从架构创新到多模态探索,MiniMax如何为国产AI持续赋能?

从架构创新到多模态探索,MiniMax如何为国产AI持续赋能?

数据结构和算法
发布于 2025-03-28 12:52:25
发布于 2025-03-28 12:52:25
2025年刚过,中国AI技术在国际舞台上持续闪耀,国产开源模型的集体爆发成为行业焦点。实际上在DeepSeek的开源模型爆火之前,中国的另一家公司MiniMax的MiniMax-01模型就已经发布和开源。目前MiniMax,与DeepSeek、阿里千问系列共同构成了国产开源模型的中流砥柱,展现出中国在AI开源领域的强大实力。
MiniMax 用实力成为“行业标杆”
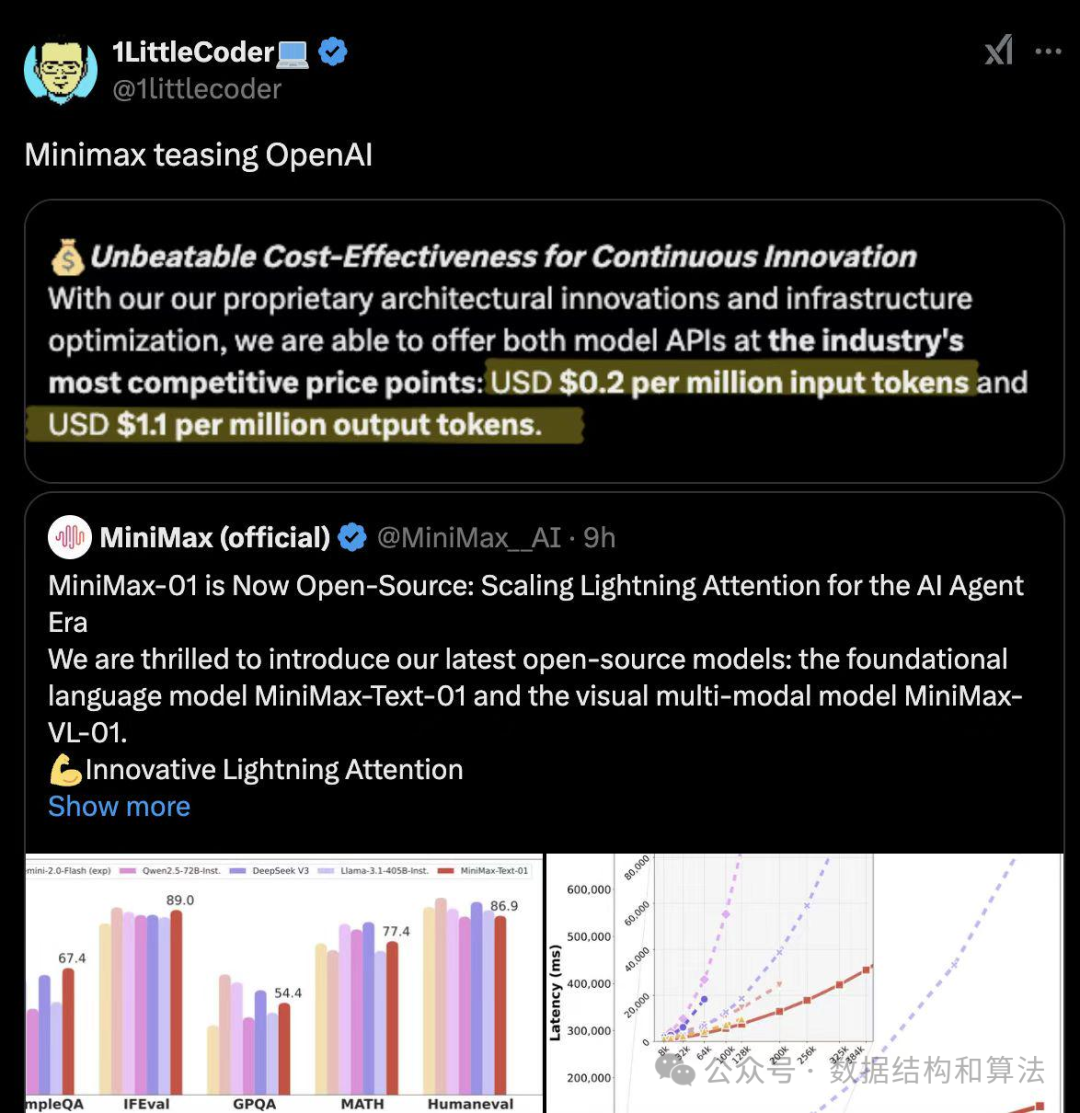
MiniMax-01开源模型作为全球首个突破传统Transformer架构限制的模型,其核心创新在于通过线性注意力机制实现了对4M长文本的高效处理能力,是 GPT-4o 的 32 倍、Claude-3.5-Sonnet 的 20 倍。被海外科技媒体、投资人及研究员认为一个来自中国的可以与OpenAI“掰手腕”的顶尖开源模型。
这一突破源自对AI基础架构痛点的深刻洞察。传统Transformer虽在自然语言处理领域取得巨大成功,但其核心的注意力机制存在二次计算复杂度(O(n²))的根本性缺陷:随着输入序列长度增加,计算量呈平方级增长,这不仅导致算力需求暴增,更成为长文本处理的瓶颈。
在技术路径选择上,研究界曾提出稀疏注意力方案,试图通过选择性忽略部分注意力矩阵来降低计算量。但MiniMax认为这本质上是以有损压缩的方式逼近完整注意力(Full Attention)的效果。
而MiniMax团队创新性地发现,传统注意力机制中隐含的计算冗余恰为算法优化提供了空间——线性注意力将复杂度降至线性级别(O(n)),在完全保留信息交互能力的前提下实现无损优化。
这种架构级突破展现出显著的技术优势:当模型规模扩大时,线性注意力相较传统方案的计算效率优势呈指数级放大,尤其在处理超长文本场景中,其可扩展性为模型赋予了处理海量上下文信息的潜力。
这种长文本处理能力在即将到来的Agent时代具有战略价值。智能体(Agent)需要持续记忆交互历史、处理多轮复杂对话、整合跨文档知识,这对模型的上下文窗口长度提出刚性需求。MiniMax-01的突破,标志着AI基础架构从"算力堆砌"向"算法革新"的关键转折。

同样值得关注的是,MiniMax在多模态领域的持续探索,1 月 10 日发布的视频模型 S2V-01,把传统的输入和计算成本降低到1% 。只需输入一张图片, 即可实现视觉细节的精确还原;2月24日上线了图生视频模型I2V-01-Director,与此前的文生视频T2V-01-Director共同组成01-Director系列,使普通人如专业导演一样,自如控制镜头语言,实现精细的创作控制。
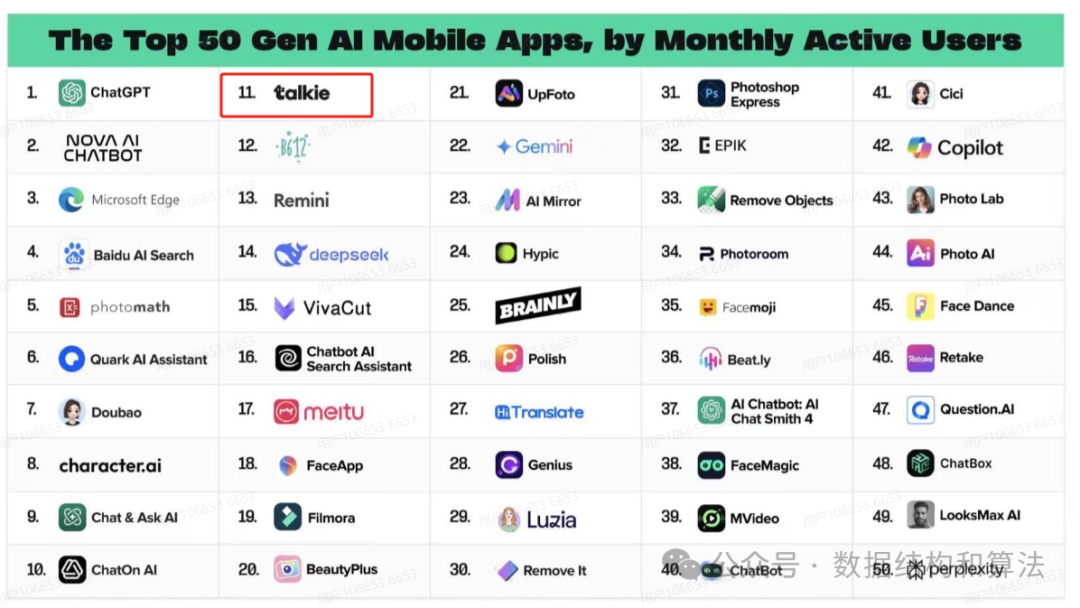
MiniMax将这些技术运用到了HailuoAI以及Talkie上,极大地提升了用户体验。目前这两款出海产品均在榜全球权威风投机构公布的a16z全球AI应用TOP50的web排行榜和app排行榜前列,其中海螺AI力压可灵、Sora稳居全球视频AI赛道top1。
原文链接:https://a16z.com/100-gen-ai-apps-4/

MiniMax的创新坚守与企业精神
正如MiniMax-01的架构创新以及不同领域的多模态布局,MiniMax以技术为驱动,以技术创新为核心不断探索和突破AI技术的边界。MiniMax CEO闫俊杰在采访中表达的“好模型的本质是技术驱动,而模型是产品出现的驱动力”。DeepSeek的爆火以及海螺AI成为全球用户访问量第一的视频网站,都充分证明了“技术驱动”可以带来更多的用户和市场认可。
闫俊杰还说“我们认为真正有价值的事,不是当前做得怎么样,而是技术进化速度。而开源会加速技术进化,做得好的地方有鼓励,不好的地方会有很多批评,外面的人也会有贡献,这是我们开源的最大驱动力。”这一观点体现了其对开源价值的深刻认识,不仅促进了自身技术的发展,更为整个AI行业带来了更多的创新和可能性。
据了解MiniMax 即将在 4 - 5 月份发布基于 Linear Attention 架构的深度推理多模态模型,将融合Text&VL两个模态,平衡文本能力和视觉理解能力,为AI技术的应用开辟更广阔的前景。我们有理由相信,它将继续引领行业的发展潮流,为 全球AI 技术的未来带来更多的可能性,见证中国AI的持续辉煌。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-03-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号