向量检索(RAG)之向量数据库研究
原创

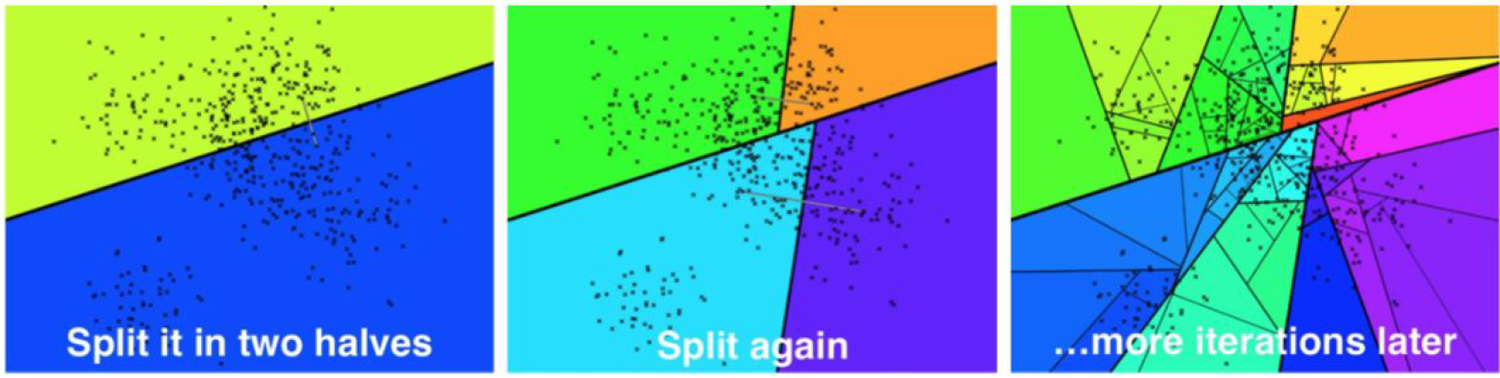
研究内容主要包括:是否开源,支持的功能有哪些(是否支持暴力检索,支持哪些索引),是否有可视化界面,是否支持标量过滤。
结果汇总
向量数据库名称 | 是否开源(Github Star,数据统计于 2025年3月) | 是否有 云版本 | 支持暴力检索 | 支持的索引 | 可视化界面 | 标量过滤 | 特点 |
|---|---|---|---|---|---|---|---|
Annoy | 是(13.5k) | 无 | 否 | Annoy | 无 | 不支持 | 适用于低维度(比如<100),效果会更好。内存使用量小。让你在多个进程之间共享内存。它有能力使用静态文件作为索引。索引的创建与查找是分开的。在磁盘上建立索引,以实现对不适合内存的大数据集的索引(由 Rene Hollander 贡献)。缺点:索引创建后不可添加更多项目,也就是不能实现增量功能。 |
Atlas | 否 | 有 | 没公开 | 没公开 | 有 | 不支持 | 存储、更新和组织数百万点的非结构化文本、图像和向量的数据集。通过 Web 浏览器与您的数据集进行可视化交互。对您的数据集运行语义搜索和向量操作。协同清理、标记和标注您的数据集。可视化 Weaviate 和 Pinecone 向量数据库。 |
Chroma | 是(18.3k) | 无,即将推出 | 否 | hnswlib | 无,即将推出带有可视化界面的托管版本 | 支持 | Chroma 是一个开源的向量数据库,公司名也是 Chroma,通过使知识、事实和技能等可插拔地运用与大型语言模型,使建立大型语言模型应用变得容易。功能:将文档生成向量,存储向量及其元数据,检索向量。即将推出:多种数据类型,包括图像、音频、视频等。 |
DeepLake | 是(8.4k) | 有 | 是 | 当前没有使用索引,未来几周将实现基于HNSW的索引 | 有 | 支持 | Deep Lake 可以作为机器学习的数据集,也可以作为向量数据库。Deep Lake 作为一个无服务器矢量存储,部署在用户自己的云、本地或内存中。所有计算都在客户端运行,这使用户能够在几秒钟内支持轻量级生产应用程序。Deep Lake 的数据格式除了可以存储嵌入之外,还可以存储图像、视频和文本等原始数据。 |
OpenSearch | 是(10.3k) | 官方没有,外部云平台有商业化版本,如 AWS | 是 | 1)nmslib 库的 hnsw 实现。 2)faiss 库的 hnsw 或 ivf 实现,加上 pq 编码。 3)lucene 库的 hnsw 实现。 | 有,OpenSearch管理端 | 支持 | OpenSearch 是一个可扩展、灵活且可扩展的开源软件套件,用于在 Apache 2.0 许可下的搜索、分析和可观察性应用程序。OpenSearch 由 Apache Lucene 提供支持并由 OpenSearch 项目社区推动,提供了一个与供应商无关的工具集,您可以使用它来构建安全、高性能、经济高效的应用程序。使用 OpenSearch 作为端到端解决方案,或将其与您首选的开源工具或合作伙伴项目连接起来。 |
PGVector | 是(14.4k) | 官方没有,外部云平台有商业化版本 | 是 | ivfflat | 有,PostgreSQL管理端 | 支持 | PGVector 是 PostgreSQL(一款开源关系型数据库管理系统,也称为 Postgres)的一个扩展,PGVector 用于向量相似度检索。 |
Pinecone | 否 | 有 | 没公开 | 没公开 | 有 | 支持 | 快速:获得任何规模的超低查询延迟,即使是数十亿个项目。实时:当您添加、编辑或删除数据时获取实时索引更新。过滤:将矢量搜索与元数据过滤器相结合,以获得更相关、更快的结果。全面托管:轻松开始、使用和扩展,同时我们确保一切顺利、安全地运行。 |
Qdrant | 是(22.2k) | 有 | 是 | hnsw | 有 | 支持 | 丰富的数据类型。SIMD硬件加速:Qdrant 利用现代 CPU x86-x64 架构,在现代硬件上提供更快的搜索性能。Write-Ahead Logging 预写式记录。分布式部署,独立运行,不依赖外部数据库或编排控制器,简化了配置。 |
Weaviate | 是(12.6k) | 有 | 否 | hnsw 索引 + pq 编码 | 有 | 支持 | Weaviate是一个低延迟的矢量数据库,开箱即用,支持不同的媒体类型(文本、图像等)。它提供语义搜索、问题-答案提取、分类、可定制模型(PyTorch/TensorFlow/Keras)等。Weaviate用Go语言从头开始构建,同时存储对象和向量,允许将向量搜索与结构化过滤和云原生数据库的容错性相结合。这一切都可以通过GraphQL、REST和各种客户端编程语言进行访问。 |
Zilliz | 否,Milvus (32.9k) | 有 | 否 | AUTOINDEX(商业化版专有算法) | 有 | 支持 | 比 Milvus 更强大的功能,具体可见下文比较 |
ANN-Benchmark官网:http://ann-benchmarks.com/
向量数据库产品介绍
本次分享的公司外部产品(10款):Annoy、Atlas、Chroma、Deep Lake、OpenSearch、PGVector、Pinecone、Qdrant、Weaviate、Zilliz。
研究内容主要包括:是否开源,支持的功能有哪些(是否支持暴力检索,支持哪些索引,是否支持标量过滤等),可视化界面。
Annoy
基本信息
Annoy(Approximate Nearest Neighbors Oh Yeah)是一个带有 Python bindings 的C++库,用于搜索空间中接近给定查询点的点。它还创建了大型的基于文件的只读数据结构,并将其映射到内存中,以便许多进程可以共享相同的数据。
Github & 官网地址:https://github.com/spotify/annoy,star 数:11.5k
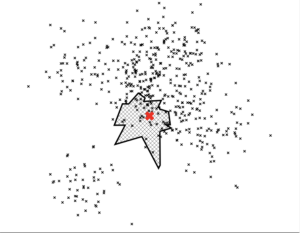
特点概述:
- 相似度计算方式:欧氏距离,曼哈顿距离,余弦距离,汉明距离,或点(内)积距离;
- 如果你没有太多的维度(比如<100),效果会更好。
- 内存使用量小。
- 让你在多个进程之间共享内存。它有能力使用静态文件作为索引。特别是,这意味着你只需要建立一次索引,便可以跨进程共享索引。
- 索引的创建与查找是分开的(特别是一旦树被创建,你就不能再添加更多的项目),因此你可以将索引作为文件传递,并将其快速映射(mmap)到内存。
- 在磁盘上建立索引,以实现对不适合内存的大数据集的索引(由 Rene Hollander 贡献)。
调整Annoy只需要两个主要参数:树的数量n_trees和搜索时要检查的节点数量search_k。
- n_trees 是在构建时提供的,它影响构建时间和索引大小。一个更大的值会得到更准确的结果,但索引也更大。
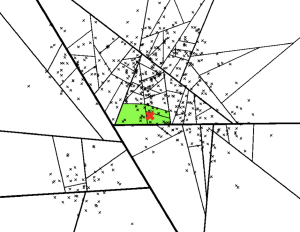
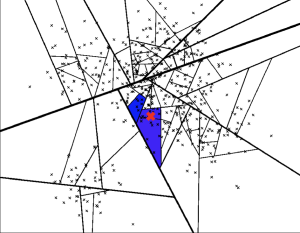
- search_k 是在运行时提供的,影响搜索性能。一个更大的值会给出更准确的结果,但需要更长的时间来返回。
暴力检索:不支持
索引:Annoy
标量过滤:不支持
可视化界面
没有可视化界面
使用介绍
安装:
- 要安装,只需做 pip install --user annoy,从 PyPI 拉下最新版本。
- 对于 C++ 版本,只需克隆 repo 并 #include "annoylib.h"。
python 示例代码:
from annoy import AnnoyIndex
import random
f = 40 # Length of item vector that will be indexed
# 构建过程
t = AnnoyIndex(f, 'angular') # 支持5种距离计算方式:"angular", "euclidean", "manhattan", "hamming", or "dot"
for i in range(1000):
v = [random.gauss(0, 1) for z in range(f)]
t.add_item(i, v) # 添加随机向量信息
t.build(10) # 10 trees, 构建由n_trees树组成的森林。更多的树在查询时有更高的精度。调用build后,不能再添加任何项目。n_jobs指定用于构建树的线程数。n_jobs=-1使用所有可用的CPU核。
t.save('test.ann') # 将索引保存到磁盘
# 加载
u = AnnoyIndex(f, 'angular')
u.load('test.ann') # super fast, will just mmap the file 从磁盘加载(mmaps)一个索引
print(u.get_nns_by_item(0, 1000)) # 用于根据 item id=0 查找最相似的 k=1000 个 itemAtlas
基本信息
Atlas 是 Nomic 公司的一个产品,是一个配备了世界上最具可扩展性的向量空间浏览器的数据引擎。它使任何人都可以在浏览器中可视化、组织、管理、搜索和共享大量数据集。使用 Atlas,我们可以开始了解人工智能模型正在学习哪些数据。目前支持文本、视频,其他媒体(视频、音频、图片)需要联系工作人员。
官方文档:https://docs.nomic.ai/index.html
可视化界面:https://atlas.nomic.ai/dashboard
Python Client Github:https://github.com/nomic-ai/nomic

功能:
- 存储、更新和组织数百万点的非结构化文本、图像和向量的数据集。
- 通过 Web 浏览器与您的数据集进行可视化交互。
- 对您的数据集运行语义搜索和向量操作。
- 协同清理、标记和标注您的数据集。
- 可视化 Weaviate 和 Pinecone 向量数据库。
暴力检索:没有公开
索引:没有公开
标量过滤:不支持
可视化界面
可视化界面:https://atlas.nomic.ai/dashboard
这里已经按照官方demo创建了一个项目,也可以点击图形进去查看详情
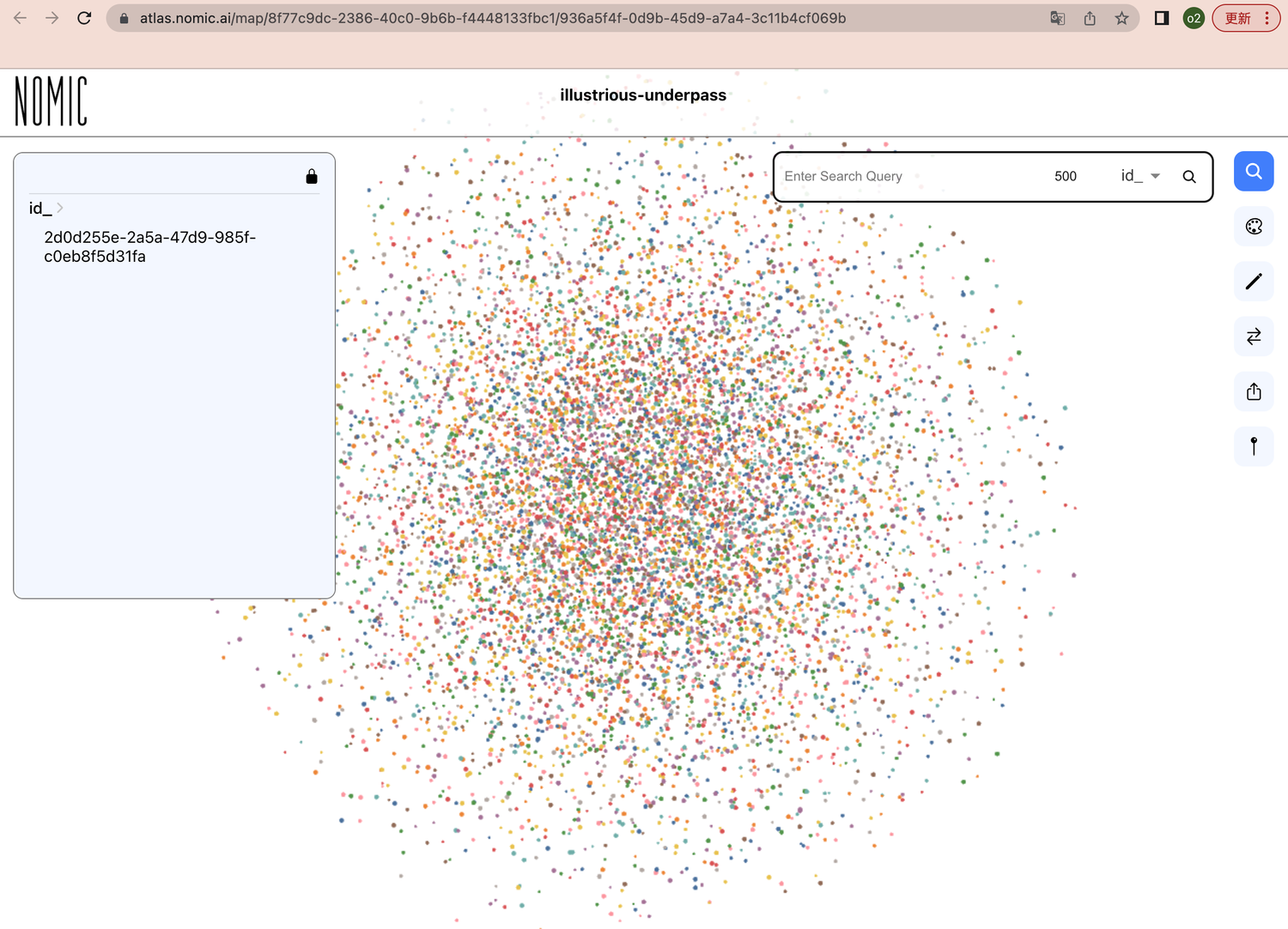
官方 https://docs.nomic.ai/collection_of_maps.html 也有提供一些公共map,(不用登录就可以查看)
https://atlas.nomic.ai/map/twitter
https://atlas.nomic.ai/map/stablediffusion
https://atlas.nomic.ai/map/neurips
https://atlas.nomic.ai/map/iclr
https://atlas.nomic.ai/map/2a222eb6-8f5a-405b-9ab8-f5ab23b71cfd/1dae224b-0284-49f7-b7c9-5f80d9ef8b32
使用介绍
这里介绍:1)通过向量构建索引和查询、2)通过文本构建索引:
from nomic import atlas
import numpy as np
# 1、构建向量索引
num_embeddings = 10000
embeddings = np.random.rand(num_embeddings, 256)
project = atlas.map_embeddings(embeddings=embeddings)
# 检索向量
neighbors, distances = map.vector_search(ids=['42'])
print(project.get_data(ids=neighbors[0]))
# 2、构建文本索引,由 atlas 内部模型生成向量,也可以使用自己的模型(例如:HuggingFace model、Cohere model)
dataset = load_dataset('ag_news')['train'] # https://huggingface.co/datasets/ag_news
max_documents = 10000
subset_idxs = np.random.randint(len(dataset), size=max_documents).tolist()
documents = [dataset[i] for i in subset_idxs]
project = atlas.map_text(data=documents,
indexed_field='text',
name='News 10k Example',
colorable_fields=['label'],
description='News 10k Example.'
)Chroma
基本信息
Chroma 是一个开源的向量数据库,公司名也是 Chroma,通过使知识、事实和技能等可插拔地运用与大型语言模型,使建立大型语言模型应用变得容易。功能:将文档生成向量,存储向量及其元数据,检索向量。即将推出:多种数据类型,包括图像、音频、视频等。
官网地址:https://www.trychroma.com/
官方文档:https://docs.trychroma.com/
Github地址:https://github.com/chroma-core/chroma,star 数:6.7k,开源时间:2022年10月
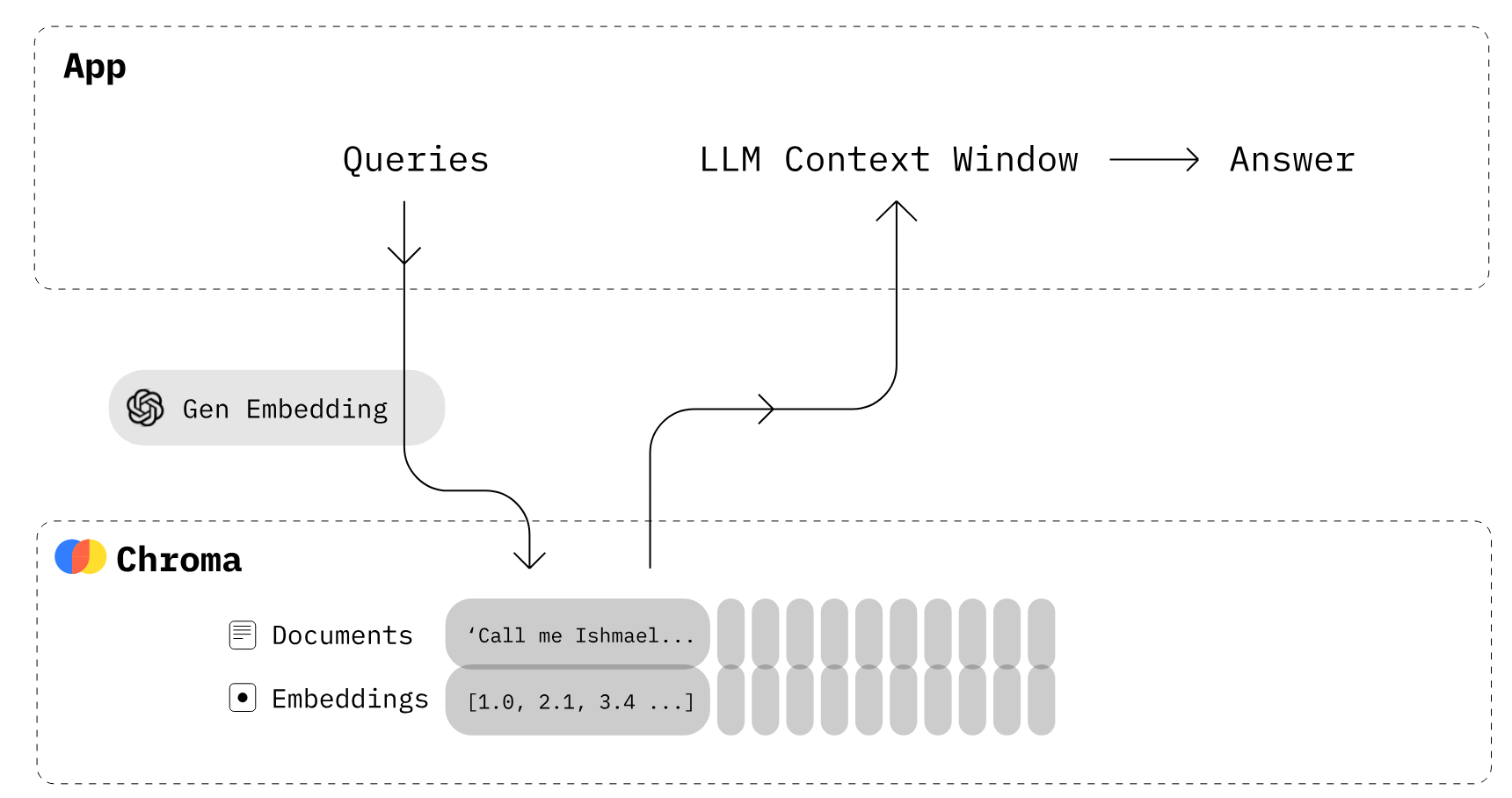
支持向量相似度计算方式:"l2", "ip, "or "cosine"。
运行模式:
- in-memory 模式,可以设置数据持久化路径。
- client/server 模式,Chroma 还可以配置为使用磁盘数据库,这对于内存无法容纳的较大数据很有用,该模式目前还不是很成熟:
- 服务端可以运行在自己的机器或云平台,官方提供将 Chroma 部署到 AWS EC2 的文档,https://docs.trychroma.com/deployment;
- 托管版本 hosted version 即将推出,带有操作界面(可以不用自己部署维护);
支持的编程语言:
in-memory | client & server | |
|---|---|---|
Python | ✅ | ✅ |
Javascript | ➖ | ✅ |
Chroma为流行的嵌入供应商提供了轻量级的包装,使得在你的应用程序中使用它们很容易。你可以在创建Chroma集合时设置一个嵌入函数,它将被自动使用,或者你可以自己直接调用它们。
- 默认使用:Sentence Transformers all-MiniLM-L6-v2模型,该嵌入模型可以创建可用于各种任务的句子和文档嵌入。此嵌入功能在您的计算机上本地运行,并且可能需要您下载模型文件(这将自动发生)。也可以使用其他模型(模型集合),只要在代码中指定模型名。
sentence_transformer_ef = embedding_functions.SentenceTransformerEmbeddingFunction(model_name="all-MiniLM-L6-v2")- Chroma 为 OpenAI 的嵌入 API 提供了一个方便的包装器。该嵌入功能在 OpenAI 的服务器上远程运行,并且需要 API 密钥。您可以通过在 OpenAI 注册帐户来获取 API 密钥。
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key="YOUR_API_KEY",
model_name="text-embedding-ada-002"
)- Chroma 还为 Cohere 的嵌入 API 提供了一个方便的包装器。该嵌入功能在 Cohere 的服务器上远程运行,并且需要 API 密钥。您可以通过在 Cohere 注册帐户来获取 API 密钥。
cohere_ef = embedding_functions.CohereEmbeddingFunction(api_key="YOUR_API_KEY", model_name="large")
cohere_ef(texts=["document1","document2"])- Instructor models,适用于cuda-capable GPU,有三种型号可供选择。默认值为 hkunlp/instructor-base ,为了获得更好的性能,您可以使用 hkunlp/instructor-large 或 hkunlp/instructor-xl 。
ef = embedding_functions.InstructorEmbeddingFunction(model_name="hkunlp/instructor-xl", device="cuda")- Google PaLM API models
palm_embedding = embedding_functions.GooglePalmEmbeddingFunction(
api_key=api_key, model=model_name)- 自定义嵌入函数:您可以创建自己的嵌入函数来与 Chroma 一起使用,它只需要实现 EmbeddingFunction 协议。
from chromadb.api.types import Documents, EmbeddingFunction, Embeddings
class MyEmbeddingFunction(EmbeddingFunction):
def __call__(self, texts: Documents) -> Embeddings:
# embed the documents somehow
return embeddings暴力检索:不支持
索引:hnswlib
标量过滤:支持
可视化界面
没有,即将推出的托管版本(商业化版本)带有可视化界面。
使用介绍
这里介绍在 Python 环境下,以 in-memory 模式运行 chroma。
# pip install chromadb
import chromadb
# step 1 Get the Chroma Client
chroma_client = chromadb.Client()
# step 2 Create a collection, store your embeddings, documents, and any additional metadata
collection = chroma_client.create_collection(name="my_collection")
# step 3 Add some text documents to the collection
# 第一种:采用默认方式生成 embeddings
collection.add(
documents=["This is a document", "This is another document"],
metadatas=[{"source": "my_source"}, {"source": "my_source"}],
ids=["id1", "id2"]
)
# 第二种:自己生成 embeddings
collection.add(
embeddings=[[1.2, 2.3, 4.5], [6.7, 8.2, 9.2]],
documents=["This is a document", "This is another document"],
metadatas=[{"source": "my_source"}, {"source": "my_source"}],
ids=["id1", "id2"]
)
# step 4 Query the collection
results = collection.query(
query_texts=["This is a query document"],
n_results=2
)
results = collection.query(
query_embeddings=[[11.1, 12.1, 13.1],[1.1, 2.3, 3.2] ...]
n_results=10,
where={"metadata_field": "is_equal_to_this"}, # 条件过滤
where_document={"$contains":"search_string"} # 搜索文本
)
# 同时,可以进行 update 和 delete 操作Deep Lake
基本信息
Deep Lake 是 Activeloop 公司的产品,Activeloop 公司的目标是让深度学习团队无需构建复杂的数据基础设施,从而可以更快地开发人工智能产品。Deep Lake 可以作为机器学习的数据集,也可以作为向量数据库。Deep Lake 作为一个无服务器矢量存储,部署在用户自己的云、本地或内存中。所有计算都在客户端运行,这使用户能够在几秒钟内支持轻量级生产应用程序。Deep Lake 的数据格式除了可以存储嵌入之外,还可以存储图像、视频和文本等原始数据。
Activeloop 是带有界面的平台,而 Deep Lake 是一个 python 库,被用作 Activeloop 的 SDK。
Deep Lake 官网地址:https://www.deeplake.ai/,Deep Lake 官方文档:https://docs.activeloop.ai/,Github 地址:https://github.com/activeloopai/deeplake,star 数:6.3k
Activeloop 官网地址:https://www.activeloop.ai/,不开源。
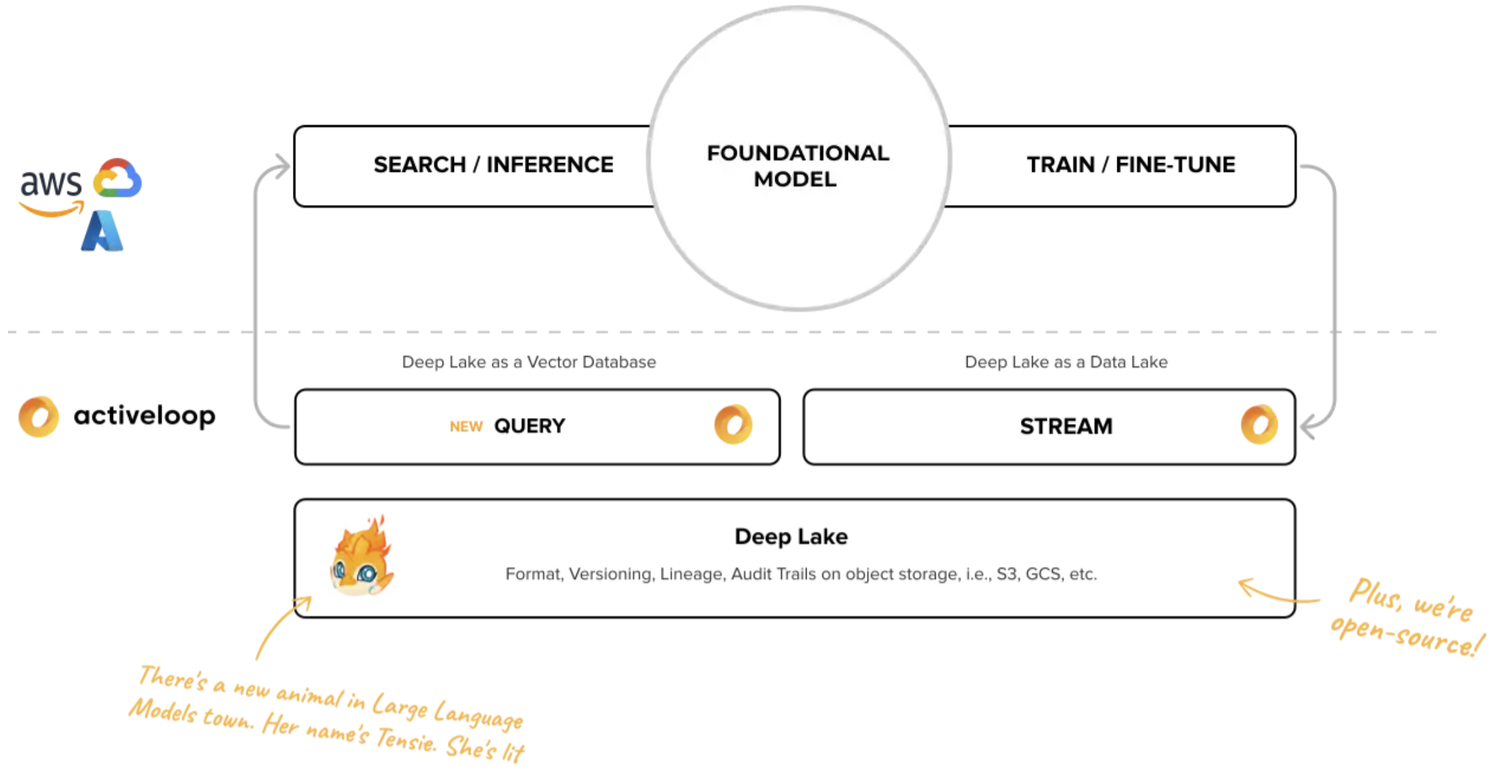
Deep Lake 作为向量数据库:
- 存储嵌入物及其元数据,包括文本、jsons、图像、音频、视频等。将数据保存在本地、云端或 DeepLake 存储中。(使用 DeepLake 存储可以使用 Tensor Query Language 进行查询)
- 执行混合搜索,包括嵌入和它们的属性。
- 使用或整合LangChain和LlamaIndex构建LLM应用程序
- 在客户端、我们的管理向量数据库或你的VPC中的无服务器部署上运行计算。
Deep Lake 作为深度学习的数据湖:
- 以针对深度学习优化的数据格式存储图像、音频、视频、文本及其元数据(即注释)。将数据保存在本地、云中或 Activeloop 存储中。
- 无需样板代码即可在流式传输数据的同时快速训练 PyTorch 和 TensorFlow 模型。
- 使用简单的 Python API 运行版本控制、数据集查询和分布式工作负载。
与其他向量数据库比较:
1)Deep Lake vs Chroma
Deep Lake 和 ChromaDB 都使用户能够存储和搜索向量(嵌入)并提供与 LangChain 和 LlamaIndex 的集成。但是,它们在架构上非常不同。 ChromaDB 是一个矢量数据库,可以部署在本地或使用 Docker 的服务器上,并将很快提供托管解决方案。 Deep Lake 是一个无服务器矢量存储,部署在用户自己的云、本地或内存中。所有计算都在客户端运行,这使用户能够在几秒钟内支持轻量级生产应用程序。与 ChromaDB 不同,Deep Lake 的数据格式除了可以存储嵌入之外,还可以存储图像、视频和文本等原始数据。 ChromaDB 仅限于嵌入之上的轻型元数据,并且没有可视化。 Deep Lake 数据集可以可视化和版本控制。 Deep Lake 还有一个高性能的数据加载器,用于微调您的大型语言模型。
2)Deep Lake vs Pinecone
Deep Lake 和 Pinecone 都使用户能够存储和搜索向量(嵌入),并提供与 LangChain 和 LlamaIndex 的集成。但是,它们在架构上非常不同。 Pinecone 是一个完全托管的矢量数据库,针对需要搜索数十亿个矢量的高要求应用程序进行了优化。 Deep Lake 是无服务器的。所有计算都在客户端运行,这使用户可以在几秒钟内开始。与 Pinecone 不同,Deep Lake 的数据格式除了可以存储嵌入之外,还可以存储图像、视频和文本等原始数据。 Deep Lake 数据集可以可视化和版本控制。 Pinecone 仅限于嵌入之上的光元数据,没有可视化。 Deep Lake 还有一个高性能的数据加载器,用于微调您的大型语言模型。
3)Deep Lake vs Weaviate
Deep Lake 和 Weaviate 都使用户能够存储和搜索向量(嵌入),并提供与 LangChain 和 LlamaIndex 的集成。但是,它们在架构上非常不同。 Weaviate 是一个矢量数据库,可以部署在托管服务中,也可以由用户通过 Kubernetes 或 Docker 部署。 Deep Lake 是无服务器的。所有计算都在客户端运行,这使用户能够在几秒钟内支持轻量级生产应用程序。与 Weaviate 不同,Deep Lake 的数据格式除了可以存储嵌入之外,还可以存储图像、视频和文本等原始数据。 Deep Lake 数据集可以可视化和版本控制。 Weaviate 仅限于嵌入之上的轻型元数据,并且没有可视化。 Deep Lake 还有一个高性能的数据加载器,用于微调您的大型语言模型。
其他方面:
暴力检索:支持
索引:官方回复当前没有使用索引,是一种精确近邻搜索方法(exact nearest neighbor),未来几周会推出基于 HNSW 索引的近似近邻搜索方法(approximate nearest neighbor(ANN))。
标量过滤:支持
可视化界面
收费级别(可以试用 Community 级别)
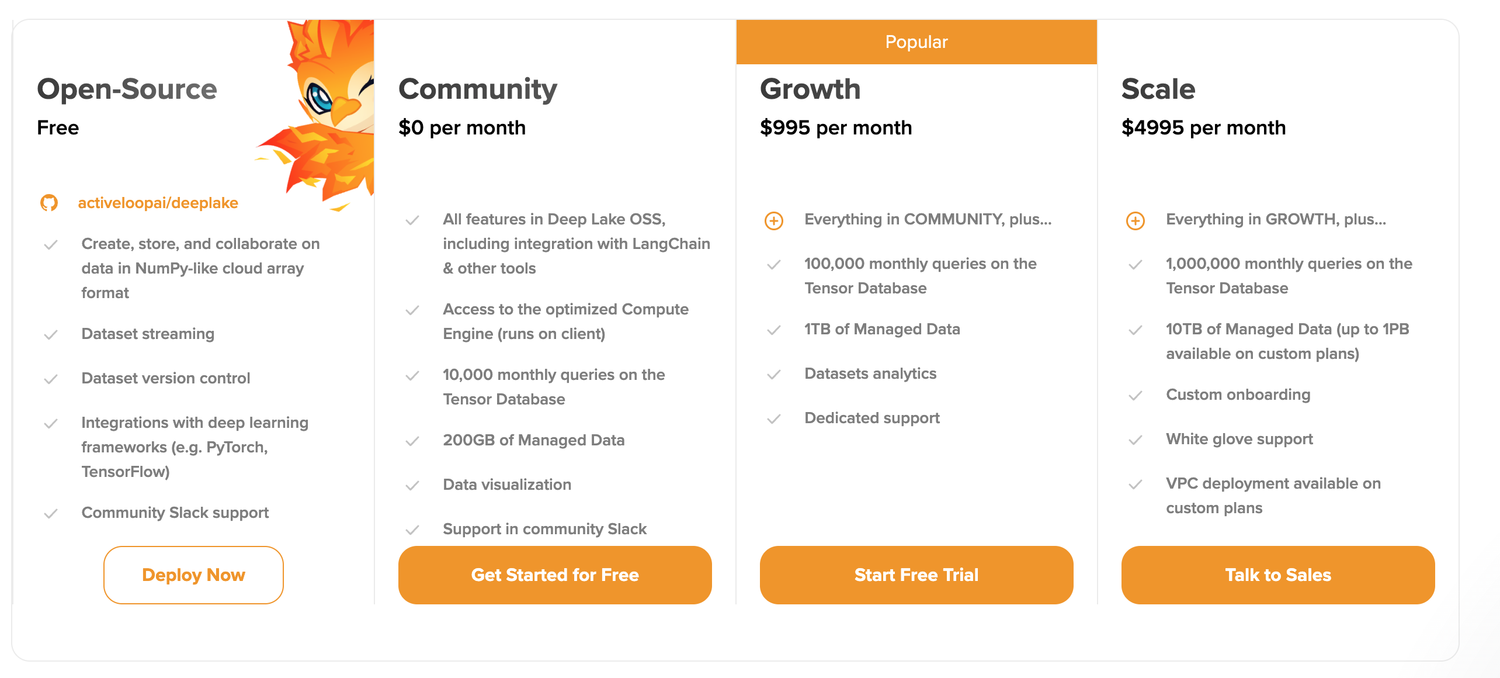
DeepLake 页面地址:https://app.activeloop.ai/
包含向量的数据集:https://app.activeloop.ai/activeloop/twitter-algorithm
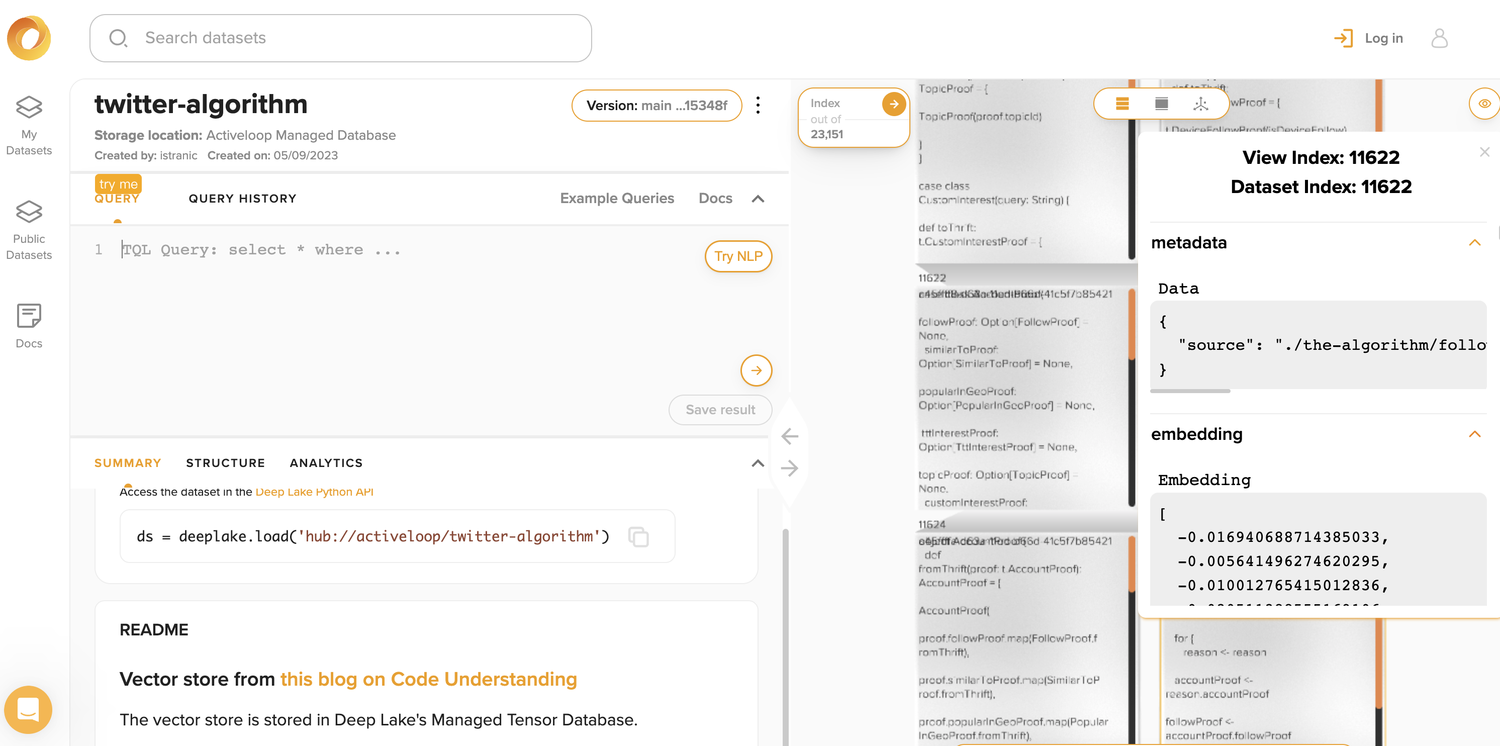
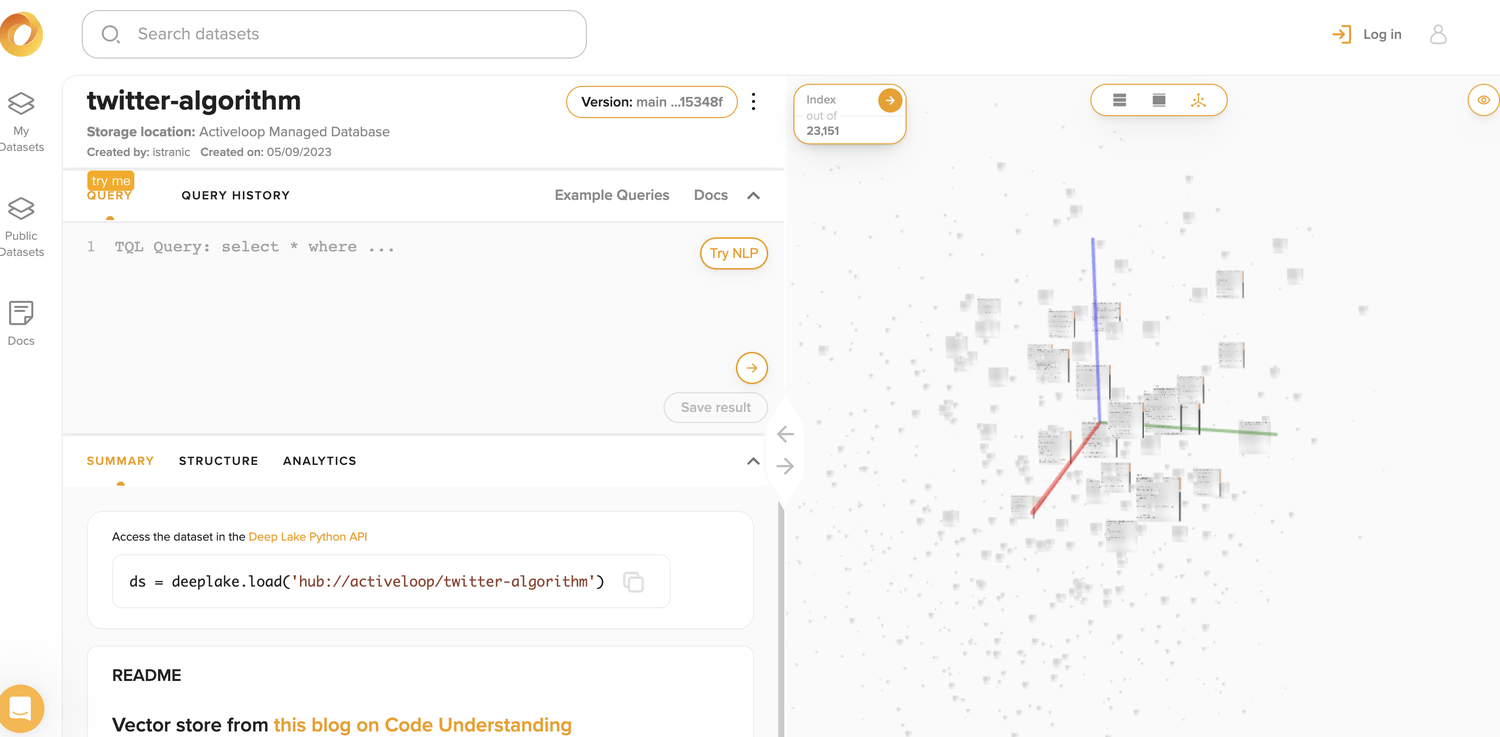
使用介绍
这里介绍 Deep Lake 作为向量数据库的使用
vector_store_path = 'vector_store'
CHUNK_SIZE = 1000
# text
chunked_text = []
for i in range(0, CHUNK_SIZE):
chunked_text.append("text" + str(i + 1))
# embedding
embedding = []
for i in range(0, CHUNK_SIZE):
embedding.append([random.random(), random.random(), random.random()])
# meta
meta = []
for i in range(0, CHUNK_SIZE):
d = {'key': i + 1}
meta.append(d)
vector_store = DeepLakeVectorStore(
path=vector_store_path,
)
vector_store.add(text=chunked_text,
embedding=embedding,
metadata=meta)
# vector_store.summary()
# prompt = "What are the first programs he tried writing?"
search_results = vector_store.search(embedding=[0.1, 0.2, 0.3])
# 也可以使用 openai 的模型
def embedding_function(texts, model="text-embedding-ada-002"):
if isinstance(texts, str):
texts = [texts]
texts = [t.replace("\n", " ") for t in texts]
return [data['embedding']for data in openai.Embedding.create(input = texts, model=model)['data']]OpenSearch
基本信息
OpenSearch 是一个可扩展、灵活且可扩展的开源软件套件,用于在 Apache 2.0 许可下的搜索、分析和可观察性应用程序。OpenSearch 由 Apache Lucene 提供支持并由 OpenSearch 项目社区推动,提供了一个与供应商无关的工具集,您可以使用它来构建安全、高性能、经济高效的应用程序。使用 OpenSearch 作为端到端解决方案,或将其与您首选的开源工具或合作伙伴项目连接起来。
其附加功能和插件如下:
- 异常检测 - 识别非典型数据并接收自动通知
- KNN - 在你的矢量数据中找到“最近的邻居”
- 性能分析器 - 监控和优化您的集群
- SQL - 使用 SQL 或管道处理语言查询数据
- 索引状态管理 - 自动化索引操作
- ML Commons 插件 - 训练和执行机器学习模型
- 异步搜索 - 在后台运行搜索请求
- 跨集群复制 - 跨多个 OpenSearch 集群复制数据
OpenSearch 官网:https://opensearch.org/
knn 相关文档:https://opensearch.org/docs/latest/search-plugins/knn/index/
Github:https://github.com/opensearch-project/OpenSearch,star 数:7.2k
OpenSearch 与 ElasticSearch 的关系:
OpenSearch 项目由 OpenSearch (fork Elasticsearch 7.10.2) 和 OpenSearch Dashboards (fork Kibana 7.10.2) 组成,包括企业安全、告警、机器学习、SQL、索引状态管理等功能。OpenSearch 项目中的所有软件均采用了 Apache License 2.0 开源许可协议。OpenSearch 删除了 Elasticsearch 中受 Elastic 商业许可证限制的功能、代码和商标,以兼容 Apache License 2.0,自称这是每个人都可以构建和创新的基础,任何人无需签署 CLA (Contributor License Agreement) 即可为项目贡献代码。
支持三种不同的方法来从向量索引中获取 k 个最近邻居:
- Approximate k-NN:低延迟的大型索引(即数十万个向量或更多)搜索的最佳选择 近似最近邻搜索,索引:1)nmslib 库的 hnsw 实现。2)faiss 库的 hnsw 或 ivf 实现,加上 pq 编码方式。3)lucene 库的 hnsw 实现(支持标量过滤)。
- Script Score k-NN:执行强力、精确的 k-NN 搜索。通过这种方法,您可以对索引中的向量子集运行 k-NN 搜索(有时称为预过滤搜索),对大型索引使用此方法可能会导致高延迟。 暴力检索,支持标量过滤
- Painless extensions:功能与 Script Score k-NN 类似,可以在更复杂的组合中使用它,但性能比 Script Score k-NN 差。 暴力检索,,支持标量过滤
可视化界面
Opensearch 页面地址:http://9.135.155.110:5603/app/home#/
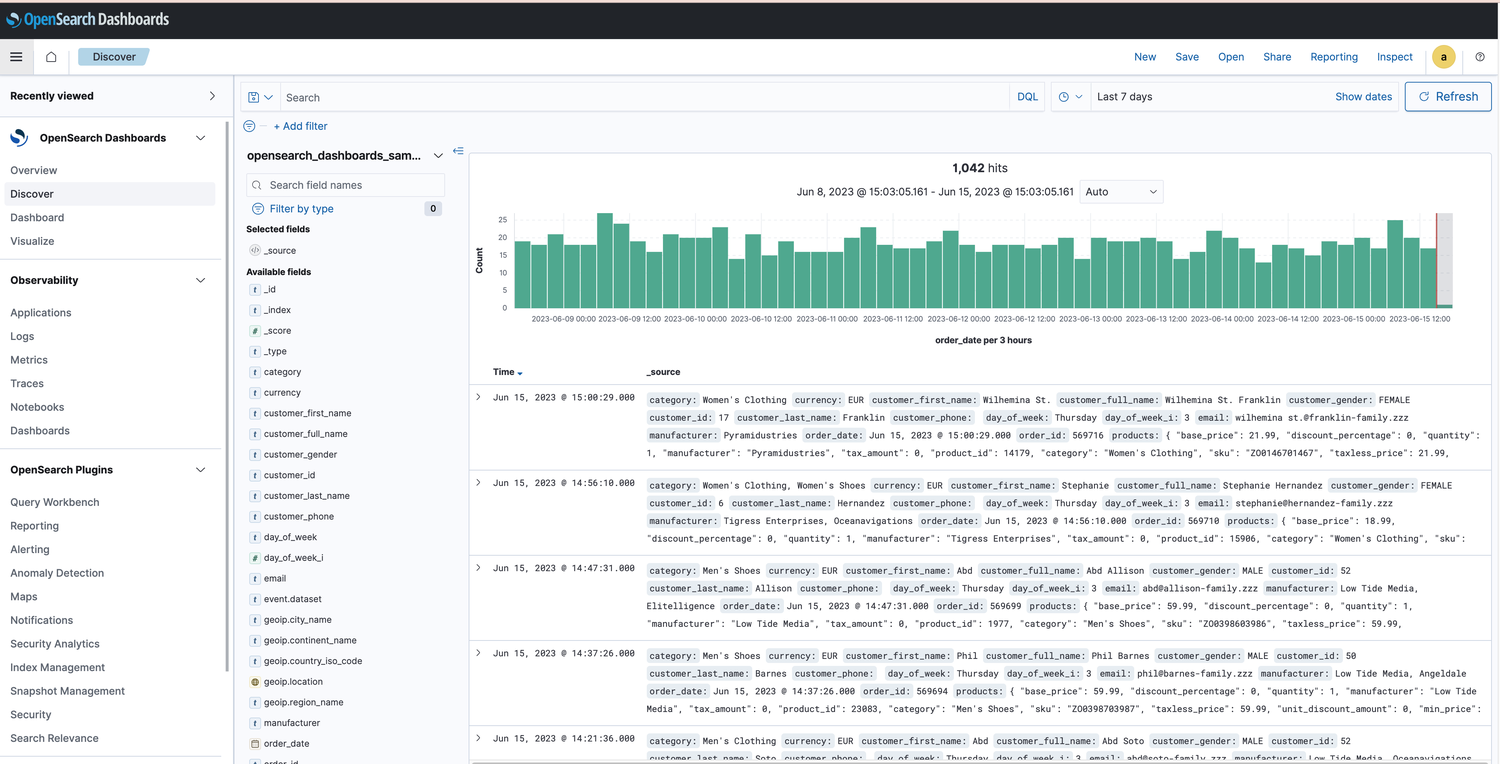
这个链接有 Opensearch 管理端页面的操作使用说明:https://opensearch.org/docs/latest/dashboards/index/
使用介绍
这里介绍带标量过滤的近似最近邻搜索(Approximate k-NN)
构建 index:
PUT /hotels-index
{
"settings": {
"index": {
"knn": true,
"knn.algo_param.ef_search": 100,
"number_of_shards": 1,
"number_of_replicas": 0
}
},
"mappings": {
"properties": {
"location": {
"type": "knn_vector",
"dimension": 2,
"method": {
"name": "hnsw",
"space_type": "l2",
"engine": "lucene", # 这里指定 lucene
"parameters": {
"ef_construction": 100,
"m": 16
}
}
}
}
}
}添加数据:
POST /_bulk
{ "index": { "_index": "hotels-index", "_id": "1" } }
{ "location": [5.2, 4.4], "parking" : "true", "rating" : 5 }
{ "index": { "_index": "hotels-index", "_id": "2" } }
{ "location": [5.2, 3.9], "parking" : "false", "rating" : 4 }
{ "index": { "_index": "hotels-index", "_id": "3" } }
{ "location": [4.9, 3.4], "parking" : "true", "rating" : 9 }检索:
POST /hotels-index/_search
{
"size": 3,
"query": {
"knn": {
"location": {
"vector": [
5,
4
],
"k": 3,
"filter": {
"bool": {
"must": [
{
"range": {
"rating": {
"gte": 8,
"lte": 10
}
}
},
{
"term": {
"parking": "true"
}
}
]
}
}
}
}
}
}PGVector
基本信息
PGVector 是 PostgreSQL(一款开源关系型数据库管理系统,也称为 Postgres)的一个扩展,PGVector 用于向量相似度检索,开源。
PostgreSQL 支持多种图形化界面,其中较为流行的是 pgAdmin。PostgreSQL 官网:https://www.postgresql.org/
PGVector Github & 官网地址:https://github.com/pgvector/pgvector,star 数:4.3k
支持:L2 distance, inner product, and cosine distance
暴力检索:支持
索引:ivfflat
标量过滤:支持
可视化界面
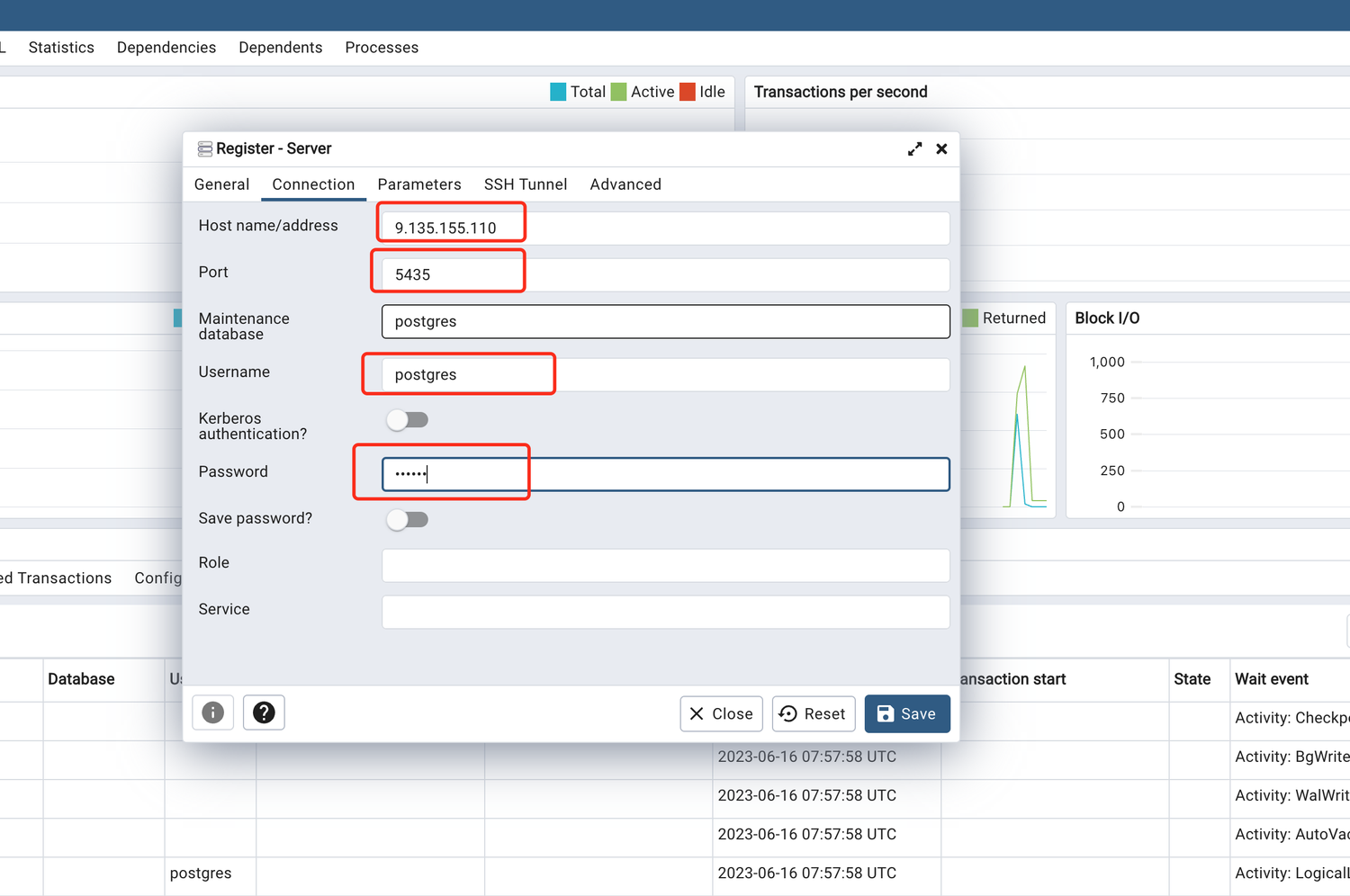
PGVector 页面地址:http://9.135.155.110:5433/browser/
进来之后选择 Server

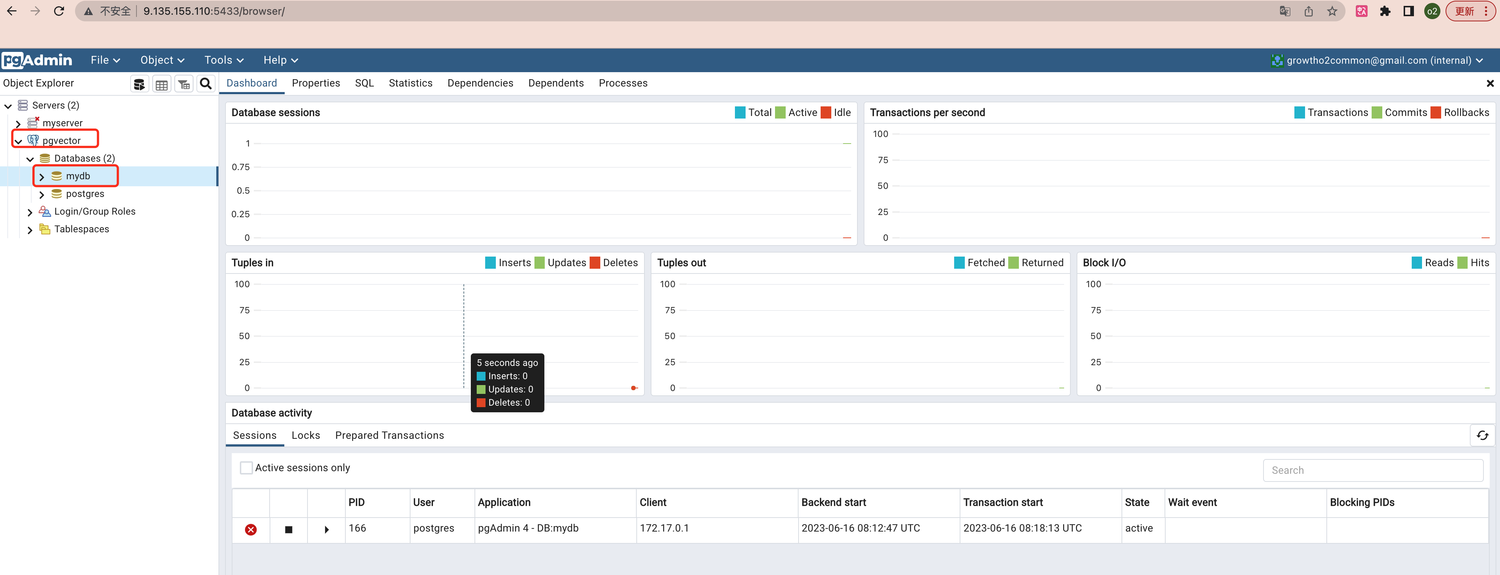
进来之后可以看到我新建的 mydb 数据库,可以用于测试
使用介绍
编译并安装:
cd /tmp
git clone --branch v0.4.2 https://github.com/pgvector/pgvector.git
cd pgvector
make
make install # may need sudo你也可以用 Docker、Homebrew、PGXN、APT、Yum 或 conda-forge 来安装它,它还预装了 Postgres.app 和许多托管提供商。
精确近邻搜索:
# 启用扩展功能
CREATE EXTENSION vector;
# 创建一个具有3个维度的向量列
CREATE TABLE items (id bigserial PRIMARY KEY, embedding vector(3));
# 插入向量
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]');
# 通过L2距离获得最近的结果,还支持内积(<#>)和余弦距离(<=>)。
SELECT * FROM items ORDER BY embedding <-> '[3,1,2]' LIMIT 5;
# 获取一定距离内的记录
SELECT * FROM items WHERE embedding <-> '[3,1,2]' < 5;近似近邻搜索
# 创建索引:在表有一些数据后创建索引,可以对多达2000个维度的向量进行索引
# L2 distance
CREATE INDEX ON items USING ivfflat (embedding vector_l2_ops) WITH (lists = 100);
# Inner product
CREATE INDEX ON items USING ivfflat (embedding vector_ip_ops) WITH (lists = 100);
# Cosine distance
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
# 查询
SELECT * FROM items WHERE category_id = 123 ORDER BY embedding <-> '[3,1,2]' LIMIT 5;Pinecone
基本信息
Pinecone Vector Database 是 Pinecone 公司的产品。Pinecone 可以轻松地为高性能人工智能应用提供永久性存储。它是一个托管的云原生矢量数据库,具有简单的 API,并且没有基础设施的麻烦。 Pinecone 在数十亿个向量的规模上以低延迟提供新鲜的、经过过滤的查询结果。不开源。
官方文档:https://docs.pinecone.io/docs/overview
特性:
- 快速:获得任何规模的超低查询延迟,即使是数十亿个项目。
- 实时:当您添加、编辑或删除数据时获取实时索引更新。
- 过滤:将矢量搜索与元数据过滤器相结合,以获得更相关、更快的结果。
- 全面托管:轻松开始、使用和扩展,同时我们确保一切顺利、安全地运行。
常见使用案例
- 语义文本搜索:使用NLP转化器(如句子嵌入模型)将文本数据转换成矢量嵌入,然后使用Pinecone对这些矢量进行索引和搜索。
- 生成式问题回答:从Pinecone中检索相关的查询内容,并将这些内容传递给OpenAI这样的生成模型,以生成一个由真实数据源支持的答案。
- 混合搜索:在一个查询中对你的数据进行语义和关键词搜索,并将结果结合起来以获得更多相关结果。
- 图像相似性搜索:将图像数据转化为矢量嵌入,并通过Pinecone建立索引。然后将查询图像转换为向量,并检索出相似的图像。
- 产品推荐:基于代表用户的向量,为电子商务生成产品推荐。
其他方面:
暴力检索:没公开
索引:没公开
标量过滤:支持
可视化界面
收费级别(可以试用 Starter 级别,免费层环境中的索引将在 7 天不活动后终止):

Pinecone 页面地址:https://app.pinecone.io/
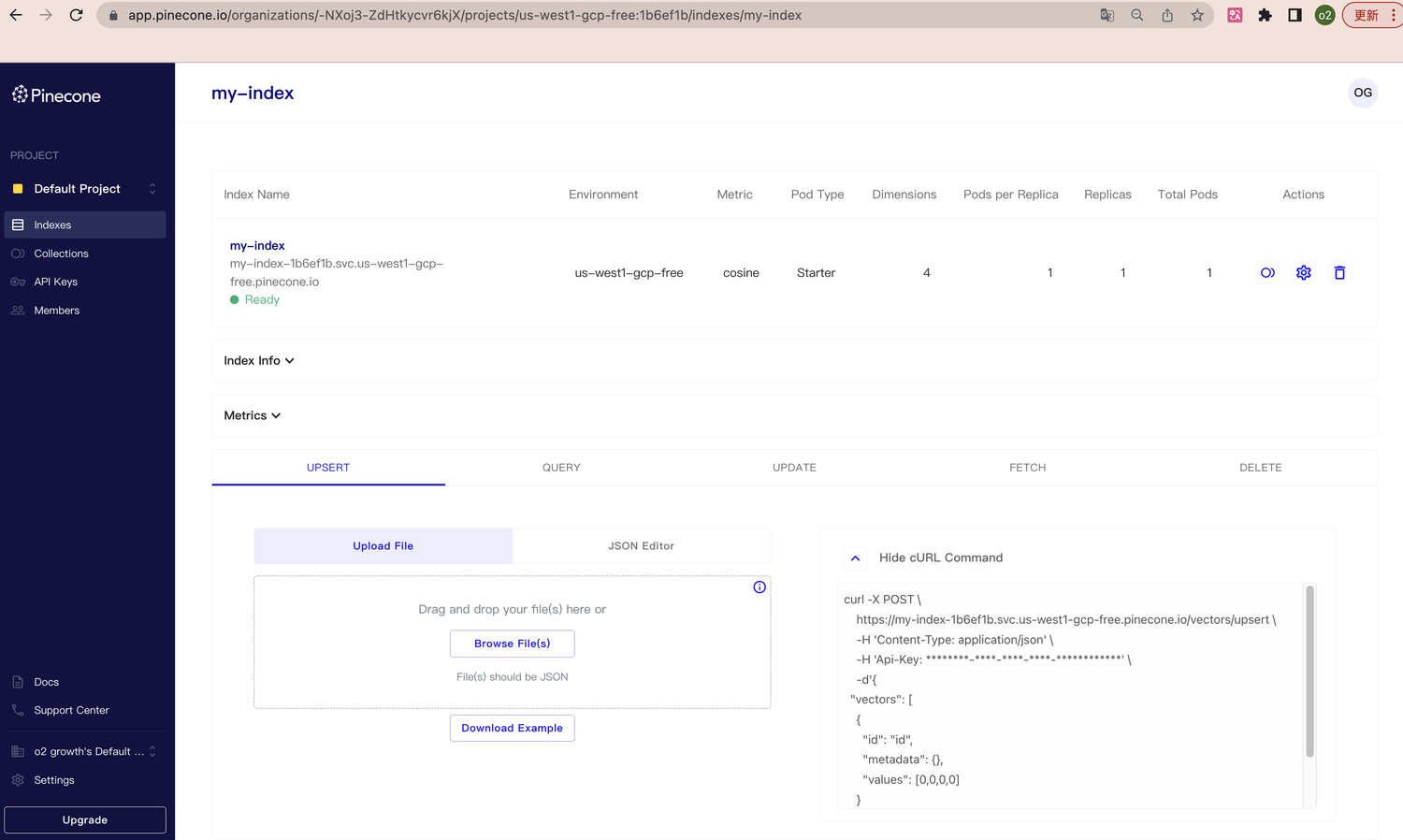
集合是索引的静态副本。它是一组向量和元数据的不可查询的表示。您可以从索引创建集合,也可以从集合创建新索引。此新索引可以与原始源索引不同:新索引可以具有不同数量的 Pod、不同的 Pod 类型或不同的相似性度量。
使用介绍
pip install pinecone-client # 安装 pinecone python 客户端
import pinecone
# 初始化,验证 API key
pinecone.init(api_key="YOUR_API_KEY", environment="YOUR_ENVIRONMENT")
# 创建一个名为"quickstart"的索引,它使用8维向量的欧氏距离度量来执行近似的近邻搜索。创建索引大约需要一分钟时间。
pinecone.create_index("quickstart", dimension=4, metric="euclidean") # euclidean、cosine、dotproduct
# 返回现有的索引列表
pinecone.list_indexes()
# 先连接索引
index = pinecone.Index("quickstart")
# 新增数据 Upsert sample data (5 8-dimensional vectors)
upsert_response = index.upsert(
vectors=[
(
"vec1", # Vector ID
[0.1, 0.2, 0.3, 0.4], # Dense vector values
{"genre": "drama"} # Vector metadata
),
(
"vec2",
[0.2, 0.3, 0.4, 0.5],
{"genre": "action"}
)
],
namespace="example-namespace"
)
# 查询数据,使用条件过滤+欧氏距离得到前三个相似向量
query_response = index.query(
namespace="example-namespace",
top_k=3,
include_values=True,
include_metadata=True,
vector=[0.1, 0.2, 0.3, 0.4],
filter={
"genre": {"$in": ["comedy", "documentary", "drama"]}
}
)Qdrant
基本信息
Qdrant 是一个矢量相似度搜索引擎和矢量数据库。它提供了一个生产可用的服务,带有一个方便的 API 来存储、搜索和管理点。Qdrant 使用 Rust 编写,即使在高负载下也能快速可靠。还有提供一个云托管版本,包括免费套餐。距离度量支持:欧几里德距离、余弦相似度和点积。
官网地址:https://qdrant.tech/
官方文档:https://qdrant.tech/documentation/
Github:https://github.com/qdrant/qdrant,star 数:11.4k
1、Collections:集合是一组命名的点,您可以在其中进行搜索。
2、Distance Metrics:这些用于衡量向量之间的相似性,并且必须在创建集合的同时选择它们。度量的选择取决于向量的获取方式,特别是取决于将用于编码新查询的神经网络。
3、Points:点是 Qdrant 操作的中心实体,它们由一个向量和一个可选的 id 和有效负载组成(有效载荷是一个 JSON 对象,其中包含可以添加到向量的附加数据)
4、Storage:Qdrant 可以使用两种存储选项之一,内存存储(将所有向量存储在 RAM 中,速度最快,因为只有持久性才需要磁盘访问),或 Memmap 存储(创建一个与磁盘上的文件相关的虚拟地址空间)。
特性:
- 丰富的数据类型:可容纳多种数据类型和查询条件,包括字符串匹配、数值范围、地理位置等。这些过滤条件使您能够在相似性匹配的基础上创建自定义业务逻辑。
- SIMD硬件加速:Qdrant 利用现代 CPU x86-x64 架构,在现代硬件上提供更快的搜索性能。
- Write-Ahead Logging 预写式记录:即使在断电期间,Qdrant 也可以通过更新确认来确保数据持久性。更新日志存储所有操作,从而可以轻松重建最新的数据库状态。
- 分布式部署:从 v0.8.0 开始,Qdrant 支持分布式部署。多台 Qdrant 机器形成一个集群,用于水平扩展,通过 Raft 协议进行协调。
- 独立式:Qdrant 独立运行,不依赖外部数据库或编排控制器,简化了配置。
- 暴力检索:支持
- 索引:HNSW
- 标量过滤:支持
可视化界面
收费级别(Community 是自建,可以试用 Managed Cloud):

Qdrant Managed cloud 页面地址:https://cloud.qdrant.io/
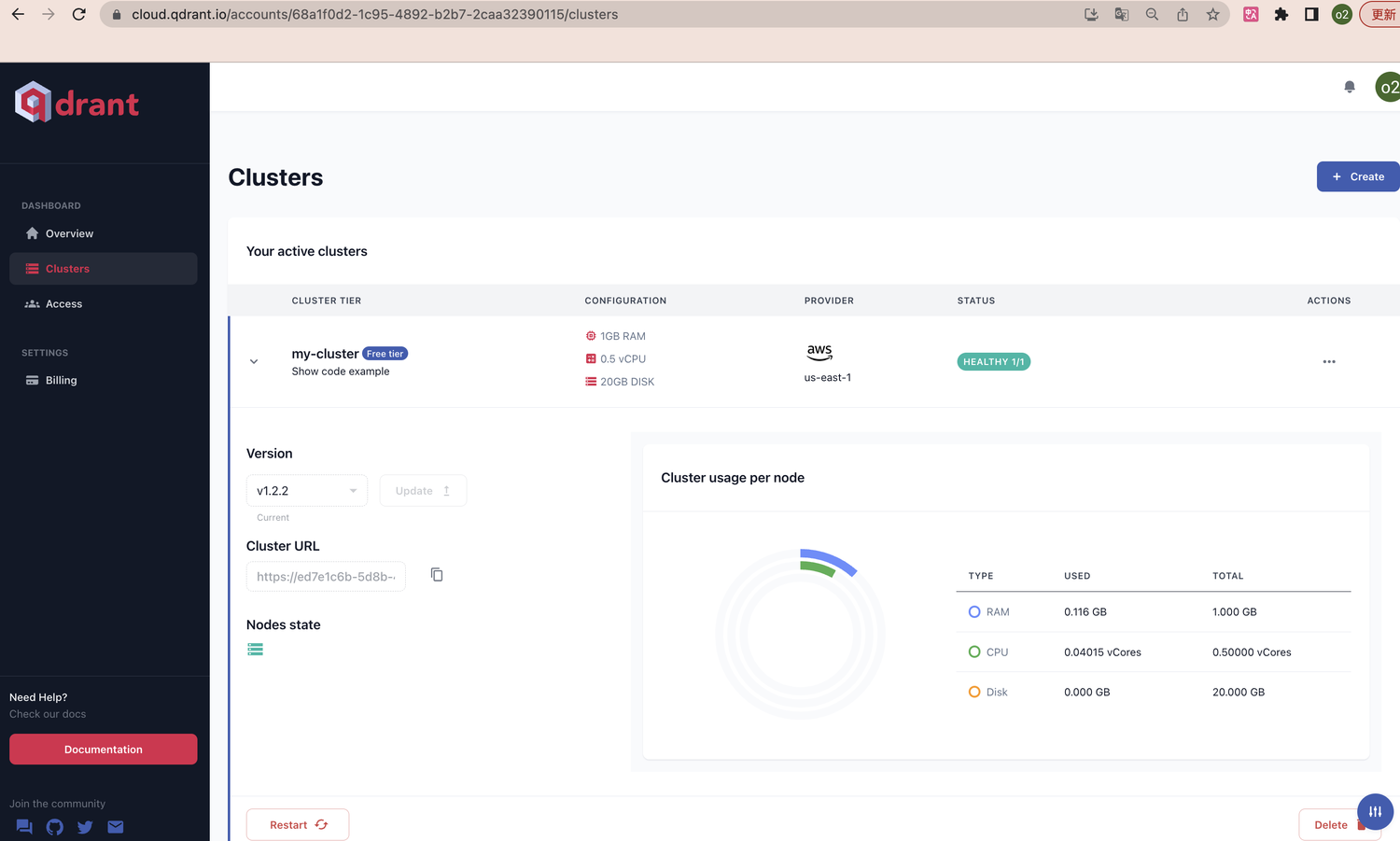
使用介绍
测试环境使用 python 客户端,可以无需安装 qdrant。
正式环境使用 docker 安装部署,或者使用 Qdrant 基于云的官方托管解决方案。
调用方式:1)REST API、2)gRPC、3)Client 客户端(Python、Rust、Go)
from qdrant_client import QdrantClient
from qdrant_client.http.models import Distance, VectorParams
# 创建 collection
client = QdrantClient("localhost", port=6333)
client.recreate_collection(
collection_name="test_collection",
vectors_config=VectorParams(size=4, distance=Distance.DOT),
)
# 查看 collection
collection_info = client.get_collection(collection_name="test_collection")
# 添加 points
operation_info = client.upsert(
collection_name="test_collection",
wait=True,
points=[
PointStruct(id=1, vector=[0.05, 0.61, 0.76, 0.74], payload={"city": "Berlin"}),
PointStruct(id=2, vector=[0.19, 0.81, 0.75, 0.11], payload={"city": ["Berlin", "London"]}),
PointStruct(id=3, vector=[0.36, 0.55, 0.47, 0.94], payload={"city": ["Berlin", "Moscow"]}),
PointStruct(id=4, vector=[0.18, 0.01, 0.85, 0.80], payload={"city": ["London", "Moscow"]}),
PointStruct(id=5, vector=[0.24, 0.18, 0.22, 0.44], payload={"count": [0]}),
PointStruct(id=6, vector=[0.35, 0.08, 0.11, 0.44]),
]
)
# 查询
search_result = client.search(
collection_name="test_collection",
query_vector=[0.2, 0.1, 0.9, 0.7],
query_filter=Filter(
must=[
FieldCondition(
key="city",
match=MatchValue(value="London")
)
]
),
search_params=models.SearchParams(
hnsw_ef=128,
exact=False # exact - 不使用近似搜索 (ANN) 的选项。如果设置为 true,搜索可能会运行很长时间,因为它会执行完整扫描以检索准确的结果。(暴力检索)
),
limit=3
)Qdrant 目前仅使用 HNSW 作为矢量索引。
为了提高性能,HNSW 将图的每一层节点的最大度数限制为 m 。此外,您可以使用 ef_construct (建立索引时)或 ef (搜索目标时)来指定搜索范围。
hnsw_index:
# 索引图中每个节点的边数。值越大 - 搜索越准确,需要的空间就越大。
m: 16
# 建立索引时要考虑的邻居数量。值越大——搜索越准确,建立索引所需的时间越长。
ef_construct: 100
# Minimal size (in KiloBytes) of vectors for additional payload-based indexing.
# If payload chunk is smaller than `full_scan_threshold_kb` additional indexing won't be used -
# in this case full-scan search should be preferred by query planner and additional indexing is not required.
# Note: 1Kb = 1 vector of size 256
full_scan_threshold_kb: 10000
# Number of parallel threads used for background index building. If 0 - auto selection.
max_indexing_threads: 0
# Store HNSW index on disk. If set to false, index will be stored in RAM. Default: false
on_disk: false
# Custom M param for hnsw graph built for payload index. If not set, default M will be used.
payload_m: null ef 参数在搜索期间配置,默认情况下等于 ef_construct 。
支持对向量进行量化。
Weaviate
介绍
Weaviate 是一个开源矢量数据库,公司名称也叫 Weaviate。开箱即用,支持不同的媒体类型(文本、图像等)。它提供语义搜索、问题-答案提取、分类、可定制模型(PyTorch/TensorFlow/Keras)等。Weaviate用Go语言从头开始构建,同时存储对象和向量,允许将向量搜索与结构化过滤和云原生数据库的容错性相结合。这一切都可以通过GraphQL、REST和各种客户端编程语言进行访问。
官网地址:https://weaviate.io/
官方文档:https://weaviate.io/developers/weaviate
Github:https://github.com/weaviate/weaviate,star 数:6.6k
特点:
- 快速查询:Weaviate 通常在不到 100 毫秒的时间内对数百万个对象执行最近邻 (NN) 搜索。您可以在我们的基准页面上找到更多信息。benchmark
- 使用 Weaviate 模块摄取任何媒体类型:使用最先进的 AI 模型推理(例如 Transformer)在搜索和查询时访问数据(文本、图像等),让 Weaviate 为您管理数据矢量化过程 - 或提供您自己的向量。
- 将矢量和标量搜索相结合:Weaviate可以实现高效的、结合矢量和标量的搜索。例如,"过去7天内发表的与COVID-19大流行有关的文章"。Weaviate同时存储对象和矢量,并确保两者的检索始终高效。
- 实时性和持久性:即使当前正在导入或更新数据,Weaviate 也可让您搜索数据。此外,每次写入都会写入预写日志 (WAL),以便立即持久写入 - 即使发生崩溃也是如此。
- 水平扩展性:根据您的具体需求扩展 Weaviate,例如数据集大小、每秒最大查询数等。
- 成本效益:在Weaviate中,非常大的数据集并不需要完全保存在内存中。同时,可用的内存可以用来提高查询的速度。这样就可以有意识地对速度/成本进行权衡,以适应各种使用情况。
其他方面:
- 暴力检索:不支持
- 索引:HNSW
可视化界面
3种收费级别 + Sandbox Free 级别(沙盒是免费的,但会在 14 天后过期。这段时间之后,沙盒中的所有数据都将被删除):
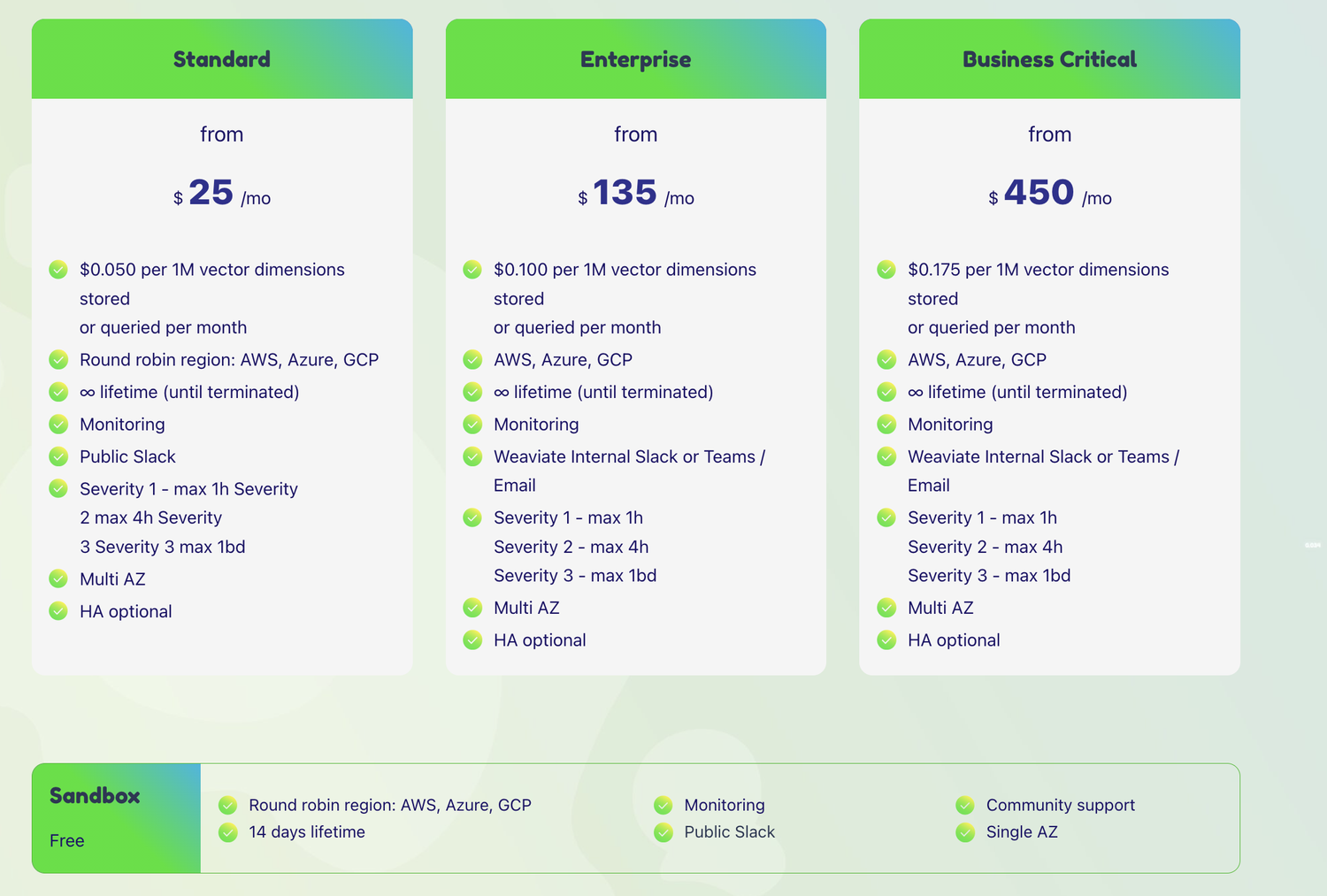
weaviate cloud 页面地址:https://console.weaviate.cloud/,可以登陆到托管的 weaviate cloud,也可以登陆到自建的 weaviate cloud,试用的话登陆到托管的 weaviate cloud 即可。
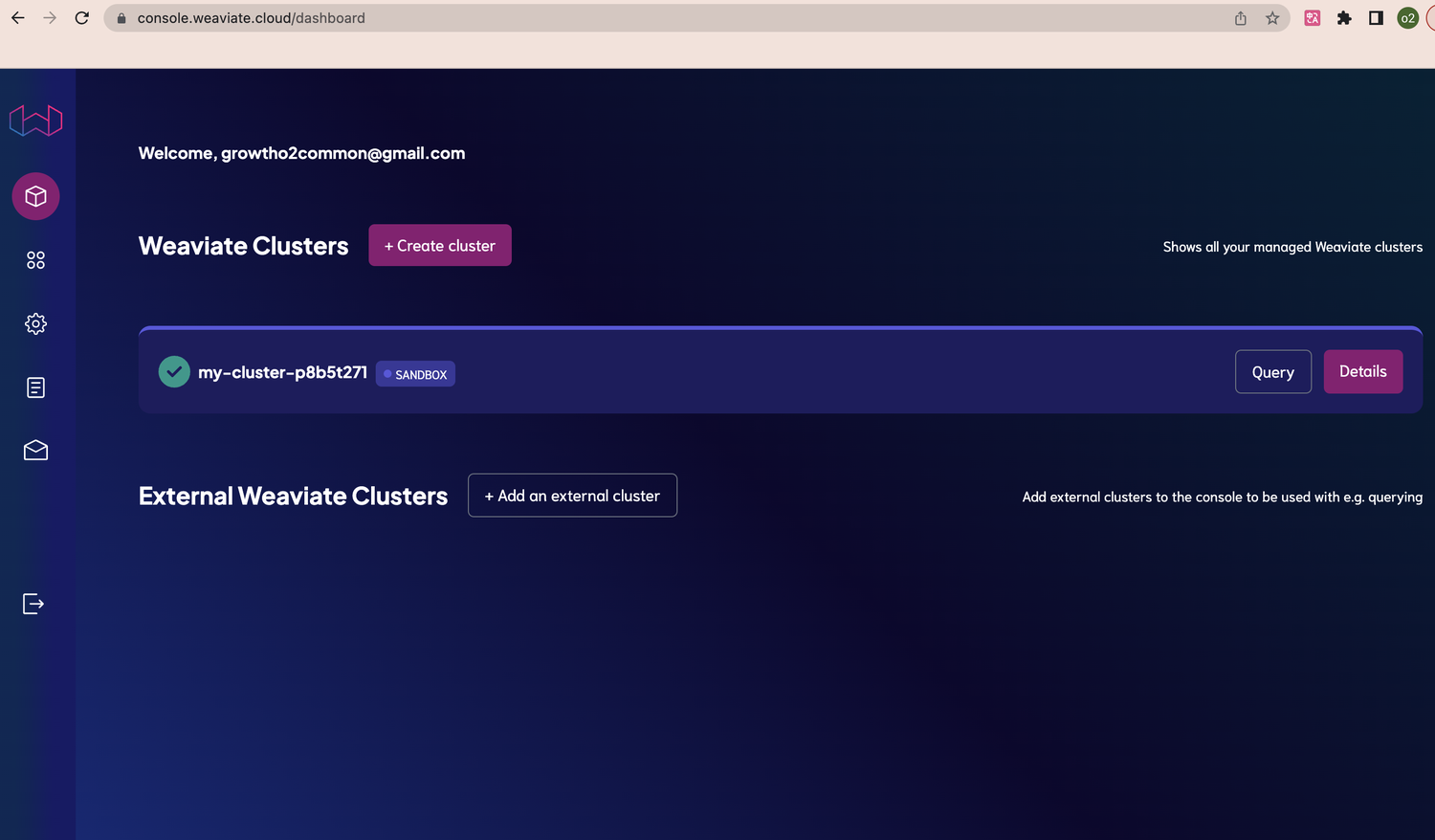
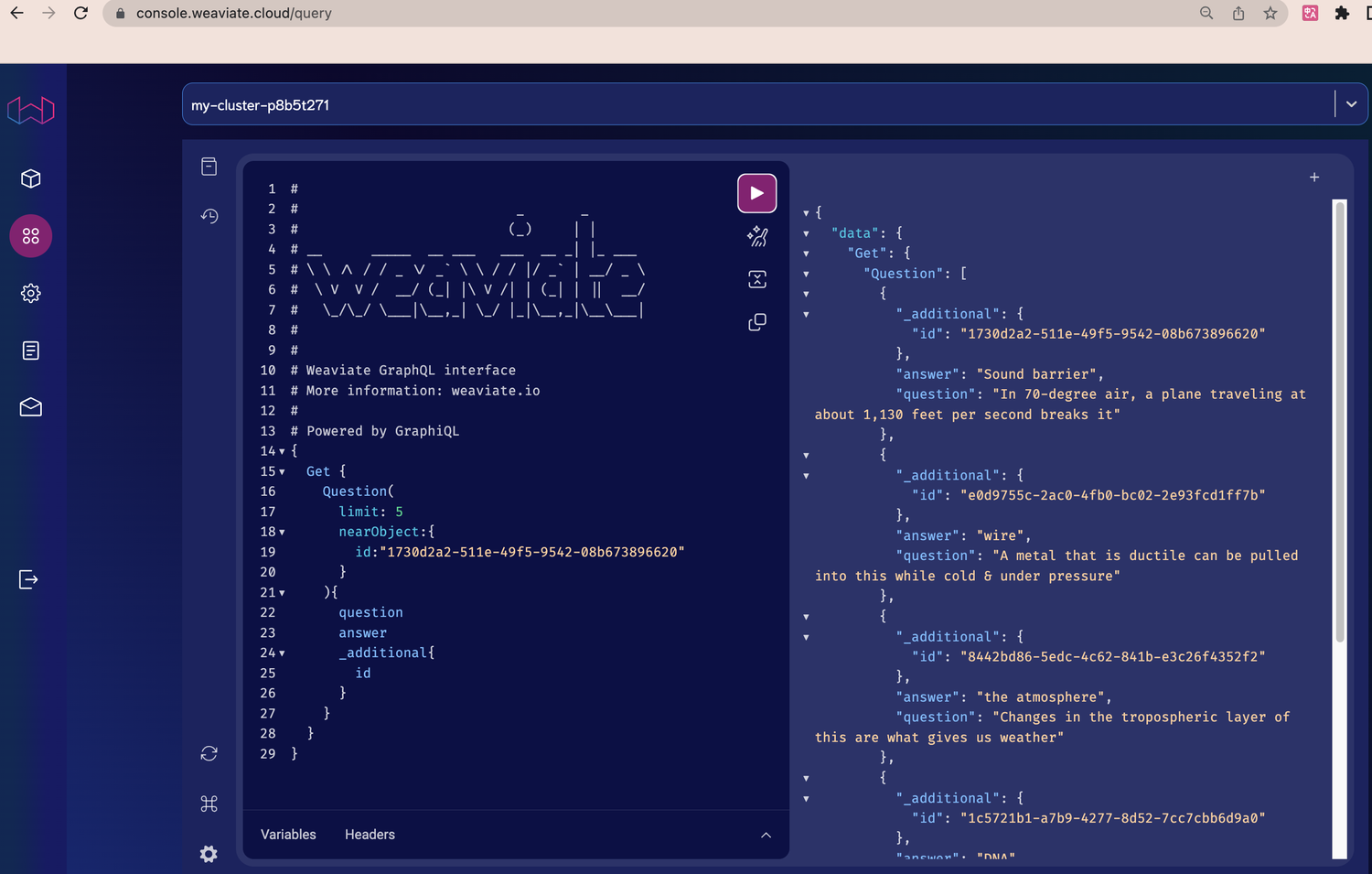
使用介绍
可以通过 Python、JavaScript/TypeScript、Go、Java 等客户端进行操作,还可以使用其 GraphQL API 或 RESTful API 来检索对象和属性。
这里介绍使用 Python 客户端进行操作:
# Load data
import weaviate
import json
client = weaviate.Client(
url = "https://some-endpoint.weaviate.network", # Replace with your endpoint
auth_client_secret=weaviate.AuthApiKey(api_key="YOUR-WEAVIATE-API-KEY"), # Replace w/ your Weaviate instance API key
additional_headers = {
"X-HuggingFace-Api-Key": "YOUR-HUGGINGFACE-API-KEY" # Replace with your inference API key
}
)
# ===== add schema ===== # 如果您使用不同的矢量化器,我们还提供建议的 vectorizer 模块配置:Cohere、Hugging Face、OpenAI、PaLM
class_obj = {
"class": "Question",
"vectorizer": "text2vec-huggingface", # If set to "none" you must always provide vectors yourself. Could be any other "text2vec-*" also.
"moduleConfig": {
"text2vec-huggingface": {
"model": "sentence-transformers/all-MiniLM-L6-v2", # Can be any public or private Hugging Face model.
"options": {
"waitForModel": True
}
}
}
}
client.schema.create_class(class_obj)
# ===== import data =====
# Load data
import requests
url = 'https://raw.githubusercontent.com/weaviate-tutorials/quickstart/main/data/jeopardy_tiny.json'
resp = requests.get(url)
data = json.loads(resp.text)
# Configure a batch process
with client.batch(
batch_size=100
) as batch:
# Batch import all Questions
for i, d in enumerate(data):
print(f"importing question: {i+1}")
properties = {
"answer": d["Answer"],
"question": d["Question"],
"category": d["Category"],
}
client.batch.add_data_object(
properties,
"Question",
# vector=custom_vector # 如果没有指定模型,需要自己设置向量
)查询:
import weaviate
import json
client = weaviate.Client(
url = "https://some-endpoint.weaviate.network", # Replace with your endpoint
auth_client_secret=weaviate.AuthApiKey(api_key="YOUR-WEAVIATE-API-KEY"), # Replace w/ your Weaviate instance API key
additional_headers = {
"X-HuggingFace-Api-Key": "YOUR-HUGGINGFACE-API-KEY" # Replace with your inference API key
}
)
nearText = {"concepts": ["biology"]}
response = (
client.query
.get("Question", ["question", "answer", "category"])
.with_near_text(nearText) # 指定向量 .with_near_vector({"vector": [-0.0125526935]})
.with_limit(2)
.with_where({ # 条件过滤器
"path": ["round"],
"operator": "Equal",
"valueText": "Double Jeopardy!"
})
.do()
)
print(json.dumps(response, indent=4))具体查询 API 功能很丰富,可以查看文档:https://weaviate.io/developers/weaviate/search/basics
使用 HNSW 时,您还可以选择使用乘积量化 (PQ) 来压缩向量表示,以帮助减少内存需求。乘积量化是一种允许 Weaviate 的 HNSW 向量索引使用更少字节存储向量的技术。由于 HNSW 将向量存储在内存中,因此可以在给定的内存量上运行更大的数据集。
client.schema.update_config("DeepImage", {
"vectorIndexConfig": {
"pq": {
"enabled": True,
}
}
})Zilliz
介绍
Zilliz Cloud 和 Milvus 同为 Zilliz 公司的产品,Milvus 是开源的,而 Zilliz Cloud 提供完全托管的 Milvus 服务,是一个商业化版本的 Milvus。它无需创建和维护复杂的数据基础架构,从而简化了矢量搜索应用程序的部署和扩展过程。
官网地址:https://zilliz.com/
这里直接列出官方提供的 Zilliz Cloud 与 Milvus Community edition 的比较。
Deployment
Zilliz Cloud vector database | Community edition | |
|---|---|---|
云提供商的选择 | AWS, GCP, Azure (coming soon) | No |
部署规模的选择 | 多种部署规模和类别 | Self-managed |
存储 | 数据存储无限制 | Self-managed |
升级和错误修复 | 简单 | Self-managed |
可用性 | 99.9% | 无保证 |
Database features
Zilliz Cloud Vector database | Community edition | |
|---|---|---|
向量相似度检索 | Yes | Yes |
标量数据类型 | INTFLOATBOOLEANVARCHAR | INTFLOATBOOLEANVARCHAR |
ANNS 索引 | AUTOINDEX optimized for high-performance searchesAUTOINDEX optimized for big-data searches(AUTOINDEX 是 Zilliz Cloud 上可用于索引自动优化的专有索引类型) | FLATIVF_FLATIVF_SQ8IVF_PQHNSWANNOYDISKANN |
Vector similarity metrics (距离计算方式) | Euclidean distance (L2)Inner product (IP) | Euclidean distance (L2)Inner product (IP)HammingJaccardTanimotoSuperstructureSubstructure |
混合搜索 | Yes | Yes |
Time travel | Yes | Yes |
多用户 | Yes | Yes |
客户端 | Python and Java SDK (fully tested) | Community maintained SDKs |
- INT
- FLOAT
- BOOLEAN
- VARCHAR
- INT
- FLOAT
- BOOLEAN
- VARCHAR
ANNS 索引
- AUTOINDEX optimized for high-performance searches
- AUTOINDEX optimized for big-data searches
(AUTOINDEX 是 Zilliz Cloud 上可用于索引自动优化的专有索引类型)
- FLAT
- IVF_FLAT
- IVF_SQ8
- IVF_PQ
- HNSW
- ANNOY
- DISKANN
Vector similarity metrics (距离计算方式)
- Euclidean distance (L2)
- Inner product (IP)
- Euclidean distance (L2)
- Inner product (IP)
- Hamming
- Jaccard
- Tanimoto
- Superstructure
- Substructure
混合搜索YesYesTime travelYesYes多用户YesYes客户端Python and Java SDK (fully tested)Community maintained SDKs
Administrative tools 管理工具
Zilliz Cloud Vector database | Community edition | |
|---|---|---|
GUI | Cloud UI | Attu, CLI |
其他方面:
暴力检索:不支持
索引:AUTOINDEX 自研算法
标量过滤:支持
可视化界面
收费级别:
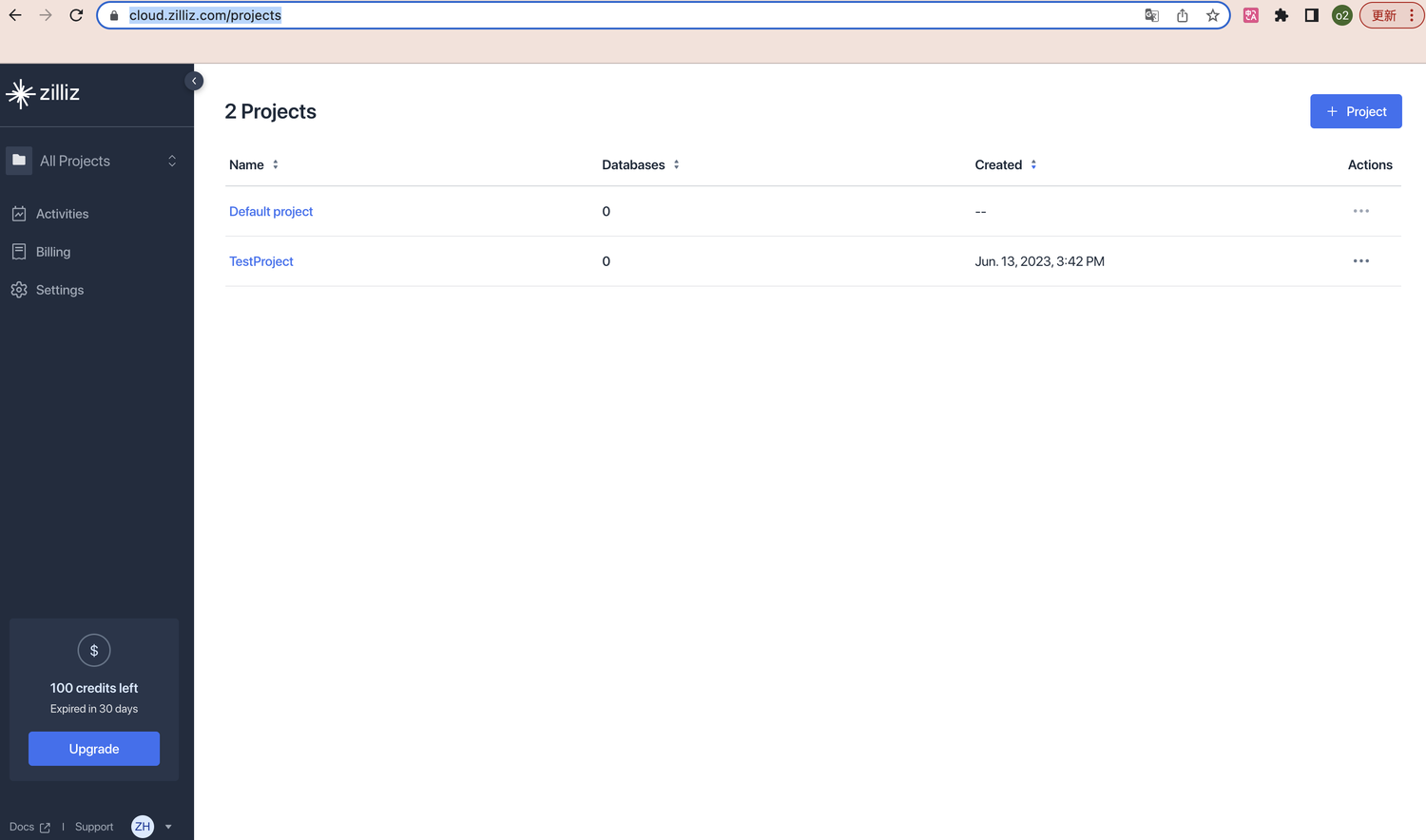
zilliz cloud 页面地址:https://cloud.zilliz.com/
首次注册有100美元积分可以试用(30天有效期)
https://zilliz.com/doc/quick_start 该官方文档也有比较详细的操作指引。
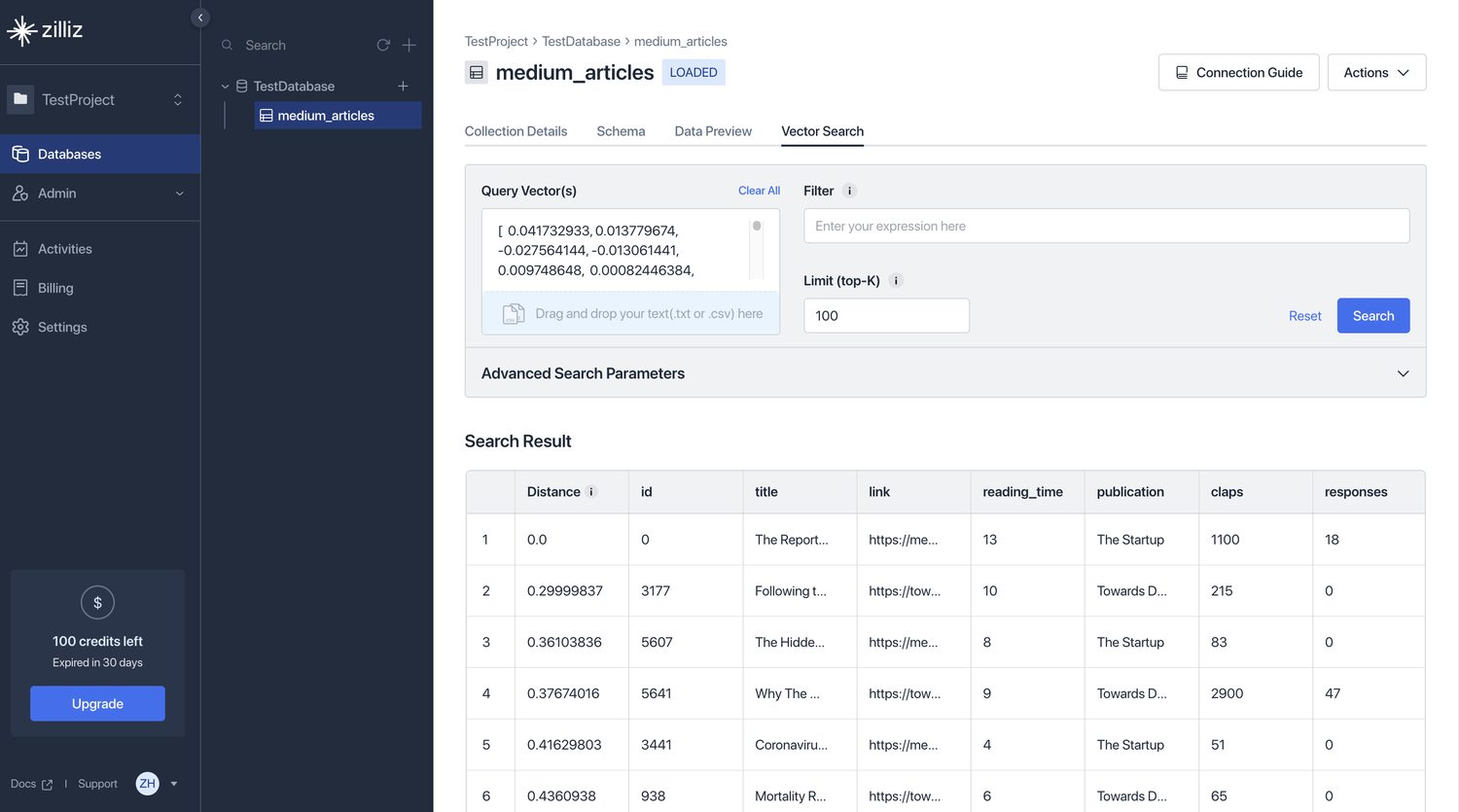
操作介绍
from pymilvus import MilvusClient
# Initialize a MilvusClient instance
# Replace uri and API key with your own
client = MilvusClient(
uri="<CLUSTER-ENDPOINT>", # Cluster endpoint obtained from the console
token="<API-KEY>"
)
# Create a collection
client.create_collection(
collection_name="medium_articles_2020",
dimension=768
)
# Insert a single entity
res = client.insert(
collection_name="medium_articles_2020",
data={
'id': 0,
'title': 'The Reported Mortality Rate of Coronavirus Is Not Important',
'link': 'https://medium.com/swlh/the-reported-mortality-rate-of-coronavirus-is-not-important-369989c8d912',
'reading_time': 13,
'publication': 'The Startup',
'claps': 1100,
'responses': 18,
'vector': [0.041732933, 0.030096486]
}
)
with open("https://s3.us-west-2.amazonaws.com/publicdataset.zillizcloud.com/medium_articles_2020_dpr/medium_articles_2020_dpr.json") as f:
data = json.load(f)
res = client.search(
collection_name="medium_articles_2020",
data=[data["rows"][0]["title_vector"]],
filter='claps > 100 and publication in ["The Startup", "Towards Data Science"]',
output_fields=["title", "claps", "publication"]
)原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号