大数据领域开山鼻祖组件Hadoop核心架构设计


一、Hadoop的整体架构
Hadoop是一个专为大数据设计的架构解决方案,历经多年开发演进,已逐渐发展成为一个庞大且复杂的系统。其内部工作机制融合了分布式理论与具体工程开发的精髓,构成了一个整体架构。
Hadoop最朴素的原理在于,它利用大量的普通计算机来处理大规模数据的存储和分析任务,而非依赖于单一的超级计算机。这一设计理念不仅降低了硬件成本,还通过分布式处理提高了系统的可扩展性和容错性。
Hadoop作为大数据处理领域的基石性架构,其设计理念体现了"分而治之"的分布式计算哲学。经过十余年的技术演进,Hadoop已从最初的单一计算框架发展为包含存储、资源管理、计算引擎等完整组件的生态系统,其架构复杂度反映了分布式系统理论与工程实践的深度融合。
Hadoop 系统的一个架构图,现在已经有了非常多的组件,但最核心的两部分依然是底层的文件系统 HDFS和用于计算的 MapReduce。来看下 Hadoop 系统中的一些重要组成部分。
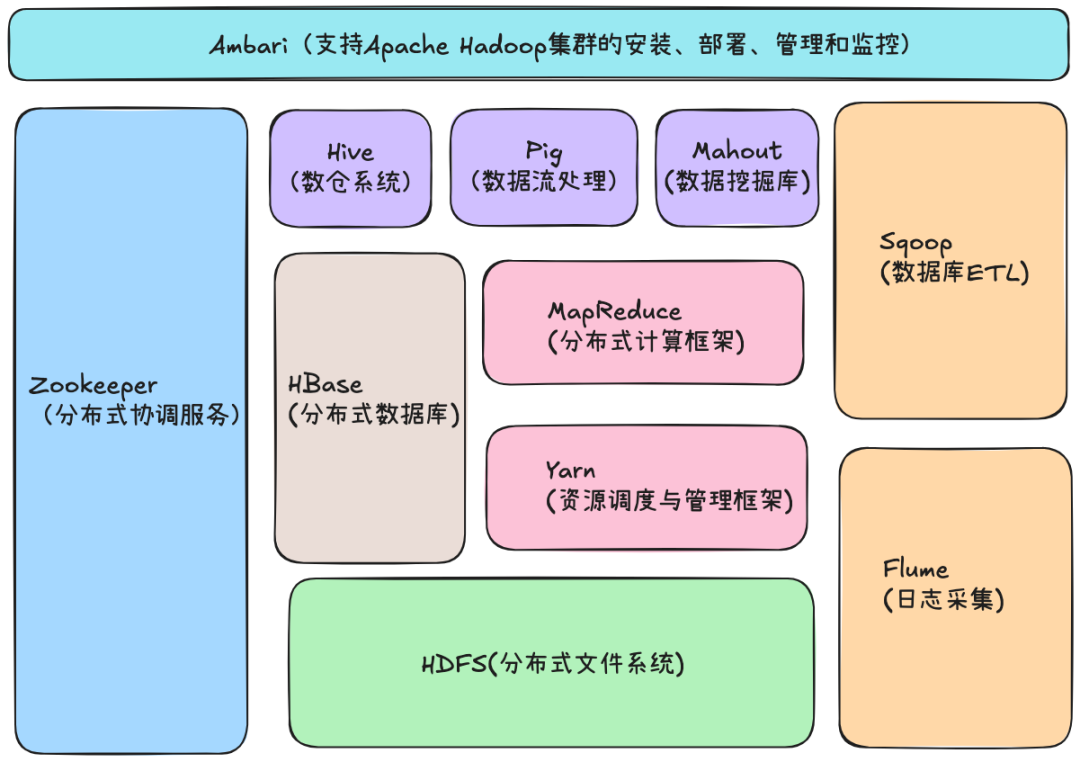
在这里插入图片描述
二、HDFS(分布式文件系统)
HDFS 主要有 NameNode、DataNode、Secondary NameNode 三大组件:
- NameNode
- 管理文件系统的命名空间
- 协调客户端对文件的访问
- 存储文件系统的元数据
- Secondary NameNode
- 定期合并NameNode的编辑日志和镜像文件,减少NameNode启动时间
- 提供NameNode的备份,但不用于故障切换
- DataNode
- 存储实际的数据块
- 执行数据的读写操作
- 定期向NameNode报告其存储的数据块信息
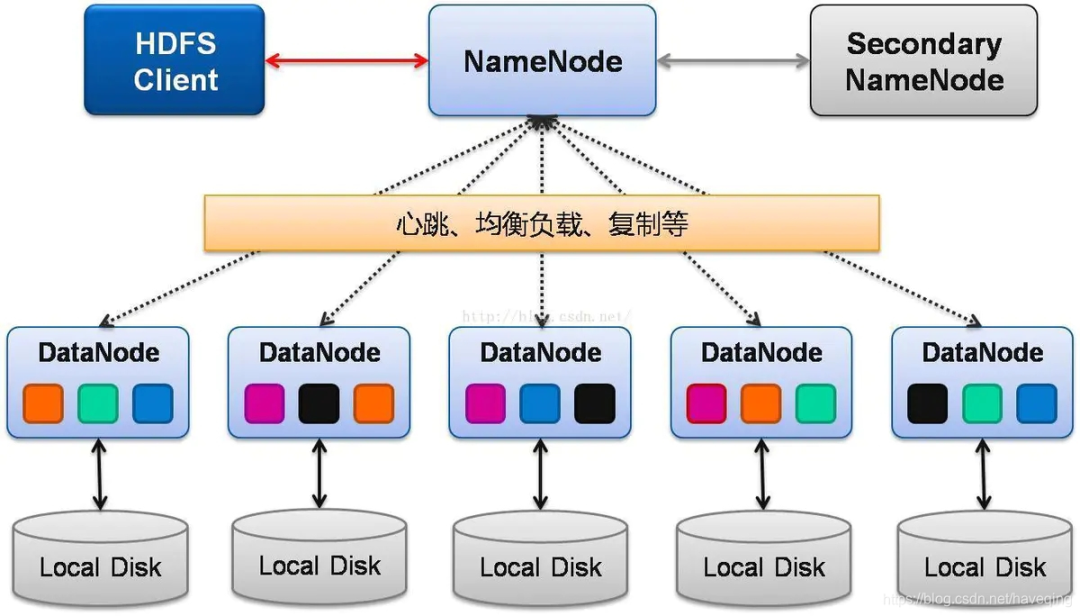
在这里插入图片描述
Primary Namenode 与 Secondary Namenode
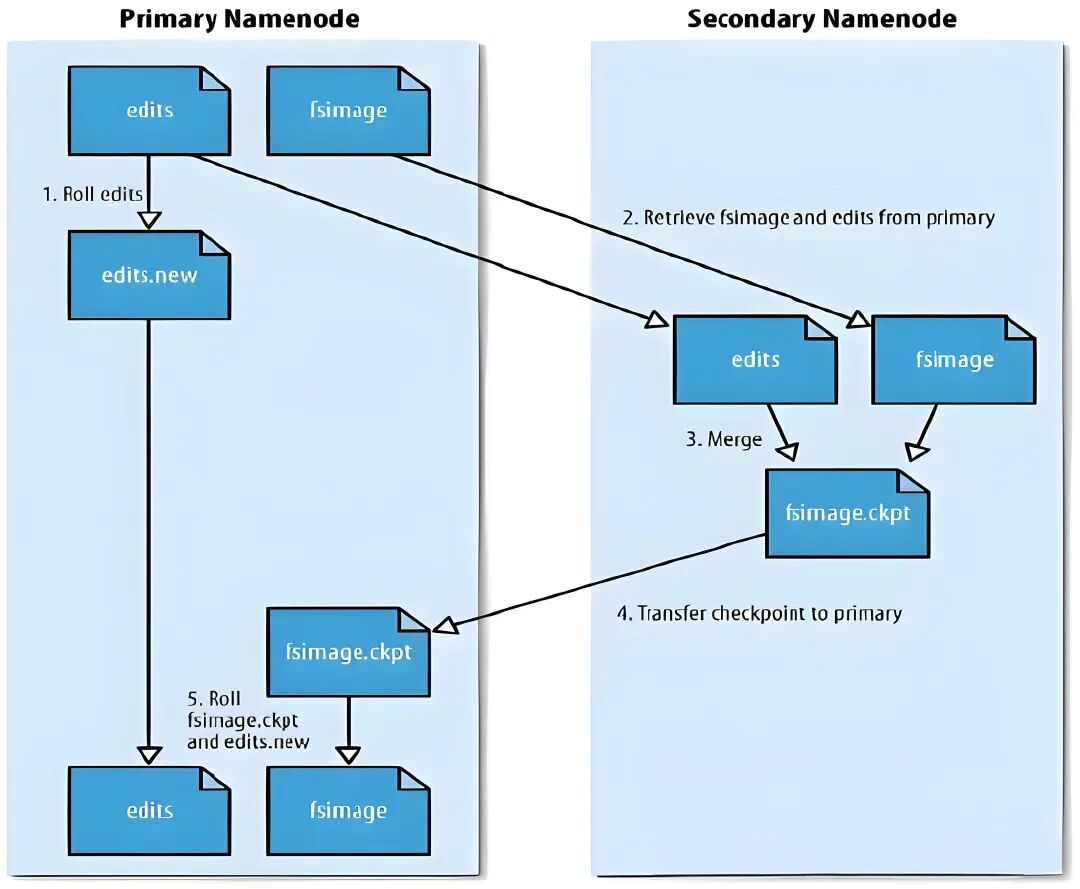
在这里插入图片描述
三、MapReduce(分布式计算框架)
MapReduce 核心思想:分而治之的并行计算
3.1 拆分(Split)→ 并行计算(Map)
- 输入数据被自动切割为 分片(Split)(默认与 HDFS Block 对齐) → 分发到集群节点。
- Map 阶段:每个节点对本地数据执行相同的用户自定义函数,输出中间键值对 (key, value)。
👉 实质:将大规模问题分解为独立子问题
3.2 聚合(Shuffle)→ 归约(Reduce)
- Shuffle 阶段:框架按 key 将中间结果跨节点分组、排序、传输(核心瓶颈)。
- Reduce 阶段:相同 key 的数据发送到同一节点,执行归约逻辑(如求和、去重)。
👉 实质:合并子问题的结果生成全局解
MapReduce Split
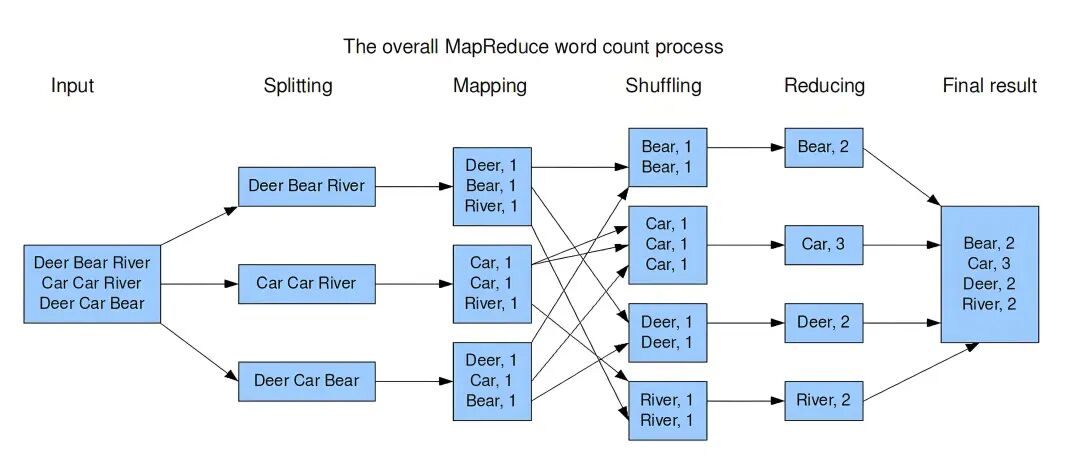
在这里插入图片描述
MapReduce Shuffle
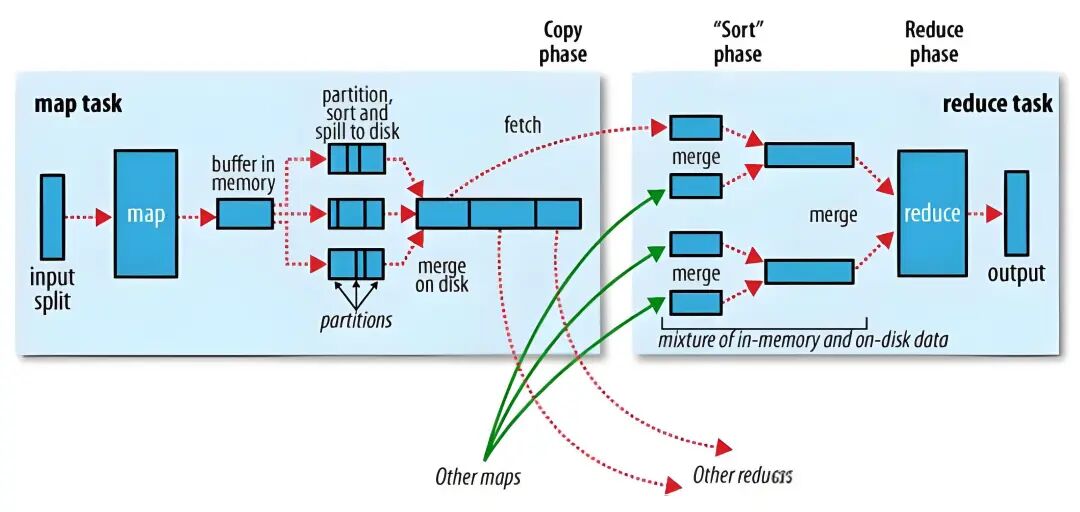
在这里插入图片描述
四、Yarn(资源调度与管理框架)
老周在之前讲解Flink架构的时候讲过YARN集群架构,我这里直接拿我之前Yarn的架构图。YARN集群总体上是经典的主/从(Master/Slave)架构,主要由ResourceManager、NodeManager、ApplicationMaster和Container等几个组件构成。
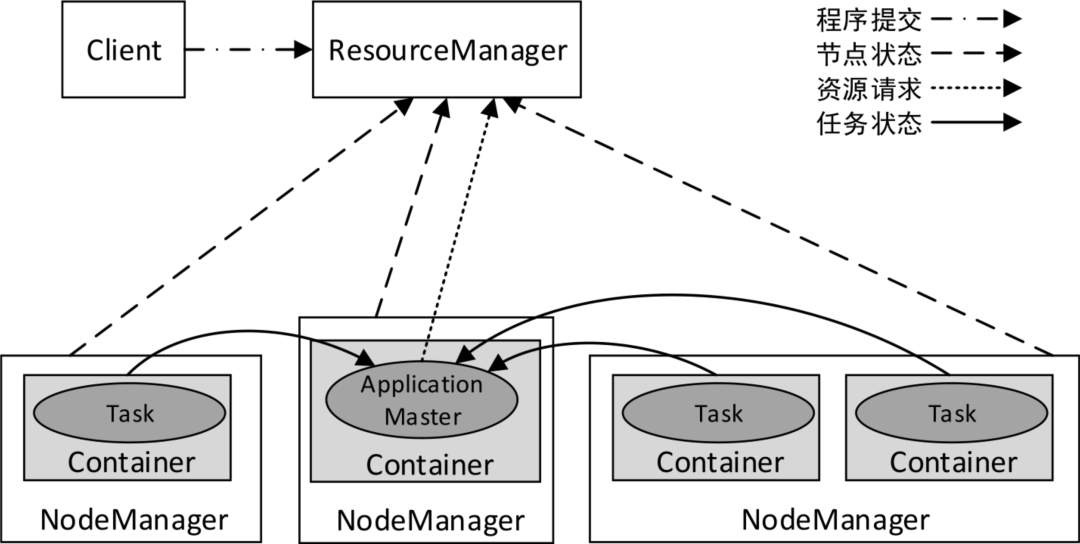
在这里插入图片描述
4.1 ResourceManager
以后台进程的形式运行,负责对集群资源进行统一管理和任务调度。ResourceManager的主要职责如下:
- 接收来自客户端的请求。
- 启动和管理各个应用程序的ApplicationMaster。
- 接收来自ApplicationMaster的资源申请,并为其分配Container。
- 管理NodeManager,接收来自NodeManager的资源和节点健康情况汇报。
4.2 NodeManager
集群中每个节点上的资源和任务管理器,以后台进程的形式运行。它会定时向ResourceManager汇报本节点上的资源(内存、CPU)使用情况和各个Container的运行状态,同时会接收并处理来自ApplicationMaster的Container启动/停止等请求。NodeManager不会监视任务,它仅监视Container中的资源使用情况,例如。如果一个Container消耗的内存比最初分配的更多,就会结束该Container。
4.3 Task
应用程序具体执行的任务。一个应用程序可能有多个任务,例如一个MapReduce程序可以有多个Map任务和多个Reduce任务。
4.4 Container
YARN中资源分配的基本单位,封装了CPU和内存资源的一个容器,相当于一个Task运行环境的抽象。从实现上看,Container是一个Java抽象类,定义了资源信息。应用程序的Task将会被发布到Container中运行,从而限定了Task使用的资源量。
一个应用程序所需的Container分为两类:运行ApplicationMaster的Container和运行各类Task的Container。前者是由ResourceManager向内部的资源调度器申请和启动的,后者是由ApplicationMaster向ResourceManager申请的,并由ApplicationMaster请求NodeManager进行启动。
我们可以将Container类比成数据库连接池中的连接,需要的时候进行申请,使用完毕后进行释放,而不需要每次独自创建。
4.5 ApplicationMaster
ApplicationMaster可在Container内运行任何类型的Task。例如,MapReduce ApplicationMaster请求一个容器来启动Map Task或Reduce Task。也可以实现一个自定义的ApplicationMaster来运行特定的Task,以便任何分布式框架都可以受YARN支持,只要实现了相应的ApplicationMaster即可。
我们可以这样认为:ResourceManager管理整个集群,NodeManager管理集群中的单个节点,ApplicationMaster管理单个应用程序(集群中可能同时有多个应用程序在运行,每个应用程序都有各自的ApplicationMaster)。
YARN集群中应用程序的执行流程如下图所示:
- 客户端提交应用程序(可以是MapReduce程序、Spark程序等)到ResourceManager。
- ResourceManager分配用于运行ApplicationMaster的Container,然后与NodeManager通信,要求它在该Container中启动ApplicationMaster。ApplicationMaster启动后,它将负责此应用程序的整个生命周期。
- ApplicationMaster向ResourceManager注册(注册后可以通过ResourceManager查看应用程序的运行状态)并请求运行应用程序各个Task所需的Container(资源请求是对一些Container的请求)。如果符合条件,ResourceManager会分配给ApplicationMaster所需的Container(表达为Container ID和主机名)。
- ApplicationMaster请求NodeManager使用这些Container来运行应用程序的相应Task(即将Task发布到指定的Container中运行)。
此外,各个运行中的Task会通过RPC协议向ApplicationMaster汇报自己的状态和进度,这样一旦某个Task运行失败,ApplicationMaster就可以对其重新启动。当应用程序运行完成时,ApplicationMaster会向ResourceManager申请注销自己。
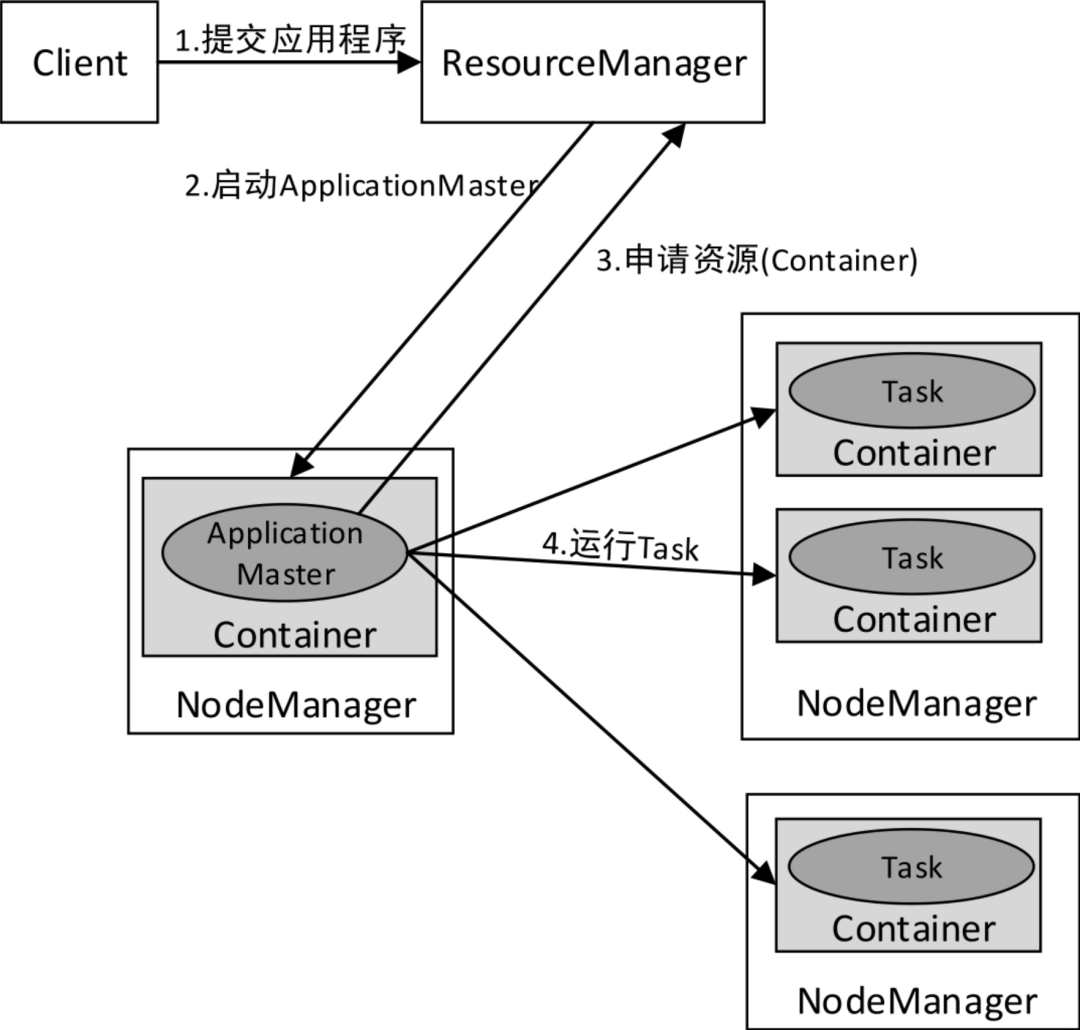
在这里插入图片描述
五、Hadoop HA
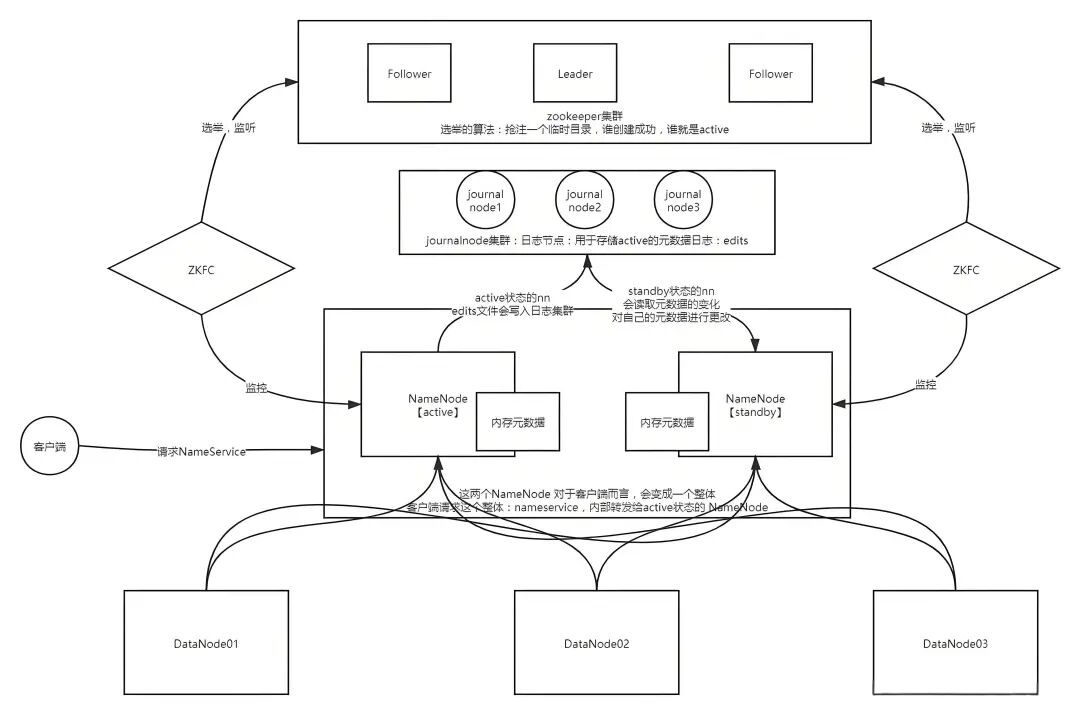
在这里插入图片描述
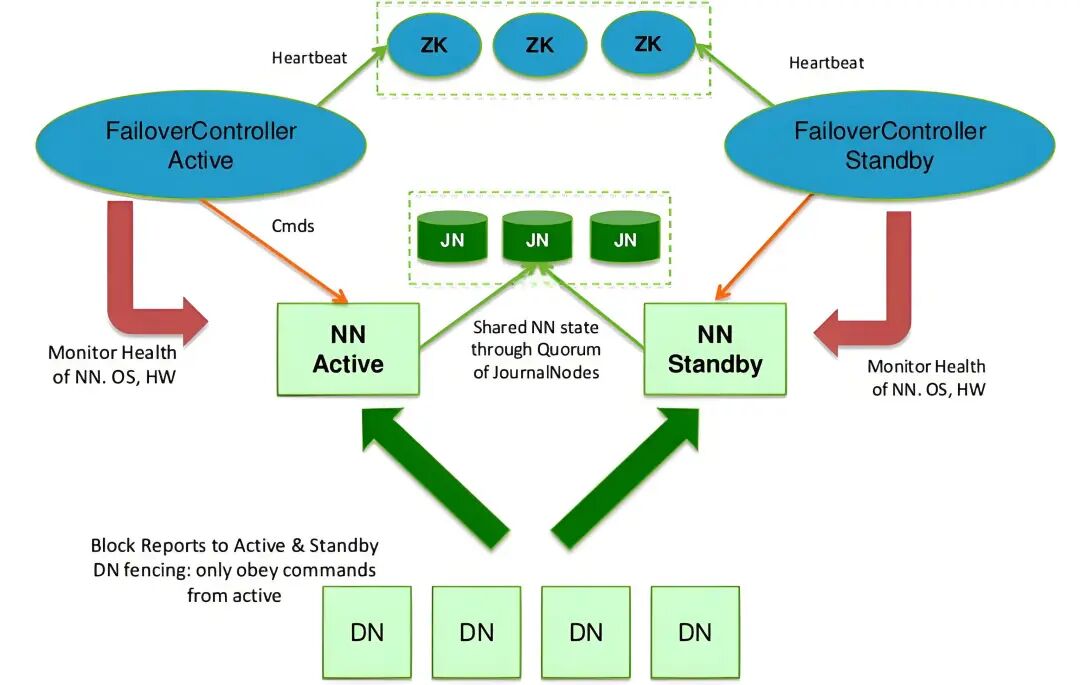
在这里插入图片描述
问题1:两个NameNode主节点,谁是Active,谁是Standby?
利用Zookeeper进行选举
问题2:怎么实现的?
- 每一个NameNode都有一个ZKFC:Zookeeper Failover Contorller
- 功能
- 负责帮助NameNode向Zookeeper进行注册选举,并且监听active的NameNode
- 负责监控NameNode的状态
问题3:如果有两个NameNode,客户端如何知道谁是active?
- 客户端只能请求active状态的NameNode
- 一旦配置了HA,将两个NameNode构建成一个整体
- 客户端不用再请求单个NameNode,请求这个整体,这个整体负责从zookeeper中找到谁是active转发这个请求
问题4:如果有两个NameNode,所有的DataNode向哪个NameNode进行注册呢?
两个NameNode 都注册,只有active的能管理。
问题5:一个是active,一个standby,如果active宕机,standby接替active,如何保证standby的元数据与active是一致的?
- journalnode日志节点
- active状态的 NN,会将自己元数据的变化日志edits文件写入journalnode集群
- standby状态的NN,会从journalnode集群中将变化读取出来,对自己操作,保证自己的元数据与active的元数据是一致的
六、HDFS Architecture
6.1 NameNode and DataNodes
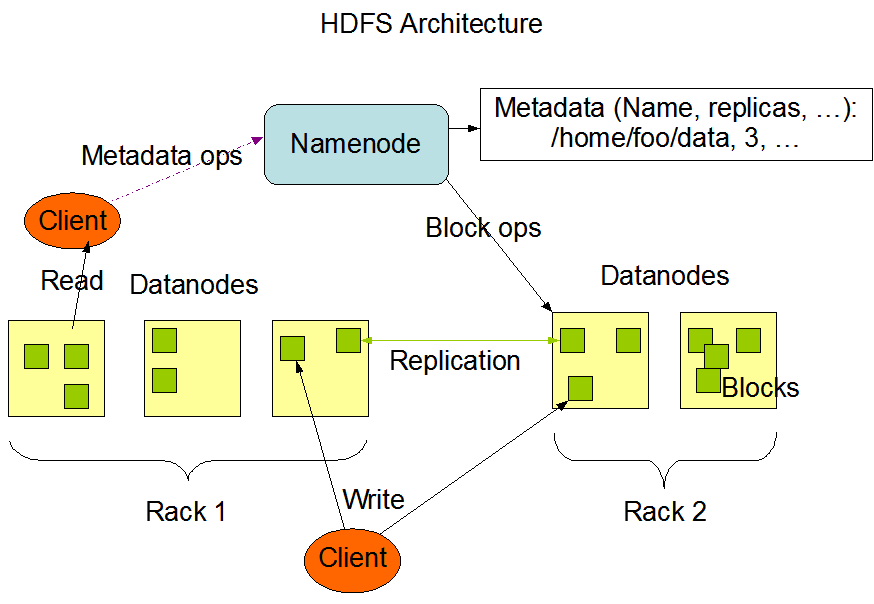
在这里插入图片描述
6.2 Data Replication
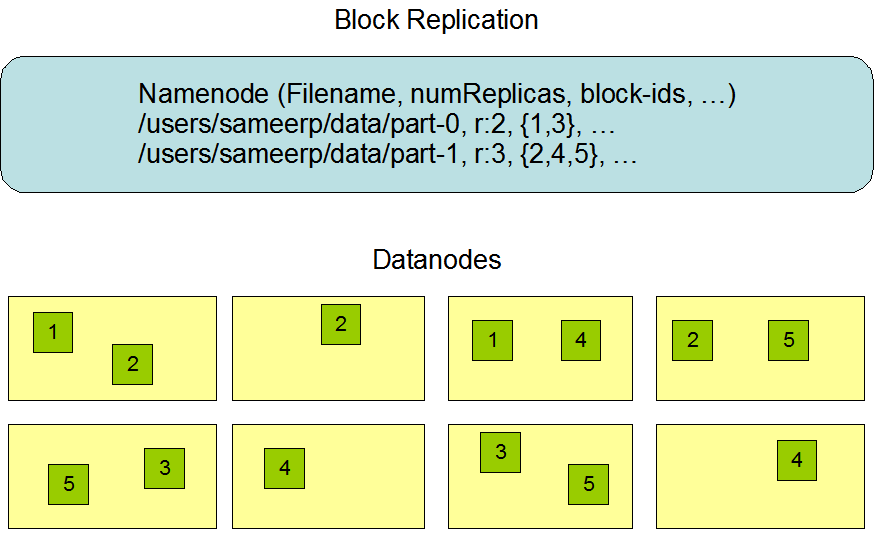
在这里插入图片描述
欢迎大家关注我的公众号【老周聊架构】,AI、大数据、云原生、物联网等相关领域的技术知识分享。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号