用最低成本,搭建属于自己的大模型数据库!ollama+graphrag
原创
用最低成本,搭建属于自己的大模型数据库!ollama+graphrag
原创
MGS浪疯
修改于 2024-11-15 07:48:17
修改于 2024-11-15 07:48:17
前言:
随着大模型的不断发展,人们对其要求也在不断提高,过往的通用大模型已经不能满足需求,更需要的是针对某个领域特定的大模型。但是从头开始训练一个模型又会很麻烦,不过,微软给了我们一个思路,那就是graphrag。本篇文件将利用graphrag和ollama搭建一个本地的大模型数据库
服务器的选择 HAI:
因为我们是要在本地运行大模型,首先要选一个带有gpu的服务器(如果选用纯cpu的服务器,速度会很慢)。
这里推荐的是购买腾讯云双十一的gpu服务器现金券,用它来开gpu服务器,效果很好
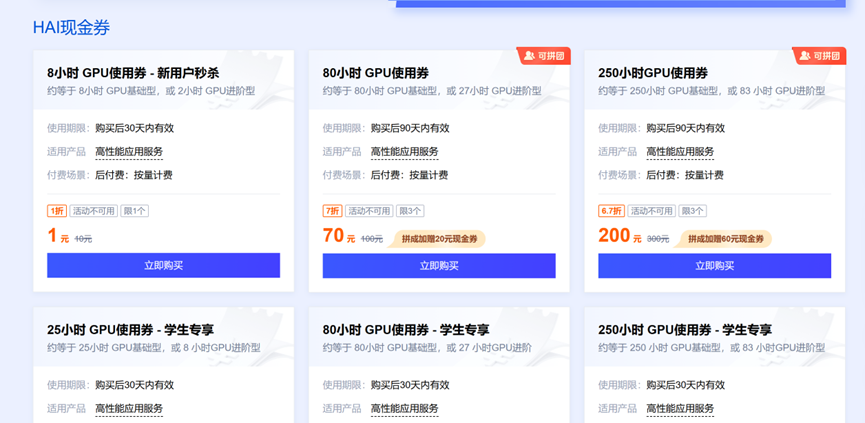
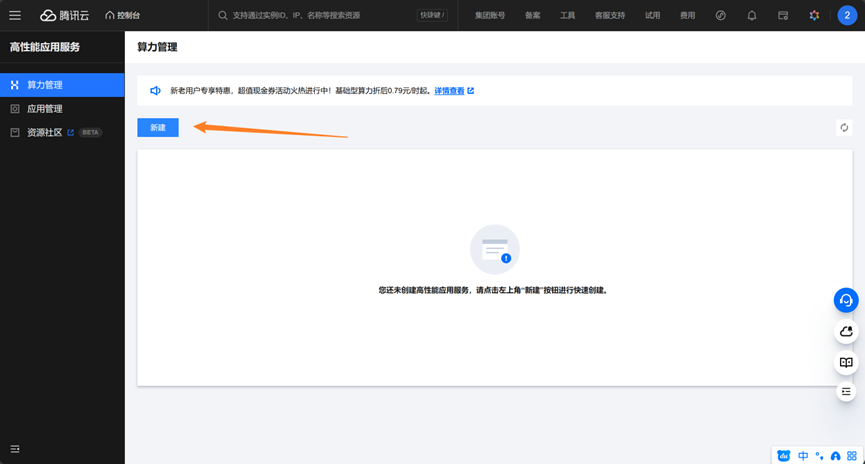
购买完成后,我们进入HAI的控制台
进入后点击新建
我们这里预设模板选择ollama,地区根据你自己的喜好购买(腾讯云这里提供了免费的学术加速,无需担心网络)
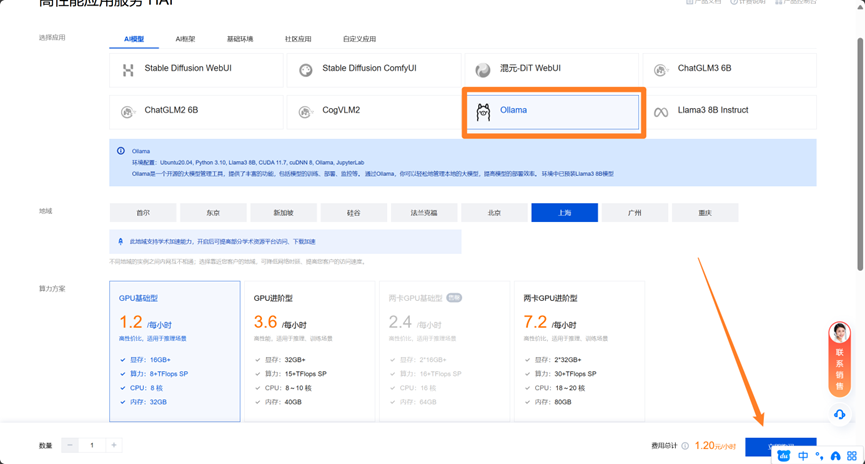
选好后我们点击立即购买即可
配置环境
购买完成后,我们点击算力链接,我们这里用的是cloud studio
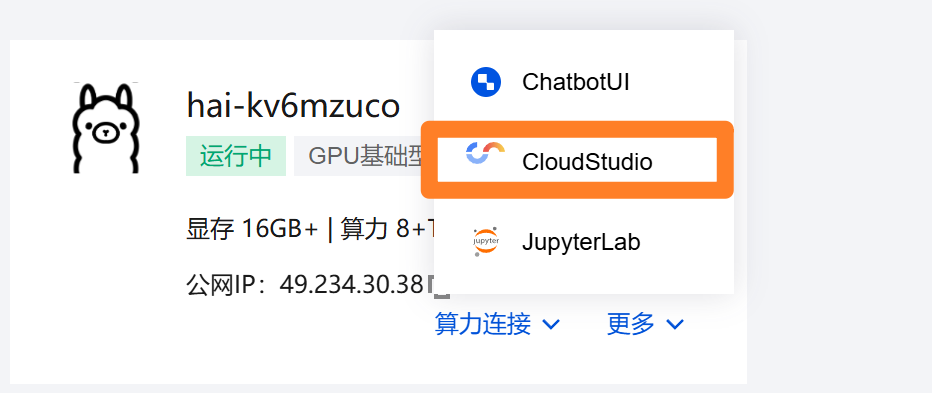
服务器的选择 CVM:
想必hai服务器,更推荐cvm服务器,因为cvm在其他方面更灵活,有更多的配置进行选择,而且可以随时创建镜像,方便数据保存
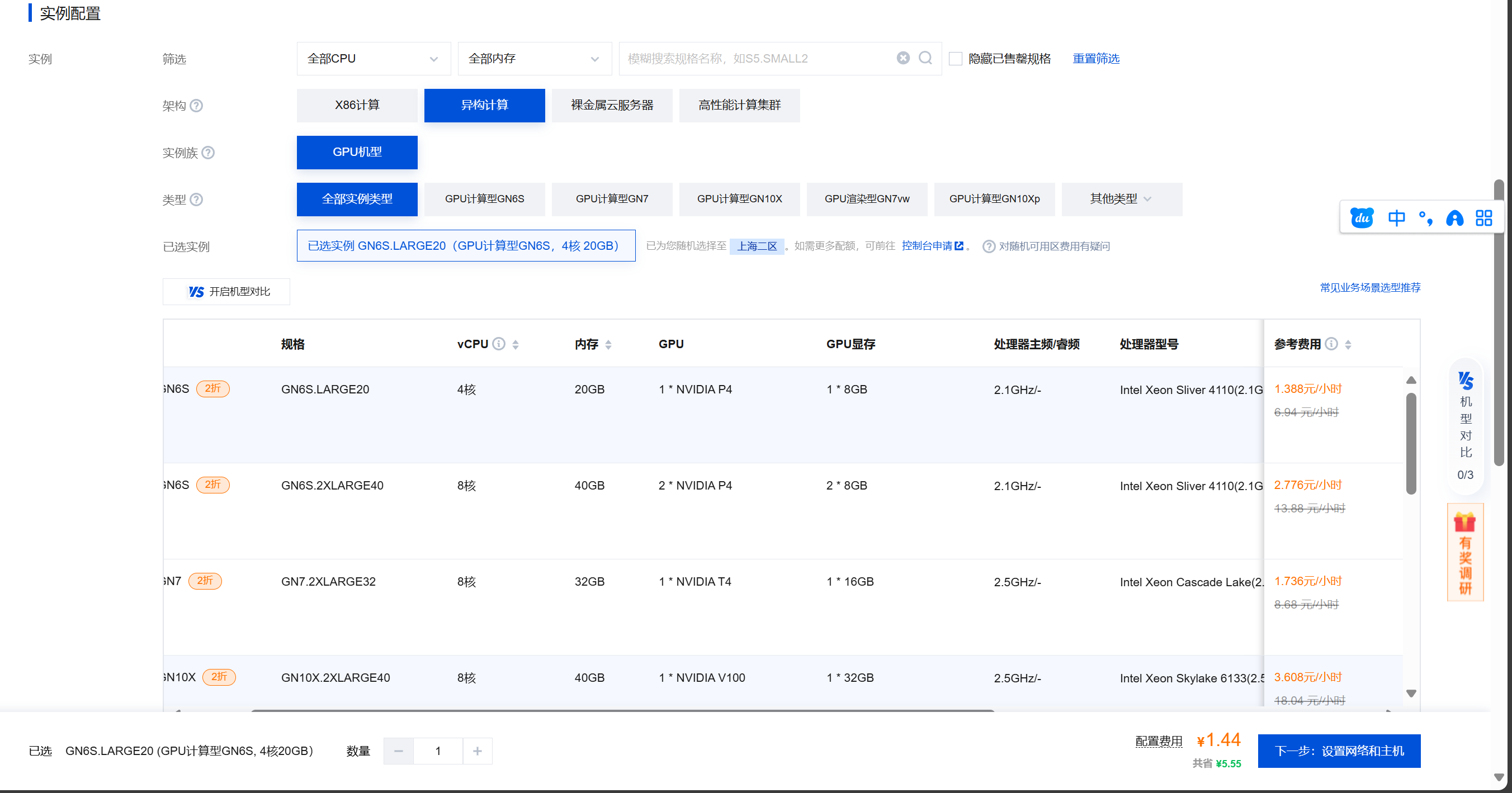
这里,我们可以选择不同的服务器,同时最近腾讯云双十一也在举行拼团活动,可以活动更多的优惠时长,欢迎大家来看看
https://cloud.tencent.com/act/pro/double11-2024
以下操作和cvm服务器的Linux操作系统下操作一样
检查ollama
因为是预装了ollama。我们只需要检查一下ollama是否正常就行了
文本描述已自动生成
我们点击新建终端,开启一个新终端
我们输入ollama,看看是否能够正常输出内容
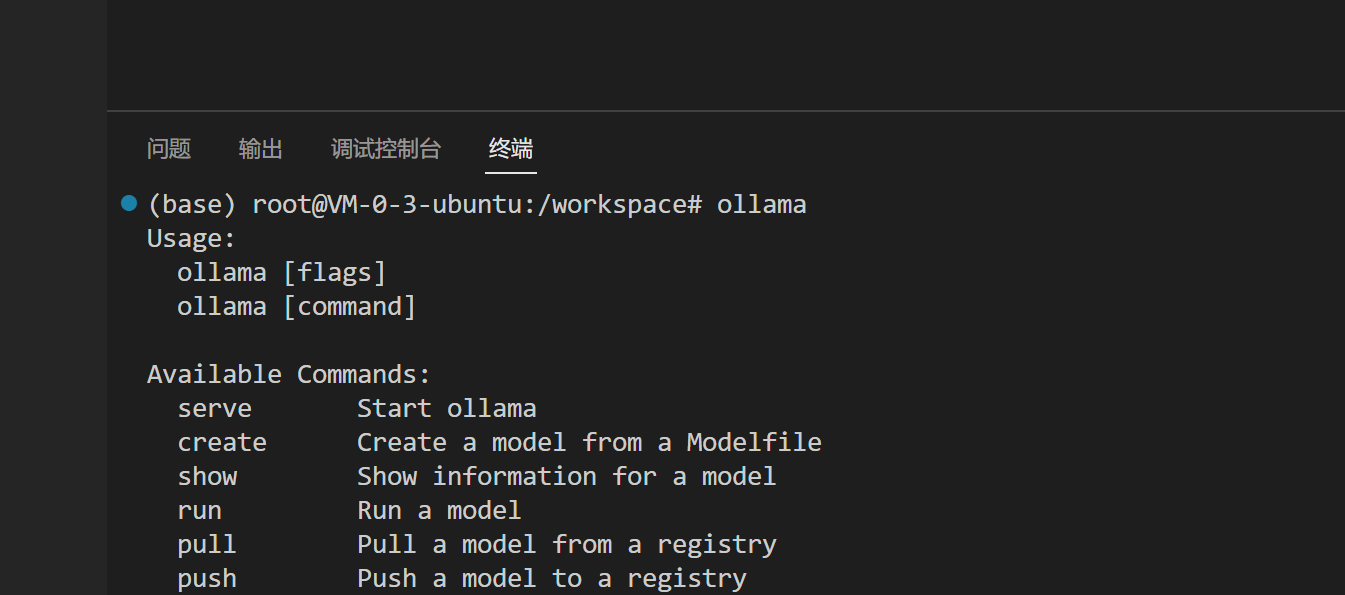
文本描述已自动生成
如果可以正常输出,就证明ollama配置没有问题
我们继续下载个新模型,直接输入
ollama run llama2-chinese

因为自带学术加速,速度还是不错的
这样 ollama本地大模型我们就不用管了,接下来安装配置graphrag
安装graphrag
- 因为自带conda,我们使用虚拟环境就方便很多
conda create -n rag python=3.12
直接输入这条指令,我们就可以创建一个python3.12的环境,会方便很多
完成后,我们输入conda activate rag即可进入虚拟环境
随后我们输入
pip install graphrag他会自动安装原版的graphrag

完成后,我们在目前的文件夹创建一个ragtest文件夹
或者使用指令
mkdir -p ./ragtest/input
创建后,我们初始化这个索引文件
graphrag init --root ./ragtest完成后 将创建两个文件:.env和settings.yaml,其中,settings是设置文件,因为我们是本地对接ollama,所以要做一些修改
我们把替换文件替换过去(感谢哔哩哔哩up主@深圳大学城市空间信息提供的替换文件
网盘链接: https://pan.baidu.com/s/1li35HD80IulxJntWcI9DFw?pwd=s53j 提取码: s53j )
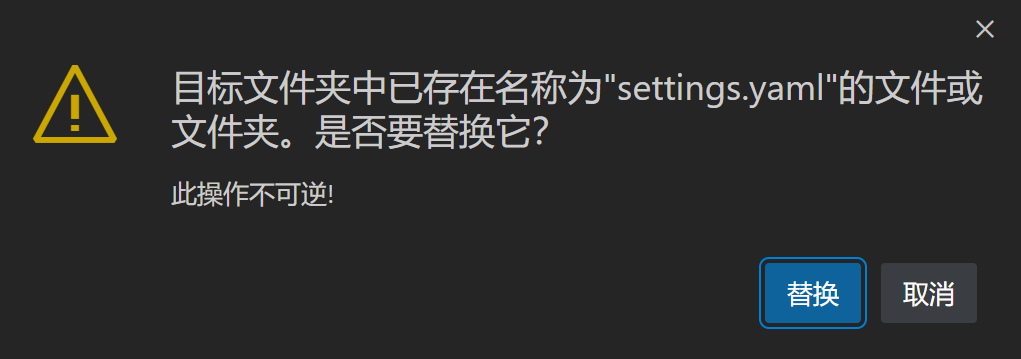
文本描述已自动生成
我们打开graphrag的安装目录(部分可能有所差异)
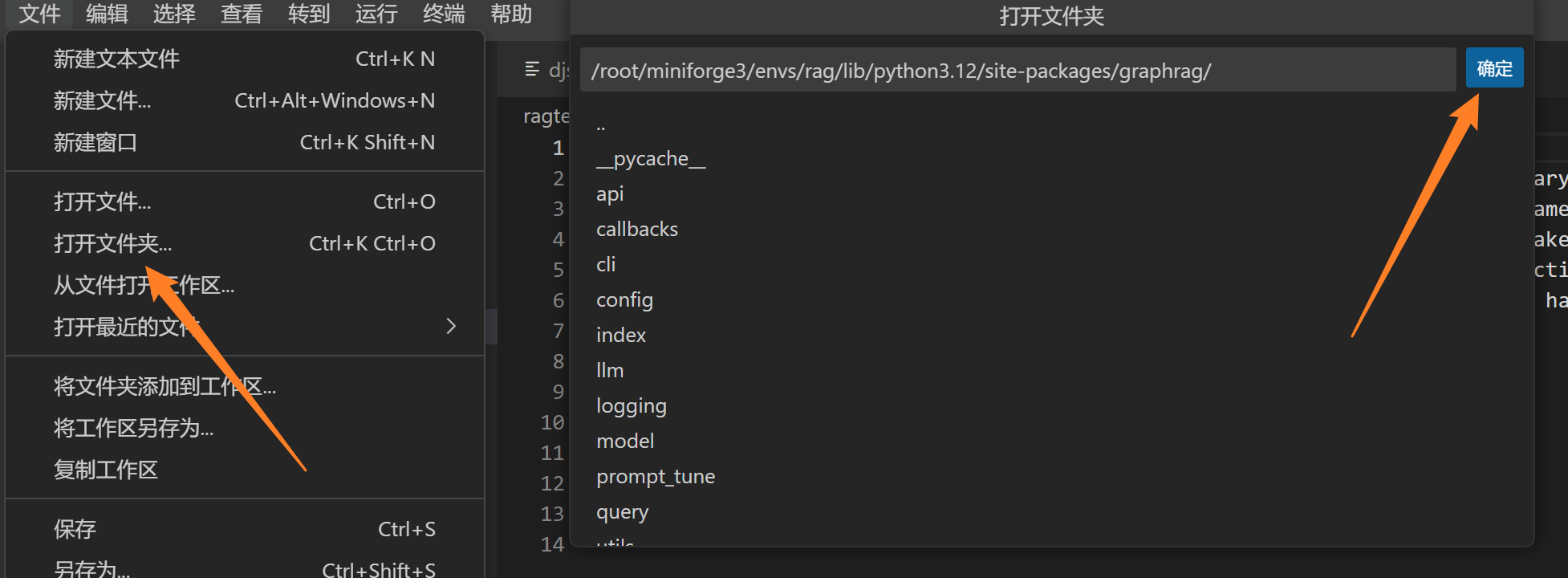
文本描述已自动生成
我们依次按照目录替换文件
/root/miniforge3/envs/rag/lib/python3.12/site-packages/graphrag/query/llm/oai
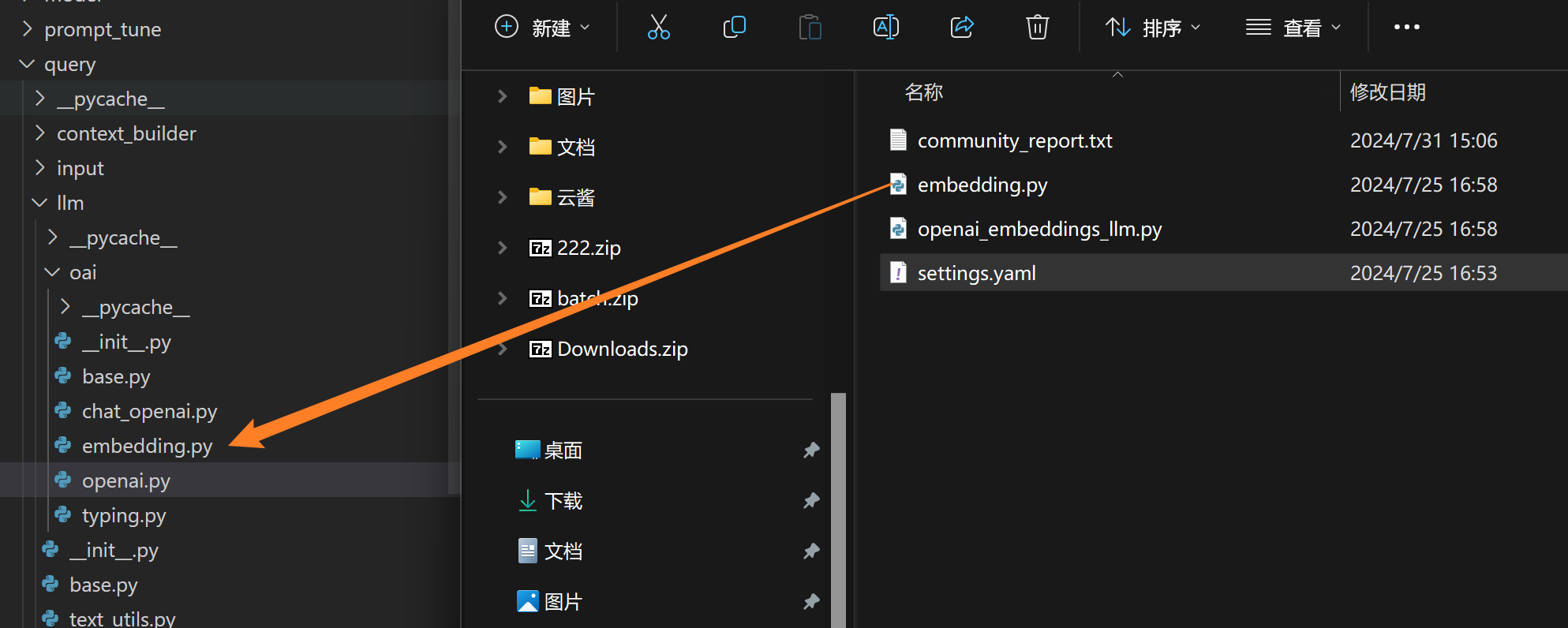
. /root/miniforge3/envs/rag/lib/python3.12/site-packages/graphrag/llm/openai
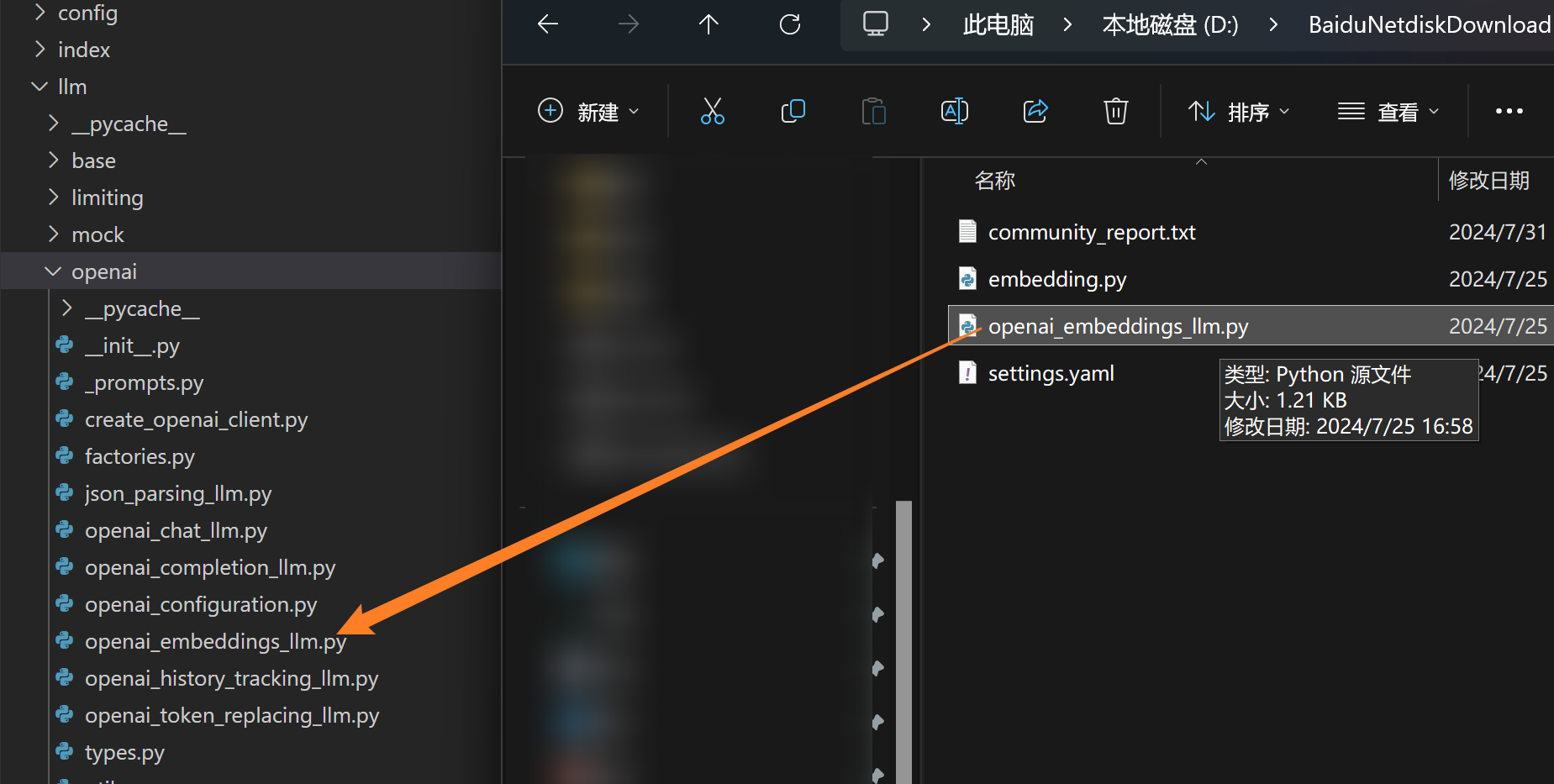
图形用户界描述已自动生成
替换完成后,我们返回到原先的文件夹就可以了
我们往input文件夹放一个TXT文档,这个txt文档就是我们要构建数据库的文档
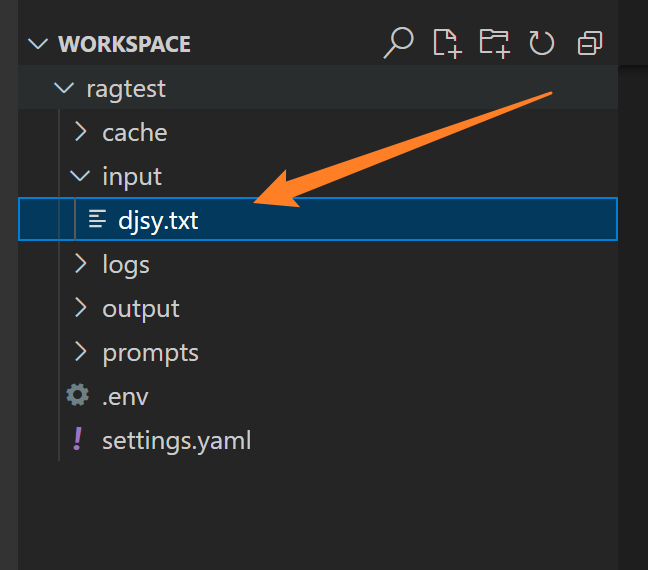
手机屏幕的截描述已自动生成
然后我们执行
graphrag index --root ./ragtest然后我们稍等即可
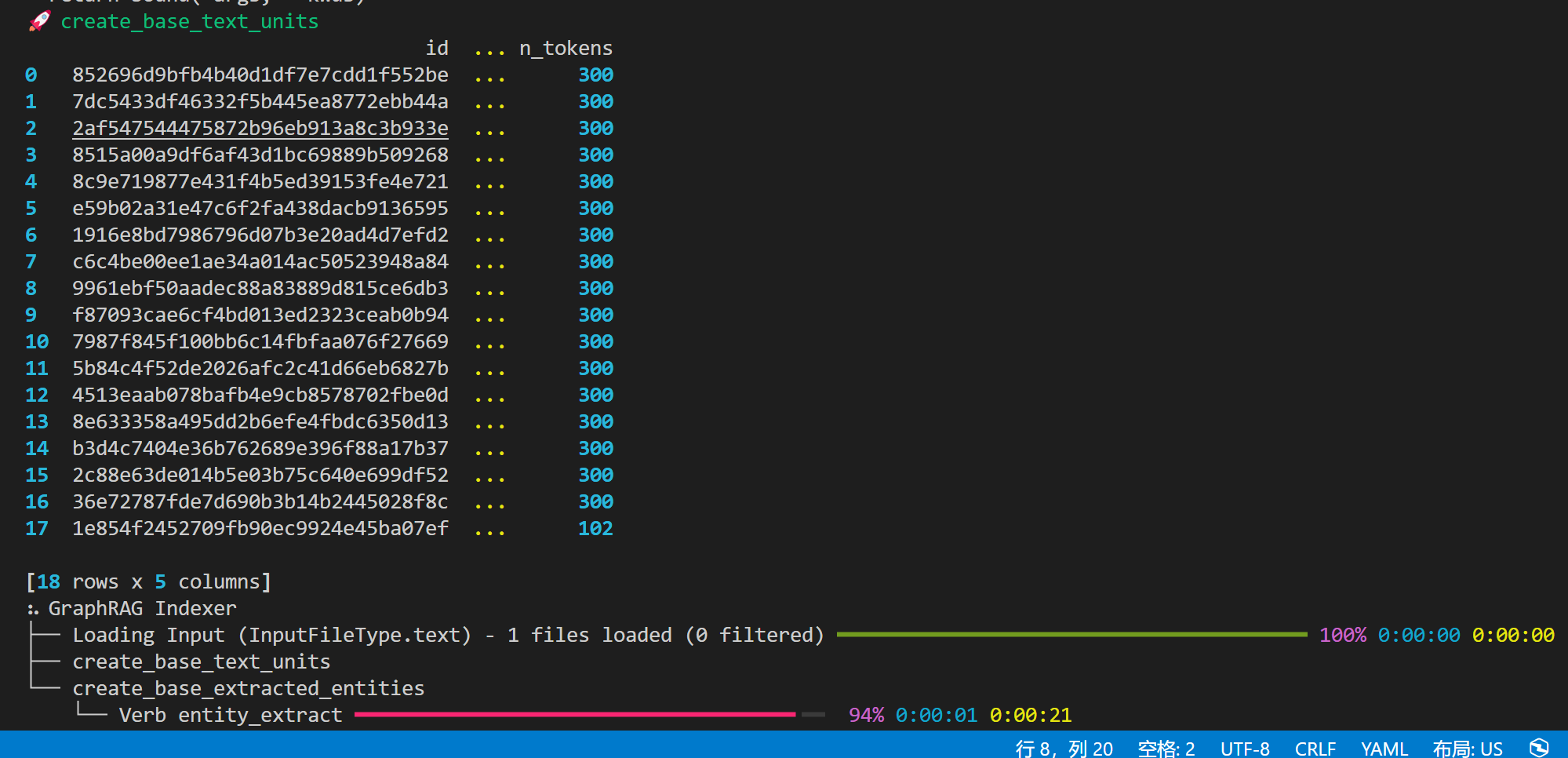
文本描述已自动生成
具体的速度快慢和最后成功好坏,取决于你本地的算力多少
这里也可以使用在线的大模型,不过需要是openai的格式,并且执行一次索引耗费的token较多,需要谨慎考虑
当最后提示🚀 All workflows completed successfully.,就表示我们建立成功了
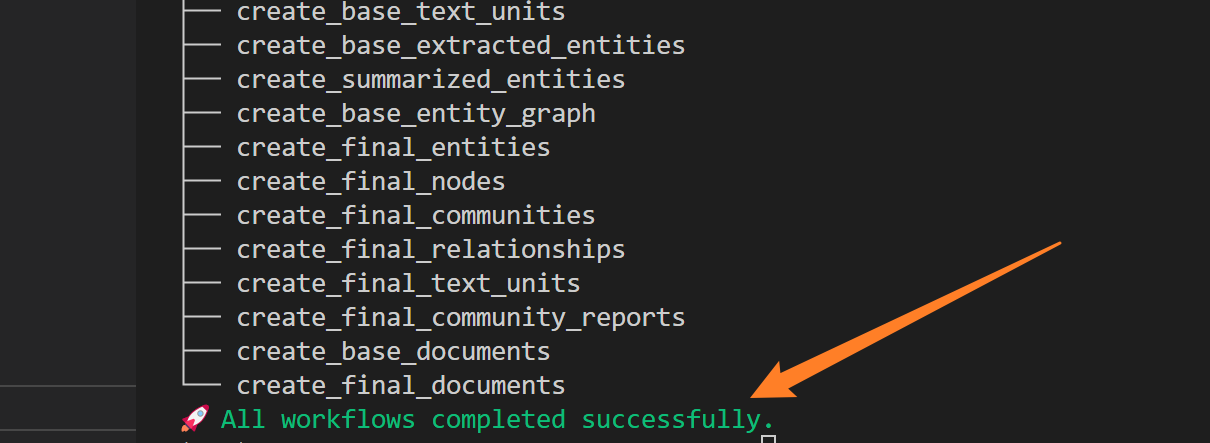
文本描述已自动生成
此时我们就可以进行检索了
输入
python -m graphrag.query --root ./ragtest --method global --query "你的问题"即可进行查询

文本描述已自动生成
因为不同安装方式有部分差异,请根据自己的安装方式进行调整
常见问题
1.为什么我最后出来的结果是英文?
答:可能是因为你使用的提示词模板是英文提示词,本地llm模型在其影响下输出了英文数据
解决方法:更换中文提示词
下载后替换到prompts文件夹接口
2.为什么无法正常索引
答:这个问题涉及到比较多,可能是配置文件部分地方修改问题,最容易出现问题的是api接口这里,我们要根据实际情况修改api接口,我们可以查看本机上ollama的服务器端口,来进行修改
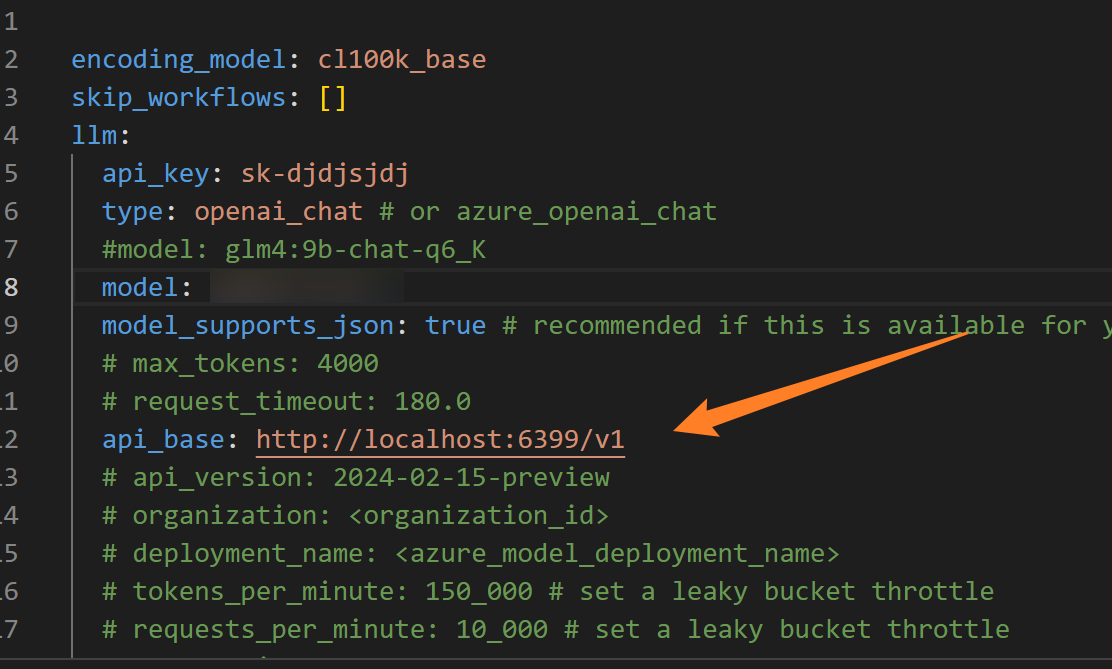
另一方面,可能是llm模型的问题,我们可以通过修改model修改,我们可以通过输入ollama list指令来看本机上有哪些大模型
3.输出的缺少文件
答:这个大概率是api接口超时了,或者是达到阈值了,这个多出现在使用在线模型的时候,本地大模型很少出现,可以尝试更换模型重新跑的方式来解决
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号