AI作画的秘密藏在数学公式里: 基于常微分方程和随机微分方程的流匹配与扩散生成模型
原创
AI作画的秘密藏在数学公式里: 基于常微分方程和随机微分方程的流匹配与扩散生成模型
原创
走向未来
发布于 2025-12-17 09:49:21
发布于 2025-12-17 09:49:21
AIGC底层的动力学原理:常微分方程ODE 的流匹配与随机微分方程SDE的扩散模型导论
走向未来
人工智能领域正在经历一场深刻的变革。系统不再仅仅用于预测,而是展现出创造能力。图像、视频乃至科学结构的设计,都源于人工智能系统生成新对象的能力。这场革命的核心是一种新的算法范式,特别是去噪扩散模型和流匹配技术。这些技术构成了当今最先进的图像、音频和视频生成模型的支柱,甚至推动了科学发现,例如在蛋白质结构预测中的应用。
理解这些模型的能力,本质上是理解一种从无序到有序的转变过程。这些模型通过模拟一个将随机噪声迭代转化为结构化数据的过程来生成对象。这个演化过程由常微分方程(ODEs)或随机微分方程(SDEs)驱动。流匹配和去噪扩散模型,正是用于构建、训练和模拟这些微分方程的强大技术家族。本文深入剖析这些模型背后的核心数学原理,揭示它们如何将生成问题重新定义为采样问题,并最终通过一个统一的框架,为构建可控、高保真的生成系统提供了简洁而强大的途径。本文的分析深度借鉴了相关领域的前沿研究《An Introduction to Flow Matching and Diffusion Models》等资料,这些资料已收录到“走向未来”知识星球中。

一:生成式建模的核心问题——作为采样的生成
要构建一个能够“生成”的系统,首先必须精确定义“生成”这一行为。无论是图像、视频还是分子结构,这些对象在数学上都可以被表示为高维向量。例如,一个图像是一个在高度、宽度和颜色通道维度上的数值张量。因此,生成任务被形式化为从一个特定的、通常是未知的概率分布中提取样本。这个分布被称为数据分布,即 。
一个好的“狗”的图像,在这个视角下,是数据分布 中具有高概率密度的一个样本。因此,生成式模型的任务,就是学习如何从这个复杂的数据分布中进行采样。训练这些模型依赖于一个包含从 中独立采样的有限示例的数据集。
实现这一目标的标准方法是,从一个我们已知如何采样的简单初始分布 (例如高斯噪声分布 )开始,学习一个变换,将来自 的样本映射到 的样本。整个生成式建模的挑战,就是找到这个从噪声到数据的精确变换。在许多实际应用中,我们还需要条件性生成,即根据特定输入(如文本提示 )来生成样本。这被建模为从条件数据分布 中采样。
二:连续变换的动力学——流模型与扩散模型
流匹配和扩散模型将从噪声到数据的变换,构建为一个在连续时间 上演化的动力学过程。这个过程由微分方程描述。

/Users/wgwang/futureland/1216/002.jpg
流模型(Flow Models)基于常微分方程(ODEs)。一个ODE由一个向量场 定义,该向量场在时空中的每一点 指定一个速度。一个从 开始的轨迹 ,其随时间的变化率由向量场在该点的取值决定,即 。这个ODE的解被称为“流”(flow),它定义了从时间0到时间 的确定性映射 。
在流模型中,一个神经网络 被用来参数化这个向量场。生成过程就是从 中采样一个初始点 ,然后通过数值模拟(如欧拉法)这个由神经网络定义的ODE,从 到 ,得到最终样本 。这个过程是确定性的:一个固定的初始噪声 将始终生成同一个数据样本 。我们的目标是训练参数 ,使得 的分布接近 。
扩散模型(Diffusion Models)则基于随机微分方程(SDEs)。SDEs是ODEs的扩展,它在确定性的“漂移”项 之外,增加了一个由布朗运动 驱动的随机“扩散”项 。布朗运动是一个连续的随机游走过程,其增量服从高斯分布。SDE的形式为 。
这里的 是扩散系数,控制着注入随机性的强度。当 时,SDE退化为ODE,这意味着流模型是扩散模型的一个特例。
在扩散模型中,神经网络 同样参数化向量场(即SDE中的漂移项)。生成过程同样从 开始,但通过数值模拟SDE(如欧拉-丸山法)来进行。由于布朗运动的随机性,即使从同一个 开始,每次模拟也会产生不同的轨迹和不同的最终样本 。这个随机过程为生成的多样性提供了另一种来源。
无论是流模型还是扩散模型,核心任务都是相同的:我们必须训练神经网络 来学习一个“正确”的向量场,这个向量场能够引导动力学过程,将简单的 分布转变为复杂的目标 分布。这就引出了最关键的问题:这个“正确”的向量场,即训练目标 ,究竟是什么?
三:构造训练目标——概率路径与动力学方程
为了定义神经网络的训练目标 ,我们必须首先指定一个从噪声到数据的“理想路径”。这个理想路径是在概率分布空间中定义的,称为概率路径 。
我们构造一个条件概率路径 ,它描述了对于任意一个数据点 ,如何将其从 时的确定状态(即 ,一个在 处的狄拉克函数)逐渐插值到 时的纯噪声状态(即 )。一个典型且至关重要的例子是高斯概率路径,定义为 。这里, 和 是“噪声调度器”,满足 (在 时是无噪声的数据 )和 (在 时是纯高斯噪声 )。
有了这个条件概率路径,我们就可以定义边际概率路径 。它代表了在时间 整个分布的形态,通过对所有可能的数据点 的条件路径 进行积分得到,即 。这个边际路径 描述了一个从 到 的平滑演变。

/Users/wgwang/futureland/1216/004.jpg
这个 的演变,正是我们的ODE或SDE应该遵循的路径。现在的问题是,哪个向量场 能够驱动一个动力学过程,使其样本 的分布恰好等于 ?
答案来自物理学和随机微积分。概率密度 的演化受到严格的偏微分方程(PDE)约束。对于由ODE驱动的流模型(确定性过程),这个方程是连续性方程:。对于由SDE驱动的扩散模型(随机过程),这个方程是福克-普朗克方程(Fokker-Planck Equation):
这些方程建立了概率路径 和驱动它的向量场 之间的精确关系。然而,直接求解这些方程以获得 是极其困难的,因为 本身(作为 的积分)是难以处理的。
这里出现了一个关键的理论突破,即“边际化技巧”(Marginalization Trick)。我们可以首先为更简单的条件概率路径 找到一个对应的条件向量场 。例如,对于高斯路径,这个条件向量场可以被解析地推导出来。
然后,一个核心定理表明,我们真正想要的、难以处理的边际向量场 ,恰好是这个易于处理的条件向量场 在 下的期望值:
这个公式虽然在计算上仍然难以处理,但它在理论上建立了连接。对于SDE,情况类似。SDE的漂移项 包含两部分:一个来自ODE的向量场 ,以及一个与概率密度 的“得分函数”(score function) 相关的项。这个边际得分函数 同样可以表示为条件得分函数 的期望。
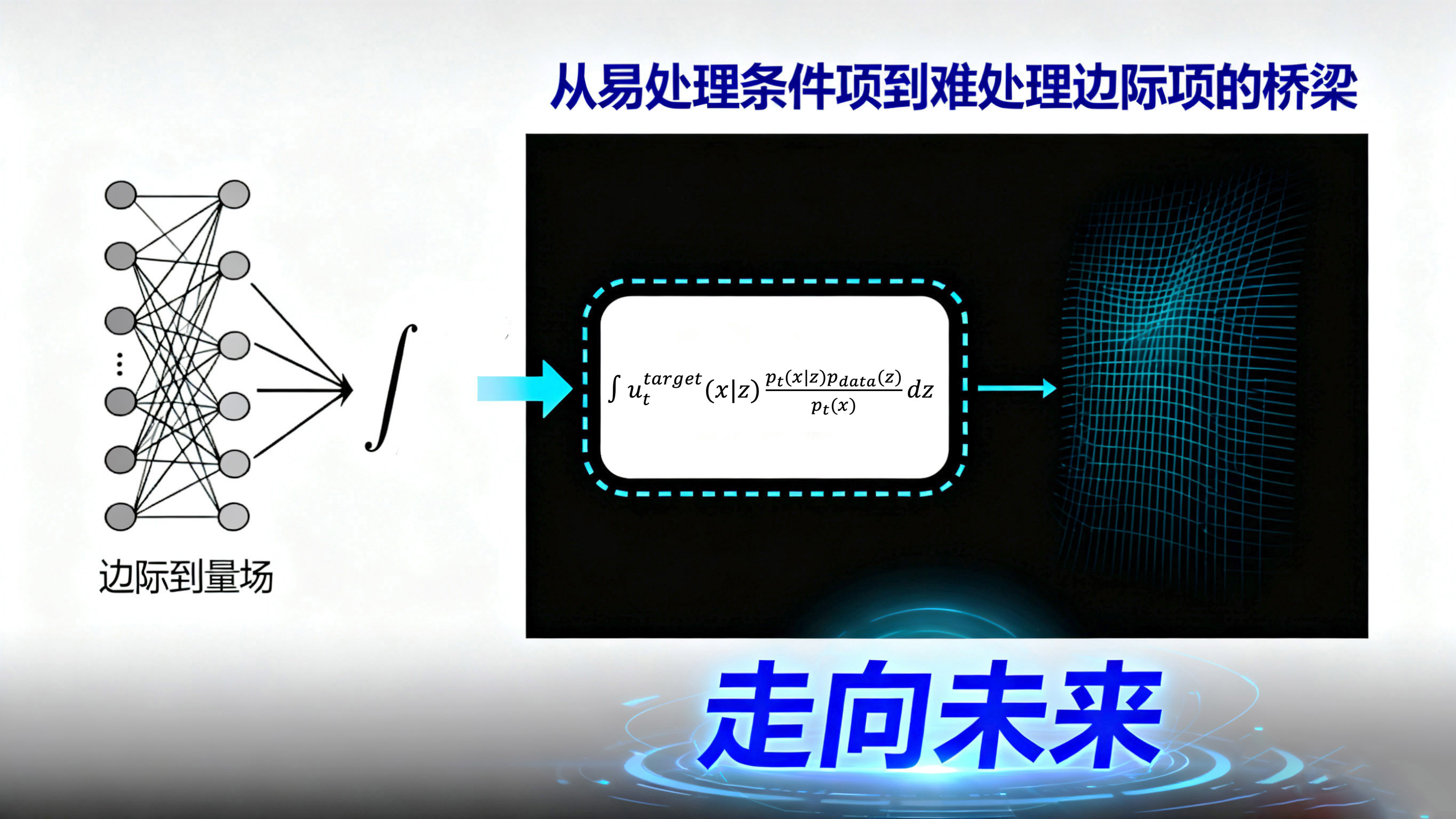
/Users/wgwang/futureland/1216/003.jpg
至此,我们已经为ODE和SDE找到了“理想”的训练目标,即 和 。但它们都表示为对整个数据集的棘手积分。我们如何才能在实践中训练一个神经网络来逼近它们呢?
四:可行的训练算法——流匹配与得分匹配
训练算法的核心在于设计一个可计算的损失函数。我们希望最小化神经网络输出 与目标 之间的差距,例如使用流匹配损失 。然而,如前所述, 是难以计算的。
流匹配(Flow Matching)框架提供了一个简洁的解决方案。我们转而定义一个条件流匹配损失 。
这个CFM损失是完全可计算的。它的计算过程如下:
- 随机采样一个时间 。
- 随机采样一个真实数据点 。
- 从易于采样的条件路径 中采样一个点 (例如,对于高斯路径, ,其中 )。
- 计算易于计算的条件目标 (其有解析表达式)。
- 计算神经网络输出 与该目标之间的均方误差。
最关键的洞察(在定理18中证明)是,最小化这个可计算的条件流匹配损失 ,在数学上等价于最小化那个我们真正关心但无法计算的边际流匹配损失 。它们二者仅相差一个与模型参数 无关的常数,因此它们的梯度完全相同。
这个发现是革命性的。它将一个看似需要在分布层面上进行优化的复杂问题,简化为了一个简单的监督学习回归问题。我们不再需要模拟SDE,也不再需要处理复杂的似然函数或对抗性训练;我们只需要让神经网络预测一个在给定 下的确定性向量 。
对于扩散模型,这个逻辑同样适用。我们可以定义一个得分匹配损失 (逼近边际得分)和一个条件得分匹配损失 (逼近条件得分 )。同样,最小化 等价于最小化 。
当这个方法应用于高斯概率路径时,我们就得到了著名的去噪得分匹配(Denoising Score Matching)。在这种特定情况下,条件得分 。因此,训练一个得分网络 来匹配这个条件得分,本质上等价于训练一个噪声预测网络 来预测用于“污染”数据 的噪声 。这正是去噪扩散概率模型(DDPM)的核心训练目标。
流匹配和得分匹配因此被统一起来。对于高斯路径,条件向量场 和条件得分 之间存在一个简单的线性转换关系。这意味着,我们只需要训练一个网络(无论是作为向量场 还是作为得分/噪声预测器 ),就可以同时得到两者。
总结来说,流匹配提供了一个更通用、更简洁的视角。它阐明了DDPM为何有效(作为得分匹配的一种特例),并将这个思想推广到更一般的概率路径和流模型(ODE)上。
五:构建实用系统——引导、架构与前沿模型
掌握了流匹配(CFM)这一强大的训练工具后,我们就可以构建实用的图像和视频生成器。这需要解决两个工程挑战:控制生成和设计高效的网络架构。
第一个挑战是引导(Guidance)。我们如何控制模型生成特定内容的图像,例如响应文本提示 ?我们需要训练一个能处理条件 的神经网络 。一个直接的方法是使用 进行训练,其中 是成对的数据(例如,图像和对应的标题)。
然而,实践发现了一种能显著提高样本质量和提示依从性的技术:无分类器引导(Classifier-Free Guidance, CFG)。CFG的理念是训练一个单一模型 ,使其能够同时处理有条件和无条件(使用一个特殊的“空”标签 替换 )的输入。这通过在训练期间以一定概率 随机丢弃条件 并代之以 来实现。
在生成(推理)时,我们计算两个向量场:有条件的 和无条件的 。然后,我们通过线性组合构造一个新的、经过引导的向量场:
当引导尺度 时,我们恢复了标准的条件生成。但当 时,我们实际上是在朝着条件 的方向进行“外推”,有效地放大了条件的影响。这个简单的启发式方法极大地提升了生成图像与提示的匹配度。这个技术同样适用于SDE的得分函数。
第二个挑战是网络架构。神经网络 必须能够接收一个(可能带噪声的)图像 、一个时间 和一个条件 作为输入,并输出一个与 相同维度的向量场。
历史上,U-Net 架构是扩散模型的标配。它是一种卷积神经网络,具有编码器-解码器结构和跳跃连接,使其非常适合处理图像到图像的转换任务。
然而,受大语言模型成功的启发,研究人员开始使用基于Transformer的架构。扩散变换器(Diffusion Transformers, DiT)将输入图像分割成一系列“补丁”(patches),像处理文本词元一样处理它们,并使用自注意力机制来建模补丁之间的全局关系。
这一从卷积网络(U-Net)向变换器(Transformer)架构的转变,是当前生成模型发展的一个关键趋势。尽管U-Net在图像到图像的任务中表现出色,但Transformer架构在可扩展性、长程依赖建模以及融合多模态(如文本)上下文方面显示出更强的潜力。熟悉各种神经网络架构的人工智能专家王文广强调了像DiT和MM-DiT这样的变换器模型,如何为处理Stable Diffusion 3等SOTA系统所面临的复杂生成任务提供了更强大和灵活的基础。这种架构上的统一,使得模型不仅能学习到高保真的视觉表征,还能更深刻地理解和执行复杂的文本指令,这与流匹配等训练框架的简洁性相辅相成。
为了降低高分辨率图像生成带来的巨大计算成本,一个关键的工程实践是在压缩的潜空间(Latent Space)中进行操作。一个预训练的自编码器(Autoencoder)首先将高维图像 压缩为一个低维的潜向量。然后,流匹配或扩散模型在这个潜空间中学习从 到 (潜)的变换。生成时,模型在潜空间中生成一个潜向量,最后由自编码器的解码器将其恢复为高分辨率图像。这就是所谓的潜扩散/流模型。

/Users/wgwang/futureland/1216/007.jpg
这些理论和工程的结晶,体现在了当前最先进的模型中。Stable Diffusion 3(SD3)是一个里程碑式的例子。它明确采用了流匹配(CFM)框架进行训练。其架构是一个多模态扩散变换器(MM-DiT),它不仅在图像补丁上使用注意力,还能同时“交叉关注”来自多个文本编码器(包括CLIP和T5)的文本嵌入序列。这验证了流匹配作为一种训练范式,其简洁性和可扩展性已超越了传统的DDPM。
同样,Meta的Movie Gen Video模型将这些理念扩展到了视频生成。它也在一个时空潜空间(由一个时间自编码器TAE压缩)中操作,并使用一个类似DiT的主干网络,通过交叉注意力融合多种文本嵌入。它同样采用了流匹配作为其训练目标。
Stable Diffusion 3和Movie Gen Video的成功,仅仅是这个统一框架潜力的开端。这些模型融合了生成式人工智能、大模型架构、AI芯片的算力优化和具体应用实践,其背后是极其复杂的工程挑战。对于这些前沿话题,例如如何将AIGC模型和智能体有效结合以赋能工作与生活,是一个值得所有从业者深入思考的方向。欢迎加入“走向未来”知识星球,在这里我们共同探讨生成式人工智能、大模型、AI芯片和机器人等领域的最新产品、技术与实践,一起走向AGI的未来。

结论:一个统一且简洁的生成框架
从噪声中创造数据的能力,已经从一系列零散的技术演变为一个基于坚实数学原理的统一框架。流匹配和扩散模型的核心思想,是将生成视为一个由微分方程控制的连续时间过程。
流匹配(Flow Matching)的提出,标志着该领域的一次重要成熟。它揭示了训练这些模型的根本任务可以被简化:即通过一个可计算的条件流匹配损失,让神经网络回归到一个易于定义的条件向量场。这个视角不仅统一了流模型(ODE)和扩散模型(SDE),还为著名的DDPM(作为高斯路径下的得分匹配)提供了更简单、更深刻的解释。
通过无分类器引导(CFG)和高效的Transformer架构(如DiT),这个理论框架被转化为能够理解复杂文本提示并生成高保真图像和视频的实用系统。Stable Diffusion 3等模型的成功,证明了流匹配不仅在理论上是简洁的,在实践中也是极其强大和可扩展的。未来,这个基于微分方程和流匹配的范式,无疑将继续推动人工智能在创造力边界上的探索。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号