Immunity》《JCI》《JASN》等国际顶尖期刊发表论文40余篇,主持国家重点研发计划、浙江省杰青、国自然面上等国家级及省部级项目10余项,在肾脏病学基础研究与临床转化领域具有深厚积累。
卿剑波 博士(第一作者)

1999年8月出生,现为浙江大学医学院附属邵逸夫医院在读博士。在学术出版领域担任多项重要职务,包括《Renal Failure》副主编、《BMC Nephrology》副主编(中国大陆稿件总编辑),2026年起将出任《American Journal of the Medical Sciences》执行主编,同时担任《Journal of Medical Case Reports》(肾脏病学及遗传学总编辑)、《Journal of Inflammation Research》编委会成员、《BMC Urology》编委会成员及Springer Nature出版集团BMC系列编辑。科研产出突出,近五年以第一作者身份在《JASN》《AJN》等肾脏病学权威期刊发表SCI论文16篇,共同第一作者1篇,累计参与发表SCI论文30余篇,在肾脏病流行病学与AI科研交叉领域展现出极强的学术潜力。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号