产品提了个每秒20W次的检索需求,架构如何演进?(第97讲,收藏)

产品提了个每秒20W次的检索需求,架构如何演进?(第97讲,收藏)

架构师之路
发布于 2025-11-24 15:26:53
发布于 2025-11-24 15:26:53
《架构师之路:架构设计中的100个知识点》
97.搜索引擎架构与细节
产品提了一个需求:
我想做一个内容检索功能,不复杂,100亿数据,每秒10万查询而已,两个星期能上线吗?
大部分工程师未必接触过“搜索内核”,但互联网业务,基本会涉及“检索”功能。以同城的帖子业务场景为例,帖子的标题,帖子的内容有很强的用户检索需求,在业务、流量、并发量逐步递增的各个阶段,应该如何实现检索需求呢?
原始阶段-LIKE
创业阶段,常常用这种方法来快速实现。
数据在数据库中可能是这么存储的:
t_tiezi(tid, title, content)
满足标题、内容的检索需求可以通过LIKE实现:
select tid from t_tiezi where content like ‘%天通苑%’
这种方式确实能够快速满足业务需求,存在的问题也显而易见:
1. 效率低,每次需要全表扫描,计算量大,并发高时cpu容易100%;
2. 不支持分词;
初级阶段-全文索引
如何快速提高效率,支持分词,并对原有系统架构影响尽可能小呢,第一时间想到的是建立全文索引:
alter table t_tiezi add fulltext(title,content)
使用match和against实现索引字段上的查询需求。
全文索引能够快速实现业务上分词的需求,并且快速提升性能(分词后倒排,至少不要全表扫描了),但也存在一些问题:
1. 由于全文索引利用的是数据库特性,搜索需求和普通CURD需求耦合在数据库中:检索需求并发大时,可能影响CURD的请求;CURD并发大时,检索会非常的慢;
2. 数据量达到百万级别,性能还是会显著降低,查询返回时间很长,业务难以接受;
3. 比较难水平扩展;
中级阶段-开源外置索引
为了解决全文索引的局限性,当数据量增加到大几百万,千万级别时,就要考虑外置索引了。外置索引的核心思路是:索引数据与原始数据分离,前者满足搜索需求,后者满足CURD需求,通过一定的机制(双写,通知,定期重建)来保证数据的一致性。
原始数据可以继续使用Mysql来存储,外置索引如何实施?
Solr,Lucene,ES都是常见的开源方案。其中,ES(ElasticSearch)是目前最为流行的。
Lucene虽好,潜在的不足是:
1. Lucene只是一个库,需要自己做服务,自己实现高可用/可扩展/负载均衡等复杂特性;
2. Lucene只支持Java,如果要支持其他语言,必须得自己做服务;
3. Lucene不友好,这是很致命的,非常复杂,使用者往往需要深入了解搜索的知识来理解它的工作原理,为了屏蔽其复杂性,还是得自己做服务;
为了改善Lucene的各项不足,解决方案都是“封装一个接口友好的服务,屏蔽底层复杂性”,于是有了ES:
1. ES是一个以Lucene为内核来实现搜索功能,提供RESTful接口的服务;
2. ES能够支持很大数据量的信息存储,支持很高并发的搜索请求;
3. ES支持集群,向使用者屏蔽高可用/可扩展/负载均衡等复杂特性;
目前,快狗打车使用ES作为核心的搜索服务,实现业务上的各类搜索需求,其中:
1. 数据量最大的“接口耗时数据收集”需求,数据量大概在10亿左右;
2. 并发量最大的“经纬度,地理位置搜索”需求,线上平均并发量大概在2000左右,压测数据并发量在8000左右;
所以,ES完全能满足10亿数据量,5k吞吐量的常见搜索业务需求。
高级阶段-自研搜索引擎
当数据量进一步增加,达到10亿、100亿数据量;并发量也进一步增加,达到每秒10万吞吐量;业务个性也逐步增加的时候,就需要自研搜索引擎了,定制化实现搜索内核了。
到了定制化自研搜索引擎的阶段,超大数据量、超高并发量为设计重点,为了达到“无限容量、无限并发”的需求,架构设计需要重点考虑“扩展性”,力争做到:增加机器就能扩容(数据量+并发量)。
同城的自研搜索引擎E-search初步架构图如下:
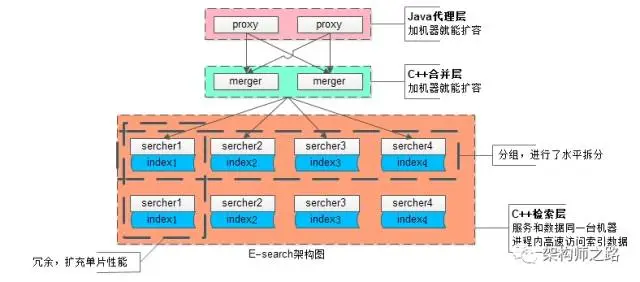
1. 上层proxy(粉色)是接入集群,为对外门户,接受搜索请求,其无状态性能够保证增加机器就能扩充proxy集群性能;
2. 中层merger(浅蓝色)是逻辑集群,主要用于实现搜索合并,以及打分排序,业务相关的rank就在这一层实现,其无状态性也能够保证增加机器就能扩充merger集群性能;
3. 底层searcher(暗红色大框)是检索集群,服务和索引数据部署在同一台机器上,服务启动时可以加载索引数据到内存,请求访问时从内存中load数据,访问速度很快:
- 为了满足数据容量的扩展性,索引数据进行了水平切分,增加切分份数,就能够无限扩展性能,如上图searcher分为了4组
- 为了满足一份数据的性能扩展性,同一份数据进行了冗余,理论上做到增加机器就无限扩展性能,如上图每组searcher又冗余了2份
如此设计,真正做到增加机器就能承载更多的数据量,响应更高的并发量。
简单小结一下:
为了满足搜索业务的需求,随着数据量和并发量的增长,搜索架构一般会经历这么几个阶段:
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号