哈尔滨工业大学提出MolTailor模型,通过文本提示定制化学分子表示


深度学习现在广泛应用于药物发现(AIDD),能够显著加速药物发现的进程并降低成本。作为AIDD最基本的环节,分子表示对于预测分子性质以实现各种下游应用至关重要。大多数现有的方法都试图结合更多的信息来学习更好的表示。然而,并非所有特性对于特定任务都同等重要。忽略这一点可能会降低训练效率和预测准确性。
2024年3月24日,哈尔滨工业大学秦兵教授团队在人工智能顶级会议AAAI2024上发表文章MolTailor: Tailoring Chemical Molecular Representation to Specific Tasks via Text Prompts。
作者提出了一种新的方法,将语言模型作为智能体,将分子预训练模型作为知识库。智能体通过理解任务的自然语言描述来强调分子表示中与任务相关的特征,就像裁缝(tailor)为客户定制衣服一样。因此,作者称这种方法为MolTailor。实验证明了MolTailor的卓越表现,验证了增强分子表示学习相关性的有效性。这说明了语言模型引导优化可以更好地利用和释放现有强大的分子表示方法的能力。
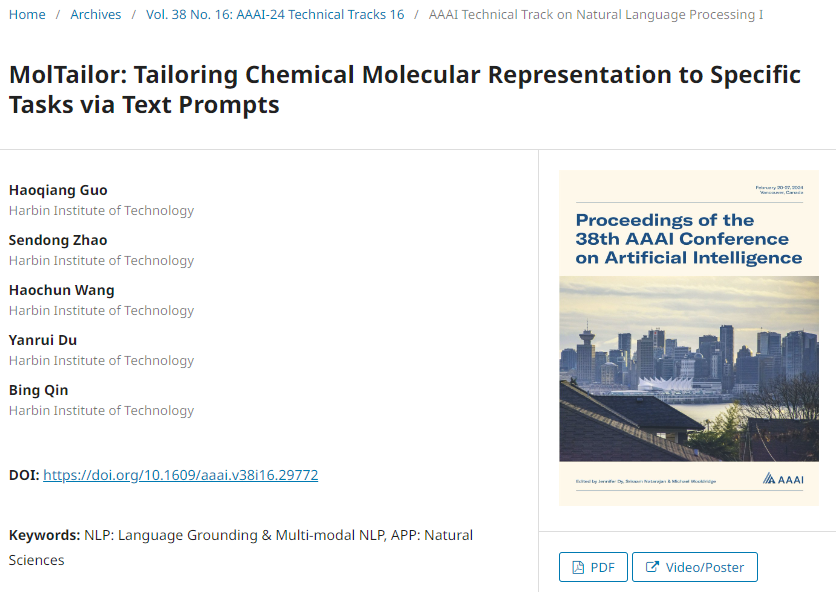
如图1所示,MolTailor包括以下部分。a) MT-MTR(分子-文本多任务回归)数据集的构建。从DrugBank和ChEBI中获得代表性分子,然后使用RDKit计算每个分子的209个性质。对于每个分子,从属性集中随机抽取5-10个属性,使用属性名称通过GPT-3.5生成虚拟任务描述,并使用属性值作为回归标签。b) MolTailor的模型架构。MolTailor由语言预训练模型(T-Encoder)和分子预训练模型(M-Encoder)组成。T-Encoder分为单模态部分(用于理解任务描述)和多模态部分(用于调整分子表示)。c) 多模态T-Encoder的内部结构。它修改了原始的Transformer编码器,以同时执行自注意力和交叉注意力操作:映射一般分子表示,然后将其与文本向量连接。d) MolTailor的预训练任务。模型需要根据分子和文本提示来预测任务描述中提到的属性。e) MolTailor下游任务。对于特定的下游任务,首先通过GPT-4分析生成与预训练相同格式的任务描述,然后将SMILES和任务描述作为输入来预测相应任务的标签。
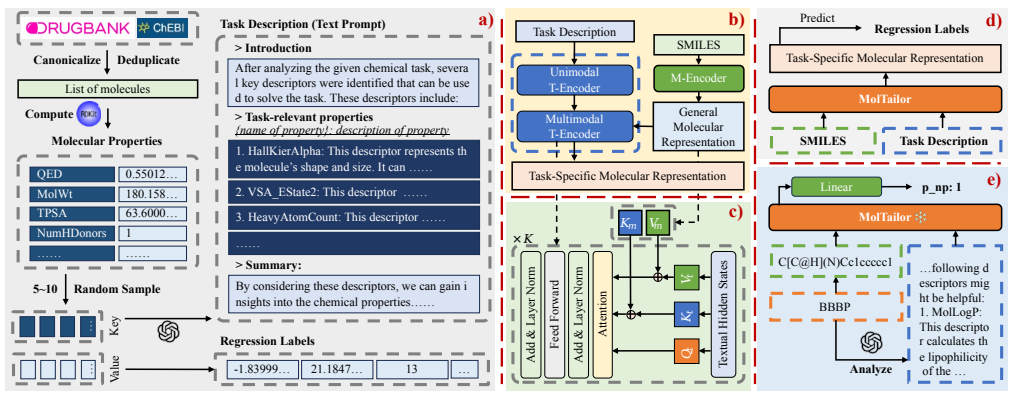
图1 MolTailor结构图
MT-MTR数据集的构建过程包括3个主要步骤,如图1a所示:
步骤1:获得代表性分子。从DrugBank和ChEBI中获取分子,然后使用RDKit得到SMILES,并删除重复数据和进行规范化。
步骤2:计算分子性质。对于上一步获得的每个分子,使用RDKit计算209个性质。
步骤3:获取任务描述和回归标签。对于每个分子,从上一步获得的属性集中随机抽取5-10个属性。将采样的属性名填充到预训练提示的模板中,以获得输入到GPT中生成虚拟任务描述的文本输入。由于GPT-4和GPT-3.5在此任务上实现相似的性能,因此在实验中使用更具成本效益的GPT-3.5进行生成。采样属性的值被用作回归标签。
生成的MT-MTR语料库包含(分子、任务描述、回归标签)三联体。同样值得注意的是,MT-MTR并不要求模型预测分子的所有性质,它只需要预测文本提示符中提到的属性,引导模型生成适合文本的分子表示,以改进预测。
如图1b和图1c所示,MolTailor由语言预训练模型(T-Encoder)和分子预训练模型(M-Encoder)组成。将语言模型分为单模态文本编码器(UT-Encoder)和多模态文本编码器(MT-Encoder)。将M-Encoder视为知识库,将T-Encoder视为代理。智能体通过理解自然语言,并从知识库中调整初始化良好的分子表示,从而获得最终期望的表示。UT-Encoder捕获语义信息,然后MT-Encoder根据理解任务描述定制分子表示。
现有的各种针对分子的预训练模型(例如CHEM-BERT)都可以作为M-Encoder,而构成这些语言模型的基本组件都是Transformer编码块(TEB),作为Transformer编码器的基本构建块,它由三个主要组件组成:多头自注意(MHA),前馈网络(FFN)和层归一化残差连接(LN)。由于任务描述包含生物医学术语,作者选择PubMedBERT作为T-Encoder的主干,其包含12个TEB。这里指定前9层为UT-Encoder,其余3层为MT-Encoder。
接着,作者使用MT-MTR作为预训练目标。具体来说,给定SMILES及任务说明作为输入,模型预测其209个指标的回归标签,如图1d所示。在将MolTailor应用于下游任务时,使用GPT-4对具体任务进行分析,生成相应的任务描述,如图1e所示,提示GPT生成模仿预训练语料库中描述格式的描述,限制它只能从RDKit支持的集合中选择属性的名称。然后,将生成的分析和SMILES输入MolTailor以获得特定任务的分子表示。最后,通过一个预测头来预测任务对应的标签。
作者将MolTailor与一些具有代表性的方法进行了比较。如表1所示,将多个分类预测和回归预测作为任务,分类任务将ROC-AUC(越高越好)作为指标,回归任务将均方根误差(RMSE,越低越好)或平均绝对误差(MAE,越低越好)作为指标进行对比,其中MolTailor或MolTailor*分别表示使用CHEM-BERT和其升级版ChemBERTa-2作为M-Encoder。表中加粗的数字表示最佳结果,下划线的数字表示MolTailor和MolTailor*的这个结果超越了对应的基线模型,即ChemBERT和其升级版ChemBERTa-2。在分类预测中,MolTailor在四个任务中的三个上超越了基线模型,在回归预测中,MolTailor在所有任务上超越了基线模型,在四个任务中的三个上取得了最佳结果。
表1 与其他方法对比
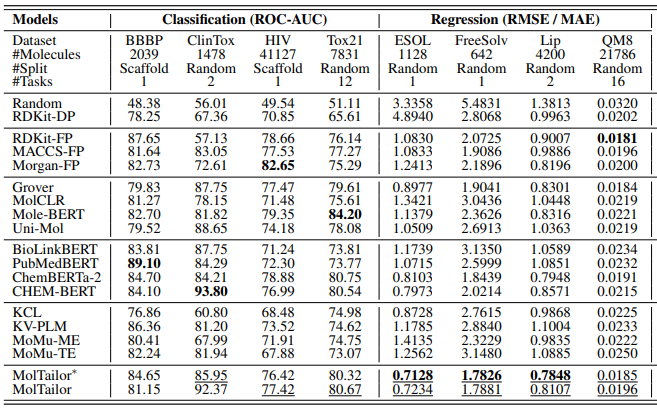
作者设计了消融实验来验证模型设计的有效性。为了评估任务描述对MT-MTR预训练的影响,首先去除任务描述得到数据集MT-MTR*,然后在MT-MTR*上预训练CHEM-BERT和PubMedBERT,得到CHEM-BERT*和PubMedBERT*模型。接下来,将任务描述连接到SMILES字符串之后,构造数据集MT-MTR+,并在MT-MTR+上预训练PubMedBERT,得到PubMedBERT+。如表2所示,四个分类数据集的指标平均值对比,以及四个回归数据集的指标平均值对比表明,CHEM-BERT*在回归任务上优于CHEM-BERT,但在分类任务上有所下降,表明去除任务描述作为预训练任务有利于下游回归,但对分类有负面影响。而另一方面,PubMedBERT+优于PubMedBERT*和MolTailor优于CHEM-BERT,都显示出进一步的回归性能提高,但分类性能下降。这表明引入任务描述有助于模型更好地从数据中学习。也就是说,如果构建新的标签可以提高模型在分类任务上的性能,那么补充任务描述可以进一步扩大这种收益。
表2 消融实验
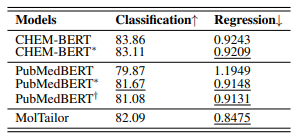
作者还进行了案例分析。本文在溶解度相关的ESOL数据集上进行了实验。该实验使用MolTailor及其相应的主干CHEM-BERT,还使用无关文本作为提示符(表示为MolTailor(噪声))测试了MolTailor的性能。结果如图2所示。作者对比了这三种方法在ESOL任务和预测四种分子性质方面的性能。在选择的四个属性中,有两个属性的名称在提示符中提到并且与ESOL任务相关(MolWt和FractionCSP3),一个属性没有提到但相关(EState_VSA3),还有一个属性既没有提到也不相关(Kappa1)。作者使用均方根误差(RMSE)作为评估指标,并进行归一化。这样,归一化均方根误差小于0,说明结果较好。图2结果表明:a)与CHEM-BERT相比,MolTailor确实更关注提示中提到的属性,验证了获得的表征确实是特定于任务的。b) MolTailor不仅更加关注提示符中明确说明的相关属性,还关注未说明但仍然相关的属性。同时,它减少了对不相关的、未提及的属性的注意力。这证明了该方法的泛化能力。c) MolTailor(噪声)在属性预测中的性能下降表明提示确实有助于模型关注关键信息。
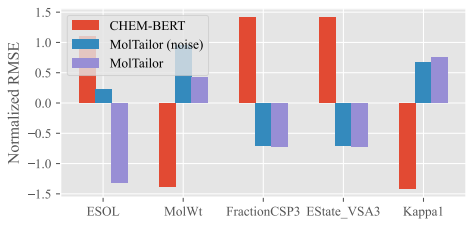
图2 案例分析
进一步,作者还从UT/MT-Encoder的最后一层的注意力矩阵来研究MolTailor是否关注关键信息。如果模型关注诸如分子量或极性官能团之类的信息(这些信息是溶解度的关键决定因素),则表明模型捕获了关键信息。图2的分析结果表明,MolTailor确实关注了与溶解度相关的信息,如“官能团”、“醚”和其他突出显示的关键词。此外,该模型还关注了SMILES中的极性官能团,如左侧分子注意力图所示。此外,不同提示下的两个分子注意图之间的差异表明,相比于噪声提示而言,有效的提示有助于模型更好地关注有助于解决任务的关键信息。
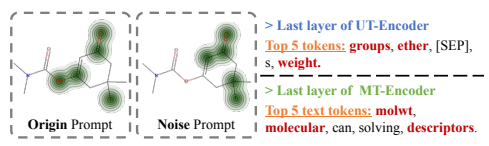
图3 可视化
本文提出了分子表示学习的新视角,也就是不再尝试将更多信息合并到表示中,而是通过组合上下文信息获得更多特定于任务的表示。同时,本文提出的MolTailor不仅利用文本情态中所包含的知识,还试图利用语言模型的推理能力,这在大语言模型时代具有巨大的潜力。在未来,有必要探索新的预训练任务,更加稳定地提高模型在分类和回归任务上的性能。其次,有必要探索如何基于大型语言模型构建分子-文本多模态模型。最后,相关模型可进一步结合药物研发领域专家知识,扩展分子-文本多模态方法的应用。
参考文献
[1] Guo et al. MolTailor: Tailoring Chemical Molecular Representation to Specific Tasks via Text Prompts. AAAI. 2024
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号