频繁Full GC如何优化?


大家好,我是苏三,又跟大家见面了。
前言
我们在面试时,经常会被面试官问到:线上服务频繁Full GC该如何优化?
今天这篇文章跟大家一起聊聊这个话题,希望对你会有所帮助。
1. 什么是Full GC?
当老年代空间不足时,JVM会触发Stop-The-World的全局回收(Full GC),暂停所有应用线程。
致命危害(生产环境实测):
暂停时间 | 业务影响 |
|---|---|
1秒 | 支付超时率上升5% |
3秒 | 数据库连接池耗尽 |
10秒 | 服务被注册中心摘除 |
对象的晋升之路流程图:
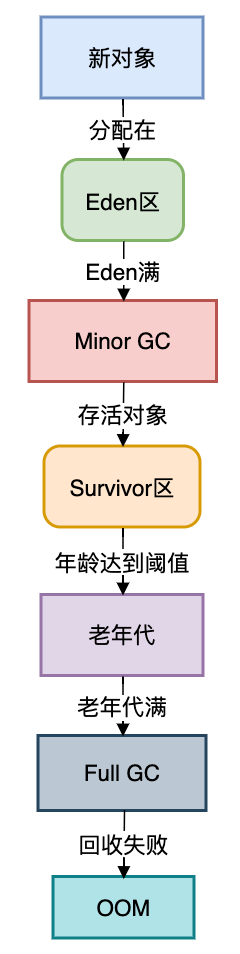
关键代码:年龄计数器
// HotSpot虚拟机源码片段(objectMonitor.cpp)
void ObjectSynchronizer::fast_enter(Handle obj, BasicLock* lock) {
if (obj->age() >= MaxTenuringThreshold) { // 年龄阈值检查
promote_to_old_gen(obj); // 晋升老年代
}
}
2.如何排查定位问题?
2.1 实时监控:GC健康度速诊
jstat -gcutil <pid> 1000 # 每秒输出GC数据
关键指标解读:
- OU:老年代使用率 > 90% = 危险区
- FGCT:Full GC总耗时 > 应用运行时间10% = 严重问题
2.2. 堆内存转储:揪出内存黑洞
jmap -dump:live,format=b,file=heap.bin <pid> # 生产环境慎用live
2.3 MAT深度分析:解剖内存泄漏

3.优化方案
方案1:对象池化——大对象的救赎
场景:高频创建10MB的文件缓存
// 反例:每次请求创建新对象
public void processRequest(Request req) {
byte[] buffer = newbyte[10 * 1024 * 1024]; // 10MB
// ...处理逻辑
}
// 优化:对象池复用
privatestaticfinal ObjectPool<byte[]> pool = new GenericObjectPool<>(
new BasePooledObjectFactory<byte[]>() {
@Override
publicbyte[] create() {
returnnewbyte[10 * 1024 * 1024];
}
}
);
public void processRequest(Request req) throws Exception {
byte[] buffer = pool.borrowObject();
try {
// ...处理逻辑
} finally {
pool.returnObject(buffer);
}
}
效果:老年代分配速率下降85%
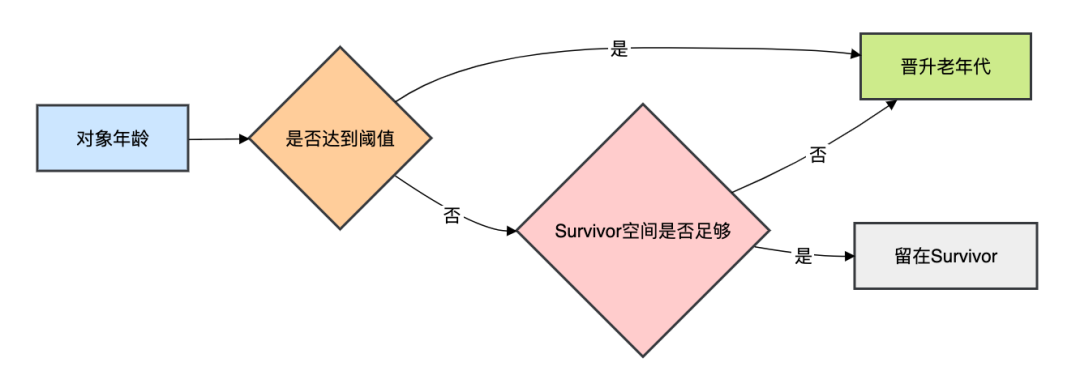
方案2:手动控制晋升
问题:Survivor区过小导致对象提前晋升 优化参数:
-XX:TargetSurvivorRatio=60 # Survivor区使用阈值
-XX:MaxTenuringThreshold=15 # 最大晋升年龄
-XX:+NeverTenure # 若Survivor足够,永不晋升(慎用!)
晋升原理:
方案3:合理分配堆空间
经典误区:
-Xmx4g -Xms4g # 错误!未配置新生代
优化公式:
新生代大小 = 总堆 * 3/8
Eden:Survivor = 8:1:1
正确配置:
-Xmx8g -Xms8g
-Xmn3g # 新生代3G (8*3/8≈3)
-XX:SurvivorRatio=8 # Eden:Survivor=8:1:1
方案4:卸载无用类
场景:热部署频繁的应用(如JRebel) 诊断命令:
jcmd <pid> VM.class_stats # JDK8+
jcmd <pid> GC.class_stats # JDK11+
根治代码:
// 自定义类加载器必须实现close()
public class HotSwapClassLoader extends URLClassLoader {
@Override
public void close() throws IOException {
// 1. 停止新请求
// 2. 卸载所有类
// 3. 关闭资源
}
}
方案5:颠覆传统的ZGC
传统GC痛点:
- CMS:内存碎片问题
- G1:Mixed GC不可控
ZGC迁移步骤:
- 升级JDK至17+
- 添加参数:
-XX:+UseZGC
-XX:ZAllocationSpikeTolerance=5.0 # 容忍内存分配速率波动
-Xmx16g -Xlog:gc*:file=gc.log
效果对比:
指标 | CMS | ZGC |
|---|---|---|
Full GC次数 | 15次/天 | 0次/天 |
最大暂停 | 2.8秒 | 1.2毫秒 |
方案6:堆外内存治理
现象:堆内存正常,但Full GC频繁 根源:DirectByteBuffer的清理依赖Full GC 防御方案:
// 方案1:限制堆外内存
-XX:MaxDirectMemorySize=512m
// 方案2:主动调用Cleaner
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
Cleaner cleaner = ((DirectBuffer) buffer).cleaner();
if (cleaner != null) cleaner.clean();
// 方案3:Netty的内存管理
PooledByteBufAllocator allocator = new PooledByteBufAllocator(true);
ByteBuf buffer = allocator.directBuffer(1024);
// ...使用后必须release!
buffer.release();
4.实战案例
背景:某支付系统日均交易10亿 症状:
- 每分钟5次Full GC,暂停4.2秒
- 99线响应时间从50ms飙升至3秒
排查过程:
jstat显示老年代10秒内从60%→99%- MAT分析发现
ConcurrentHashMap$Node[]占78%内存 - 溯源代码找到缓存黑洞:
// 问题代码:永不失效的缓存
Map<String, Transaction> cache = new ConcurrentHashMap<>();
public void cacheTransaction(Transaction tx) {
cache.put(tx.getId(), tx); // Key冲突时旧对象未移除!
}
解决方案:
- 改用Caffeine缓存:
Cache<String, Transaction> cache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build();
- 添加ZGC参数
- 重写线程池任务队列:
// 用有界队列替代LinkedBlockingQueue
new ThreadPoolExecutor(..., new ArrayBlockingQueue<>(1000));
效果:
- Full GC降为0
- 99线回落至68ms
总结
- 监控三件套:
jstat -gcutil <pid> 1000 # 实时监控
-Xlog:gc*:file=gc.log # GC日志
Prometheus + Grafana # 可视化大盘
- 参数黄金法则:

- 代码军规:
- 大对象必须池化
- 缓存必须设置上限
- 线程池必须用有界队列
- GC算法选择:场景推荐算法堆<8GParallel8G~32GG1关键业务系统ZGC
Full GC不是优化出来的,是设计出来的!
永远在架构设计阶段预留30%内存缓冲空间,比任何调参技巧都重要。
附录:急救工具箱
工具 | 命令 | 适用场景 |
|---|---|---|
jcmd | jcmd <pid> GC.run | 主动触发Full GC |
Arthas | vmtool --action getHeap | 内存快照 |
btrace | 监控DirectByteBuffer分配 | 堆外内存泄漏 |
PerfMa | 在线分析GC日志 | 自动化诊断 |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号