深度优先搜索(DFS)与回溯法:从全排列到子集问题的决策树与剪枝优化

深度优先搜索(DFS)与回溯法:从全排列到子集问题的决策树与剪枝优化

suye
发布于 2024-12-20 08:57:12
发布于 2024-12-20 08:57:12
前言
深度优先搜索(DFS)和回溯法是解决复杂问题中不可或缺的算法工具,尤其在组合问题(如全排列、子集等)中,发挥着至关重要的作用。通过递归的方式,DFS 能够遍历问题的解空间,而回溯法则通过撤销不合法的选择,避免重复计算,提高效率。在解题过程中,剪枝是优化回溯法的重要手段,它通过提前排除无效路径,进一步减少了运算的复杂度。本文将深入探讨如何使用 DFS、回溯法及剪枝技术,构建解决全排列和子集问题的决策树,并优化算法的执行效率。
🎄一、全排列
题目链接:https://leetcode.cn/problems/permutations/description/
✨核心思路
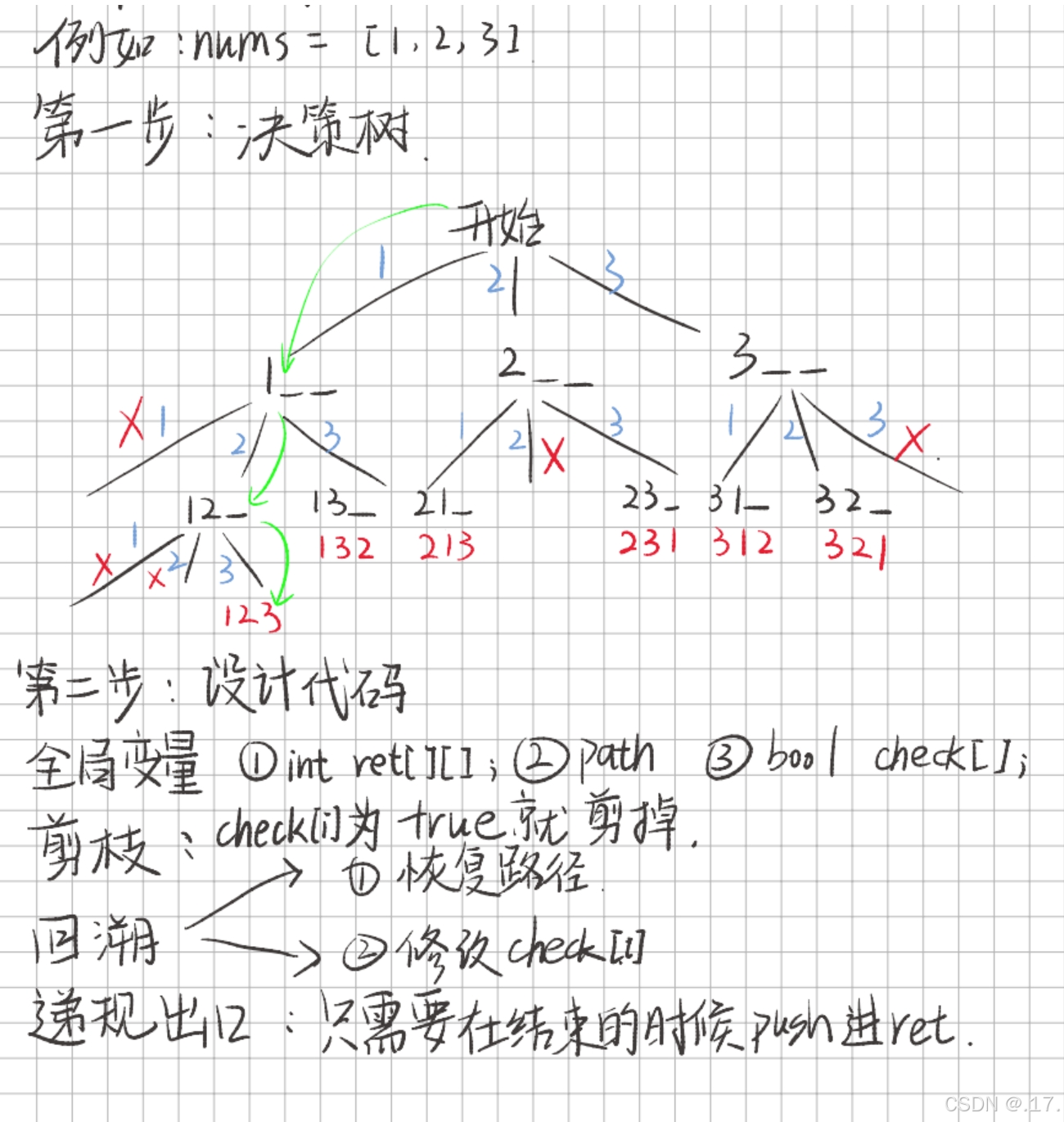
这段代码实现了生成一个数组的所有排列(Permutation),并返回所有可能的排列列表。采用了**深度优先搜索(DFS)**的方式,配合一个 check 数组来记录哪些元素已经使用过,从而避免重复使用。
✨实现步骤
- 初始化变量:
vector<vector<int>> ret:存储最终结果,包含所有排列。vector<int> path:存储当前正在构造的排列。bool check[7]:标记数组,记录某个位置是否已经被使用,避免重复选择。默认全为false。
- 主函数
permute:- 调用
dfs(nums)开始进行递归遍历,寻找所有排列。 - 返回最终结果
ret。
- 调用
- 辅助函数
dfs:- 递归终止条件:当
path的长度等于nums.size(),说明已经构造出一个完整的排列,将其加入结果集ret。 - 循环遍历:
- 遍历数组的每个元素,判断其是否已经被使用(
check[i] == false)。 - 如果未使用,将其加入当前路径
path,同时更新check[i] = true。 - 递归调用
dfs(nums),继续构造排列。 - 回溯:
- 移除当前路径中的最后一个元素
path.pop_back()。 - 重置
check[i] = false,允许后续尝试其他路径。
- 移除当前路径中的最后一个元素
- 遍历数组的每个元素,判断其是否已经被使用(
- 递归终止条件:当
如图分析:
✨代码
class Solution {
public:
vector<vector<int>> ret;
vector<int> path;
bool check[7];
vector<vector<int>> permute(vector<int>& nums) {
dfs(nums);
return ret;
}
void dfs(vector<int>& nums) {
if (path.size() == nums.size()) {
ret.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
if (check[i] == false) {
path.push_back(nums[i]);
check[i] = true;
dfs(nums);
// -> ֳָ
path.pop_back();
check[i] = false;
}
}
}
};✨时间和空间复杂度
🎁1. 时间复杂度
- 每个排列需要遍历
nums的所有元素,同时需要递归构造排列。 - 全排列的总数为
,其中 n 为 nums 的长度。
- 每次构造排列需要
的时间复杂度,因此总时间复杂度为:
🎁2. 空间复杂度
- 递归深度为
,对应递归栈的最大深度。
- 存储结果的
ret大小为
(每个排列长度为 n,共有 n! 个排列)。
- 额外空间为 path 和 check,均为 O(n) 。
- 总空间复杂度为:
🎄二、子集
题目链接:https://leetcode.cn/problems/subsets/description/
✨解法一:逐位置决策法
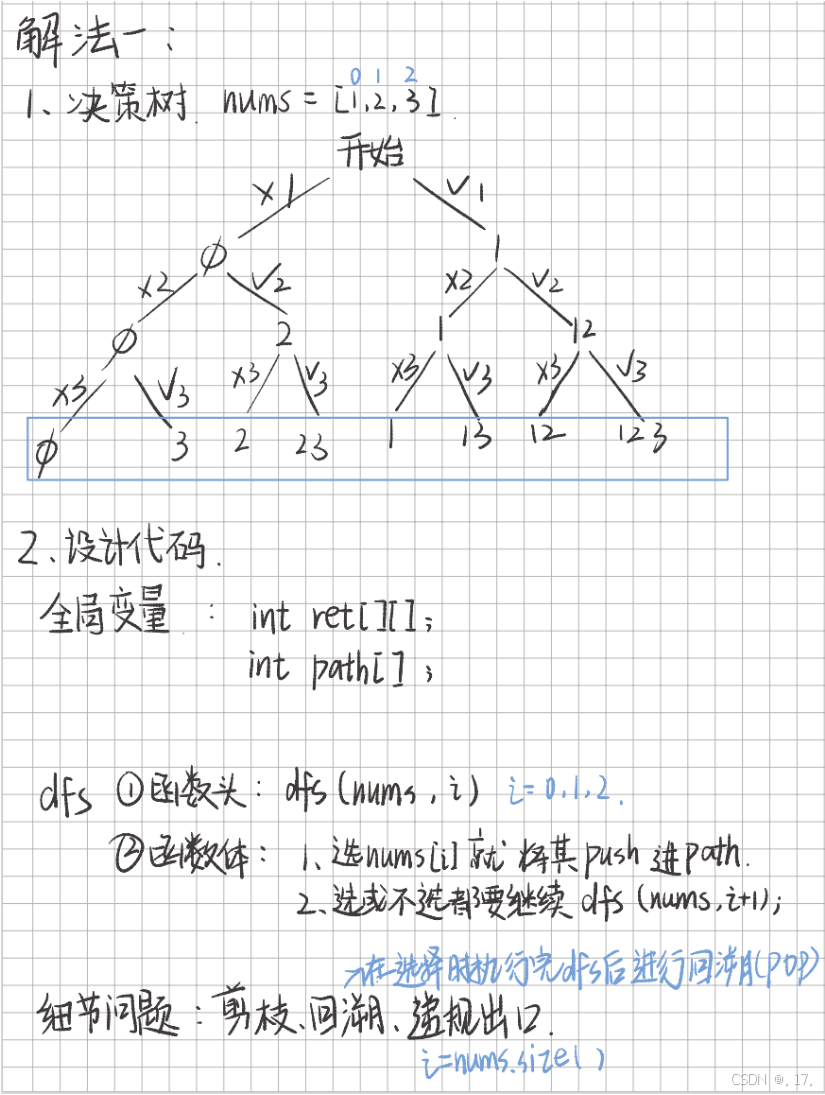
核心思想:对于每个位置,都需要明确“选”或者“不选”两种可能,然后继续对后续位置进行递归。
🎁步骤分析
- 输入数组:
nums = [1, 2, 3]。 - 决策树构造:
- 对于每个元素,存在两个分支:选它和不选它。
- 递归过程中,我们先“选”再“回溯”,然后“跳过当前元素”。
- 递归终止条件:
- 当递归位置
pos达到数组末尾(pos == nums.size())时,将当前路径path加入结果集ret。
- 当递归位置
🎁运行示例
- 初始调用:
dfs(nums, 0)- 选1:
path = [1],递归进入dfs(nums, 1)- 选2:
path = [1, 2],递归进入dfs(nums, 2)- 选3:
path = [1, 2, 3],递归终止,保存结果[[1, 2, 3]] - 回溯到选2状态:
path = [1, 2] - 不选3:
path = [1, 2],递归终止,保存结果[[1, 2, 3], [1, 2]]
- 选3:
- 回溯到选1状态:
path = [1] - 不选2:
path = [1],递归进入dfs(nums, 2)- 选3:
path = [1, 3],递归终止,保存结果[[1, 2, 3], [1, 2], [1, 3]] - 不选3:
path = [1],递归终止,保存结果[[1, 2, 3], [1, 2], [1, 3], [1]]
- 选3:
- 选2:
- 回溯到初始状态:
path = [] - 不选1:
path = [],递归进入dfs(nums, 1)- 选2:
path = [2],递归类似上面。 - 不选2:
path = [],递归继续处理后续。
- 选2:
- 选1:
最终得到所有子集。
如图分析:
🎁代码
class Solution {
public:
vector<vector<int>> ret;
vector<int> path;
vector<vector<int>> subsets(vector<int>& nums) {
dfs(nums, 0);
return ret;
}
void dfs(vector<int>& nums, int pos) {
if (pos == nums.size()) {
ret.push_back(path);
return;
}
// 选
path.push_back(nums[pos]);
dfs(nums, pos + 1);
// 回溯 -> 恢复现场
path.pop_back();
// 不选
dfs(nums, pos + 1);
}
};✨解法二:逐元素扩展法
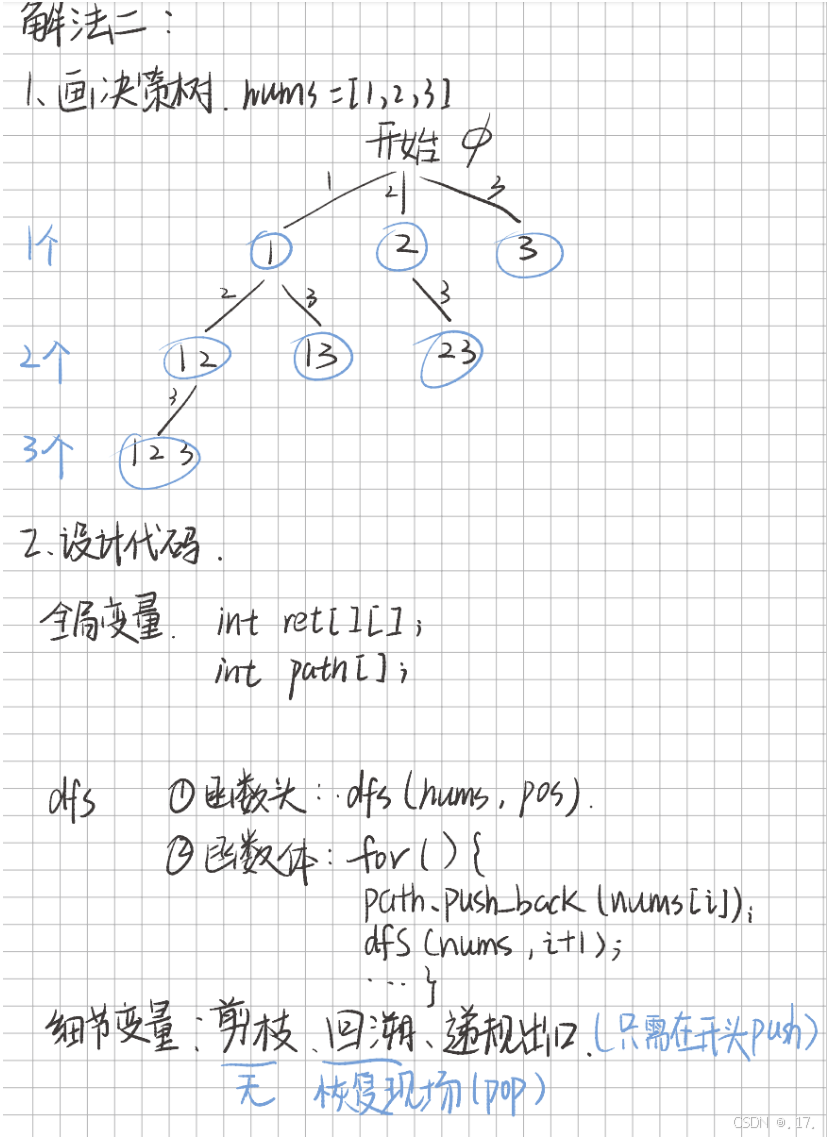
核心思想:直接将当前路径加入结果集,然后从当前位置逐个向后选取元素递归。
🎁步骤分析
- 输入数组:
nums = [1, 2, 3]。 - 递归机制:
- 每次递归时,直接将当前路径加入结果集。
- 从当前位置
pos开始,依次向后选择元素,尝试递归。
🎁运行示例
- 初始调用:dfs(nums, 0)
- 当前路径为空,加入结果集:
ret = [[]] - 从
pos = 0开始:- 选1:
path = [1],加入结果集:ret = [[], [1]],递归进入dfs(nums, 1)- 选2:
path = [1, 2],加入结果集:ret = [[], [1], [1, 2]],递归进入dfs(nums, 2)- 选3:
path = [1, 2, 3],加入结果集:ret = [[], [1], [1, 2], [1, 2, 3]] - 回溯到选2状态:
path = [1, 2]
- 选3:
- 回溯到选1状态:
path = [1]
- 选2:
- 回溯到初始状态:
path = [] - 选2:递归同上。
- 选3:递归继续。
- 选1:
- 当前路径为空,加入结果集:
如图分析:
🎁代码
class Solution {
public:
vector<vector<int>> ret;
vector<int> path;
vector<vector<int>> subsets(vector<int>& nums) {
dfs(nums, 0);
return ret;
}
void dfs(vector<int>& nums, int pos) {
ret.push_back(path);
for (int i = pos; i < nums.size(); i++) {
path.push_back(nums[i]);
dfs(nums, i + 1);
// 回溯 -> 恢复现场
path.pop_back();
}
}
};✨时间复杂度分析
🎁解法一
- 决策树分析:
- 每个元素有两种选择(选或不选),对于长度为 n 的数组,共有 2^n 种子集。
- 递归的每一步都对应一个子集的生成,因此遍历整个决策树需要 O(2^n) 的时间。
- 额外操作:
- 每次递归终止时,将当前路径
path加入结果,需要 O(n) 的时间(复制path的内容)。
- 每次递归终止时,将当前路径
总时间复杂度:
🎁解法二
- 决策树分析:
- 每个元素被递归遍历一次,所有可能的子集共 2^n 个。
- 递归过程中,每次递归都会将当前路径
path加入结果集ret。
- 额外操作:
- 每次将路径加入结果集也需要 O(n) 的时间(复制
path)。
- 每次将路径加入结果集也需要 O(n) 的时间(复制
总时间复杂度: O(2n⋅n)
✨空间复杂度分析
🎁解法一
- 递归深度:
- 递归调用的最大深度为数组长度 n ,因此递归栈的空间复杂度为
O(n) 。
- 路径存储:
path需要存储当前路径,大小为
O(n) 。
- 结果集:
- 最终结果集
ret包含
2^n 个子集,每个子集的平均长度为
O(n/2) ,因此结果集的存储空间为:
O(2n⋅n) - 最终结果集
总空间复杂度:
(递归栈和路径空间较小,可忽略不计)
🎁解法二
- 递归深度:
- 递归调用的最大深度为数组长度 n,因此递归栈的空间复杂度为
O(n) 。
- 路径存储:
path需要存储当前路径,大小为
O(n) 。
- 结果集: 同解法一,结果集需要 O(2^n \cdot n) 的空间。
总空间复杂度:
(递归栈和路径空间较小,可忽略不计)
🎄三、找出所有子集的异或总和再求和
题目链接:https://leetcode.cn/problems/sum-of-all-subset-xor-totals/description/
✨解法简介
题目要求求出数组中所有子集的异或和的总和。解法采用 回溯法 (Backtracking),枚举所有子集,同时计算每个子集的异或和,并将其累加到结果中。
✨解法步骤
🎁Step 1: 初始化变量
ret:最终结果,用于存储所有子集的异或和的累加值。path:当前路径变量,表示当前子集的异或值。nums:输入数组。
🎁Step 2: 回溯递归函数设计
递归函数 dfs(nums, pos):
- 功能:
- 遍历以
pos为起点的所有可能子集。 - 累加每个子集的异或值到
ret。
- 遍历以
- 核心逻辑:
- 累加当前路径的异或值到
ret: 每次递归进入时,将当前路径的异或值(path)加入到结果中。 - 枚举后续元素: 从当前
pos开始,逐一尝试将后续元素加入路径path,并递归处理。 - 回溯: 在递归返回后,撤销当前选择(通过异或运算恢复
path的值)。
- 累加当前路径的异或值到
- 递归终止条件:
- 无需显式终止条件,因为递归自然会遍历所有子集,当
pos超出数组范围时,循环自动结束。
- 无需显式终止条件,因为递归自然会遍历所有子集,当
🎁Step 3: 主函数调用
在主函数 subsetXORSum 中:
- 初始化结果变量
ret = 0。 - 调用回溯函数:
dfs(nums, 0),从数组的第 0 个位置开始递归。 - 返回最终结果
ret。
如图分析:

✨代码
class Solution {
public:
int ret = 0;
int path = 0;
int subsetXORSum(vector<int>& nums) {
dfs(nums, 0);
return ret;
}
void dfs(vector<int>& nums, int pos){
ret += path;
for(int i = pos; i < nums.size(); i++){
path ^= nums[i];
dfs(nums, i + 1);
// 回溯
path ^= nums[i];
}
}
};✨时间与空间复杂度
🎁时间复杂度
- 子集数量:对于数组长度为
,共有
个子集。
- 异或计算:每次递归执行异或操作的时间复杂度为
。
- 总复杂度:
🎁空间复杂度
- 递归深度:递归调用栈的最大深度为
。
- 路径变量:
path是一个整数,占用
的空间。
- 总复杂度:
🎄四、全排列II
题目链接:https://leetcode.cn/problems/permutations-ii/description/
✨解法简介
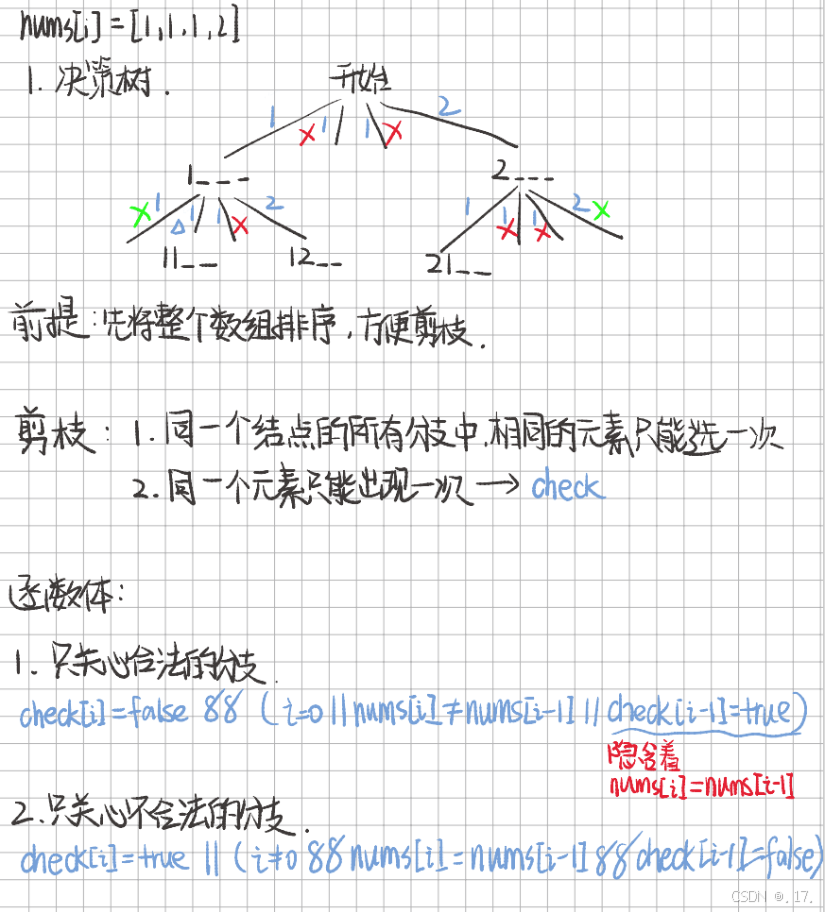
利用 回溯法 (Backtracking) 生成所有排列,通过排序和剪枝(跳过重复元素)来避免生成重复排列。
✨步骤详解
🎁Step 1: 初始化
- 变量说明:
ret:存储所有结果的二维数组。path:当前路径,用于构造一个排列。check:布尔数组,记录每个元素是否已经被使用过。
- 预处理:
- 对输入数组
nums进行排序:sort(nums.begin(), nums.end())。- 排序的目的是将相同的元素放在一起,方便后续剪枝操作。
- 对输入数组
🎁Step 2: 回溯递归函数设计
递归函数 dfs(nums, pos):
- 递归终止条件:
- 如果当前路径
path的大小等于数组nums的长度,说明构造了一组完整排列,将其加入结果集ret。
- 如果当前路径
- 循环遍历每个元素:
- 遍历
nums中的每个元素,尝试将未被使用的元素加入当前路径。
- 遍历
- 剪枝条件:
- 元素未被使用:通过
check[i] == false判断当前元素是否可用。 - 跳过重复元素:
nums[i] == nums[i - 1]:当前元素与前一个元素相同。check[i - 1] == false:前一个相同的元素尚未被使用,说明该排列已经处理过,直接跳过当前分支。
- 元素未被使用:通过
- 递归和回溯:
- 递归调用:
- 将当前元素加入路径,标记为已使用。
- 递归处理下一个位置。
- 回溯操作:
- 递归返回后,将当前元素移出路径,标记为未使用,恢复状态。
- 递归调用:
🎁Step 3: 主函数调用
在主函数 permuteUnique 中:
- 对数组排序:
sort(nums.begin(), nums.end())。 - 初始化布尔数组:
check的大小为nums.size(),初始值为false。 - 调用回溯函数:
dfs(nums, 0)。 - 返回结果集
ret。
如图分析:
✨代码
class Solution {
public:
vector<vector<int>> ret;
vector<int> path;
bool check[9];
vector<vector<int>> permuteUnique(vector<int>& nums) {
// 先排序
sort(nums.begin(), nums.end());
dfs(nums, 0);
return ret;
}
void dfs(vector<int>& nums, int pos) {
if (path.size() == nums.size()) {
ret.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
// 剪枝(只关心合法分支)
if (check[i] == false && (i == 0 || nums[i] != nums[i - 1] || check[i - 1] == true)) {
path.push_back(nums[i]);
check[i] = true;
dfs(nums, pos + 1);
// 回溯
path.pop_back();
check[i] = false;
}
}
}✨时间与空间复杂度
🎁时间复杂度
- 全排列生成:
- 数组长度为
n ,排列数量为
n! 。
- 剪枝优化:
- 剪枝减少重复分支,但在最坏情况下仍需要生成
n! 个排列。
总时间复杂度:
🎁空间复杂度
- 递归深度:
- 递归调用栈的深度为
O(n) 。
- 路径和标记数组:
- 路径数组
path和布尔数组check的大小为
O(n) 。
- 路径数组
总空间复杂度:
结语
回溯法与深度优先搜索(DFS)结合,能有效地解决多种组合问题。通过决策树的结构,回溯法逐步探索解空间,而剪枝则通过减少不必要的计算,显著提高算法的效率。针对特定问题的剪枝优化,可以进一步提升回溯法的性能。
希望通过本文的讲解,您能深入理解回溯法与DFS在解决组合问题中的应用,并通过剪枝技术优化算法效率。如果您对回溯算法或其他算法问题有任何疑问,欢迎交流与讨论!
今天的分享到这里就结束啦!如果觉得文章还不错的话,可以三连支持一下,17的主页还有很多有趣的文章,欢迎小伙伴们前去点评,您的支持就是17前进的动力!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-12-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号