OpenCV × YOLO × 大模型:构建实时视频智能分析全链路方案
原创
OpenCV × YOLO × 大模型:构建实时视频智能分析全链路方案
原创
音视频牛哥
发布于 2025-08-12 16:41:41
发布于 2025-08-12 16:41:41
✳️ 引言:从“能看”到“能懂”的三大核心能力
在实时视频智能分析体系中,OpenCV、YOLO 和 大模型 是最常被提及的三大技术关键词。 它们并非互相竞争,而是分工明确、优势互补,共同构成现代视觉 AI 系统的核心能力栈:
- OpenCV —— 视觉计算的“基础工具箱”,擅长图像预处理、特征提取、几何变换等传统算法,实现从原始画面到可用数据的高效转换。
- YOLO —— 深度学习驱动的“目标检测引擎”,能够在毫秒级内同时定位并分类多个目标,为实时场景识别奠定基础。
- 大模型 —— 跨模态推理的“认知中枢”,具备复杂语义理解、场景描述与决策能力,让机器不仅能“看见”,更能“理解”和“判断”。
如果将一个实时视频智能分析系统类比为 智慧中枢:
- OpenCV 是 调焦与画质增强器
- YOLO 是 识别与标记系统
- 大模型 是 语义与决策大脑
但要让这三者在在线、实时、可扩展的条件下协同工作,前提是拥有一条 稳定、低延迟且跨平台的视频数据通道。 这正是 大牛直播SDK(SmartMediaKit) 在整个系统架构中的核心价值——为视觉智能提供持续、可靠的“数据动脉”。
1️⃣ OpenCV:视觉处理的基础能力层
在任何实时视频智能分析系统中,第一步往往不是“直接识别目标”,而是获取并优化原始画面,确保后续的检测与推理过程在高质量数据的基础上进行。 这正是 OpenCV(Open Source Computer Vision Library) 发挥作用的地方。
🔍 核心定位
OpenCV 是全球应用最广泛的开源计算机视觉库,提供了数千种高效的视觉算法实现。它的目标是帮助开发者快速完成图像和视频的基础处理与分析,包括:
- 图像预处理:裁剪、缩放、旋转、翻转、颜色空间转换(RGB ↔ HSV / 灰度)
- 图像增强:直方图均衡化、锐化、去噪、对比度与亮度调节
- 边缘与轮廓检测:Canny、Sobel、Laplace 等算子
- 特征提取与匹配:SIFT、ORB、SURF 等局部特征算法
- 视频操作:视频帧解码、逐帧处理、帧差检测
⚙️ 技术优势
- 轻量化:可在嵌入式、移动端和桌面端部署
- 跨平台:Windows、Linux、Android、iOS 均有成熟支持
- 灵活性高:支持多种编程语言(C++、Python、Java 等)
- 计算效率高:优化过的底层实现,可充分利用 CPU 与 GPU
🛠 与大牛直播SDK的结合
在实时视频分析链路中,大牛直播SDK可以提供毫秒级延迟的跨平台视频帧捕获接口,而 OpenCV 则接管后续的图像处理步骤。例如:
- 实时帧提取
- SDK 播放器或推流端通过回调直接输出 NV12、I420 或 RGB 帧
- 预处理增强
- 使用 OpenCV 对帧进行降噪、色彩增强、几何校正
- 下游分析准备
- 将优化后的帧送入 YOLO 或大模型进行目标检测与语义推理
📌 示例架构:
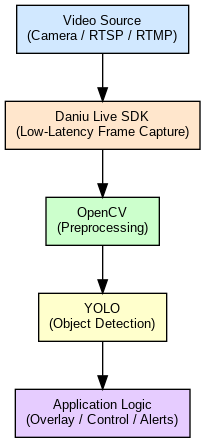
🎯 实际应用案例
- 工业巡检:对低光照、灰尘干扰的画面进行去噪与锐化,保证 YOLO 识别设备刻度的准确性
- 安防监控:对鱼眼镜头画面做畸变矫正,提高人形检测的精准度
2️⃣ YOLO:实时目标检测引擎
在 OpenCV 完成画面预处理之后,下一步就是**“在画面中找到并识别目标”**。 这正是 YOLO(You Only Look Once) 的强项。
🚀 核心理念
YOLO 的设计哲学是:一次网络前向计算,直接完成所有目标的位置与类别预测。 它采用单阶段(One-Stage)检测架构,将图像划分为网格(Grid),每个网格同时预测:
- 目标边界框(Bounding Box)的坐标与大小
- 目标类别的概率分布
这种端到端的方式,使得 YOLO 在速度和精度之间取得了极佳的平衡,非常适合实时视频场景。
📊 技术特点
- 高速度:在 GPU 加速下,帧率可达 30~100 FPS
- 多目标支持:同一帧内可检测多种类别目标
- 端到端:无需复杂的后处理,直接输出检测框与类别
- 多版本迭代:YOLOv3/v4/v5/v7/v8 在速度、精度和部署灵活性上不断优化
⚙️ YOLO 与大牛直播SDK的结合方式
在实时视频智能分析中,YOLO 通常紧跟在大牛直播SDK的帧获取阶段之后:
- 大牛直播SDK帧捕获
- 通过播放器或推流端回调,获取原始视频帧(NV12、I420、RGB)
- (可选)OpenCV预处理
- 对图像进行尺寸缩放、去噪、增强等处理
- YOLO 推理
- 将预处理后的帧送入 YOLO 模型进行推理
- 结果回传与可视化
- 直接在视频画面上叠加检测框与标签
- 或将检测结果以 JSON 形式传输到后端/控制系统
🎯 应用场景案例
- 智慧安防:实时检测入侵人员、可疑行为,并触发报警
- 工业质检:识别流水线上零件缺陷,实现自动剔除
- 交通监控:检测车牌、车型、交通违章行为
- 远程教育/培训:检测学员的举手、站立、互动动作,统计参与度
3️⃣ 大模型:语义与多模态的推理中枢
即便 YOLO 能精准识别出“画面中有什么”,它依然停留在“感知”层面。 要让机器真正理解“发生了什么”,甚至推测“接下来会发生什么”,就需要引入 大模型(Large Models) 作为系统的高级认知层。
🧠 核心能力
现代大模型(如 GPT-4V、Qwen-VL、InternVL 等)已经从传统的图像分类/检测任务,发展到 多模态推理 阶段,具备跨领域知识与上下文理解能力,具体表现为:
- 复杂语义理解:不仅能识别“人”,还能理解“人正在进行某种行为”
- 时序分析:从视频帧序列中分析事件发展趋势
- 跨模态融合:结合视频、文本、传感器数据进行综合判断
- 自然语言交互:直接用人类语言描述场景、回答问题、生成报告
🔍 技术特征
- 强泛化能力:无需为每个任务单独训练模型
- 指令可控:可通过 Prompt 精确指定分析任务
- 场景适应性强:可处理复杂、多变的真实环境
- 推理深度高:不仅“看到”表象,还能基于知识和逻辑做决策
⚙️ 大模型与大牛直播SDK的结合
在一个实时视频智能分析系统中,大模型通常位于 YOLO 之后,负责高阶语义处理与业务决策:
- 大牛直播SDK 低延迟视频输入
- 接收并转发来自摄像机、无人机、会议系统等视频流
- OpenCV/YOLO 前处理与检测
- 提供目标位置、类别、属性等结构化信息
- 大模型语义推理
- 接收检测结果和部分原始帧,生成场景描述、行为分析或风险评估
- 业务控制与反馈
- 将推理结果传输到中控系统、告警平台或自动执行设备
📌 典型应用
- 智慧安防
- YOLO 检测到“有人翻越围栏” → 大模型判断该行为是否符合正常模式 → 自动报警并记录事件
- 远程医疗
- YOLO 识别手术器械与动作 → 大模型分析手术步骤是否规范 → 给出实时提示
- 工业巡检
- YOLO 检测到设备仪表 → 大模型判断读数是否异常,并结合历史数据预测可能的故障
4️⃣ 三层能力协作与全链路架构
一个高效的实时视频智能分析系统,可以抽象为以下三层:
能力层 | 核心技术 | 典型任务 | 输出结果 |
|---|---|---|---|
视觉处理层 | OpenCV | 图像预处理、增强、特征提取 | 高质量图像帧 |
目标检测层 | YOLO | 实时多目标检测 | 目标位置 + 类别 |
语义推理层 | 大模型 | 复杂语义理解、行为分析、预测 | 语义描述 + 决策建议 |
大牛直播SDK(SmartMediaKit) 贯穿其中,作为稳定、低延迟、跨平台的视频数据通道,为三层能力提供持续、高质量的输入。
5️⃣ 架构示意
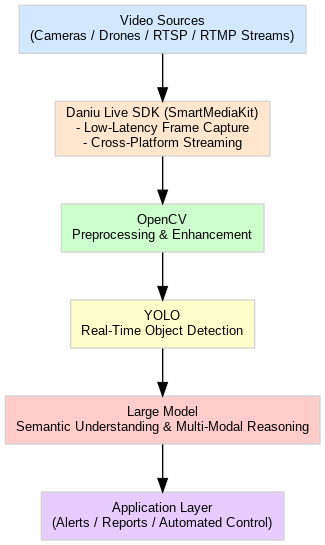
🔚 结语与展望:迈向实时多模态 AI 视频系统
从 OpenCV 的图像预处理,到 YOLO 的实时目标检测,再到 大模型 的语义理解与跨模态推理,现代视频智能分析系统已经不再是单一算法的堆砌,而是一个 多能力协作的生态体系。
在这个体系中,大牛直播SDK(SmartMediaKit) 扮演的角色并不仅仅是“视频传输工具”—— 它是保证整条智能分析链路能够在低延迟、跨平台、可扩展条件下稳定运行的数据动脉。
🎯 核心价值回顾
- OpenCV:优化视觉输入质量
- YOLO:快速获取精准目标位置信息
- 大模型:进行高阶语义推理与决策
- 大牛直播SDK:为这三者提供实时、高质量、可运维的视频输入与分发能力
📈 未来趋势
- 实时多模态融合
- 视频将与音频、传感器、文本数据融合,构建完整的感知与决策闭环
- 边缘计算协同
- 部分 OpenCV 与 YOLO 推理将在摄像机或边缘设备上完成,大模型部署在云端,通过 SDK 实现低延迟交互
- 自适应链路优化
- 根据网络状态动态调整视频质量、帧率与推理频率,确保关键时刻的响应速度
- 行业专用模型
- 结合领域数据定制化训练 YOLO 与大模型,实现更高精度与更强业务相关性
📌 总结
未来的实时视频 AI 系统,将不再只是“看”和“识别”,而是具备感知 → 理解 → 决策 → 执行的全链路闭环能力。 在这条链路中,大牛直播SDK 将继续作为稳定的“视觉数据基础设施”,让 OpenCV、YOLO、大模型 这三大核心能力真正落地到各行各业,从智慧安防到工业巡检,从远程医疗到无人机作业,实现更智能、更高效、更可靠的视觉计算未来。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号